John
C. Paolillo and Elijah
Wright
School of Library and Information Science, Indiana University, Bloomington
The FOAF ("Friend of a Friend") project is described as a "practical experiment" in the application of RDF and Semantic Web technologies to social networking. Under this experiment, FOAF files have become widespread, and now form the backbone social metadata of sites such as PeopleLink and LiveJournal. Essential to any experiment is a phase in which the experiment's results are evaluated in an objective fashion. While a "practical experiment" does not submit to the same kind of evaluation as a true experiment (the phrase suggests a meaning similar to "practical joke" [1]), it nonetheless invites evaluation in the same mode as that of another practical experiment, namely the World-Wide Web.
Like the W3C Web Characterization Project, the aim of FOAF characterization would be to investigate the use of FOAF/RDF markup in order to ascertain how its current design fits the purposes for which it is used. On the technical level, we may be interested in noting the relative incidence of namespaces in FOAF files (foaf, rdf, rdfs and alternate namespaces), different vocabulary items (incidence of foaf:knows, foaf:name and other items), parsing errors, etc. Such information would be a useful guide to developers of FOAF tools, protocols and applications.
On the level of the application itself, we might like to know more about how FOAF is being used, and the social space defined by the files that make up the FOAF-sphere. How connected are different people's FOAF files, and what sort of social environment do they define? Are they densely interconnected in a large network of strong ties , or are they more loosely connected via weak-ties (cf. Granovetter 1973, 2003)? Or is there a clumping of social relations into recognizable groups? To what extent do the social groups that form reflect technological barriers, such as the (lack of) ability to interchange social data among connected sites? To what extent do peoples' encoded FOAF relations reflect affiliations they have in other arenas, such as IRC, Instant Messaging and the "real world"? How do these relationships evolve, and to what extent does that evolution reflect the spread of technological innovation, or other yet unknown factors? Answers to these questions potentially benefit our most basic understandings of human sociability and the use we make of it, as well as the design of technical systems for social networking. All of these questions fall squarely in the domain of social network analysis, and require analysis of the FOAF graph to be answered.
This paper reports on our efforts to date to conduct an evaluation of FOAF that would begin to answer these questions, but especially the latter set of socially-oriented questions. We adopt the perspective of social scientists interested in the interaction of social patterns and technological systems ("Social Informatics", Kling 1999), who want to understand the effects of networked communications technologies on the quality of social life. Our approach focuses on the quantitative characterization of a corpus of FOAF files collected by another individual in the course of a social computing project. We report here on the challenges, technical, methodological and ethical, facing researchers who undertake projects such as ours.
This paper is organized as follows. The present section, Section 1, comprises the introduction. Section 2 addresses the issue of sampling and its resolution in our current study. Section 3 describes the size of the database of FOAF information obtained, and the problems of working with it in extracting useful information of a general sort. Section 4 addresses issues of data quality, and the differing semantics of FOAF and other markup as it is used in practice. Section 5 presents the preliminary results of our social network analysis, and the technical and methodological challenges it faces. Section 6 raises the issues of ethical concern that arise in conducting our analysis. We conclude in Section 7 with some general recommendations for FOAF use and characterization.
Because FOAF data is distributed rather than centralized, data collection is somewhat challenging. Several individuals within the Semantic Web community operate what are known as 'scutters' - essentially web spiders that collect semantic web data. A scutter's main mode of operation is a recursive traversal of FOAF files by following links that are contained in FOAF files it already knows. The scutter is generally bootstrapped with a list of known files, and it typically follows a breadth-first traversal strategy while maintaining a store of sites it has already visited.
The first problem with this strategy of collecting FOAF data is that it is never clear whether the data sample is representative of FOAF more generally. By starting with a set of known nodes, and traversing the universe of users as a network, one only obtains a "snowball sample" -- a necessarily biased sample of data, because of the strong preference to obtain data from nodes already close to the ones already obtained. If there are accidentally or deliberately unconnected components of the FOAF network, these will never be discovered by traversal of any kind. Since some of the questions about FOAF use concern the extent and topology of the inter-connectedness of the FOAF graph, scutter methodologies are necessarily inadequate.
