Warning:
This wiki has been archived and is now read-only.
Analysis of Disease Outbreak Scenario
Detailed analysis of the Disease Outbreak Scenario, which is scenario 2 of our group's requirements report.
Contents
Goals/Scope: Provenance Issues Highlighted in the Disease Outbreak Scenario
This scenario covers aspects of provenance involving scientific data and public policy, at a number of levels of detail ranging from working scientists and data specialists who need to understand the detailed provenance of the data they work with, to high-level summaries and justifications used by non-expert decision makers.
In this scenario, there are several distinctive uses of provenance:
- data integration: combining structured and unstructured data, data from different sources, linked data
- archiving: understanding how data sources evolve over time through provenance and versioning information
- justification: summarizing provenance records and other supporting evidence for high-level decision making
- reuse: using data or analytic products published by others in a new context
- repeatability: using provenance to rerun prior analyses with new data
User Requirements Specific to the Disease Outbreak Scenario
This section enumerates specific (provenance-related) user requirements from the scenario as described here, and gives reference to the relevant general user requirements listed in the requirements list.
- Content
- C-Attr-UR 1: Determine who contributed to a document (disambiguation).
- C-Attr-UR 2: Record which content was created by which person (versions).
- Eg: Who created the first version of the patient classification dataset?
- C-Proc-UR 1: Relate agents to the (sub)process involved.
- C-Proc-UR 2: It should be possible to reason on the outcome of a given process, assuming changes in their preconditions -- for example to consider hypothetical what-if scenarios.
- Eg: What would be the result of the experiment if we change 2 different and compatible datasets?
- C-Proc-UR 3: A process should be reproducible from its provenance graph.
- C-Proc-UR 5: It should be possible to analyze the provenance of a process at different levels of granularity -- for example to drill down on justification for a result
- Eg: Why have we obtained this outcome? Where does it come from?
- C-Vers-UR 1: Determine how content changes (i.e. its version) across the web and who is responsible for those changes -- if a data source changes and is posted as a new version, you would need to update the integrated data and see what effects it has on the system.
- Eg: Who is the author of the version 5.0 of the patient classification dataset?
- Eg: How was the patient classification dataset changed from v3 to produce v5?
- C-JUST-UR1: The end results of engineering processes or scientific studies need to be justified by linking to source and intermediate data.
- C-JUST-UR1.1: The justification should distinguish between source and derived data, and show how intermediate results were obtained (Cf. C-PROC-UR-1, C-ENTAIL-UR-1, U-UNDER-UR-1, U-UNDER-UR-2)
- Eg: Which datasets have been used for Alice's patient classification?
- Eg: Is Gene K related to Bob's research?
- Eg: Is patient classification dataset modified by Bob's research?
- C-JUST-UR1.2: Links need to relate both public and confidential materials stored both online and offline (cf. C-ENTAIL-UR-6, M-DISS-UR-2)
- C-JUST-UR2.1: Non-experts should be able to make basic judgments about the validity of the end results based on the supporting information, possibly using automatically constructed "executive summaries". (Cf. C-PROC-UR-3, C-PROC-UR-5, C-ENTAIL-UR-3, M-ACC-UR-2, M-ACC-UR-3, U-UNDER-UR4, U-IMPER-2)
- C-JUST-UR2: The justification should facilitate informed discussion and decisions about the results.
- C-JUST-UR2.2: Experts should be able to test the robustness of the conclusions by considering alternative steps or modeling choices, or identifying likely "points of failure" (Cf. M-DISS-UR-1, U-UNDER-UR-3, U-DEBUG-UR-1)
- C-JUST-UR2.3: Automatic tools (by both experts and non-experts) should be able to perform basic checks of the authenticity, integrity and validity of the justification, to verify that a study or engineering process followed regulations, or to decide among different supported conclusions making competing claims (M-DISS-UR-1, U-INTER-TR1.3, U-ACCT-UR-1, U-COMP-UR1)
- Eg: Why have I obtained that A is a human patogen responsible for owl flu in the experiment152?
- Eg: Why step three took patient classification dataset v3 instead of owl dataset v5 in Bob's study?
- C-JUST-UR3: The justification should be preserved so that the actual long-term behavior of a product, or effects of a policy can be compared with predictions.
- Eg: Have the predictions for Bob's study come true when combining his data with Alice's experiment? Why?
- C-JUST-UR4: As much as possible of the above processes should be automated, to reduce effort and ensure compliance with regulations.
- C-Entail-UR 1 : Decide the trustworthiness of a reasoning process or a materialized view.
- C-Entail-UR 7: Identify the transformation pattern used to derive conclusions.
- Eg: How was patient classification obtained?
