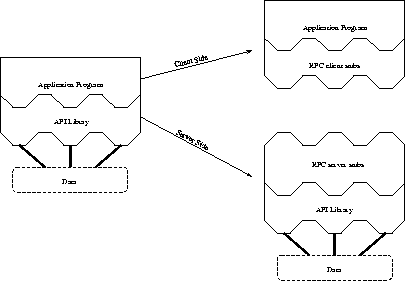
Figure 1. Implementation of distributed application---API access using remote procedure calls.
James Gallagher *
George Milkowski
The storage format of data is often specific to a particular system making it difficult to view or combine several datasets even though, as Pursch points out, combining data sets is often a key requirement of global-scale earth science[13]. Furthermore, most data archives have developed their own data management systems with specialized interfaces for navigating their data resources. Examples of such specialized systems include the Global Land Information System (GLIS)[22] developed by the U.S. Geological Survey (USGS) and the NOAA/NASA Oceans Pathfinder Data System developed at the Jet Propulsion Laboratory (JPL)[10]. Virtually none of these data systems interoperate with each other, making it necessary for a user to visit many systems and `learn' multiple interfaces in order to acquire data. Finally, even after the data has been successfully transfered to the researcher's local system, in order to use the data a researcher must convert that data into the format that his or her data analysis application requires or alternatively modify the analysis application[13].
Many national data centers and university laboratories are now providing remote access to their scientific data holdings through the World Wide Web. Users are able to select, display and transfer these data using WWW browsers such as Netscape and NCSA Mosaic. Examples of such systems are the NOAA / PMEL - Thermal Modeling and Analysis Project[12] and the University of Rhode Island Sea surface Temperature Archive[20]. However, current generation HTML browsers (Netscape 1.1, Mosaic 2.4) are limited and cumbersome when compared to other data access and display client-server systems such as the Global Land Information System (GLIS) developed by the USGS. While WWW browsers are very useful for pedagogical purposes they have limited capabilities in terms of data analysis or manipulation. In the era of Global Change researchers will need tools that provide both network access and data analysis functionality[13][11].
Finally, while large data centers have a clearly defined data policy, and often a mandate to make data accessible to members of the research community[9], there is no infrastructure that enables individual scientists to make data accessible to others in a simple way. While many scientists in the earth-sciences community share data, and cite shared data as one of their most important resources, doing so is often cumbersome[2]. Systems like the World Wide Web make sharing research results vastly simpler, but do little to reduce the difficulty of sharing raw data.
To address these problems, researchers at the University of Rhode Island and the Massachusetts Institute of Technology are creating a network tool that, while taking advantage of WWW data resources, helps to resolve the issue of multiple data formats and different data systems interfaces. This network tool, called the Distributed Oceanographic Data System (DODS), enables oceanographers to interactively access distributed, online science data using the one interface that a researcher is already familiar with; existing data analysis application software (i.e., legacy systems) while at the same time providing a set of tools which can be used to build new application software specifically intended to work with distributed resources. The architecture and design of DODS makes it possible for a researcher to open, read, subsample and import directly into his or her data analysis applications scientific data resources using the WWW. The researcher will not need to know either what format is used to store the data or how the data is actually accessed and served by the remote data system[2].
DODS models data analysis programs as some body of user written code linked with one or more API libraries. The API presents a specialized interface which the user program uses to read data. It is straightforward to split the user program at the program-library interface, and by adding suitable interprocess communication layers, create a classical client and server which can use peer-to-peer communications across a network. Figure 1 shows how this can be done using Sun's RPC technology[18]. However, any suitable network layer can accomplish this goal[16].
For the remainder of this paper a data access API that has been modified to satisfy each of its functions by communicating with a matching data server, as opposed to accessing a local file, will be referred to as a client library. The matching data server will be referred to as a data server or simply as a server.
Once a client library has been constructed for a given API, it is possible to re-link many user programs written for the API with this new library. If the API hides the storage format of the data being accessed and the program uses the API correctly (i.e., without taking advantage of any undocumented features present in the original version but not present in the new client-library version), then the program will require no modification to work with the new implementation of the API. A program thus re-linked can read data from any machine so long as that machine has installed a matching data server. Because the same API has been used by many programs, re-implementing it so that it reads information over the network facilitates the transformation of each program into a client capable of accessing data provided by any suitable server on the network.
