Warning:
This wiki has been archived and is now read-only.
Analysis of News Aggregator Scenario
Detailed analysis of the News Aggregator Scenario, which is one of the three flagship scenarios of our group's report on Requirements for Provenance.
Contents
Goals/Scope: Provenance Issues Highlighted in the News Aggregator Scenario
This section identifies anchor/entry points that people outside the provenance group can use to understand how to map their provenance needs into general aspects of the scenarios.
- checking licenses when reusing content
- verifying that a document/resource complies with licensing policies of pieces it reused
- integrating unstructured content, ie documents and media (in contrast with integrating structured data)
- content aggregation: aggregating RSS feeds, or product information, or news (in the case of the scenario)
- checking authority
- recency of information
- verification of original sources
- conveying to an end user the derivation of a source of information
- versioning and evolution of unstructured content, whether documents or other media (eg images)
- tracking user/reuse of content
- scalable provenance management
User Requirements Specific to News Aggregator Scenario
- Content
- Determine all the contributors to an aggregated blog post (instance of C-Attr-UR 1)
- Determine whether the owner of the site protesting the panda move has the authority to give the sweating panda image a particular license (instance of C-Attr-UR 2)
- Check whether the panda image was modified and by whom (instance of C-Vers-UR 1)
- Find the exact modifications of the the panda image (instance of C-Vers-UR 1b)
- Check when the panda image was modfied (instance of C-Vers-UR 2b)
- Ensure that the attribution information attached to a blog post is at the level of anonymity specified by the content producer (instance of C-Vers-UR 5.1)
- Be able to track the provenance of the blog post across multiple sites including microblogging sites as well as normal web pages (instance of C-Vers-UR 6b)
- Ensure that determining the where content for a blog post came from is automatic so that BlogAgg does not require is no human intervention for generating a blog post (instance of C-JUST-UR4)
- For the text of the blog post, be able to determine which parts of that text came from different content sources (instance of C-Entail-UR 3)
- Provide the date and time when a blog post was generated (instance of C-Entail-UR 8)
- Management
- Make available a web page describing the provenance of each blog post (instance of M-Pub-UR 1)
- Provide an easy to use mechanism for navigating the provenance (instance of M-Pub-UR2)
- Ensure that the changes to images are consistently represented so that BlogAgg can automatically make determinations about news (instance of M-Pub-UR3)
- Users should be able to know whether it is BlogAgg or another site that provided the provenance information (instance of M-Pub-UR4)
- Enable BlogAgg to analysis provenance for thousands of pieces of content (articles, images, etc) a day (instance of M-Scale-UR 1)
- Use
- Justify why a particular trust value was given to a post (instance of U-Under-UR 3)
- Provide for a visual seal of trust determined from provenance for each blog post allow the user to investigate how that seal was produced using what sources (instance of U-Under-UR4)
- Find which image the sweating panda image was originally based on (instance of U-Inter-UR2)
- Provide well documented provenance for retweets so that the original tweet can be found (instance of U-Inter-UR3)
- Allow BlogAgg to easily integrate the provenance from various news sites and blogs (instance of U-Inter-UR 5)
- Provide a trust seal for each blog post (instance of U-Tru-UR 1)
- Provide credits for each blog post (instance of U-Tru-UR 2)
- Allow the user to find how the trust seal for each blog post was calculated (instance of U-Tru-UR 3)
- Provide a summary of where each blog post came from (instance of U-Imper-UR 2)
- Allow users to see the entire provenance of an aggregated post (instance of U-Debug-UR 1)
Technical Requirements for News Aggregator Scenario
For this we started from the user requirements in our group's requirements report, looked at the list of user and technical requirements and the user requirements listed in the group's internal requirements document. We refined (in some cases dropped) the technical requirements as stated below.
We should make sure that any additional technical requirements are transposed back into the original requirements page and noted as such on that page.
