Warning:
This wiki has been archived and is now read-only.
Textual Bodies
Contents
Representation of Textual Bodies
This page discusses possible solutions for representing plain textual bodies, which are strings without structure or any other markup. Possible solutions as well as pro and con arguments were collected from the following discussion threads:
- http://lists.w3.org/Archives/Public/public-openannotation/2013Jan/0016.html
- http://lists.w3.org/Archives/Public/public-openannotation/2012Jul/0067.html
Current Solution: Represent All Textual Bodies using BNodes or UUID nodes
Spec: http://www.openannotation.org/spec/future/core.html#BodyEmbed
Model
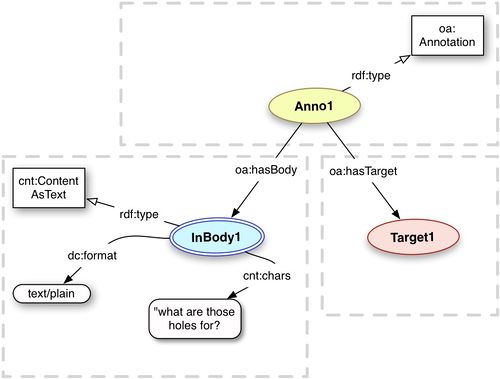
Example
flickr:notes/72157625204794737 a oa:Annotation ; oa:hasBody <_b1> ; oa:hasTarget <http://www.flickr.com/photos/nationalmediamuseum/3588905866#xywh=307,163,88,106> . <_b1> a cnt:ContentAsText, dctypes:Text ; cnt:chars "what are those holes for?" ; dc:format "text/plain" .
Pros
Consistency: all oa:hasBodies are nodes (resources or blank nodes); client doesn't need to check whether a node might be literal (Rob, Paolo, Bob)
- It seems GoodRelations has a similar (yet different) approach (what the call "Dynamic Data Granularity") http://lists.w3.org/Archives/Public/public-vocabs/2013Jan/0120.html or at least that is my interpretation of it (Paolo)
Things like CNT are not very difficult to program against in any platform where RDF can be handled in the first place (Bob)
Serialization in JSON-LD (recommended syntax for OA) is trivial (Rob)
(Extended slippery slope consistency argument) Many of the Textual_Bodies#Cons apply to one degree or another for other aspects of the OA model. Treating textual Bodies specially suggests doing so for these other cases also. For example users may find it inconvenient to provide an ISO 8601 date and so might require free text for oa:annotatedAt. Similarly, many users may want to provide only an annotator name, so there is an argument to not require oa:annotatedBy to be a foaf:Agent. --Robert Morris 14:55, 17 January 2013 (UTC) (Bob)
- Good point. The counter-argument (but it needs discussion, see below) is that in the case of oa:annotatedBy the "ontological distance" between the string and the agent is much much bigger than one between a string and a comment. - Antoine
Further, it would encourage embedding all resources as literals, including CSS Styles, SVG Selectors and so forth, which is highly undesirable. (Rob)
Cons
Many real-world use cases use plain text literals (e.g., Flickr), which can be directly represented as such (Bernhard)
- This is a poor characterization of the issue. The real world use cases do not use plain text literals; existing models used to convey these use cases do. The Open Annotation model aims to improve upon those existing models, otherwise we would just use one of them. OA does not, for example, use the Context node from Annotea, instead it introduces the Specific Resource model that is more consistent and flexible. The same applies here. (Rob)
- As above. I'd argue that in the case where implementers would like to use strings, it's because they don't have any other information on the object, other than it's a string -- someone has just typed something in a textbox, you don't know if it's a personal comment, a subject annotation, etc. I agree that if the application has more info on the object itself, one could lift it to a higher ontological status. -- Antoine
- Someone and they don't know who it is? And they don't know what the time is for when it it was created? And they don't know the media type (more plausible)? Basically "developers want to", which is actually the next bullet, is an undefeatable argument, but equally there are developers who don't want to write two sets of code. --Rob
- someone = 'a user'. A flickr user. On simple flicker-kind of systems, you just have a string. Or more precisely, you have more properties like creation time, but they are annotation-level, I'd argue. Not body-level. -- Antoine
- Someone and they don't know who it is? And they don't know what the time is for when it it was created? And they don't know the media type (more plausible)? Basically "developers want to", which is actually the next bullet, is an undefeatable argument, but equally there are developers who don't want to write two sets of code. --Rob