The same problem exists of course for Web characterization, more generally. Web crawlers most often find new content by following links in the content that is already cached. A couple of factors mitigate this problem, however. First, the Web has been growing for onwards of ten years, and so a large number of erstwhile unconnected sites have been absorbed into the main components of the Web. Second, deliberately unconnected sites such as corporate intranets and extranets, are generally not of much interest in characterizing the public web, which is now a coherent object of study in its own right. And third, public websites are generally accessed through a standard IP port, so true random sampling of Web hosts can be undertaken if a random sampling is required (Lavoie, et al. 1998, 2002).
These things are not true of the FOAF-sphere: FOAF is a relatively young form of markup which has not seen the same scale of global interest and use as the Web. The existence of unconnected components of FOAF data is a real concern, and one that matters in gauging the success of the technology. Deliberately unconnected FOAF-spheres, should they be discovered, would require social interpretation. Are there distinct FOAF-spheres for distinct social activities, such as work and socializing, or different FOAF-spheres based on region, class, or other social affiliations? The distinction between the public Web and private or corporate intranets is much like the former distinction; the development of distinctions along the latter lines is potentially new, and would require careful documentation. Finally, FOAF files are not shared over a common IP port. Consequently it is not possible to randomly sample the Web for FOAF files, as one can do, entirely without fore-knowledge for the Web.
There is to our knowledge no resolution to these problems. Hence our strategy is to focus our attention on a scutter dump, but keeping mindful of low-connected or isolated components that we have no access to in our interpretation. In addition, we are actively looking for signs of "clumping" in the social network graph that may alert us to similar social divisions in the data.
For this study, we obtained a scutter dump collected by Jim Ley [jibbering.com], available as either 700+MB of cached RDF files, or nearly 1GB as a MySQL database dump of RDF triples plus indices. The URLs were harvested between March 3 and March 7, 2004. We obtained both the raw RDF data and the database, which was modified for import into PostgreSQL. The dump consists of two main tables (other empty tables exist that are used by the scutter in processing the data). The first of these, urlsnew, is a list of all of the URLs of FOAF files obtained by the scutter, with information about the processing status of the file, the local cache name of the file, and a reference number used to identify the files that are the sources of individual triples. Table 1 summarizes the distribution of the 259298 number of records in this first table in terms of the operation of the scutter.
Table 1. Distribution of URLs in urlsnew table of the scutter dump.
LiveJournal |
LiveJournal |
Other |
Other |
|
Date |
Visited |
Not visited |
Visited |
Not visited |
March 3 |
663 |
0 |
1607 |
0 |
March 4 |
13940 |
121408 |
160 |
23 |
March 5 |
2810 |
17648 |
1279 |
130 |
March 6 |
11782 |
60844 |
0 |
6 |
March 7 |
4347 |
22650 |
0 |
1 |
The more-than ten-times-greater number of Live Journal sites that were visited in scuttering the FOAF data indicates the problems that can be created by a single large site in obtaining a representative sample of FOAF data. Some months ago, LiveJournal, a large weblog/social networking website began exposing its user data as FOAF. Currently LiveJournal boasts 3.8 million users with 15 thousand added daily. LiveJournal's organization, and its history of use before the user data was exposed as FOAF, led to its FOAF files containing URLs almost exclusively to LiveJournal members (crschmidt #foaf@irc.freenode.net, 2004-07-16): only two out of the 36 thousand LiveJournal FOAF files in our sample appear to be external FOAF files. Consequently, a large social networking site like LiveJournal is a kind of "black hole" for links, from which few links point outward. A selective strategy of prioritizing FOAF files from outside the large social networking sites is required to guarantee their representation in the sample. This fact has substantial social consequence, as it indicates the extent to which large social networking sites can effectively control their members' social capital. Truly free association is not possible if the representation of the social sphere is dictated by interests from outside the people they concern.
That said, the number of links outside of LiveJournal not yet visited is strikingly small. This suggests two possibilities. Either the 3042 visited links are relatively inter-connected, linking mostly to each other, or they tend to link to LiveJournal FOAF files, rather than those outside. Either possibility tells us something about the social landscape in which Ley's scutter began operating, although the precise interpretation is uncertain.