Note that, when doing examples, if you cannot understand the requirement, add a note requesting clarification (see U-Acct-TR 6.2 as an example)
Content
- Content/Object What is the artifact that is the object of any provenance statements and what are the means to refer to it.
- identify an artifact in history
- refer to a series of artifacts over time as a single entity
- be able to distinguish between the part and the whole of an artifact
- be able to integrate identifiers for artifacts across systems
- allow multiple provenance statements for any identified artifact
- Content/Attribution Dimension: refers to the sources (i.e., typically any web resource that has an associated URI such as documents, web sites, or data) or entities (i.e., people, organizations, and other identifiable groups) that contributed to create the artifact in question.
- C-Attr-TR 1.1: disambiguated ids for sources and entities
- Eg. Distinguish between content creators 1 and 2
- Eg Distinguish between images 12 and 13
- Non-example: recognise that content creator 1 identified by its gmail account is the same as content creator 1 identified by a twitter account
- C-Attr-TR 2.1: mechanism to denote the entity that takes responsibility for the object of provenance
- Eg is content creator 1 the publisher of image 12?
- Eg Can reliable source 5 be sued for twitter 10?
- ability to identify the role of the entity with respect to the source
- Eg. who took the picture of image 12?
- Eg. who assigned this license to 13?
- C-Attr-TR 2.2: annotations for the origins of the provenance assertions. i.e. whether it's inferred, witnessed (by whom?), recorded, reconstructed, verified or not
- Eg user 4 claims that 5 made a tweet "#panda is sweating"
- Eg Who said that someone verified tweet 15?
- C-Attr-TR 2.3: A system should track which portions of a document were produced by an entity.
- Eg. who specified the license of image 13?
- C-Attr-TR 1.1: disambiguated ids for sources and entities
- Content/Versioning Dimension: As an artifact evolves over time, its provenance should be augmented in specific ways that reflect the changes made over prior versions and what entities and processes were associated with those changes
- C-Vers-TR 1.1: A system should keep track of the different versions of a published document, or piece of information.
- C-Vers-TR 1.2: A system should keep track of who makes changes to the document
- C-Vers-TR 1.1: A system should identify and record changes that are made to a document or data
- C-Vers-TR 1.2: A system should define what constitutes a different version of a document or data
- C-Vers-TR 2.1: mechanism to identify when content has changed
- C-Vers-TR 5.1: the provenance should be able to be queried with respect to versions of data
- C-Vers-TR 6b: versioning information should be interoperable across systems
- Content/Justification Dimension: A particular kind of provenance information is justifications of decisions. The purpose of a justification is to allow those decisions to be discussed and understood.
- C-JUST-TR4.1: their needs to be a mechanism for parties to define the correct behavior of a system so that that behavior can be valited against the provenance
- C-JUST-TR4.2: the provenance support provided by a system should be accessible and in a well-known format
- C-JUST-TR4.3: systems that provide provenance support should provide a transparent representation of their actions to the end-user either through documentation or through proofs
- C-JUST-TR4.4: provenance interoperability formats should support multiple concurrent user
- Content/Entailment Dimension: Some provenance information may be directly asserted by the relevant sources of some data or actors in a process, while other information may be derived from that which was asserted.
- C-Entail-TR 3.1: provenance mechanisms should support documenting the source of information at different granularities (e.g. at the database, table, and tuple levels or in RDF the triple, graph, or endpoint levels)
- C-Entail-TR 3.2 for a given query to a database systems should be able to provide the provenance of the answer that query
- mechanisms to provide the date and time when provenance was derived
Management
- Management/Publication Dimension:
- M-Pub-TR 1.1: Tools should be available allowing content publishers to publish the associated provenance information.
- M-Pub-TR 1.2: Tools to publish provenance information at different levels of granularity.
- M-Pub-TR 1.3: Provenance sources should be able to aggregate provenance from other sources.
- M-Pub-UR 3.1: Provenance should be represented in a form that facilitates interoperability.
- M-Pub-UR 3.2: Provenance should be presented in a accessible format, including visual, textual and structured formats: for presentation, human consumption and automation.