- Eg: Which decisions has Bob taken to obtain the results his diagnosis?
- C-Entail-UR 8: Identify the date and time of the derivation
- C-Entail-UR 9: Identify any input information directly and indirectly used to derive conclusions
- Management
- M-Acc-UR 2: Given a set of provenance information, the user must be able to determine the source and authority of the provenance author
- M-Acc-UR 4: Provide a way for stable provenance information to survive deidentification processes without endangering privacy.
- M-Diss-UR 1: Verify that data, disseminated to some entity for processing, was processed for a purpose which was valid under some generally applied rules of validity, or as stated by the entity upon requesting the data.
- M-Diss-UR 4: Check which uses of some data are affected by a change in that data, including those of remote, independent users who copied the data long before the change.
- Eg: Would a change in Alice's dataset affect the result obtained in Bob's diagnosis?
- Use
- U-Under-UR 3: Be able to provide Subject Matter Experts (SMEs) with explanations of the rationale behind a certain outcome (domain)
- U-Under-UR4: Enable users to approach the provenance graph at different levels of detail, e.g. enabling understanding for users of different levels of expertise, ranging from novice to expert (granularity).
- Eg: For a novice user, Bob's study might show 3 different steps. For an expert user, the experiment could decompose one of those steps in another 4 specific and detailed steps.
- U-Inter-UR 1 Enable users/systems to merge metadata about a same "entity" according to its attribution/provenance
- U-Inter-UR2: (Chained provenance) Enable users/systems to trace back the origin of an "entity" whose ancestors have been produced/generated by different systems.
- U-Inter-UR 5: Facilitate data sharing through interoperability of the associated provenance information.
- Eg:Did the epidemiological study include data from the northern regions after May?
- U-Comp-UR 1: Enable users to determine the similarities and differences between past processes or events
- U-Tru-UR 1: Enable users to assess the trustworthiness of Web data.
- U-Imper-UR 1: Allow users to access provenance information even if it cannot be directly observed.
Technical Requirements for Disease Outbreak Scenario
List the general technical requirements (a subset of those in the list gathered here) which are required to fulfill the user requirements listed above specifically for the Disease Outbreak Scenario.
- Content
- C-Attr-TR 1.1: The notion of contributor ID should be fixed to have data provider identity disambiguated.
- Eg. Distinguish between authors 1 and 2, which have contributed to the creation of 2 different datasets.
- C-Attr-TR 2.1: There should be a notion of "creator of data" (in which cases user can be considered a creator of a piece of data and in which cases only collaborator).
- C-Attr-TR 2.2: There should be a schema which will lead user to fulfill requirements for correct management of provenance metadata (proper insertion/modifications of data creators and collaborators).
- C-Attr-TR 2.3: A system should track which portions of a document were produced by an entity.
- C-Proc-TR1.1: The provenance metamodel used should be expressive enough to support reasoning capabilities about agents and subprocesses.
- Eg: Which agents were involved in the patient classification to obtain Alice's final dataset?
- Eg: Which processes and subprocesses have been executed in Bob's diagnosis?
- C-Proc-TR3.1: The provenance metamodel should be rich enough in terms of process description to identify the key features of a process.
- Eg: When did Bob start his diagnosis?
- Eg: Which databases did Bob use for his diagnosis?
- C-Proc-TR3.2: It should be possible to revert provenance graphs into enactable process models.
- C-Proc-TR 5.1: Libraries of domain-independent overlays could be (re)used that describe processes at different levels of detail so that provenance graphs can be matched against them.
- C-Proc-TR 5.2: It should be possible to group the entities present on a provenance graph according to different criteria like proximity, sequence of subprocess, etc.
- Eg: Which processes took place before step 3 in Bob's research?
- Eg: Which processes have compatible inputs or outputs?
- C-Vers-TR 1.1: A system should keep track of the different versions of a published document, or piece of information.
- C-Vers-TR 1.2: A system should keep track of what entity makes changes to the document
- C-JUST-TR3.1: The data and supporting information should be archived securely in a stable long-term preservation format
- C-JUST-TR3.2: Changes to the source data or justification over time need to be recorded to keep the records consistent (C-VERS-*, M-DISS-UR4)
- C-JUST-TR4.1: The "correct" behavior of unsupervised justification behavior (for individual or networked systems) need to be specified and agreed with regulatory agencies
- Need to know which specification is used as “correct” to determine the experiment. Are there many “correct” specifications?