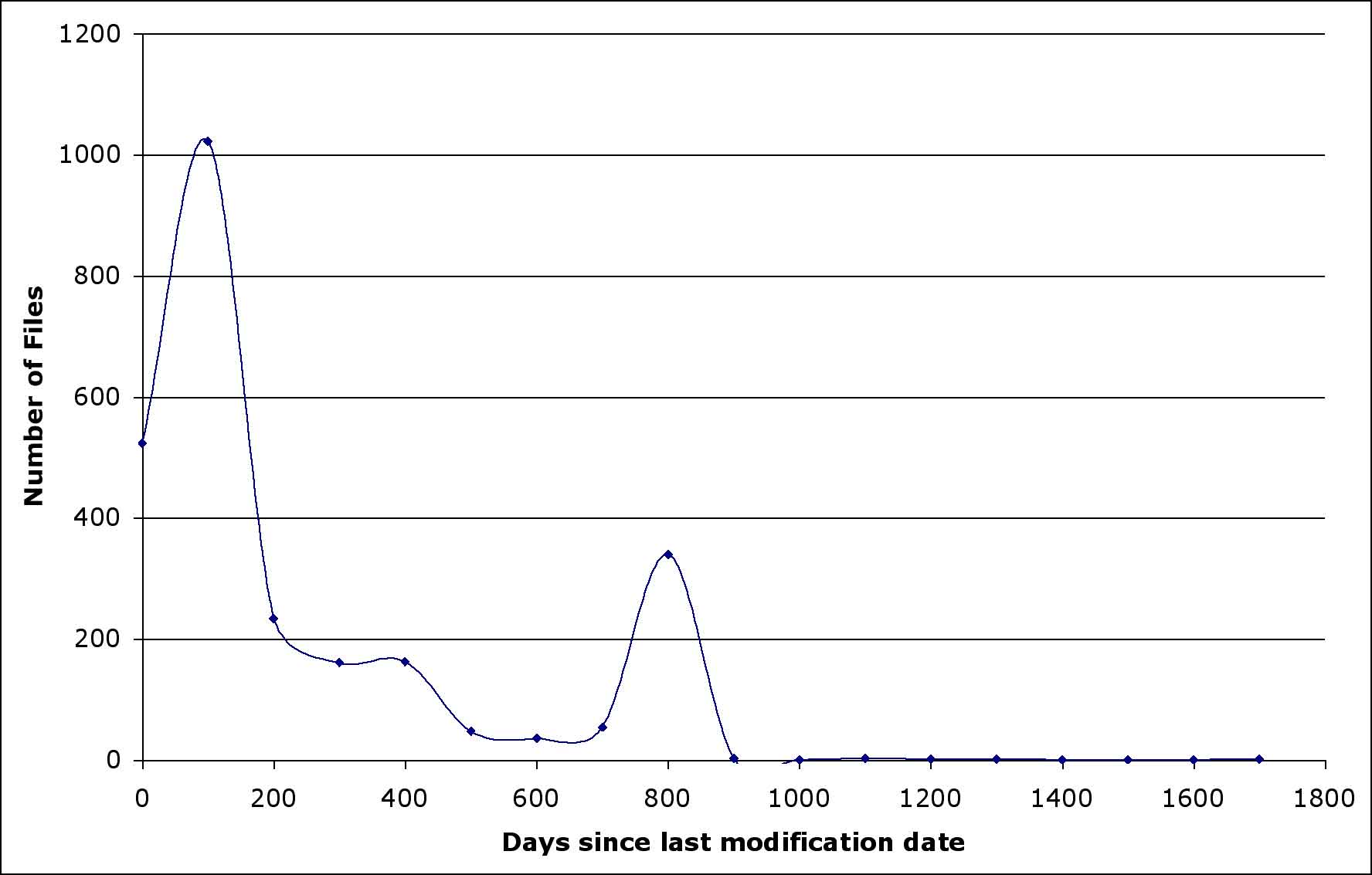
Another index we sought to use to characterize the dataset was the last modification date of the FOAF files. Our intent was to investigate the spread of FOAF data; we would have preferred creation dates, but these are not generally available in HTTP headers. We managed to collect modification dates for all of the non-LiveJournal FOAF files visited in our sample using a Perl script. As it turns out, LiveJournal does not publish a last modification date in the HTTP headers of its FOAF files, presumably because the content is automatically generated from their databases, and may be modified by users at any time. In any case, these dates would not be terribly informative, as FOAF was made available for all users on the site simultaneously.
Figure 1. Distribution of modification dates on non-LiveJournal files.
Figure 1 illustrates the distribution of non-LiveJournal FOAF files modification dates. A large proportion of these files -- responsible for both of the peaks in the graph at 100 days ago and 800 days ago -- appear to be to RDF annotations of photographs on ajft.org, a personal site maintained by Adrian Tritschler of Melbourne, Australia. They are apparently either generated or updated automatically. As anticipated, only a very small number of files have modification dates going back to 1999; this would be expected from the spread of FOAF through a real-world social network. However, because of the influence of large numbers of apparently inappropriate files and the possibility of automatic updates, the modification dates cannot be interpreted without more careful study.