- M-Acc-TR 4.1: It should be possible to authenticate the publisher who wishes to publish to a provenance service (publish authentication using standard ID's)
- M-Acc-TR 4.2: It should be possible to control who can publish to a provenance service (authorization)
- M-Pub-TR 4.3: Allow provenance to be published online without violating privacy and privacy laws.
- M-Acc-TR 4.4: It should be possible to publish provenance in a secure, non-forgeable way.
- Management/Access Dimension:
- M-Acc-TR 1.1: Well-known, authoritative and federated sources should provide access to provenance.
- M-Acc-TR 1.2: Provenance sources should provide protocols to query for provenance.
- M-Acc-TR 1.3: Provenance sources should allow provenance to be extracted at different levels of granularity and formats.
- M-Acc-TR 1.4: It should be possible to locate the provenance source(s) for an artifact to query for its provenance.
- M-Acc-TR 2.1: It should be possible to authenticate a user who wishes to access a provenance source (access authentication using standard ID's)
- M-Acc-TR 2.2: It should be possible to control who can access a provenance source (authorization)
- M-Acc-TR 2.3: It should be possible to access provenance in a secure, non-forgeable way.
- Management/Dissemination Dimension:
- M-Diss-TR 1.1: Represent purposes of using data in a way which can be compared against the provenance of its usage.
- M-Diss-TR 1.2: Represent the provenance of disseminated data in a way which allows its usage to be checked against pre-stated purposes.
- M-Diss-TR 1.3: Provide mechanisms to examine data's provenance to check for correct usage according to pre-stated purpose.
- M-Diss-TR 1.4: Make the provenance representation non-forgeable (non-repudiation, no man-in-the-middle attack)
- M-Diss-TR 2.1: It should be possible to verify who the publisher/originator of provenance is (publisher authentication using standard ID's)
- Management/Scale Dimension:
- M-Scale-TR 4.1: Provenance sources should scale with the number of provenance documents published for artifacts at fine granularities. (Web scale resources)
- M-Scale-TR 4.2: Provenance sources should scale with the number of query requests. (Web scale requests)
- M-Scale-TR 4.3: Provenance sources should scale with provenance aggregated from other sources.
- M-Scale-TR 4.4: Provenance sources should reliably provide provenance publishing and access over time.
Use
- Usability/Understandability Dimension: An important consideration is how to make provenance information understandable to its users/consumers.
- U-Under-TR 1.1: Support for domain specific presentation of the provenance record
- U-Under-TR 1.2: It should be possible to query a provenance graph using a combination of domain-independent, common terms and properties as well as terms from a domain-specific vocabulary.
- U-Under-TR4.1: Ability to query different levels of abstraction/granularity/detail from the provenance record.
- U-Under-TR4.2: It should be possible to transit between the different levels of abstraction/granularity/detail.
- Ability to query different perspectives/views/aspects from the provenance record.
- Integrate the provenance record with other data sources.
- Usability/Interoperability Dimension: Because provenance information may be obtained from heterogeneous systems and different representations, interoperability is an important requirement
- U-Inter-TR 2.1: Provide a common representation of provenance
- U-Inter-TR 2.1.1: Provide a computer parseable notation for provenance
- U-Inter-TR 2.1.2: Provide an explanation about how the provenance was calculated understandable by the user.
- U-Inter-TR 3.3: It should be possible to use provenance from multiple repositories
- U-Inter-TR 4.1.: Ability to assess provenance at different levels of granularity.
- U-Inter-TR 4.3.: Ability to find the provenance of merged metadata.
- Usability/Accountability Dimension: Provenance data is often used to provide accountability
- U-Acct-TR 3.1: Provenance information should help identify the costituents of an aggregated atifact, along with their actual respective licenses.
- Eg. The Web site should display the actual license of the original panda image
- Eg. The Web site should display each of the tweets and blog text of post 4 along with their licenses
- U-Acct-TR 6.1: It should be possible to annotate artifacts as copyrighted/licensed entities.