- C-JUST-TR4.4: Standards for exchanging justified, or provenance-carrying data should support collaboration among many users or systems (CF U-INTER-UR-2, U-INTER-UR-4, U-INTER-UR-5)
- C-Entail-TR1.1 record the provenance of data at a coarse and fine granularity levels. In the context of RDF, recording the provenance at a fine granularity level amounts to recording the provenance of a single triple, whereas recording the provenance at a coarse granularity level accounts to recording the provenance of a collection of RDF triples.
- C-Entail-TR 1.2 provenance model for the SPARQL language: determine the provenance of the result of a SPARQL query.
- C-Entail-TR 7.1: For conclusion that is data, the algorithm, heuristic used
- C-Entail-TR 8.1: Annotate the date and time of the derivation
- C-Entail-TR 9.1: Identify Parameters directly and indirectly used to derive conclusions
- C-Entail-TR 9.2: Identify Assumptions directly and indirectly used to derive conclusions
- C-Entail-TR 9.3: Identify Hypotheses directly and indirectly used to derive conclusions
- C-Entail-TR 9.4: Identify Other conclusions directly and indirectly used to derive conclusions
- C-Attr-TR 1.1: The notion of contributor ID should be fixed to have data provider identity disambiguated.
- Management
- M-Acc-TR 1.1: Applications should be able to use provenance to identify the authors and sources of data.
- M-Diss-TR 1.1: Provenance should make it possible to determine whether experimental or survey results are suitable for a given kind of reprocessing or repurposing.
- M-Diss-TR 4.1: Provenance should link data and physical artifacts (e.g. experimental samples) to the data from which they are derived.
- Use
- U-Under-TR 3.1: It should be possible to match a provenance graph against pre-existing high-level, domain-independent representations of candidate reasoning types.
- U-Under-TR3.2: Such templates, or overlays, should be rich enough and abundant enough to cover the majority of the possible reasoning behaviours for a given domain and task.
- U-Under-TR4.1: The reasoning structures used to provide the explanations mentioned in UR 3 should be represented at different levels of granularity
- U-Under-TR4.2: It should be possible to transit between the different levels of granularity of the overlays, being such transitions semantically described.
- Eg: Which steps would Bob's research display have if I’m a novice user? What if I demand a more detailed explanation of each step?
- U-Inter-TR 1.1: Provide the means to query provenance of an "entity" (in the rdf context, "entity" to be understood as resource or statement!)
- U-Inter-TR 1.1.1: query should be able to identify specific "aspects" of provenance, such as attribution, source characteristics, etc), hence some form of "filtering" required.
- Eg: Which are the processes derived from Alice's patient classification that took place before date January 31th?
- U-Inter-TR 1.1.2: query should be able to scope provenance (how far back to we go into the history). Note this was not specific in the use case but was discussed in Miles' requirements paper (http://eprints.ecs.soton.ac.uk/11189/)
- Eg: Which are the processes derived from Alice's patient classification that took place before date January 31th and belong to this experiment?
- U-Inter-TR 1.1.1: query should be able to identify specific "aspects" of provenance, such as attribution, source characteristics, etc), hence some form of "filtering" required.
- U-Inter-TR 1.2: Given a document, image, file, etc, provide the means to obtain its provenance
- U-Inter-TR 1.2.1: Find an authoritative provenance service to retrieve its provenance
- U-Inter-TR 1.3: Given a resource and some provenance, provide the means to verify that the provenance is the one of that resource.
- Eg: Is Alice's patient classification dataset compatible with the input for Bob's research?
- Eg: Does conclusion321 belong to Bob's research?
- U-Inter-TR 2.1: Provide a common representation of provenance offering a technology-independent description of how an entity was derived
- U-Inter-TR 2.1.1: Provide a computer parseable notation for provenance
- U-Inter-TR 2.1.2: Provide a user-oriented notation for provenance.e.g. graphical notation
- U-Inter-TR 2.2: Provide a mechanism to integrate part of a history in system x and part of history in system y.
- U-Inter-TR 2.2.1: Provide the means to automatically propagate provenance information as data is exchanged between systems
- U-Inter-TR 5.1: Provenance models to ensure conceptual clarity of provenance terms
- U-Inter-TR 5.2: Ensure consistent use of provenance terms to reduce terminological heterogeneity (for example, naming conflict and data unit conflicts)
- U-Inter-TR 5.3: Allow representation of domain-specific provenance details while ensuring provenance interoperability
- U-Comp-TR 1.1: Allow records of past processes to be represented in such a way as to be able to compare their parts
- U-Comp-TR 1.2: Provide a means for two processes or parts of processes to be treated as comparable (about the same thing), either by manual assertion or automatic deduction
- U-Comp-TR 1.3: Provide a mechanism to take two comparable processes and produce a helpful explanation of their similarities and differences
- U-Tru-TR 1.1: Allow applications to associate source information with aggregated data.