Table 2. Distribution of namespace used in RDF files collected by the scutter.
count |
prefix |
namespace |
38315 |
foaf |
http://xmlns.com/foaf/0.1/ |
37055 |
rdfs |
http://www.w3.org/2000/01/rdf-schema# |
35620 |
rdf |
http://www.w3.org/1999/02/22-rdf-syntax-ns# |
35588 |
dc |
http://purl.org/dc/elements/1.1/ |
17527 |
ns0 |
http://purl.org/net/scutter/ |
1020 |
wn |
http://xmlns.com/wordnet/1.6/ |
945 |
log |
http://www.w3.org/2000/10/swap/log# |
901 |
ajft |
http://ajft.org/foaf.rdf# |
779 |
contact |
http://www.w3.org/2000/10/swap/pim/contact# |
762 |
an |
http://rdf.desire.org/vocab/recommend.rdf# |
709 |
air |
http://www.daml.org/2001/10/html/airport-ont# |
689 |
pos |
http://www.w3.org/2003/01/geo/wgs84_pos# |
668 |
vcard |
http://www.w3.org/vcard-rdf/3.0# |
667 |
ical |
http://www.w3.org/2002/12/cal/ical# |
640 |
exif |
http://www.w3.org/2000/10/swap/pim/exif# |
640 |
file |
http://www.w3.org/2000/10/swap/pim/file# |
591 |
ns0 |
http://xmlns.com/foaf/0.1/mbox_sha1 |
302 |
bio |
http://purl.org/vocab/bio/0.1/ |
216 |
stm |
http://www.w3.org/2001/sw/schedScrape.xsl? |
157 |
img |
http://jibbering.com/2002/3/svg/# |
156 |
dcterms |
http://purl.org/dc/terms/ |
135 |
h |
http://www.w3.org/1999/xhtml |
120 |
wot |
http://xmlns.com/wot/0.1/ |
117 |
uri |
http://www.w3.org/2000/07/uri43/uri.xsl?template= |
106 |
rel |
http://www.perceive.net/schemas/20021119/relationship/relationship.rdf# |
103 |
terms |
http://jibbering.com/2002/6/terms# |
1269 |
remaining namespace uses with < 100 occurrences each |
The second database table, rdf3, is a comprehensive table of the RDF triples parsed by the scutter stored in their full textual form (!), a fact which is responsible for the large storage size of this otherwise modest crawl. The table comprises 6.73 million RDF triples with URIs defined in 196 different namespaces. Table 2 summarizes the number of files utilizing each namespace. Of these http://xmlns.com/foaf/0.1 is the most common, followed by rdfs, rdf and dublin core elements, suggesting that the scutter is principally obtaining genuine FOAF files (though the enforced structure and inter-linkage of LiveJournal FOAF files would guarantee this). The incidence of different namespaces drops sharply from this. The ajft namespace, used in Adrian Tritschler's photo annotation files to identify individuals in his FOAF file, again shows the disproportionate effect of a single person's vigorous application of the markup. In its present low incidence of use, it is possible for a single individual or site to populate the accessible FOAF data with members of their own social sphere. Hence the data show some inconsistency in the markup applied, based on the purposes of individual users.
Table 3. Use of FOAF vocabulary in the sample.| count | pred |
| 1067568 | interest |
| 869916 | nick |
| 868538 | weblog |
| 839934 | knows |
| 40066 | mbox_sha1sum |
| 33172 | page |
| 26385 | dateOfBirth |
| 15624 | homepage |
| 13255 | aimChatID |
| 6718 | yahooChatID |
| 6072 | name |
| 4973 | msnChatID |
| 4275 | icqChatID |
| 1603 | depiction |
| 1436 | mbox |
| 1416 | thumbnail |
| 1089 | firstName |
| 1016 | surname |
| 749 | depicts |
| 685 | jabberID |
| 674 | maker |
| 561 | title |
| 452 | workplaceHomepage |
| 403 | schoolHomepage |
| 273 | codepiction |
| 238 | currentProject |
| 235 | img |
| 203 | gender |
| 203 | phone |
| 195 | made |
| 195 | regionDepicts |
| 143 | workInfoHomepage |
| 109 | lastName |
| 1213 | 77 items occurring 100 times or less |
The most common tags in the FOAF files are indicted in Table 3. foaf:interest dominates the frequency-sorted list, with more than a million instances; nick, weblog and knows are all close together in occurrencefollowed a full order of magnitude lower by mbox_sha1sum. other forms of id (mbox) are lower still. This is probably because of the large number of LiveJournal files; identity management is a built-in feature of the system (handled through nicks), hence it is not necessary for users to populate their FOAF files with identities created from mbox hashes, email addresses, etc. However it is interesting that advertising one?s interests takes such a high priority; arguably this has a role in shaping social identity much greater than the mere establishment of uniqueness of reference. It provides information that other users can orient to, for instance.
