Group's public email, repo and wiki activity over time
Note: Community Groups are proposed and run by the community. Although W3C hosts these conversations, the groups do not necessarily represent the views of the W3C Membership or staff.
Earlier this month RWW.IO was launched, to much positive feedback. In this post I will show how RWW.IO can be used to extend your FOAF file to become a distributed microblog.
*Disclaimer* this tutorial is for advanced users that may be prepared to live on the bleeding edge, and maybe do some debugging.
Step 1 — Create a FOAF profile
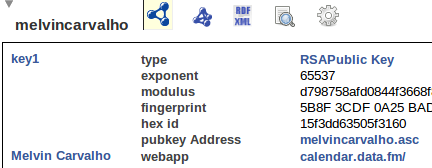
If you’ve followed previous posts, you probably have a FOAF profile by now. The FOAF is used to give a nick, avatar, name and URL for the micro blog creator. For this demo I’ve uploaded a FOAF to
But you can put it anywhere in your space. If you’ve done this right, click on it and it should look something like this:
Note: that you do not need the tabulator extension running to view this FOAF, rww.io has a tabulator skin pre installed, so there is nothing to install.
Step 2 — Create a Microblog
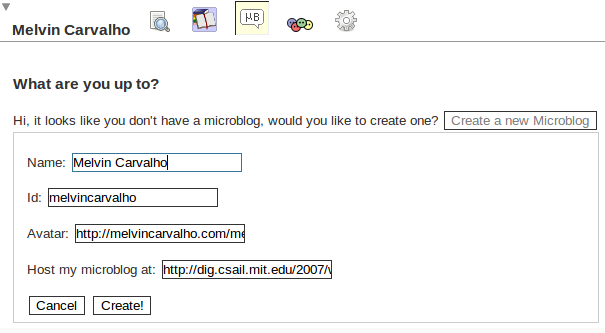
Once you are at your FOAF, click in the entity that is of “type” FOAF : Person, in my case it’s “Melvin Carvalho”. After this click the small microblog icon which will ask you to create a microblog. The screen should look something like this:
Again, you can locate it anywhere you wish. And hit create. It will then put a new file in the directory you chose.
Note: this worked best for me in opera. In firefox and chrome it was temperamental and worked best when I stepped through with a debugger.
Step 3 — Link your microblog to your profile
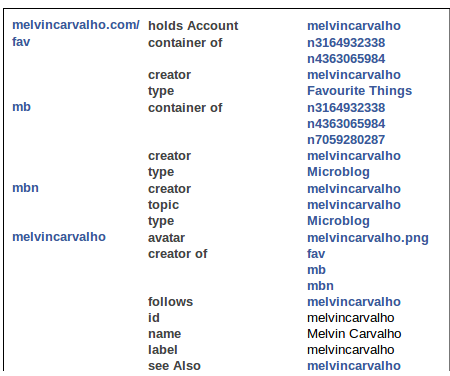
Although not strictly required, for various reasons this demo works best when you have linked your microblog to your profile. This is done by adding the triple:
<#nickname> rdfs : seeAlso <../profile/nickname>
Your microblog should look something like:
We want to click to the right of “see Also” which will take us back to our profile where we can now add micro blog posts.
Step 4 — Set Your Identity
While you’re at your profile page quickly click the foaf icon at the top, and you’ll see an image of yourself such that you can set our identity. If you’ve done it right it should look something like:
Step 5 — Start Microblogging!