- U-Tru-TR 1.2: Applications should be able to use source information to compute trust associated with data.
- U-Tru-TR 1.3: Allow versions of trust to reflect different versions of source information (used to compute trust).
- U-Tru-TR 1.4: Applications should be able to deal with missing provenance information
- U-Imper-TR 1.1: Allow applications to assert provenance with a degree of uncertainty
- U-Imper-TR 1.2: Allow applications to infer dependence/causation with a degree of uncertainty.
- Eg: Patient classification depends on Data.gov and NeISS resources. The system infers that it may depend too on Data.gov.uk resources (60% sure)
- U-Imper-TR 1.3: Require asserter to be identified, and the nature of assertion to be specified (guess, inference, ...)
- U-Imper-TR 1.2: Allow applications to infer dependence/causation with a degree of uncertainty.
Diagrams
This is where we identify components/aspects of a provenance solution to the scenario, and how technical requirements for the scenario are illustrated in three diagrams.
File:UseCase2-DiseaseOutbreak.pdf
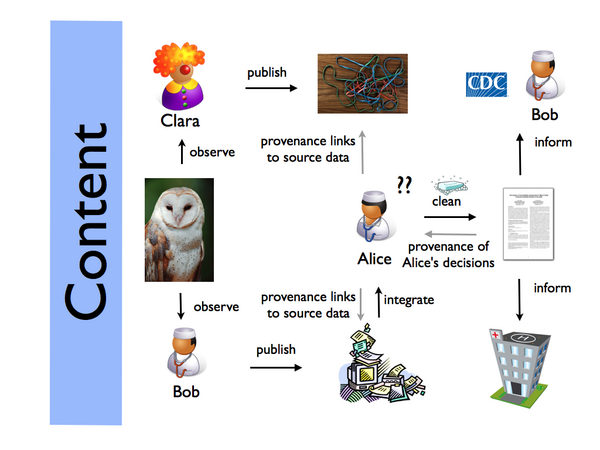
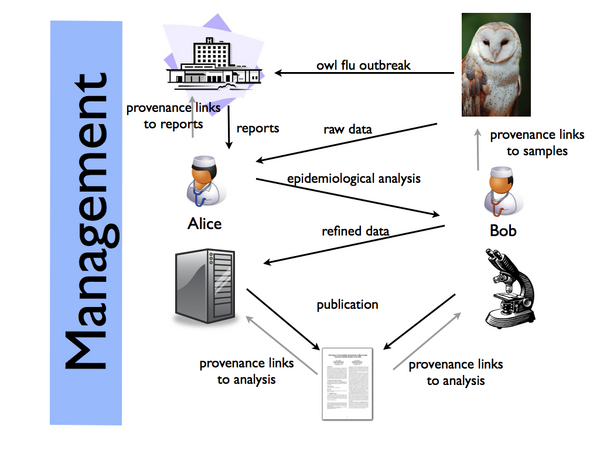
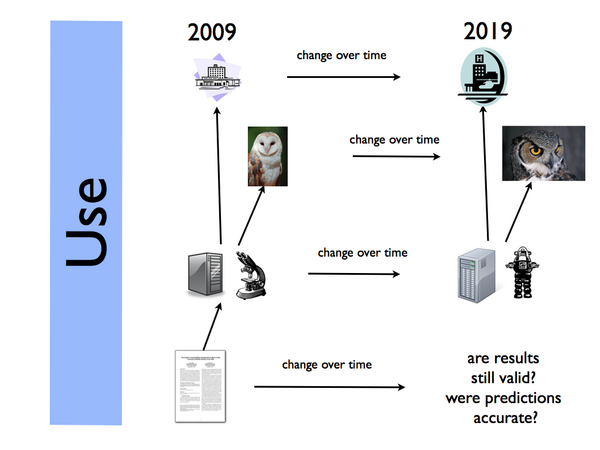
Relevant State of the Art
Here we describe the research conducted in relation to, and the technology available to fulfill, the above described requirements with specific regard to this scenario.
Here is a summary of related work across scenarios.
Existing Solutions Used Today for Disease Outbreak Scenario
Today, most data sharing is labor-intensive, and any provenance records are either produced by hand (i.e. by scientists filling in data entry forms on submission to a data archive or repository), produced by ad hoc applications developed specifically for a given kind of data, or not produced at all.
Within curated biological databases (including large examples such as UniProt, Ensembl, or the Gene Ontology, with tens or hundreds of curators, as well as many smaller databases), provenance is often recorded manually in the form of human-readable change logs. Some scientists are starting to use wikis to build community databases.
