ReSpec Editor's Guide
A ReSpec document is a HTML document that brings in the ReSpec script, defines a few configuration variables, and follows a few conventions. A very small example document would be:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Replace me with a real title</title>
<script
src="https://www.w3.org/Tools/respec/respec-w3c"
class="remove"
defer
></script>
<script class="remove">
// All config options at https://respec.org/docs/
var respecConfig = {
specStatus: "ED",
editors: [{ name: "Your Name", url: "https://your-site.com" }],
github: "some-org/mySpec",
shortName: "dahut",
xref: "web-platform",
group: "my-working-group",
};
</script>
</head>
<body>
<section id="abstract">
<p>This is required.</p>
</section>
<section id="sotd">
<p>This is required.</p>
</section>
<section class="informative">
<h2>Introduction</h2>
<p>Some informative introductory text.</p>
<aside class="note" title="A useful note">
<p>I'm a note!</p>
</aside>
</section>
<section>
<h2>A section</h2>
<aside class="example">
<p>This is an example.</p>
<pre class="js">
// Automatic syntax highlighting
function someJavaScript(){}
</pre>
</aside>
<section>
<h3>I'm a sub-section</h3>
<p class="issue" data-number="121">
<!-- Issue can automatically be populated from GitHub -->
</p>
</section>
</section>
<section data-dfn-for="Foo">
<h2>Start your spec!</h2>
<pre class="idl">
[Exposed=Window]
interface Foo {
attribute DOMString bar;
undefined doTheFoo();
};
</pre>
<p>The <dfn>Foo</dfn> interface represents a {{Foo}}.</p>
<p>
The <dfn>doTheFoo()</dfn> method does the foo. Call it by running
{{Foo/doTheFoo()}}.
</p>
<ol class="algorithm">
<li>A |variable:DOMString| can be declared like this.</li>
</ol>
</section>
<section id="conformance">
<p>
This is required for specifications that contain normative material.
</p>
</section>
</body>
</html>The following code is used to include a ReSpec document, usually in the <head>:
<script src="https://www.w3.org/Tools/respec/respec-w3c" class="remove" defer>
</script>
<script class="remove">
var respecConfig = {
// configuration options
}
</script>ReSpec is regularly updated and this will allow you to automatically benefit from bug and security fixes and enhancements.
ReSpec is configured using a JSON-like object, which is assigned to a respecConfig JavaScript variable:
<script class="remove">
var respecConfig = {
// configuration options
}
</script>All the configurations options are listed in this document.
ReSpec documents are just HTML document and rely on HTML structural elements, in particular <section>, <aside>, <h2>-<h6>, <dl>, <ol> etc. In this section, we discuss how to specify various aspects of a typical document.
The <title> of the document is reused as the title of the specification in the resulting document's h1. That way, they are always in sync and you need not worry about specifying it twice.
<title>The Best Specification</title>If you need to add additional markup to your title, you can still use a <h1> with id="title".
<h1 id="title">The <code>Foo</code> API</h1>As with the title, you can also specify a subtitle as:
<h1 id="title">The <code>Foo</code> API</h1>
<h2 id="subtitle">Subtitle here</h2>Which is rendered as:

You can also specify a subtitle configuration option in the ReSpec config, but using the markup above is preferred.
Every specification will likely have editors (at least one) and/or authors. It is left to users or standards organizations to differentiate between editors and authors (e.g., from W3C, what does an editor do?).
See the Person objects for the full list of properties you can assign.
var respecConfig = {
// ...
editors: [
{
name: "Robin Berjon",
url: "https://berjon.com/",
company: "W3C",
companyURL: "https://w3c.org/",
mailto: "robin@berjon.com",
note: "A Really Cool Frood",
},
{
name: "Billie Berthezène-Berjon",
company: "Catwoman",
},
],
authors: [
{
name: "Ada Lovelace",
url: "https://findingada.com/",
company: "Aristocracy",
retiredDate: "1852-11-27",
},
],
// ...
};Is rendered as:

ReSpec-based specifications require you to wrap your content in <section> elements. We provide specific information and examples on how to use <section> elements.
Sections, subsections, appendices, and whatever other structural items are marked up in ReSpec using <section> elements.
<section>
<h2>A section</h2>
<p>Some text.</p>
<section class="informative">
<h3>I'm a sub-section</h3>
<p>Sub-section text.</p>
</section>
</section>Which is rendered as:
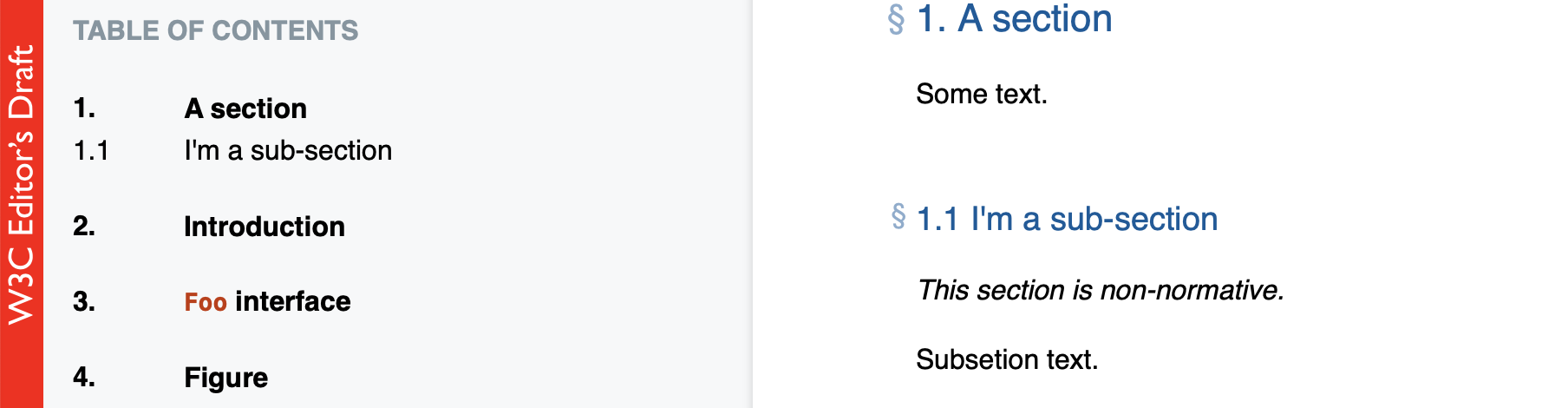
As shown, sections are automatically numbered and uniquely id's for you. Use <section id="my-id"> specify your own id.
ReSpec sections understand some specific CSS classes: introductory, informative, and appendix.
Note: You can use the special syntax [[[#some-id]]] to link to a section.
In W3C specs, a table of contents (ToC) is generated automatically and placed after the "Status of This Document".
See also the maxTocLevel option to limit how deep the ToC is.
Set the configuration option noTOC to true to remove the table of content.
To include a figure, use the <figure> and <figcaption> elements. They automatically get an id and figure number.
<figure id="figure">
<img src="figure.svg" alt="W3C Logo" />
<figcaption>The W3C logo</figcaption>
</figure>Which renders as:

Automatic linking to figures works just as it does for sections, with [[[#some-figure]]].
To add a "List of Figures", include <section id="tof"> anywhere in the document. ReSpec will do its best to guess if it should be an appendix, introductory, or just a regular section.
<section id="tof" class="appendix"></section>Renders as:

Any <pre class="example"> or <aside class="example"> gets the additional example header and style. Content inside <pre>/<code> elements is syntax highlighted. You can specify the language in the class attribute, for example <pre class="js">.
<aside class="example" title="How to use it">
<p>
This is how to use it.
<p>
<pre class="js">
function myCoolFunction() {
// stuff goes here...
}
</pre>
</aside>which is rendered as:

Including external content into ReSpec is done using the data-include attribute, which points to a URL.
<section data-include="some.html"></section>You can specify data-include-format='text' to include content as text, and therefore only process it as much as text is expected to be. The only recognized value are "text", "markdown", and "html" (default).
Note: data-include relies on the browser's ability to retrieve the resource and is governed by CORS (and the browser's security model in general). Browsers will generally block cross origin request, which means file:// URLs will likely fail. For more information, please see "Cross-Origin Resource Sharing (CORS)". You can usually get around this by starting a local web server (e.g., by running python -m http.server 8000 from the command line).
Use data-oninclude to perform transformation on content included with data-include.
ReSpec specifications are RFC2119/RFC8174 keyword aware.
Adding a <section id="conformance"> tells ReSpec that the specification is dealing with "normative" statements. ReSpec can then warn if RFC2119 keywords are accidentally used in informative/non-normative contexts.
<section>
<h2>Requirements</h2>
<p>A user agent MUST do something.</p>
</section>
<section id="conformance"></section>Renders as:

Mark abbreviations using <abbr title="abbreviation">abbr</abbr>. ReSpec will then wrap all matching instances abbreviations with <abbr>.
<p>
The <abbr title="World Wide Web">WWW</abbr>.
</p>
<p>
ReSpec will automatically wrap this WWW in an abbr.
</p>To mark some text as code, use <code> or backticks (`).
To define a term, simple wrap it in a <dfn> element.
<dfn>some concept</dfn>Then, to link to it, just do:
<a>some concept</a>
or
[=some concept=]For simple/single nouns, ReSpec handles pluralization automatically:
<dfn>banana</dfn>
<!-- these are the same -->
These [=bananas=] are better than those <a>bananas</a>Sometimes a defined terms needs additional related terms or synonyms. In those cases, you can use the data-lt attribute on the dfn element:
<dfn
data-lt="the best fruit|yellow delicious">
banana
</dfn>Note: "lt" stands for "linked term".
The following all link back to "banana":
<p>[=the best fruit=] or the [=yellow delicious=].</p>The powerful (xref) feature let's you reference terms and concepts in other specifications. For example, to reference "default toJSON steps" from the WebIDL standard:
<script>
var respecConfig = {
xref: ["WebIDL"],
};
</script>
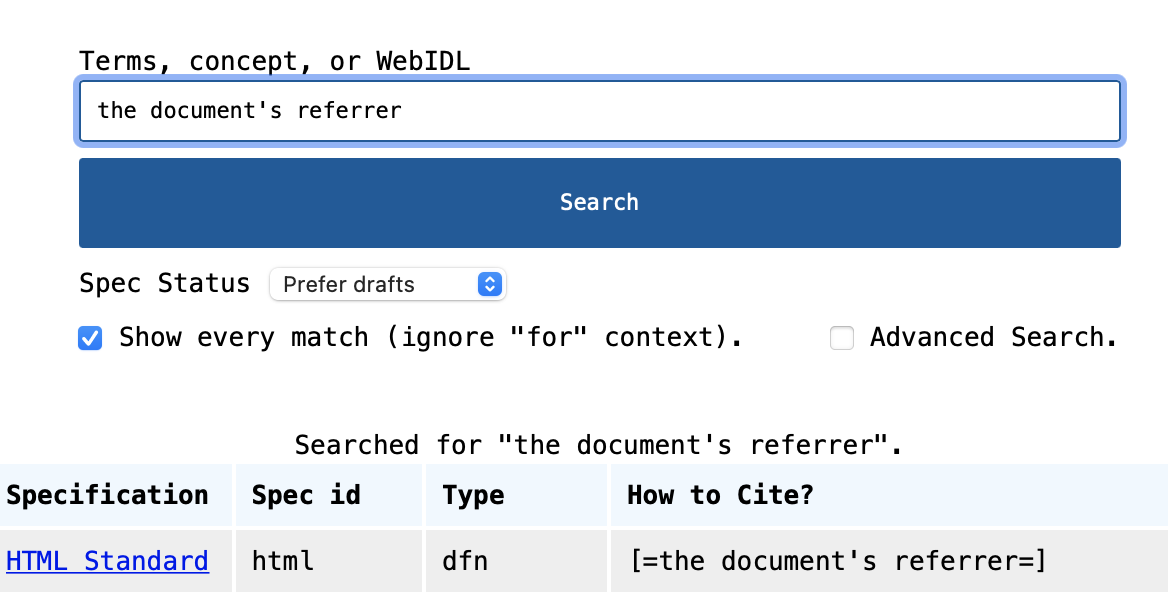
<a>default toJSON steps</a>To search for terms + specs your can link to, you can use the XREF UI at http://respec.org/xref/. Below is a screenshot of what the UI looks like:
There are two important shorthands for linking to definitions:
-
[=term=]for linking regular concepts, -
{{IdlThing}}for linking WebIDL.
Shorthand syntax works for referencing external terms as well as locally defined terms. It's best practice is to use shorthands all the time.
<script>
var respecConfig = {
xref: ["webidl", "payment-request"],
};
</script>
<section>
<!--
Here, we reference the "default toJSON steps" concept defined in [[WebIDL]] standard,
and the PaymentRequest interface (WebIDL) defined in [[payment-request]] standard.
-->
<p>[=default toJSON steps=] for the {{PaymentRequest}} interface are ...</p>
<!-- We also define a concept "feline", and an interface "Cat". -->
<p>A <dfn>feline</dfn> has 4 legs and makes sound.</p>
<pre class="idl">
interface Cat {}
</pre>
<!-- ...and we can reference them as: -->
<p>A {{Cat}} is a [=feline=] if it meows.</p>
</section>Read more about linking and other shorthands in the Shorthands Guide.
To reference another specification use the [[SPEC-ID]] syntax, where SPEC-ID is the referenced specification's in the Specref ecosystem - which includes most W3C, WHATWG, ECMA, and IETF documents.
When you reference a specification, your document automatically gets a bibliography section.
The [^link^] element is defined in the [[HTML]] spec. Which renders as:

If you would like to reference a specification by its full name, you can use the three square brackets to "expand it":
<p>
The [^link^] element is defined in the [[[HTML]]].
</p>Renders as:

ReSpec uses the context of the reference to work out if the reference is normative or informative: if the reference is in a section marked "informative", or an example, note, or figure, then ReSpec automatically makes the reference non-normative. Otherwise, the reference is treated as normative.
If you need a non-normative reference in a normative section, you can use a ? like so:
This is normative and MUST be followed. But, sometimes we need a non-normative
example reference [[?FOO]].To escape a reference, use a backslash "[[\". For example, "[[\InternalSlot]]".
If a reference is missing, please submit it to Specref. This helps the whole community.
If that is not possible, you can use of the localBiblio configuration option to define your own references.
ReSpec supports adding additional links by specifying an otherLinks property in the configuration. The values for this configuration option are rich and complex, so are detailed in the reference section for otherLinks.
If you wish to add your own additional styles to your document, just use the regular <link> and <style> elements.
Some of ReSpec's configuration options can be specified in the query string, and they override the options specified in the source. For example, you can override the subtitle by, for example, doing the following: index.html?subtitle=This is a subtitle.
This is useful for quickly overriding configuration options without needing to directly edit the document itself (e.g., for the purpose of exporting a document draft with a different specStatus).
ReSpec provides useful options to handle the creation of the W3C boilerplate that goes into the "status of this document" and other key sections.
Specifications typically require having a "short name", which is the name used (amongst other places) in the canonical "https://w3.org/TR/short-name/" URLs. This is specified using the shortName option, as seen in the example above.
The group configuration option lets you state to which working/business/community group your specification belongs to. The list of group identifiers can be found at: https://respec.org/w3c/groups/.
Setting the group option sets the IPR Policy for your document, which is reflected in the "Status of this Document" section.
If your document is not intended to be on the W3C Recommendation Track, set noRecTrack to true.
The specStatus option denotes the status of your document, per the W3C Recommendation track. Typically, a status has implications in terms of what other options required. For instance, a document that is intended to become a Recommendation will require previousPublishDate and previousMaturity.
The specStatus section list all the possible status values.
By default, W3C specifications all get the regular W3C copyright notice. In some cases however, you will want to modify that.
For all document types, you can add your own copyright by using <p class="copyright">.
At times, the patent situation of a specification may warrant being documented beyond the usual boilerplate. In such cases, simply add your own <p> to the Status of this Document section.