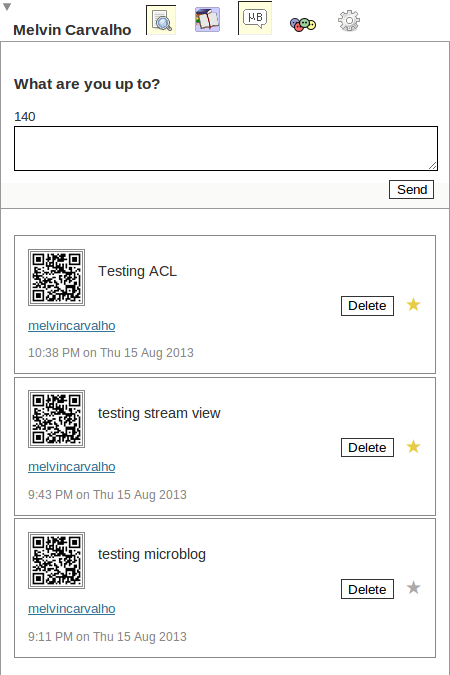
You can start microblogging straight away by clicking he microblog icon. However it helps if you start following people. Strangely you need to follow yourself to see your own posts, so you can add triples to the same place you added the seeAlso, with 2 URIs of the form:
And you should start seeing the posts of the people you follow come in. You can even favourite the ones you like with the final screen looking something like:
If you’ve got this far (or even past a few steps) very well done! I’d be very happy so start growing my microblog circle!
To summarize we’ve shown how to use commodity storage such as rww.io to create a distributed microblog using tabulator’s microblog pane. No installations were required and it is possible to follow an arbitrary list of users, and, of course, control the access!
Further privacy issues emerged, this month, across the internet, as the extent to which data is monitored has encompassed more than was previously reported. The web has been awash with concerns, including reports that even passwords can at times be requested.
Preparations are under way for a workshop on the social web, in San Francisco. An interesting program has been discussed, with the possibility to go to a full working group if there is enough interest.
Community Group
There have been discussions with various groups including the OpenID Foundation, and Internet Identity Community about a proposed header, to enable a user to be identified to a server. Some quite productive feedback ensued.
I have added a couple of blog posts in the tabulator series. Part 1 shows you how to create a brand new tabulator pane, and part 2 shows how to render a simple SIOC microblog post.
Applications
Two new implementations of LDP are under way. One in java, and another in node. More great work from Andrei Sambra who has created an API for my-profile, and also is experimenting with WebRTC to enable real time chat and video. An interesting project from Ben Werdmuller of elgg fame, called idno, allows you make your personal page into a social read/write experience.
Last but not least…
For all you SPARQL fans out there enjoy the release of YASGUI a web based SPARQL GUI with auto completion, syntax checking, CORS enabled, endpoint search, permalinks, bookmarking and much more!
Last week, we looked at how to create a new tabulator pane. The first part was just a template, without any real content. This time we will look at how to add a pane for a specific object type and to query the object’s fields and display them in the pane. If you havent already completed the first part, go back and follow the instructions to make a new file microblogPostPane.js. This is the file we’ll be editing in this part.
Step 1 — Only Display an Icon for Microblog Posts
Previously we would display our microblog icon in all cases. We would rather only show the icon when we are looking at a microblog post. Instead of the if (true) condition we had in the label() function we will now replace it with:
var SIOCt = tabulator.rdf.Namespace('http://rdfs.org/sioc/types#');
if (tabulator.kb.whether(
subject, tabulator.ns.rdf('type'), SIOCt('MicroblogPost'))) {
return"MicroblogPost"; //The icon text
} else {
return null;
}
The kb.whether function will test whether we are looking at something of type SIOC MicroblogPost. More on the kb later.
Step 2 — Initialize the Render Function
The first thing to initialize is the tabulator knowledge base. The following code will go in the render() function.
var kb = tabulator.kb;
The knowledge base is an indexed database of all the information you will store. It allows many features such as fast querying and utility functions. As you browse the web of data, the knowledge base is automatically populated. The next thing we will do is set up namespaces.
var SIOC = tabulator.rdf.Namespace("http://rdfs.org/sioc/ns#");
var dc = tabulator.rdf.Namespace("http://purl.org/dc/elements/1.1/");
var FOAF = tabulator.rdf.Namespace('http://xmlns.com/foaf/0.1/');
Once we have the knowledge base in place, we add the popular namespaces for the FOAF, dublin core and SIOC ontologies.