There has been a stream of research on provenance in databases but so far little of it has been transferred into practice, in part because most such proposals are difficult to implement, and often involve making changes to the core database system and query language behavior. Such techniques have not yet matured to the point where they are supported by existing database systems or vendors, which limits their accessibility to non-researchers.
On the other hand, a number of workflow management systems (e.g. Taverna, Pegasus) and Semantic Web systems (Inference Web) have been developed and are in active use by communities of scientists. Many of these systems implement some form of provenance tracking internally, and have begun to standardize on one of a few common representations for the provenance data, such as OPM or PML. Moreover, research on storing and querying such data effectively (e.g. ZOOM) has easily be transferred to practice since it relies only on standard systems.
Current Provenance Research Relevant to the Scenario
This section is a partial overview of representative work in this area. The bibliography contains over 50 papers tagged as relevant to this scenario. We focus on surveys and key papers that introduced new ideas or concluded a line of research, not incremental steps that, while also important, are of less interest to readers outside the provenance reserach community.
Content
Object
There appear to be two basic approaches to describing the objects to which provenance records refer: a "coarse-grained" approach which assigns atomic identifiers (e.g. URLs) to data objects (with no containment relationships) and a "fine-grained" approach in which objects may be at multiple levels in a containment hierarchy, and identifiers explicitly reflect this. The Open Provenance Model (Moreau et al. 2010) and most of the provenance vocabularies studied in Provenance_Vocabulary_Mappings adopt the coarse-grained model, while much work on provenance in databases (Buneman 2006) (and increasingly some in workflows and other settings) adopts the fine-grained model.
The difference between coarse- and fine-grained identification of objects is not really a difference in kind, but one of emphasis: coarse-grained object identifiers can of course be used to simulate fine-grained collections; the issue is really whether the identifiers have a standard, transparent structure, or are ad hoc. Thus, the two models can probably be reconciled.
Attribution
Attribution is important for making data citable and helping ensure that creators or cleaners of data receive credit to offset the extra effort required to publish data. URLs do not necessarily provide adequate attribution since they are not considered stable citations. Initiatives such as PURL and DOI have addressed this to some extent, but still only allow for references to whole Web resources, and the targets of URLs may change over time. There are some proposals for fine-grained citation of data in databases (Buneman 2006) and for versioning (Memento, Van de Sompel et al. 2010) that can begin to address this (see Versioning/Evolution below). Bleiholder and Naumann discuss the issue of attribution in the context of data fusion or data integration, where it is also important to be able to track data to its source in order to understand errors or anomalies.
Process
Much of the focus of work on provenance in workflows and distributed systems has been recording processing steps, the precise parameters used, and any other metadata considered important for ensuring repeatability of electronic "experiments". There is a great deal of work in this area, particularly in scientific workflows, high-performance computing and eScience (Oinn et al. 2004,Simmhan et al. 2005, Sahoo et al. 2008, Bose et al. 2005), including many early systems that initially adopted ad hoc formats and strategies for recording provenance. The Open Provenance Model, Proof Markup Language, and other provenance vocabularies represent progress towards a uniform representation for this kind of process provenance. However, although these standards specify a common data format that can be used to represent a wide variety of kinds of processes, they can still represent the same process in many different ways. Thus, further work needs to be done on top of these efforts (possibly by domain experts) to ensure that provenance produced by different systems is compatible and coherent. Another important, and ill-understood, problem is how to relate the provenance information that is recorded with the "actual" behavior of a system; that is, how to ensure that such provenance is "correct" in some sense besides the trivial fact that it is what the implementation happened to record.
Versioning/Evolution
Provenance is relevant to versioning and evolution of Web resources and data, in several ways. First, the version history of a resource itself can be considered part of its provenance (often an important part). Second, provenance records are often about data that is static in the short term during which results are produced, but changes in the long term. Third, descriptions of the change history of an object can be used to reconcile differences between replicated data or propagate updates among databases that share data on the basis of conditional trust relationships.
Version history provenance is seldom recorded and there is no standard way of doing so. For example, curated databases in bioinformatics record provenance showing who has made changes to each part of the data (often by manual effort); Buneman et al. 2006 study techniques for automating this kind of provenance tracking. Efforts such as the Internet Archive to take "snapshots" of the Web for the benefit of posterity have attempted to provide a partial, coarse-grained historic record for the Web. The Memento project (Van de Sompel et al. 2010) is an effort to extend HTTP with a standard way to access past versions of a Web resource. Neither provides detailed provenance explaining how the different versions are related, but a versioning infrastructure such as Memento could add value to provenance by making it possible to retrieve contemporaneous versions of past data referenced within provenance records. The ORCHESTRA system (Green et al. 2007) provides update exchange among relational databases based on schema mappings and provenance, which can be used to undo updates if trust policies change.