- Eg. annotate image 2 with its appropriate license
- U-Acct-TR 6.2: The semantics of copyrights should be standardized w.r.t. provenance
- this requirement needs clarification. Here is a possible interpretation: provenance should be able to express terminology from copyright law
- Eg. need to show that blog post 4 is a derivative work of the NY Times web site
- Eg. is image 2 original?
- U-Acct-TR 3.1: Provenance information should help identify the costituents of an aggregated atifact, along with their actual respective licenses.
- Usability/Trust Dimension: Provenance information is used to make trust judgments on a given entity.
- U-Tru-TR 1.1: Ability to associate source information with aggregated data.
- U-Tru-TR 1.2: Ability to use source information to compute trust associated with data.
- U-Tru-TR 1.4: Ability to deal with missing provenance information.
- U-Tru-TR 2.2: Attribution metadata should be expressed in a formal and machine‐processable language.
- U-Tru-TR 3.1: Enable users to understand the process used to compute trust.
- U-Tru-TR 3.2: Enable users to understand the measurement value of trust.
- Usability/Debugging Dimension: Users may want to detect failure symptoms in the provenance records and diagnose problems in the process that generated an artifact, whether conducted in a software system or by people
- U-Debug-TR 1.2: Let the user know how the provenance or trust value of a provenance record was calculated in order to detect errors.
Diagrams
This is where we identify components/aspects of a provenance solution to the scenario, and how technical requirements for the scenario are grouped into 1) content, 2) management, 3) use.
- See PDF version of figures below: File:UseCase1-BlogAgg.pdf

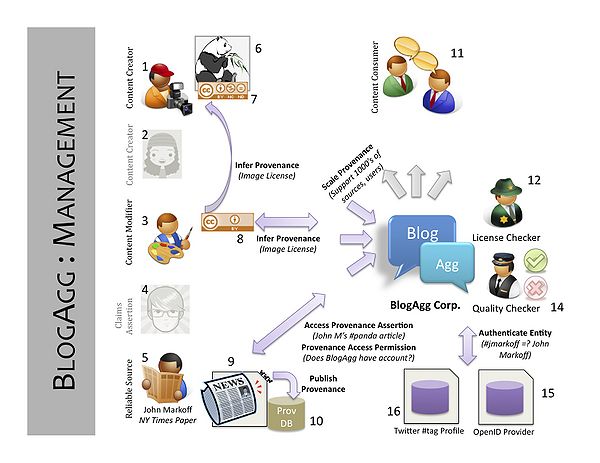

We need to explain these pictures, we should add numbers so that we could refer.
Relevant State of the Art
This section describes the research conducted in relation to, and the technology available to fulfill, the above described requirements with specific regard to the Business Contract Scenario.
Here is a summary of related work brought up in the original use cases.
Existing Solutions Used Today for News Aggregation
A summary of research, with referenced papers, which consider issues similar to the scenario-specific user requirements above, or are applied in a similar domain.
The News Aggregator envisions a system that can automatically tell where a piece of content (i.e. object) on the Web comes from and who is responsible for that content after it has aggregated content.
Aggregation Today
Content aggregation is widely used on the web. Examples of content aggregation for news include sites such The Huffington Post, Digg, and Google News. Personal aggregation is facilitated by feed technologies (RSS, Atom) and their associated readers (e.g. Google Reader). Newer aggregators like Flipboard provide a merged view of content, thus, hiding some of the provenance of the information to increase visual appeal. This is similar to what is envisioned in the News Aggregator scenario.
Tracking Content
A number of systems have looked at tracking content, in particular, quotes across the web. Memetracker (Leskovec2009), for example, provides a system and algorithms for tracking distinctive phrases through the blogosphere. Memetracker is able to reconstruct the news cycle by tracking both news outlets and blogs (Leskovec2009). (Gomez-Rodriquez2010) expands on this work to track how information is propagated through the network and thus which blogs and media have the greater influence. Similarly, (Cha2010) studies influence in the microblogging network, Twitter, including the difference between the influence of content and the influence of users. (Lerman2010) studied how the social networks of both Twitter and Digg impact the propagation of information through these networks.