By using HTTP as a transport protocol, we are able to tap into a large base of existing software which will likely evolve along with the Internet as a whole. Because the development of large-scale distributed systems is relatively new there are many problems which must still be addressed for these systems to be robust. These problems include naming resources independently of their physical location, choosing between two objects which appear to be the same but which differ in terms of quality. These are general problems which are hard to solve because they will be solved effectively only when the Internet community reaches a consensus on which of the available solutions are best. HTTP, because it is so widely accepted, provides a reasonable base for such solutions. This view is supported by the recent Internet Engineering Task Force (IETF)[3] work on extending the HTTP and HTML standards.
All information sent from the server programs to the client library is enclosed in a MIME document. Two of the three programs return information about the variables contained in the data set as text/plain MIME documents. These documents can then be parsed by software in the client library. In addition, these text documents can be read by any software that can process ASCII text. Thus, the responses made by the server are specifically suited to use by the DODS client libraries, they can also be used by many more general programs. For example, it is possible the use a general purpose World Wide Web browser to `read' these documents.
The third data server program returns binary data encoded using Sun Microsystems External Data representation (XDR)[17] scheme. The data is enclosed in a binary MIME document. This document can be read by software that is part of the client library using the additional information contained in the two ASCII documents. This document can only be read by software that can interpret the datatype information sent by the server in the ASCII documents. Because of this, it is not possible for other general purpose WWW browsers to interpret this file (although most browsers can read and save to disk any arbitrary data).
In order to provide link-time compatibility with the original API libraries, the DODS client libraries must present exactly the same external interface as the original libraries. However, these new libraries perform very different operations on the data (although, for a API used to access a self-describing data format the operations are analogous). One difference between the two is that most data access APIs use file names to refer to data sets. In the simplest case these file names are given on the command line by the user and passed, without modification, to the API. The API uses the file name to open a file and returns an identifier of some type to the user program. Subsequent access to the data are made through this identifier.
In this simple scenario, it is possible to substitute a URL in place of a file name (in part because both are stored in string-type variables). This same user program can be invoked, on the command line, using a URL in place of the file name. The program will, in almost all cases, pass the URL to the API to open the data set. However, since the user program has been re-linked with the DODS re-implementation of the API, the functions in the API will correctly interpret the URL as a remote reference. Clearly, one requirement that a user program must meet in order to be re-linked with DODS is that it must not itself try to open or otherwise manipulate the `file name' which will be passed to the API.
Rewriting existing APIs is hard to implement; it would be much simpler to write our own data display and analysis program to read data from DODS data servers. However, it is important that as much legacy software as possible be able to read the data made accessible by DODS data servers. While this may sound like a trivial requirement, it is wrong to assume that existing data analysis software is simple or can be rewritten at little cost; the existing software in the sciences is no less expensive to rewrite than in any other field. Furthermore, some researchers tailor there research efforts to the characteristics of particular data systems and see the costs of abandoning those systems as very high[2].
The ability to evaluate constraint expressions is an essential characteristic of a DODS data server. In many cases reading a single variable from a data set results in data which is of little or no interest to the user. Often users are interested in those values of a variable which meet some additional criteria (e.g., they fall within a certain time range). For a complete description of the data types supported by DODS and the constraint expression operators, see DODS---Data Access Protocol[21].
Providing access to data using the DAP is necessary because that is how the DODS architecture provides interoperability between different APIs. Because the data servers translate accesses to a data set from the DAP into either an API (e.g., netcdf if the data set is stored using that API) or a special format (e.g., GRIB), any (client) process that uses the DAP can access the data. The underlying access mechanism is hidden from the client by the API.
In the current design of DODS, meeting this requirement means that for each API or format in which data is stored, a new DODS data server must be built.
The other requirement which each server must satisfy is that data, however it is stored, should not require modification to be served by a DODS data server. This is important because many data sets are large and thus very expensive to modify. It is a poor practice to force data providers to modify their data to suit the needs of a system. Rather, DODS data servers must be able to translate access via the DAP into the local storage mechanism without changing that local storage mechanism.
This requirement limits DODS to those APIs and formats which are, to some extent, self-describing. Because the DAP bases access on reading a named variable, it must be possible, for each data set, to define the set of variables and to `read' those variables from the data set. However some data sets do not contain enough information to make remote access a reality. Instead, additional information, not in the data set itself, is needed. This information can be stored in ancillary data files which accompany the data set. Note that these files are separate from the data set, they are not added to the data set and do not require any modification of the data set.