The structure of the rdf3 table data makes it difficult to operate on the triples to summarize the distribution of the namespaces. What is required is a relational JOIN operation, but with 196 different possible namespaces, 255-character fields for each field in a triple, low information content in the first seven characters of these fields (almost all begin with http://) and 6.73 million triples to operate on, this operation ends up taking unreasonable amounts of time on the hardware available to us.
To facilitate analysis, we began work on a modified database structure that will isolate the namespace and resource information in separate tables, and use integer ID fields for the triple storage (indeed, this was the operation that forced us to migrate the database from MySQL to PostgreSQL). By matching the fixed-length string http://xmlns.com/foaf/0.1, we were able to identify 3.81 million triples as FOAF triples. These were extracted for separate analysis. Of these, 837,791 were instances of the foaf:knows relation, the one most important to the social networking functions of FOAF -- a modest number by the standards of distributed hypertext, but a formidable number for an interpretable social network analysis.
Since most social network analysis algorithms run in polynomial or exponential time, the scale of FOAF data is a major problem is working with it. If FOAF data is intended to enable users to undertake the kinds of analysis we would like to do, then it is necessary for the FOAF community to go beyond the specification of markup standards. Processing of FOAF would be greatly assisted by local pre-compilation of interconnectivity relations among the FOAF files of a local group, especially those hosted on a site such as LiveJournal. While a large site like LiveJournal might understandably balk at such a requirement for its 3.5 million users, that merely serves to underscore the problem that scale poses for FOAF characterization. [2] It should be remembered here that the problems of scale arise in what is merely a fraction of the available FOAF data.
Alternatively, as with encryption algorithms, the computational complexity of network analysis of FOAF could be exploited as a security barrier of sorts. Strangers would be prevented from learning much of social consequence by the sheer cost of learning it. However, for this protection to work at all would require that FOAF be designed to make it impossible to learn meaningful social facts from a small sample of FOAF data. This is certainly not the case, since a single FOAF file exposes a coherent set of social relations, namely those related to an individual, rather than a random or meaningless set.
Characterization of FOAF requires interpretation of the FOAF data which poses certain other problems. The structure of a typical FOAF file is a nested RDF/XML hierarchy where a person corresponds to a blank node. Since blank nodes arising in the context of different files will have different _:genid's associated with them by the parser, the reference of these needs to be resolved. The problem here is that FOAF allows different ways to identify a unique individual: people may use foaf:mbox, or foaf:mbox_sha1sum. On systems such as LiveJournal, foaf:nick is also unique, and it is more interpretable to humans (typically nicks encode gender and other social attributes of interest). Mailboxes themselves are not unique to an individual, and an someone could easily post multiple FOAF files, one for each email address she possesses.
It is unlikely that a single solution can be found that will cover all possible cases of reference resolution in FOAF files. In our database, because of the difficulty of joining on large text fields, we were forced to resort to an approximate solution. Since our primary interest was the foaf:knows relation, we created a table of unique nicknames and substituted integer reference numbers for these into a revised version of the foaf:knows relation, as a separate table. Since nicknames are guaranteed to be unique on LiveJournal, but are not necessarily used in hand-rolled FOAF files, this means that the LiveJournal data is replicated faithfully, but some other data may be lost. Hence, what we have to say about the foaf:knows relation must be interpreted cautiously for non-LiveJournal files and links.
An additional problem with interpretation is that we might get the same or conflicting information from multiple FOAF files. In the rdf3 database table, the source of a particular triple is indicated by a foreign key reference number into the urlsnew table. This is unsatisfactory for two reasons. First, the social world is dynamic and changing; as people update their FOAF files, the image of the social landscape changes. If we want to study this, it is essential that the reference to a file not be to a unique URL but to a combination of URL and date. Even this is not enough if an individual's file comes to be stored on a different host at some later point. Given that the data we have is collected within a narrow window of time, we can take our data to represent a synchronic time-slice, hence a representation of (some part of) the social network at one time.