Most of these systems rely on crawls of the web that are produced uniquely for each application. However, there are tools and services for producing these crawls uniquely. For example, BlogTracker is tool for periodically crawling and then analyzing blogs(Agarwal2009). On a commercial scale, Spinn3r (http://www.spinn3r.com/) provides realtime access to a large crawl of both blog and microblog data.
Need for Explicit Provenance
It is important to note that these systems deduce the provenance of an object (e.g. a piece of text) after the fact from crawled data. However, determining provenance after the fact is often difficult. For example, during the Iranian Green Revolution protests it was extremely difficult to determine the actual origins of tweets about what was happening on the ground (Brinkley2009). Because of the variabilities of determining where tweets came from, in later 2009, Twitter launched it's own service to explicitly capture the notion of retweeting (Williams2009). (Lynch2001) provides an analysis of the difficulty in determining provenance for accountability and trust from crawled documents. Another widely used example of explicit tracking of the origin of web data is trackbacks [1] and pingbacks [2] for blogs. These are used to notify a blog when another blog has linked to it. We note that these systems are isolated to specific technology platforms and do not encompass the whole of the web.
Licensing
A crucial reason for tracking provenance in the News Aggregator Scenario is the ability to determine if an image (or other content) can be reused. In the area of music, Creative Commons hosts the site ccMixter [CreativeCommons2010], which allows musicians to track the licenses of different music clips across sites. In a similar vein, the Google Books Rights Registry [Wikipedia2010] tracks and maintains the licensing rights for books especially with respect to online publishing of those books. Fundamental technology related to this is the digital representation of licenses. An example of this is the representation of Creative Commons licenses as RDFa [3].
In summary, there are a number of systems on the web today that resemble BlogAgg, however, the technologies that underpin these systems, in particular with respect to provenance, are divergent.
Current Provenance Research Relevant to the Scenario
This section presents a summary of research and software, with references, which address the general technical requirements above in a way directly applicable to this scenario
Here, we aim to discuss how the technical requirements drawn from the News Aggregator Scenario are addressed by existing technology and research. We proceed by discussing each dimension in turn.
Notes
This section is a work in progress. The group has analyzed relevant work, but it would take a lot of effort and coordination to summarize it all here. This may or may not be complete by the time the group ends its activities. We encourage all group members to contribute. Some notes to facilitate this process:
- Research is organized according to our provenance dimensions.
- We list the titles of the papers/documents that should be discussed for that dimension. The documents were listed there according to the tags within mendeley.
- When discussing a paper, please relate it both to the scenario and to the technical requirements above.
- Descriptions of papers should be parsimonious and aimed to a non provenance reader.
Content
Object
A key part of the News Aggregator Scenario is to be able to point to the piece of media to determine its provenance. This is typically done through the use of URLs. However, systems do need to be able to point to parts of media for example a scene in video clip or part of movie. The Multimedia Semantics Incubator Group has a detailed discussion of describing multimedia and thus how identify their constituent parts (Hausenblas 2007).
Attribution
Attribution is a key part of the scenario. It's important to know who or what asserted a statement. Dublin Core is a widely used vocabulary for expressing attribution information. Deeply tied to attribution in social web scenarios is the notion of identity. For an overview of identity technologies, research and implications for social media, we refer readers to the Social Web Incubator Group's final report and its section on identity (Halpin,Tuffield 2010). Another crucial aspect is that attribution may not be explicitly recorded or may be falsely claimed. Lynch 2011 discusses this problem in depth and Juola 2006 suggests a mechanism for inferring attribution based on language.