Step 3 — Query the Knowledge Base
We will use the kb.any function to get the values of data points for our microblog post. The function queries the knowledge base in a similar way to NoSQL or map reduce style databases. In this case we will get the avatar, name, content and date of the microblog post.
var content = kb.any(subject, SIOC("content"));
var date = kb.any(subject, dc("date"));
var maker = kb.any(subject, FOAF("maker"));
var name = kb.any(maker, FOAF("name"));
var avatar = kb.any(maker, FOAF("depiction"));
Now that we have our data we can go ahead and display it.
Step 4 — Draw the Pane
Now that we have our data, all that’s left is to draw the microblog post. I’m using a simple native javascript commands of createElement, createTextNode and appendChild. However tabulator also works with jQuery too.
var postLi = document.createElement("div");
postLi.className ="post";
main.appendChild(postLi);
var img = document.createElement("img");
img.src = (""+avatar).slice(1,-1);
img.height = img.width =50;
img.className ="postAvatar";
postLi.appendChild(img);
var nameHeading = document.createElement("h3");
nameHeading.appendChild(document.createTextNode(name));
postLi.appendChild(nameHeading);
var contentDiv = document.createElement("div");
contentDiv.appendChild(document.createTextNode(content));
postLi.appendChild(contentDiv);
var dateDiv = document.createElement("div");
dateDiv.appendChild(document.createTextNode(date));
postLi.appendChild(dateDiv);
The basic styles live in an existing file, mbStyle.css, so I have just reused that.
Step 5 — Test the Microblog Post
If all has gone well your file should look like the following gist. When clicking on a microblog post such as this test post, you should see something like the image above.
Summary
We’ve seen how to add a simple pane to The Tabulator, how to set up and query the knowledge base, and how to display a new pane in the tabulator. In future blogs we will show how to use Tabuator’s read and write functions to both render, and update, the web of data!
Last time, we looked at how to install The Tabulator as a Firefox extension. Although tabulator can also run as a chrome extension or a JavaScript shim, one advantage of the approach outlined is that you can dive in to the code and make changes.
We’re going to look at how to create a new ‘Pane’ and expand slightly on the developer notes. For this tutorial you’ll need a text editor and basic JavaScript knowledge.
What is a Tabulator Pane?
Panes are views for displaying different types of data, and creating apps that are data driven. Although tabulator has many generic data panes, for viewing, querying and editing data, it can be handy to have vertical specific panes, too.
For example for a Person entity you may want a social style pane that allows updates to your timeline, for a publication you may want a special reader, or for your photos you may wish to develop a gallery pane. In this two part tutorial I’ll show how to display a microblog post in a pane.
Step 1: Find an Icon
Each pane will normally require an icon. There are many icon repositories on the web, for this I used, openiconlib which has conveniently sized 22×22 sized icons under LGPG.
The icons are stored in content/icons from the main source tree. In our case we will save the 22×22 PNG under /content/icons/microblog/microblogPost.png
Step 2: Add the Icon to Tabulator
Next we need to add the icon to tabulator and this is done in the file located at /content/js/init/icons.js. Add the following line:
To add the pane we need to create a new JavaScript file located at /content/js/panes/microblog/
tabulator.panes.register({
icon: tabulator.Icon.src.icon_mbpost,//This icon should be defined in icons.js
label:function(subject){//'subject' is the source of the documentif(true){return"MicroblogPost";//The icon text}else{returnnull;}},
render:function(subject, document){var newDiv = document.createElement("h2");var newContent = document.createTextNode("Microblog will appear here!");
newDiv.appendChild(newContent);return newDiv;}},true);
The (true) condition means that this icon will always appear (more on this in part 2). The render function will simply display a generic heading for testing purposes. Later we will show how to query an actual microblog and display the fields.
