By Thomas Roessler (W3C), Giles Hogben (JRC), Marco Casassa Mont (HP Labs), Siani Pearson (HP Labs).
The work of the authors is supported by the PRIME project. The project receives research funding from the European Community's Sixth Framework Programme and the Swiss Federal Office for Education and Science.
The overall use case that motivates this position paper is a privacy-enabled identity management system using semantic web technologies. By this, we mean a system that uses a set of RDF-based languages to
In discussing rule use cases and requirements, this position paper focuses on those requirements that are characteristic to the privacy-enabled identity management problem.
Both preferences and policies can be cast in rule-like semantics, as both deal with conditions about what is acceptable, and what is not. In general two categories of rules are of relevance: inference rules and reactive rules.
Specifically, we want to make a case for reactive rules in the context of privacy management. ECA reactive rules (Event-Condition-Action rules) are required to express access control policies, assurance policies and obligation policies. As a significant example we consider privacy obligations. Privacy obligations fit the reactive rule pattern: they define data lifecycle management practices including supported handling policies and under what conditions certain actions have to be taken.
To further illustrate what we mean by a privacy-enabled identity management system, and where rules are useful in such a system, we sketch a walk-through of a negotiation process.
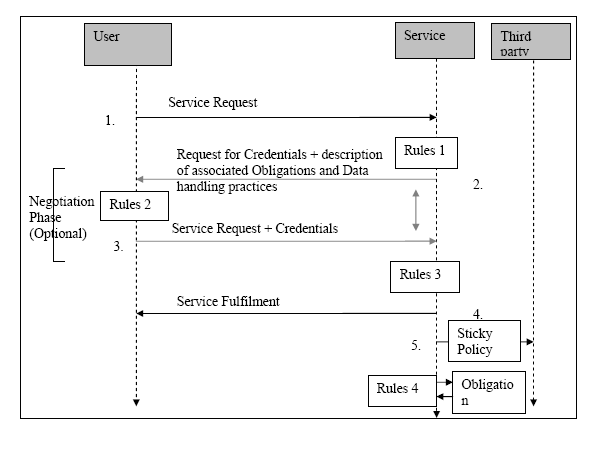
The following diagram represents a typical interaction within a privacy-enabled identity management system. It should be noted that the architecture is in fact symmetric between user and service side, as both have an access control system and both have to establish trust by proving assertions about themselves. However rule requirements are more simply illustrated by taking an asymmetric user-to-service instance of this architecture.
A basic interaction proceeds as follows (following the numbered steps on the diagram); for each step, we have given an implementation example:
The diagram shows the points in this process where rules are required. Note that several points in the process are symmetric between User and Service, hence the same kinds of rules would be used. This is explained below.
Motivations:
User-side preferences often express constraints: A transaction will not be continued, unlessthe constraints are fulfilled. Fulfilling the constraints, however, is not sufficient for the transaction to proceed. In logical terms, the semantics here are those of necessary conditions, not the ones of sufficient conditions. Such a check can be made on the client side prior to disclosing any personal information or during the negotiation process, and also on the service side after information has been disclosed (through expression of such constraints within access control policies and through the use of sticky preferences, analogous to the enforceable obligations example considered further below).
Examples of user-side preferences that are expressed as constraints include:
Another typical element of user preferences is to say which out of several possible choices is preferred: A user may, for instance, wish to express that among credentials that prove their age, the least privacy-invasive one is to be picked.
One way of framing this kind of preference is to write a set of rules with well-defined priorities.
Motivations
When a policy negotiation has lead to agreement between different parties on how personal information is to be handled, obligations arise. These obligations specify two kinds of behaviours:
In general, obligations can dictate a wide range of actions that need to be fulfilled by organisations on personal data, based on the occurrence of events. Relevant events might be based on: time, accesses to data, changes of contextual information, trust information, etc. Related actions might include:
Note that any actions that operate on instance data (such as deletion or transformation), or refer to it (such as notification actions) need a way to address individual triples in the data store.
In order to enable consistent enforcement of obligations, within and across organisational boundaries, instance data and related obligations must be associated together. These associations need to be preserved when data is transmitted i.e. they must be transmitted together.
Important requirements that need to be addressed are:
Simply using today's RDF reification and dropping obligations and instance data into the same graph would, however, break the requirement that obligations and instance data be handled differently according to their respective confidentiality needs.
Hence, besides the pure rule requirements, an additional requirement for future versions of RDF arises: References to individual triples and subgraphs, beyond the abilities of today's reification mechanisms.