- As above. I'd argue that in the case where implementers would like to use strings, it's because they don't have any other information on the object, other than it's a string -- someone has just typed something in a textbox, you don't know if it's a personal comment, a subject annotation, etc. I agree that if the application has more info on the object itself, one could lift it to a higher ontological status. -- Antoine
It would raise the bar for software developers, who have simple cases and will not understand why they should program against a model which introduces an extra level of complexity (Antoine)
- The blank node raises the bar very slightly for producing applications, but lowers it more for consuming applications that do not have to check multiple options for how embedded bodies are modeled. As the axiom goes, there are more clients than servers, and thus the benefit is to have client development easier. Further more, client developers would have to program against it anyway as the non-literal case is also required. It just adds work for all client developers and thus this point argues in favor of the current blank node solution. (Rob)
- Agreed on the longer run, once the model is being used. The problem is that OA is a standard in infancy. Raising the bar for data producers can mean a much lower adoption rate and data available - and other proposals being used instead. -- Antoine
- Yes, it's possible. It's also possible that it increases the adoption rate as the value and consistency of the annotations that are produced are higher. --Rob
- Overall, I think the "developers" argument comes out even. --Rob
- Agreed on the longer run, once the model is being used. The problem is that OA is a standard in infancy. Raising the bar for data producers can mean a much lower adoption rate and data available - and other proposals being used instead. -- Antoine
It is unclear how to make annotation with (XML) typed literals (Antoine) but no one had a use case for it (Rob)
- Firstly, this has no bearing on simple textual bodies. 2: The Content in RDF spec has a ContentAsXML class. 3: no use case. 4: You could just embed it as ContentAsText and give it the appropriate MIME type. 5: It is conversely unclear how to embed resources that do _not_ have a datatype specified in RDF. So this is a pro for the current solution, not a con as there is a single method to do so. (Rob)
- OK, it's not on textual bodies but on typed literal ones. On 3 I had made the point myself on your behalf ;-). On 5 I don't understand: what are these resources, if not plain literals? On the rest: dependency on Content in RDF is a danger. To my knowledge nobody is using it in the RDF community, and I hypothesize that it's because everyone just hates reifying literals. This is why rdf:value almost died, by the way. -- Antoine
- 3: Yes :) 5: That was unclear. My badly expressed point was for data that doesn't have a datatype definition, you would still need to use a resource and give it a dc:format. Now there are two ways to do the same thing: literal with datatype, and Content as Text with dc:format. Which is bad for interoperability. -- Rob
- yes, but then we'd be opting for the less standard option (since CNT is not used much in the RDF community, to remain polite). - Antoine
- 3: Yes :) 5: That was unclear. My badly expressed point was for data that doesn't have a datatype definition, you would still need to use a resource and give it a dc:format. Now there are two ways to do the same thing: literal with datatype, and Content as Text with dc:format. Which is bad for interoperability. -- Rob
- OK, it's not on textual bodies but on typed literal ones. On 3 I had made the point myself on your behalf ;-). On 5 I don't understand: what are these resources, if not plain literals? On the rest: dependency on Content in RDF is a danger. To my knowledge nobody is using it in the RDF community, and I hypothesize that it's because everyone just hates reifying literals. This is why rdf:value almost died, by the way. -- Antoine