The DODS DAP design contains three important parts: A data model which describes data types that can be supported by the protocol and how they are handled, the data set description and data set attribute structures which describe the structure of data sets and the data they contain, and a small set of messages that are used to access data. Each of these components are described in the following subsections.
Data models are abstract, however, and to be used by a computer program they must first be implemented by a programmer. Often this implementation takes the form of an API---a library of functions which can read and write data using a data model or models as guidance[14][8]. Thus every data access API can be viewed as implementing some data model, or in some cases several data models.
Because DODS needs to support several very different data models, it is important to design it around a core set of concepts that can be applied equally well to each of those data models. If that can be done, then translation between data represented in those different models may be possible[19].
Currently DODS supports two very different data access APIs: netCDF and JGOFS[4]. The netCDF API is designed for access to gridded data, but has some limited capabilities to access sequence data (although not with all of its supported programming language interfaces). The JGOFS API provides access to relational or sequence data. Both APIs support access in several programming languages (at least C and Fortran) and both provide extensive support for limiting the amount of data retrieved. For example a program accessing a gridded data set using netCDF can extract a subsampled portion or hyperslab of that data[14]. Likewise, the JGOFS API provides a powerful set of operators which can be used to specify which type of sequence elements to extract (e.g., only those corresponding to data captured between 1:00am and 2:00am) as well as masking certain parameters from the returned elements so that only those parameters needed by the program are returned.
The DODS DAP uses the concepts of variables and operators as the base for the data model. Within the data model, a data set consists of one or more variables where each variable is described formally by a number of attributes. Variables associate names with each component of a data set, and those names are used to refer to the components of the data set. In addition to their different attributes, it is possible to operate on individual variables or named collections of variables. The principal operation is access, although in a future version of DODS it will be possible to modify this in a number ways.
The data set description structure (DDS) does not describe how the information in the data set is physically stored, nor does it describe how the data set's API is used to access that data. Those pieces of information are contained in the data set's API and in the translating server, respectively. The server uses the DDS to describe the logical structure of a particular data set---the DDS contains knowledge about the data set variables and the interrelations of those variables. In addition, the DDS can be used to satisfy some of the DODS supported APIs data set description calls. For example, netCDF has a function which returns the names of all the variables in a netCDF data file. The DDS can be used to get that information.
The DDS is a textual description of the variables and their classes that comprise the entire data set. The data set descriptor syntax is based on the variable declaration/definition syntax of C[5]. A variable that is a member of one of the base type classes is declared by by writing the class name followed by the variable name.
An example DDS entry is shown in Example 1. Suppose that three experimenters have each performed temperature measurements at different locations and at different times. This information could be held in a data set consisting of a sequence of the experimenter's name, the time and location of each measurement and the list of measurements themselves, and indicates that there is a relation between the experimenter, location, time and temperature called temp_measurement.
data set {
int catalog_number;
function {
independent:
string experimenter;
int time;
structure {
float latitude;
float longitude;
} location;
dependent:
sequence {
float depth;
float temperature;
} temperature;
} temp_measurement;
} data;
Every attribute of a variable is a triple: attribute name, type and value. The attributes specified using the DAS are different from the information contained in the DDS. Each attribute is completely distinct from the name, type and value of its associated variable. The name of an attribute is an identifier, following the normal rules for an identifier in a programming language with the addition that the `/' character may be used. The type of an attribute may be one of: Byte, Int32, Float64, String or Url. An attribute may be scalar or vector.
When the data access protocol is used to read the attributes of a variable and that variable contains other variables, only the attributes of the named variable are returned. In other words, while the DDS is a hierarchical structure, the DAS is not; it is similar to a flat-file database.
Data servers for DODS are built using the WWW server httpd from NCSA. A data server consists of three filter programs and a dispatch CGI. Each data set is referred to via a URL which contains the name of the CGI and some identifying keywords which vary from API to API. Two of the three programs which comprise a data server return textual descriptions of the contents of the data set and can be viewed by any WWW browser. However, the principal function of these two filter programs is to provide information to the client library which it will use to request and decode the information returned by the third filter program---the values of discrete variables within the data set.
Each data set is accessed using an intermediate representation that is independent of a particular machine representation or API. This enables the client library which replaces API X to access a data server which provides access to data stored on disk in files written using API Y given that a correct DODS data server for API Y and a correct client library for API X exist. Thus for the set of APIs which DODS chooses to address, researchers are free to access data without concern for its native storage format.