Entailment
Many forms of provenance describe processes that can be characterized as logical inferences (e.g., database queries and queries over RDF data or ontologies can all be understood as deduction in various flavors of first-order or description logic). Thus, work on provenance has often focused on describing the entailment relationships linking assumptions to conclusions. Some early models of provenance, such as Cui et al. (2000)'s "lineage" and Buneman et al. 2001's "why-provenance", were indirectly based on the idea of a "witness", or a (small) subset of the facts in the database that suffice to guarantee the existence of a result fact. Green et al. (2007) generalize these ideas to a model that also allows distinguishing between different "proofs", in the form of algebraic expressions. Work on knowledge provenance and Proof Markup Language appear to be based on essentially the same idea, but make an explicit link between provenance and deductive proofs more explicit ([Pinheiro da Silva et al. 2003]), and permit greater reflection on the structure of such proofs.
Justification
An important goal for provenance in this scenario is to show the connection between evidence, processes used to reach decisions, and conclusions, first as a quality-control measure prior to publication or policy changes Wong et al., and second for review after-the-fact. Achieving this requires all of the previous components, and also requires developing an understanding of what it means for provenance to "justify" or "prove" a conclusion. In some settings, such as deduction over Web data (Pinheiro da Silva et al. 2008) it may be enough to provide the raw data and lightweight descriptions of processes used in enough detail that it can be rerun; in others, it might be required to document that the conclusions were tested in a number of different ways, or to identify all possible parts of the input on which a given part of the output "depends" (Cheney et al. 2007).
Management
Publication, Access, and Dissemination
Hartig 2009 specifically discusses publication, accessibility and dissemination of Web data provenance, based on standard technologies such as RDF, and outlines some open questions, particularly the issues of ambiguity of provenance vocabularies and the absence of provenance information for most data on the Web. This suggests that standards for documenting the kind of provenance information exchanged in this scenario need to be developed and evaluated carefully to ensure they are unambiguous and easy-to-use, or that provenance can be generated and exchanged automatically.
Scale
Work on provenance in database and workflow systems has addressed issues of scale. Buneman et al. 2006 investigated querying and compaction for provenance records in curated databases. Chapman et al. 2008 investigate compression for workflow provenance records which dwarf the size of the underlying data. Heinis and Alonso 2008 study the problem of performing graph queries efficiently over typical workflow provenance graphs.
Use
Understandability
An important goal of provenance records in the disease outbreak scenario is to promote understanding, both between peers or specialists with detailed knowledge of different areas (e.g. epidemiologist Alice and biochemist Bob), and between nonspecialist decision-makers and experts. There is also a great deal of work on visualizing provenance as graphs (e.g. Cheung and Hunter 2006, among many others). Some of this work has focused on providing high-level "user views" of workflow provenance graphs, allowing users to select which parts of the graph they are interested in (Biton et al. 2008). Machine learning and inference techniques may be useful for automatically identifying important or influential steps in provenance graphs (Gomez-Rodrigues et al. 2010).
Interoperability
Interoperability issues involving provenance have mostly been addressed through the development of common data models for provenance records. These range from fields concerning authorship in metadata standards such as Dublin Core, to vocabularies for complex graph data structures to represent provenance of processes, such as PML (Pinheiro da Silva et al. 2006) or OPM (Moreau et al. 2010). These proposals typically describe (the provenance of) static data, whereas provenance management in this scenario also requires relating dynamic data, both over the short term (when changes may be very frequent) and long term (when data may be dormant and perhaps subject to degradation or preservation failure). This appears likely to raise a number of interoperability issues, including some (such as standard citation and versioning infrastructure) that are somewhat independence of provenance and may be of general interest.
Comparison
Obviously, once we have provenance records in a common format, they can be compared using a variety of techniques (e.g. string, tree or graph variants of differencing algorithms). However, it is not clear how well existing off-the-shelf algorithms meet the needs of scientific users. Miles et al. 2006 and Bao et al. 2009 present initial steps in understanding the requirements and practical issues in comparing provenance.
Accountability
In the Disease Outbreak Scenario, provenance promotes accountability by making explicit the authors, sources, and computational steps, inference steps, and choices made to reach a conclusion. (Edwards et al. 2009) gives an overview of the social science research requirements for accountability and policy assessment, together with a discussion of how automatic provenance recording and management can better support accountability.