what will happen in multilingual environments? CNT has no recommended patterns for describing the language of its ContentAsText node (should it be a tag on the object of cnt:chars? A specific property attached to the cnt:ContentAsText node) (Antoine, new)
- Either add dc:language (which could be added to the spec) or a language tag. (Rob)
- I'm ready to completely forget this con as soon as the OA spec includes something on languages - Antoine
- We were waiting on the Content in RDF folk. I propose adding a dc:language recommendation to be consistent with dc:format. -- Rob
- yep. But (connected to above argument) RDF folks will find it really upsetting that we don't use language tags. This will jeopardize interoperability with multilingual data in RDF applications. - Antoine
- We were waiting on the Content in RDF folk. I propose adding a dc:language recommendation to be consistent with dc:format. -- Rob
- I'm ready to completely forget this con as soon as the OA spec includes something on languages - Antoine
Working with BNode raises many practical problems (cannot compute hashes over annotations, cannot do diff and patch, etc.). The use of Bnodes is therefore very controversial among RDF practitioners. Also the alternative, the use of UUID nodes for simple string bodies, introduces unnecessary cost because it requires the generation and representation of at least one UUID per annotation (Bernhard, new)
- You can't compute a hash over a concept, or a graph, only a serialization. As serializations of the same graph differ greatly this is not a consideration. Isomorphism is more important, and is possible with blank nodes. Diff/Patch are also not concerns and have the same issues with any RDF serialization. This is an argument against the inconsistency of RDF serializations in general, not against blank nodes which are defined as serialization level constructs. Further, in the recommended serialization this is not an issue as JSON-LD does not require a local "identifier". (Rob)
Possible Solution 1: Allow Literals for oa:hasBody
Model
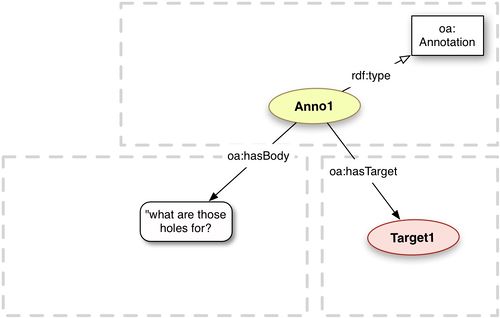
Example
flickr:notes/72157625204794737 a oa:Annotation ; oa:hasBody "what are those holes for?" ; oa:hasTarget <http://www.flickr.com/photos/nationalmediamuseum/3588905866#xywh=307,163,88,106> .
Pros
--Jacob Jett 15:39, 17 January 2013 (UTC)I think this approach may be best with the caveat that we should attach a class to the body node, e.g., "'what are those holes for?' a oa:LiteralResource". This seems like a scenario that classing addresses well and hypothetically implementations will be looking at for bodies for classes anyway in order to detect bodies that are specific resources. If I'm reading the W3C punning-OWL article correctly then this solution should also align with that. Adding class this way is, to me, symmetrical with oa:SpecificResource. In the SpecificResource case we are minting identity for a portion of a web-resource, in this case we are stating that the (body) resource does not merit an identity distinct from the annotation resource itself.
- Clearly it is impossible to add a class to a literal. Hence this is an argument in favor of the blank node solution (Rob)
Simple pattern, for simple real-world needs and more complex patterns for structured descriptions" (Antoine, Bernhard, Raphael)
- Blank nodes are also a simple and more importantly consistent pattern. (Rob)
- OK then we can rename the pro as 'simpler pattern' vs. 'more complex' one. You just can't argue blank nodes are as simple as literals...
- Sure, I agree that literals are a simpler pattern than a blank node. However the argument is a continuation of the "developers want it" one, and my point is that the complexity of a blank node is much less a cost than having to write two sets of code. -- Rob
- OK then we can rename the pro as 'simpler pattern' vs. 'more complex' one. You just can't argue blank nodes are as simple as literals...
Literals bodies does not prevent the use of complex bodies. (Antoine, Bernhard)
- They simply add two ways to do the same thing, which is undesirable. If resources as bodies were NOT required, this would be a reasonable argument. (Rob)
- This smells like tautology: rephrasing it, 'if we allowed other things than bodies as resources, then you could both resources and other things.'