Process
Most of the work in capturing the process or how a data item was produced has been done in the context of workflow systems and databases. This is discussed in more depth in the other scenarios. Most of the work with respect to provenance in social media, reconstructs the provenance after the fact from large crawls (See Lerman 2010). Groth 2010 present a model designed for representing processes in web based mash-up. Buneman et al. discuss a model for provenance of manually modified data such as web pages.
Versioning and Evolution A particular part of social media is tracking changes in web documents. Wikipedia edit histories have been widely studied. A good starting point is Lieberman's paper on locating users through their edit histories.
Management
Publication
Publication of provenance on the web has largely been discussed with respect to the semantic web and linked data. Hartig and Zhao discuss one approach to publishing provenance on the web of data. It identifies important points around how information access should be published as part of provenance. Reid et al. discuss how provenance in a research environment can be published and linked to social media. Bao et al. discuss tracking changes in MediaWiki platform and publishing those changes using semantic web technologies.
Use
Trust
By far the largest area of work with respect to the News Aggregator Scenario is with respect to provenance. Artz and Gil provide a comprehensive survey of trust and the semantic web. IWTrust uses provenance to improve users trust of in the results of a question-answering system that works over web documents. In a similar vein, the Trellis system derives trust ratings of web content using the judgements of many different users. Bizer discusses in detail information accountability with respect to web based information systems and discusses implementations with respect to the semantic web.
Gap Analysis
Given the analysis of the state of the art above, what are the technology gaps to achieve what the scenario proposes?
First, existing provenance solutions only address a small portion of the scenario and are not interlinked or accessible among one another. For each step within the News Aggregator scenario, there are existing technologies or relevant research that could solve that step. For example, one can properly insert licensing information into a photo using a creative commons license and the Extensible Metadata Platform. One can track the origin of tweets either through retweets or using some extraction technologies within twitter. However, the problem is that across multiple sites there is no common format and api to access and understand provenance information whether it is explicitly indicated or implicitly determined. To inquire about retweets or inquire about trackbacks one needs to use different apis and understand different formats. Furthermore, there is no (widely deployed) mechanism to point to provenance information on another site. For example, once a tweet is traced to the end of twitter there is no way to follow where that tweet came from.
Second, system developers rarely include provenance management or publish provenance records. Systems largely do not document the software by which changes were made to data and what those pieces of software did to data. However, there are existing technologies that allow this to be done, for example to document the transformations of images. There are also general provenance models would allow this to be expressed, but they are not currently widely deployed. There are no widely accepted architectural solutions to managing the scale of the provenance records, as they may be significantly larger than the base information itself in addition to also evolving over time.
Third, while many sites provide for identity and there are several widely deployed standards for identity (OpenId), there are no existing mechanisms for tying identity to objects or provenance traces. This is a fundamental open problem in the web, and affects provenance solutions in that provenance records must be attached to the object(s) they describe.
Finally, although there have been proposals for how to use provenance to make trust judgments on open information sources, there are no broadly accepted methodologies to automatically derive trust from provenance records. Another issue that has been largely unaddressed is the incompleteness of provenance records and the potential for errors and inconsistencies in a widely distributed and open setting such as the web.
In summary, although there are many proposed approaches and technology solutions that are relevant, there are several major technology gaps to realizing the News Aggregator scenario. Organized by our major provenance dimensions, they are:
- With respect to content:
- No mechanism to refer to the identity/derivation of an information object as it is disseminated and rewritten in the blogosphere and the twittosphere
- No common standard for exposing and expressing provenance information that captures processes as well as the other content dimensions
- With respect to management:
- No well-defined standard for linking provenance between sites (i.e. trackback but for the whole web).
- No guidance for how existing standards can be put together to provide provenance (e.g. linking to identity).
- No guidance for how application developers should go about exposing provenance in their web systems.
- No proven approaches to manage the scale of the provenance records to be recorded and processed,
- No standard mechanisms to find and access provenance information for each item that needs to be checked,
- With respect to use:
- No broadly applicable approaches for dealing with imperfections in provenance,
- No broadly applicable methodology for making trust judgments based on provenance when there is varying information quality.