Step 4 — Load the Pane and Test
Image: New pane Icon added to Tabulator
We’re now ready for the final step. Add the line below to /content/js/init/init.js and once done you should see the icon on any data that the tabulator imports.
If all has gone well you should see the new icon appear in tabulator, after restarting. Try clicking the following test link to see if you have been successful!
What’s Next?
We’ve seen how to add a simple pane to The Tabulator. In the next part we will look at how to get data items from a real microblog post, how display the icon conditionally and how to style the page. The ultimate goal here is to be able to both read and write microblog posts, and share them with your social graph, using web standards.
The World and The Web, was rocked this month to learn about centralized access to data storage, by the controversial prism surveillance program. Microsoft (2007), Yahoo! (2008), Google (2009), Facebook (2009), Paltalk (2009), YouTube (2010), AOL (2011), Skype (2011), and Apple were implicated, with many commentators concerned by the loss of privacy.
Yahoo! continues its Linked Data adoption with the announcement the open-source code release and public demo of Glimmer, a search engine for RDF data. Based on the Hadoop search engine technology, it allows querying of the web data commons knowledge base of over 750 million triples.
IndieWeb, a gathering of web creators, sharing technology to empower users to host their own user profile, had its annual gathering, in Portland Oregon. The Webmention technology that we covered previously was tested in the wild. Also a an interesting new system, WebFist, was launched which allows users to write mirrored claims based on their email address.
Communications and Outreach
Unless you’ve been living under a rock, you’ll have heard of the recent rise to fame of bitcoin, the peer to peer crypto currency. Bitcoin has it’s own web of trust for the OTC (over the counter) market. The founder (aka nanotube) has agreed to let us bootstrap their web pages with a trust based ontology. I made a short proposal to help us develop along these lines.
Mozilla mentioned that they are also in the process of created their open badges system, so perhaps a collaboration and shared concepts could be possible.
Community Group
RWW welcomes Erik Mannens and Miel Vander Sande from iMinds Multimedia lab. Some of you may recall their recent work on R&Wbase: git for triples, presented at WWW 2013. The wiki updated with a section for newcomers including the newly minted Linked Data Glossary.
Sandeep Shetty has been leading the way with two new read/write protocols in the space of two months. WebMention has been gaining traction and was tested at indie web camp 2013. But also he has developed a system for federated “likes”. Looking forward to testing this out with my web identity!
Applications
Congratulations go to W3C stalwart, Sandro Hawke, a recipient of the Knight Prototype Fund, and will be developing a read write cloud storage application called Crosscloud. CrossCloud consists of a set of protocols and tools that allows providers to give individuals control of their data, choose who can access it and move it to other systems as needed.
A new authentication protocol, hawk, from the people that brought us OAuth promises to correct a few of the issues. It seems to work nicely with URIs as identifiers so perhaps can be a universal authentication system for the web. Finally, I put together a quick intro on how to install tabulator in firefox, more to come in this series next month, as I hope to give a demo of the social pane interacting with other networks.
The Tabulator project is a generic data browser and editor. With this technology you are able to view Linked Data, drill into specific details of that data, and send updates to the Web.
Why Should I Use Tabulator?
The Original WorldWideWeb Browser / Editor
The very first browser for the web (actually called WorldWideWeb) was actually both a browser and an editor. The reason for this is that the vision of the web was to be an interactive experience, rather than, read only. Indeed, the term we use today, “Browser”, implies read but not write. The tabulator project aims to change that.
How Do I Install Tabulator?
One way to install tabulator is as a firefox extension. This involves downloading and making the source then putting a line in your extensions directory.
If tabulator is working, you should see the “Data Browser” entry in your Tools menu. Another place you can start to browse data is from any vocabulary.
This was a basic tutorial on how to install the Tabulator. In later series I’ll show how it can be used to create and edit data, to run various panes, and to use a client side social network as part of the federated social web.
WWW 2013 took place this year, in Rio de Janeiro, Brazil. There was a packed program, including an interesting workshop entitled “Linked Data on the Web“, four papers of which, were dedicated to the Read Write Web.