Trust
Issues of trust are discussed in Stead et al., Missier et al. (SIGMOD 2007), and Aldeco-Perez and Moreau (VCS 2008). Artz and Gil (J. Web Sem. 2007) also gives a survey of trust in computer science and the semantic web. Trust is widely described as a motivation for recording provenance. Many approaches model trust as Boolean or probability annotations that are propagated in various ways, for example using Boolean conjunction or disjunction or probabilistic operations to propagate trust annotations on raw data to trust annotations on results.
Imperfections
Provenance records, like all electronic data, are subject to loss, degradation, or corruption. This means that the provenance records may be misleading or incomplete. If provenance is used to make important decisions, then attackers can influence these decisions by falsifying provenance. Some work on security for provenance addresses this using standard cryptographic signing techniques (Hasan et al. 2009). In the database community, some recent work has investigated the problem of inferring provenance for data for which the source has been lost (Zhang and Jagadish 2010).
Debugging
Provenance records can be used to debug complex processes or clean dirty data. Differencing techniques (Bao et al. 2009), for example, can help clarify whether an anomalous result is due to errors in the source data, incorrect processing steps, or transient hardware or software failure. Techniques based on entailment analysis or dependency-tracking (Cheney et al. 2007) can also address similar issues, by highlighting data that contributed (or excluding data that did not contribute) to a selected part of the result. These techniques are closely related to debugging techniques such as program slicing and to security techniques such as information flow analysis.
References
- Aldeco-Pérez, R. & Moreau, L. Provenance-based Auditing of Private Data Use. International Academic Research Conference, Visions of Computer Science, 2008
- Artz D, Gil Y. A survey of trust in computer science and the Semantic Web. J. Web Sem. 2007;5(2):58-71.
- Bao Z, Davidson SB, Cohen-Boulakia S, Eyal A, Khanna S. Differencing Provenance in Scientific Workflows. In: Procs. ICDE.; 2009.
- Biton O, Davidson SB, Boulakia SC, Hara CS. Querying and Managing Provenance through User Views in Scientific Workflows. Procs. ICDE. 2008:1072-1081.
- Bleiholder J, Naumann F. Data fusion. ACM Computing Surveys. 2008;41(1):1-41.
- Bose R, Frew J. Lineage retrieval for scientific data processing: a survey. ACM Comput. Surv. 2005;37(1):1--28.
- Buneman P. How to cite curated databases and how to make them citable. In: Proceedings of the 18th International Conference on Scientific and Statistical Database Management.; 2006:195-203.
- Buneman P, Chapman A, Cheney J. Provenance management in curated databases. In: SIGMOD Conference.; 2006:539-550.
- Buneman P, Khanna S, Tan WC. Why and Where: A Characterization of Data Provenance. In: ICDT.; 2001:316-330.
- Chapman A, Jagadish HV, Ramanan P. Efficient provenance storage. In: SIGMOD Conference.; 2008:993-1006.
- Cheney J, Ahmed A, Acar UA. Provenance as dependency analysis. In: Arenas M, Schwartzbach M Proceedings of the 11th International Symposium on Database Programming Languages (DBPL 2007). Springer-Verlag; 2007:138-152.
- Cheung K, Hunter J. Provenance Explorer: Customized Provenance Views Using Semantic Inferencing. In: Procs. ISWC 2006.; 2006:215 - 227.
- Cui Y, Widom J, Wiener J. Tracing the lineage of view data in a warehousing environment. ACM Transactions on Database Systems. 2000;25:179-227.
- Edwards P, Farrington J, Mellish C, Philip L, Chorley A. e-Social Science and Evidence-Based Policy Assessment. Social Science Computer Review. 2009;27:553-568.
- Gomez-Rodriguez M, Leskovec J, Krause A. Inferring Networks of Diffusion and Influence. In: Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2010:1019-1028.
- Green TJ, Karvounarakis G, Tannen V, Ives ZG. Update Exchange with Mappings and Provenance. In: VLDB. 2007.
- Hartig O. Provenance Information in the Web of Data. In: Proceedings of the Linked Data on the Web (LDOW) Workshop at WWW. Madrid, Spain; 2009.
- Hasan R, Sion R, Winslett M. The Case of the Fake Picasso: Preventing History Forgery with Secure Provenance. In: FAST.; 2009:1-14.
- Heinis T, Alonso G. Efficient Lineage Tracking For Scientific Workflows. In: Proceedings of the 2008 ACM SIGMOD conference.; 2008:1007-1018.
- Miles S, Groth P, Branco M, Moreau L. The Requirements of Using Provenance in e-Science Experiments. Journal of Grid Computing. 2006;5(1):1-25.
- P. Missier, S.M. Embury, R.M. Greenwood, A.D. Preece, and B. Jin, "Managing information quality in e-science: the Qurator workbench," SIGMOD '07: Proceedings of the 2007 ACM SIGMOD international conference on Management of data, New York, NY, USA: ACM, 2007, pp. 1150-1152.