The foaf:knows relation is the primary form of data that indicates social relations in the data set. Other relations, such as foaf:interests potentially indicate social affiliations (e.g. membership in social groups) or markers (e.g. musical tastes) that could also be studied, but this is made inconvenient because of the additional levels of indirection (more '_:genid"s need to be resolved) and the use of additional namespaces (typically Dublin Core, but possibly not exclusively). These require different means to study than actor-actor relations like foaf:knows (see Wasserman and Faust 1994, chapter 8), which we focus on here.
Our original intent was to attempt to generate a reduced sociogram of the foaf:knows relation for interpretation. Reduced sociograms represent social relations by aggregating across members of social groups. Generally, these groups are constructed as equivalence classes of the actors in the network, based on their connections to all the other actors. Such an analysis has proven useful in understanding patterns of social relationship in many studies (see Waserman and Faust 1994, chapter 9), including social network analysis of online communications (Paolillo 2001).
Unfortunately the algorithms for reducing social networks into equivalence classes have unreasonable computational complexity. For N social actors, the full sociomatrix has N2 cells. The complete actor set comprises 274,305 distinct individuals, with a full sociomatrix of having more than 65 billion cells. Since only 17,892 actors occur as subjects of foaf:knows, we can trim this immediately to 17,892 by 256,575 actors or almost 4.6 billion cells. This size is still too large for our hardware to handle, so we attempted to undertake a reduction based on a principal components analysis (PCA) of the relations of all 17,892 subjects with a random sample of 200 actors. A scree-plot of the eigenvalues of this matrix revealed 10 principal components. Factor scores coefficients were extracted from this PCA to calculate ten basis vectors for the full complement of 274,305 actors. The basis vectors were to be used as input to k-means clustering of the actors into natural social groups. However, the calculation of the basis vectors was terminated once it was clear that it would take more than 270 hours to complete. We are still looking for other approaches to accomplishing the intended reduction based on computationally simpler methods.
Another approach we took was to measure the interconnectivity of a random sample of subject notes in the foaf:knows graph. We took a random sample of 104 nodes, and examined how many nodes were reached from each additional step in the graph. The nodes, and the number of steps to reach each one, are presented in Table 4.
| step | LiveJournal | other |
| 0 | 102 | 2 |
| 1 | 834 | 7 |
| 2 | 8309 | 28 |
| 3 | 7482 | 39 |
| 4 | 891 | 10 |
| 5 | 14 | 8 |
| 6 | 0 | 8 |
| 7 | 0 | 4 |
| 8 | 0 | 9 |
Table 4. Subject nodes in the foaf:knows network reachable from a random sample of 104 subject nodes.
Both LiveJournal and other show a mode of between 2 and 3 links to the largest number of new actors. This suggests an organization with social groups that are not exactly cliques, because they are not mutually interconnected, but nonetheless with a relatively low diameter. It appears that files outside LiveJournal have a relatively longer tail of relational chains extending past six links. However, this appearance could be due to the unfortunate selection of two more loosely-connected non-LiveJournal starting points, or else because of prematurely stopping the harvesting of LiveJournal links.
We also attempted to calculate minimum path lengths between each pair of nodes, but again were stymied by computational complexity issues. From the 837,791 instances of foaf:knows, there are 5,830,572 paths of length 2 that can be formed. Because we could not intersect this set with the original set, it is unclear how many paths are minimum paths. Calculation of paths of length 3 did not return when we attempted it.
Finally, we investigated the extent to which FOAF files in the data formed links that were reciprocal or directional. Reciprocal links are any links in which the subject links to an object which links back to the subject. We classified and counted all links as either reciprocal or directional, whether they existed between members of LiveJournal, other sites, or both, and if both, the direction of the linkage if they were not reciprocal. These counts are presented in Figure 2.