The big news in linked data is that gmail has started to add JSON LD to their popular email service. This allows developers to embed structured data into an email, in the form of Reviews, RSVPs, Interactive actions and Flight cards. Response has been generally positive to this move, with perhaps the possibility for couple of minor tweaks to the markup.
The RWW group welcomes new members. In particular, we had a great introduction from read write web veteran, Henri Bergius. Henri has been working on read write topics for a number of years. Notably midgaurd in the 1990s, and more recently, the impressive create.js. If you’re unfamiliar with Henri’s work you may enjoy this video that goes through many core concepts.
Community Group
There has been some discussion on the mailing list, but also with the semantic web group, and some IETF folks as to the best way to use HTTP to identify a user to a server. This would enable a user to identify itself to a server without having to rely on the subjecctAltName field in a client side TLS certificate, or other methods. Thought had been to reuse the “From” header, however this seems tightly bound to email. Current thinking is that we draft text for a new header, then find a name for it.
Applications
Our co-chair, Andrei Sambra, met the developers of the Cozy Cloud project in Paris. There’s hope that this system can be combined with the my-profile project to become a kind of read write web example of a social dashboard. Cozy Cloud comes with a dozen or so cloud enabled apps, and has also been short listed for the LeWeb London best startup competition, so wishing them best of luck!
Last but not least…
Activity Streams, the popular social network data exchange format, have been dipping their toes into Linked data with, Activity Streams 2.0, a JSON LD powered activity stream. This currently does not have official standing but the reception has been good, and there is talk of pushing it through the IETF. Hopefully this can finally lead to a united and interoperable social web for all!
It was exactly ten years ago, that Richard MacManus wrote his seminal article entitled, ‘The Read/Write Web‘. In a time when ‘weblogs’ were a new phenomenon, and Facebook and Twitter were but twinkles in their founder’s eyes, it’s very much worth reflecting on just how far the RWW has come in the last decade!
A new acronym, WYSIWYM, was coined with the announcement of the impressive markup tool, RDFaCE. Watch the screencast to see ‘What You See Is What You Mean’, in action.
The big announcement of the month came from Manu Sporny who demonstrates the new Payswarm Linked Data Payments Protocol in action. The whole suite includes many important solutions, such as identity, digital signing, key management, encryption and, of course, payments!
Communications and Outreach
There is been more interaction with the W3C payments group on the newly implemented payments protocol. There was some discussion about using WebID as a decentralized identity system. Essentially payswarm are already using HTTP URIs to denote an agent so there seems to be a close similarity. Now we can tie these to PEM keys and allow signatures and encryption. That is going to give many new options for identity, auth, secure payments and messaging.
There has been some talk about extending the “from” header to allow anyURI as wells as the currently suggested email. This has come up a few times in the past and could be a neat way to identify a user. There is a firefox plugin which some people are using already.
A new protocol, Webmention, which is in its early stages, and allows federated commenting on blogs has had some buzz on the web. It is also very similar to the semantic pingback protocol many systems use already.
Applications
The first commercial integration of linked data payment systems was launched in the form or ‘meritora‘. The team behind it, digital bazaar, have also been driving forces in the payswarm, rdfa, json ld and webid efforts. Great to see so many web scale technologies come together in a new system!
There was a look at Daniel Applequist’s integration to the internet of things and cosm to write his room temperature to the web in realtime.
Last but not least…
The German Wikimedia Foundation has announced that its Wikidata project has now been deployed on all language versions of Wikipedia and is ready for use around the world. Wikidata – the first new Wikimedia project since 2006 – “provides a collaboratively edited database of the world’s knowledge”. Congrats on this big milestone and reaching their 12 millionth linked data item!
Some excitement on the web as the new version of HTTP (named HTTPbis) gets closer to being launched. Kingsley has pointed out some important details related to URLs and the Content-Location header.