Currently DODS supports two different data access APIs: netCDF and JGOFS. As of October 1995 a beta release of DODS is available (both C and C++ source code as well as pre-compiled binaries) from ftp::/dods.gso.uri.edu/pub/dods. Additional documentation on DODS may be found at http://dods.gso.uri.edu/.
1. Borenstein, N. Freed, N., Mime (multipurpose internet mail extensions) part one: Mechanisms for specifying and describing the format of internet message bodies, DARPA RFC 1521, 1993.
2. Cornillon, P., Flierl, G., Gallagher, J. Milkowski, G., Report on the first workshop for the distributed oceanographic data system, The University of Rhode Island, Graduate school of Oceanography, 1993.
3. Internet Engineering Task Force, Home Page, http://www.ietf.cnri.reston.va.us/home.html, 1995.
4. Joint Global Ocean Flux Study, Home Page, http://www1.whoi.edu/jgofs.html, 1995.
5. Kernigham, B. W. Ritchie, D. M., The C Programming Language, Prentice-Hall, New Jersey, 1978.
6. Massachusetts Institute of Technology, DODS---Data Delivery, http://lake.mit.edu/dods-dir/dods-dd.html, 1994.
7. Muntz, R., Mesrobian, E. Mechoso, C. R., Integrating data analysis, visualization, and data management in a heterogeneous distributed environment, Information Systems Newsletter vol.20(2), 7--13, 1995.
8. National Center for Supercomputing Applications, Hierarchical data format, version 3.0, University of Illinois at Urbana-Champaign, 1993.
9. National Oceanic and Atmospheric Administration, Report to the senate committee on commerce, science and transportation and the house of representative committee on science, space and technology on a plan to modernize noaa's environmental data and information systems based on the needs assessment for data management archival and distribution: NOAA's leadership role in environmental information services for the nation, U.S. Department of Commerce, National Oceanic and Atmospheric Administration, Washington, DC., 1994.
10. National Oceanic and Atmospheric Administration, NOAA/NASA Oceans Pathfinder Data System, http://podaac-www.jpl.nasa.gov/, 1995.
11. National Science Foundation, The U.S. global change data and information management program plan, National Science Foundation, The Committee on Earth and Environmental Sciences, Interagency Working Group on Data Management of Global Change, 1992.
12. Pacific Marine Environmental Laboratory, NOAA / PMEL - Thermal Modeling and Analysis Project, http://ferret.wrc.noaa.gov/ferret/main-menu.html, 1995.
13. Pursch, A., Kahn, R., Haskins, R. Granger-Gallegos, S., New tools for working with spatially non-uniformly-sampled data from satellites, The Earth Observer Vol.4(5), 19--26, 1992.
14. Rew, R. K. Davis, D. P., NetCDF: An interface for scientific data access, IEEE Computer Graphics and Applications Vol.10(4), 76--82, 1990.
15. Ritchie, D. M., Johnson, S. C., Lesk, M. E. Kernighan, B. W., The C programming language, in E. Horowitz, ed., Programming Languages: A Grand Tour, 3ed., Computer Science Press, Rockville, MD., pp. 458--79, 1987.
16. Stevens, W. R., UNIX Network Programming, Prentice-Hall, New Jersey. 1990.
17. Sun Microsystems, Inc., XDR: External data representation standard, DARPA RFC 1014, 1987.
18. Sun Microsystems, Inc., RPC: Remote procedure call protocol specification version 2, DARPA RFC 1057, 1988.
19. Treinish, L., Kulkarni, R., Folk, M., Goucher, G. Rew, R., Data models, structure and access software for scientific visualization, Proceedings of the Fourth IEEE Conference on Visualization, IEEE, pp. 355--60, 1993.
20. University of Rhode Island, Sea Surface Temperature Archive, http://rs.gso.uri.edu/avhrr.html, 1995.
21. University of Rhode Island, DODS---Data Access Protocol, http://dods.gso.uri.edu/DODS/design/api/api.html, 1994.
22. U.S. Geological Survey, Global Land Information System, http://edcwww.cr.usgs.gov/glis/glis.html, 1995.
James Gallagher
The University of Rhode Island
South Ferry Road
Narragansett, RI. 02881
U.S.A.
jimg@dcz.gso.uri.edu
George Milkowski
The University of Rhode Island
South Ferry Road
Narragansett, RI. 02881
U.S.A.
george@zeno.gso.uri.edu