- Moreau L, Clifford B, Freire J, et al. The open provenance model core specification (v1.1). Future Generation Computer Systems. 2010.
- Oinn T, Addis M, Ferris J, et al. Taverna: a tool for the composition and enactment of bioinformatics workflows. Bioinformatics (Oxford, England). 2004;20(17):3045-54.
- Pinheiro Da Silva P, McGuinness DL, Del Rio N, Ding L. Inference Web in Action: Lightweight Use of the Proof Markup Language. In: International Semantic Web Conference.; 2008.
- Pinheiro Da Silva P, McGuinness DL, Fikes R. A Proof Markup Language for Semantic Web Services. Information Systems. 2006;31(4-5):381-395.
- Pinheiro Da Silva P, McGuinness DL, McCool R. Knowledge Provenance Infrastructure. IEEE Data Engineering Bulletin. 2003;25(2):179-227.
- Sahoo S., Sheth A., Henson C. Semantic Provenance for eScience: ‘Meaningful’ Metadata to Manage the Deluge of Scientific Data, IEEE Internet Computing, 2008.
- Simmhan Y, Plale B, Gannon D. A survey of data provenance in e-science. SIGMOD Record. 2005;34:31-36.
- D. Stead, N. Paton, P. Missier, S. Embury, C. Hedeler, B. Jin, A. Brown, and A. Preece, "Information Quality in Proteomics," Briefings in Bioinformatics, vol. 9, 2008, pp. 174-188.
- Van de Sompel H, Sanderson R, Nelson ML, et al. An HTTP-Based Versioning Mechanism for Linked Data. In: 2010 Workshop on Linked Data on the Web.
- Wong SC, Miles S, Fang W, Groth P, Moreau L. Provenance-Based Validation of E-Science Experiments. In: Procs. ISWC.; 2005:801-815.
- Zhang J, Jagadish HV. Lost source provenance. In: ACM International Conference Proceeding Series; Vol. 426.; 2010:311-322.
Gap Analysis
This scenario is data-centric, and there is currently a large gap between ideas that have been explored in research and techniques that have been adopted in practice, particularly for provenance in databases. This is an important problem that already imposes a high cost on curators and users, because provenance needs to be added by hand and then interpreted by human effort, rather than being created, maintained, and queried automatically. However, there are several major obstacles to automation, including the heterogeneity of systems that need to communicate with each other to maintain provenance, and the difficulty of implementing provenance-tracking efficiently within classical relational databases. Thus, further research is needed to validate practical techniques before this gap can be addressed.
In the workflow provenance (e.g. Taverna, Pegasus, ZOOM etc.) and Semantic Web systems (Inferece Web) area, provenance techniques are closer to maturity, in part because the technical problems are less daunting because the information is coarser-grained, typpically describing larger computation steps rather than individual data items, and focusing on computations from immutable raw data rather than versioning and data evolution. There is already some consensus on graph-based data models for exchanging provenance information, and this technology gap can probably be addressed by a focused standardization effort.
Guidance to users about how to publish provenance at different granularity is also very important, for example whether publishing the provenance of an individual object or a collection of objects. Users need to know how to use different existing provenance vocabularies to express such different types of provenance and what the consequence will be, for example, how people will use this information and what information is needed to make it useful.
Although there are many proposed approaches and technology solutions that are relevant, there are several major technology gaps to realizing the Disease Outbreak scenario. Organized by our major provenance dimensions, they are:
- With respect to content:
- No mechanism to refer to the identity/derivation of an information object as it is published and reused on the Web
- No guidance on what level of granularity should be used in describing provenance of complex objects
- No common standard for exposing and expressing provenance information that captures processes as well as the other content dimensions
- No guidance on publishing provenance updates
- No standard techniques for versioning and expressing provenance relationships linking versions of data
- With respect to management:
- No well-defined standard for linking provenance between sites
- No guidance for how existing standards can be put together to provide provenance (e.g. linking to identity).
- No guidance for how application developers should go about exposing provenance in their web systems.
- No proven approaches to manage the scale of the provenance records to be recorded and processed,
- No standard mechanisms to find and access provenance information for each item that needs to be checked,
- With respect to use:
- No clear understanding of how to relate provenance at different levels of abstraction, or automatically extract high-level summaries of provenance from detailed records.
- No general solutions to understand provenance published on the Web
- No standard representations that support integration of provenance across different sources
- No standard representations that support comparison across scientific analysis results
- No broadly applicable approaches for dealing with imperfections in provenance,
- No broadly applicable methodology for making trust judgments based on provenance when there is varying information quality.