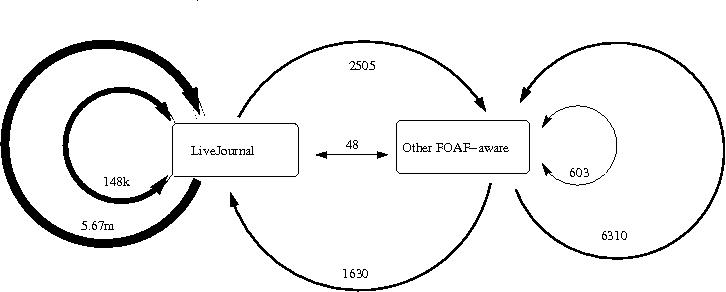
As can be seen in this illustration, the vast majority of relationships in the data are one-way references from LiveJournal users, followed by reciprocal relationships between LiveJournal users. Reciprocal and non-reciprocal relationships, along with the undirected connections between LJ and non-LJ users, follow. Least present are reciprocal connections between LiveJournal and non-LiveJournal FOAF users. From this figure we can see that LiveJournal dominates the available data, and infer that the automatic generation of FOAF by the LiveJournal system has quite a bit to do with the type and number of relationships that are found.
A number of the observations we have made in our attempt to characterize FOAF point to a need to consider FOAF and its use in terms of its potential ethical consequences. As social scientists from a university research environment, we are keenly aware of the impact of ethical considerations on the conduct of research. In fact we would be unable to conduct research on social systems of this nature on the current scale if it were not for the fact that the information in FOAF files is made publicly available. Research using information in the public domain falls into a category of research that is exempt from the full review of the Institutional Research Review Boards (IRBs) of most research institutions in the US. [3]
But how did this information become public? People's social relations are among the most personal information they have, information that could easily be misused by spammers, runaway law enforcement agencies, political misanthropes, stalkers and other social evils. Users of a social networking system employing FOAF may be uncomfortable with the amount of data provided by FOAF, or may be entirely unaware that such an amount of personal information is available to automated tools. Furthermore, privacy legislation is relevant to the use of FOAF. What happens when someone encodes information classified as sensitive under the Health Information Privacy Protection Act (HIPPA) into FOAF? Or when someone claims that their data is being used without informed consent? Moreover, automated data collection tools may produce inferences that end-users find distinctly uncomfortable. What happens when FOAF gets a bit of data wrong?
The distributed nature of the FOAF network is likely to cause problems for both research and business users. Both types of applications are often governed by restrictive privacy paradigms (for example, university IRBs or HIPAA medical privacy legislation), the mechanics of which could make implementation of FOAF-like technologies rather inconvenient. System operators who wish to automatically provide FOAF for their users -- i.e. currently LiveJournal, Typepad -- must be cautious to inform their users of the way in which their data is being exposed to the world. Even seemingly innocuous types of information such as dates of birth, favorite song, interests, and other information take on different meanings when they may be used for data mining by strangers.
For example, interest in popular music could be translated into suspicion of piracy by a music publisher zealously defending its copyright. Interests or fashions that are socially unacceptable or illegal in some locales may be both acceptable and legal in others, but it is not clear that anyone interpreting this information will have the necessary context. Personality quirks, psycho-medical conditions (alcoholism, depression) prior arrests, etc. are all examples of information that people want to share under appropriate circumstances, and which can be important to establishing and developing friendship and social bonds, but whose sharing as a general rule bears unacceptable risk. For example, if future employers encounter this data, even if it is inaccurate or false, it will likely color their interactions with a prospective employee. This is the sort of negative impact that IRBs and business and health care privacy legislation are intended to counteract.
Arguably, much of the information that is provided by FOAF, for example on LiveJournal, is already public. Database-generated HTML pages offer the profile data of any user to the public; these could be crawled much as the FOAF files can be. And what is not already public may be required by law, e.g. to meet the minimum age requirements for use of sites by minors in the US. What is not clear is whether users intend or even understand the ways in which the information may be used.
Beyond these concerns our FOAF characterization raises other points of ethical concern, which we suspect are relatively infrequently heard in social network application development circles. This concerns the nature of large social networking sites such as LiveJournal. The sheer size of such a site, and the technical costs of linking outside it, result in the sites accruing massive amounts of user's social capital for themselves. Proper characterization of FOAF use is next to impossible in this circumstance: FOAF characterization will either need to deliberately exclude such sites, and hence be un-representative of people's social relations, or be overwhelmingly dominated by them.