Linked data continues it’s steady progress with many of the world’s libraries publishing their data using the VIAF endpoint.
SPARQL 1.1 has been voted an official W3C REC, meaning we now have, a long awaited, read write query language for the web.
Communications and Outreach
There has been good progress with with the WebID community group, in fixing some bugs in the cert ontology. Also adding DSA keys, and discussion of further work. I also informally talked to the bitcoin foundation, about creating a bitcoin ontology. It’s a hope of mine that the read write web can be soon used for payments, and we seem to be getting very close now.
Community Group
A relatively quite March in the CG, we did however welcome SPARQL 1.1 as a REC, giving read and write querying ability on the web. There has been some previous discussion about adding sparql to the “well known” pattern on websites, which is perhaps something that can be further incubated.
Some early feelers have been put out too, to see if anyone will be able to attend TPAC 2013 in China.
Applications
Some preliminary informal work has taken place to try and model crypto currencies for use in a read write ledger scenario. Things that could be possibly modelled going forward are, payswarm (already linked data compliant), bitcoin, litecoin and ripple.
I’ve spoken to people at the bitcoin foundation about creating an ontology which could hopefully be an interesting use case for the read write web, working with interesting distributed computing problems such as, network synchronization, race conditions, the Byzantine generals’ problem, double-spending and reputation based trust. Little in the way of prototypes at this second, but definitely more to come in this space!
Last but not least…
Google embrace the realtime read write web with their announcement of Google Drive Realtime API. There have already been some previous RWW experiments with the Google Drive system, so it will be interesting to see what apps can be built on top of this!
Realtime communications were in play this month, with some impressive demos of firefox and chrome talking to each other, using the W3C WebRTC protocol. For those wishing to try it out, some of this functionality has been abstracted in a developer friendly API, called PeerJS. On the social front, Google have also announced a sign-in process for their social application platform, Google+.
Lots going on in the RWW, the highlight of which was probably the release of the Drupal WebID integration by Stéphane Corlosquet. Account recovery and pairing were also fleshed out on the mailing list, this month, with some more demos.
Communications and Outreach
Over at the Web Application Store CG, three sets of manifests are in the process of being compared: W3C Widgets, the Chrome app store and Mozilla marketplace. There has been talk of standardization which would be invaluable in delivering read write apps to the web.
Mozilla have announced a system of payments for their marketplace, and for firefox OS. In the W3C Payments CG, there has been some discussion with Kumar McMillan, of Mozilla, on issues such as security and linked data integration. Their receipt protocol looks promising, and could perhaps be used in conjunction with the linked data apps to provide payments.
Community Group
This month in the community group there have been some great demos. The first demonstrates conditional access to DropBox, SkyDrive, GoogleDrive, Box.net and Amazon S3. Another shows multi protocol login to MediaWiki.
We have discussed two long standing problems and found some solutions. One is account recovery and the other is pairing of devices. Andrei has explained how both of these can be solved, with a full implementation in my-profile.
Applications
As previously mentioned, Stéphane Corlosquet, has announced his Drupal integration of WebID. While Drupal 7 already has semantic elements, this can potentially help bring user centric linked data to a large portion of the Web. There is a working demo here.
For those living on the bleeding edge, it’s now possible to experience realtime updates over turtle using tabulator, data.fm and curl. Currently in production, the “updates via” branch of data.fm provides support for (secure) websockets. This is best tested in the Chrome browser, navigate to, say, http://chat.data.fm/dig#test. Then try to modify this file either by hand, from the UI or using curl ( curl -H “Content-Type: text/turtle” -X PUT -T dig http://chat.data.fm/ where ./dig is the turtle file) and watch the text update in realtime!
Last but not least…
For those following the FreedomBox project it has reached the first milestone of the software stack with version 0.1 being released. FreedomBox aims to be a free software distributed system that allows you to keep all your logs and social data in the safety of your on home. Congrats on reaching version 0.1, looking forward to future releases!