Given the commercial nature of such sites, this result is not entirely ethically innocent. Users of sites such as LiveJournal are predominantly teenagers and young adults. Such people are at the peak of their lifetime sociability (Degenne and Forse 1999; Forse 1981). It is this volume of sociability, let alone the voracious consumer-spending appetites of youth, that makes the business model of social networking sites viable. Restrictions on the formation or expression of social relations in this context, however subtle, constitute an appropriation of social capital, a privatization of the control of public sociability with as yet unforeseen consequences. The is the real nature of the practical experiment conducted under the rubric of social network computing. Like other social experiments of the past, Philip Zimbardo's Stanford prison experiment, Stanley Milgram experiments of people's willingness to carry out orders, and others, due consideration should be given to the consequences of the research for the researched, who in this case are the vulnerable youth whose use of the technologies potentially changes, indeed it even promises to change, their transition into adulthood.
And what does the future hold? Email and the World-Wide Web, novelties to millions only ten years ago, are now completely naturalized in the public mind, as are Spam, denial of service attacks, identity theft and other unforeseen consequences. Are social networking sites destined for the same naturalization? Do we want a world where one cannot get a job in a place because one does not have an account on LiveJournal, or the right friends on Orkut? Will existing social fault lines really be ameliorated by social networking services? Or merely further reified? And how does placing the control of this information in the hands of private companies bode for our social an political independence? These questions need to be addressed in any social computing application.
Characterization of FOAF is challenging on a number of levels: technical, methodological and ethical. Successful characterization of FOAF use and the practical experiment that it represents requires careful consideration of all of these aspects. The challenges are great, but may eventually be overcome, or point to different possibilities for the use and deployment of FOAF by users and sites providing it.
On the technical level, the size of RDF triple stores and the computational complexity of processing them need to be considered. While the size of our dataset is modest, large sites like LiveJournal present truly large volumes of FOAF which a scutter can easily bog down in. In terms of complexity, social network analysis algorithms typically require polynomial or exponential time and or space to execute. Possible approaches to resolving these problems are pre-compilation of some relations by servers, or protocols for distributed FOAF processing.
On the methodological level, the greatest problem in characterizing FOAF is the lack of methods for random sampling. Unfortunately there seems to be no fully satisfactory resolution of this problem. FOAF was not designed to be shared on its own standard port, in the manner of HTTP for Web documents. Consequently any FOAF characterizations must be local to a given crawl. A related issue here is the problem of sampling data that leads into a large site publishing FOAF, with many inward links. Such situations underscore the necessarily particularistic, rather than general nature of any characterization of FOAF.
On the ethical level, we find large unanswered questions about the public or private nature of the data published through FOAF, and extensive ambiguity regarding its intended uses. Protection of users' privacy should be a major priority for FOAF development in the future. Users will ultimately demand the ability to revoke individual FOAF assertions on demand, or an audit of how their data is being used, the way that credit reports can be requested. The problems here are not so much technical as social: the use of the system by users and applications will tend to influence the real-world problems encountered.
A final concern raised by our study addresses the aim of the practical experiment that is FOAF and social network computing in general. We note that the social consequences of the experiments conducted as practical experiments under the rubric of social network computing may not have been fully considered, and that the privatization of social capital is one of these effects. There is an urgent need to understand the social dynamics behind the use of these systems. To some extent, these have been documented in studies of computer-mediated communication systems such as MOOs (Cherny 1999) and IRC (Paolillo 2001; Reid 1993), but the nature and scale of the new systems are different.
The characterization of FOAF may not be fully satisfactory until all of these concerns are addressed. The technical and methodological concerns can be addressed in the usual ways, and doing so will have much to teach us about what we have done in creating this new social world of the FOAF-sphere. The ethical considerations require quite a different kind attention, and one which may have been lacking in earlier work. With these understandings from an attempted characterization of FOAF, we are at least somewhat better prepared to consider the ways in which FOAF data can be used and abused, and how it may shape our social worlds to come.
[1] Practical jokes are jokes performed on an individual through exploitation of their actions in the real world, without the individual's fore-knowledge or consent. Practical experiments, also called "social experiments", are experiments conducted in much the same way. The literature of medicine and psychology are full of examples of practical/social experiments of this nature, and their many negative consequences. Those who would undertake practical experiments of a technical nature would do well to study and learn from these examples.
[2] In fact, LiveJournal already computes some of this data for all its users, namely the rows (friends) and columns (friend of) of the full sociomatrix. Rows are exposed in user profiles and as individual FOAF files, while columns are only exposed in user profiles. For reachability, minimum path length, etc. a form of transitive closure must be computed.
[3] This is not the same thing as an exemption from review entirely, a status which is enjoyed by the inventors of the Internet, XML and most social computing environments.