- The point I was trying to make was that "literals do not prevent the use of complex bodies" does nothing to argue for literals. If literals could entirely replace resource as body, then it would be an argument in favour. -- ROb
- fully agreed. I think we made the point because a couple of times we may have been interpreted as not being interested in complex bodies at all, and we wanted to avoid this in the conversation - Antoine
- The point I was trying to make was that "literals do not prevent the use of complex bodies" does nothing to argue for literals. If literals could entirely replace resource as body, then it would be an argument in favour. -- ROb
- This smells like tautology: rephrasing it, 'if we allowed other things than bodies as resources, then you could both resources and other things.'
schema.org has the same kind of approach. Some properties advertise classes resources as range; but the guidelines explicitly say that they can be used with simple literals instead (Antoine)
Looking at the documentation I read "We also expect that often, where we expect a property value of type Person, Place, Organization or some other subClassOf Thing, we will get a text string. In the spirit of "some data is better than none", we will accept this markup and do the best we can". (Paolo)
- Many other systems have a consistent approach where resources are required. (Rob)
- Yes, the tradeoff is how ready one is to jeopardize quick wide-scale adoption (see above and below) -- Antoine
- We disagree about the potential threat, and there's no way to quantify it. -- Rob
- alas... - Antoine
- We disagree about the potential threat, and there's no way to quantify it. -- Rob
- Yes, the tradeoff is how ready one is to jeopardize quick wide-scale adoption (see above and below) -- Antoine
Experience has shown (e.g., dcterms:creator) that many many who use properties like dcterms:creator use them with simple literals. (Antoine)
- And experience has also shown the parsing and reasoning problems with these solutions. (Rob)
- If Dublin Core had not offered some flexibility, helping to lower the bar for adoption while promoting more structured data on the sides, something like MARC would probably contemplate 10 more years of peaceful existence as exchange standard in the Library domain. And please ask Herbert if OAI-PMH would have had the same success if they had required dc:creator to be a complex resource and not accepted simple strings. In fact many OA data consumers may be happy to have strings too, because they won't be interested in more complex stuff -- Antoine
- And conversely look at all of the literature that shows how terrible simple dublin core in PMH is for interoperability, which is what we're trying to achieve. PMH was successful because it served a real need at the time and had community support; the simple dublin core requirement has received as many negative reviews as positive -- Rob
- Yes, and I'd be one not happy with simple DC. But between 'having OAI-PMH a success with simple DC' and 'risking OAI-PMH fail because it would be disallowing simple DC' my choice is clearly on the former option. In terms of interoperability the progress is huge! - Antoine
- And conversely look at all of the literature that shows how terrible simple dublin core in PMH is for interoperability, which is what we're trying to achieve. PMH was successful because it served a real need at the time and had community support; the simple dublin core requirement has received as many negative reviews as positive -- Rob
- If Dublin Core had not offered some flexibility, helping to lower the bar for adoption while promoting more structured data on the sides, something like MARC would probably contemplate 10 more years of peaceful existence as exchange standard in the Library domain. And please ask Herbert if OAI-PMH would have had the same success if they had required dc:creator to be a complex resource and not accepted simple strings. In fact many OA data consumers may be happy to have strings too, because they won't be interested in more complex stuff -- Antoine
Cons
It would be inconsistent with the rest of the model which allows any resource as a Body or Target, and thus would be a special case just for text in the Body. (current spec)
- RDF literals are resources, too. There are reasons (related to reasoning or syntax) for which properties with literals as objects are distinguished from properties with "fully-fledged" resources as objects. But they do not apply to all RDF-based models. (Antoine)
- But they do apply to this one, as reasoning over annotations created by text mining applications is a common, published use case, especially in the bioinformatics domain. (Rob)
It is not possible to represent a single property in OWL-DL as having a range of either a literal or a resource, and this is considered important for both reasoning and integration with other systems. (current spec)
- Many (maybe the majority) of use cases don't require OWL-DL compatibility because their goal is exchanging annotation data and not building up formal knowledge bases. Transitioning paths (e.g., transformation of plain literals to objects) could be a solution for those that require OWL-DL compatibility (Bernhard)
- Maybe, but it makes the use cases that do _require_ it _impossible_. This is a significant disadvantage. (Rob)
- In principle data consumers could refuse to ingest the datasets that make their base OWL2-DL. Are all cases (by the way which ones?) you're thinking really needing to load datasets that don't fit their prefered option? -- Antoine
- all serious implementations of OWL2 DL reasoners allow punning of properties. I therefore think it is unwise to decide on a convoluted way of representing this in OA just because of complying with a 'dead letter' in the OWL 2 specification (Rinke)
- OWL2 is very new! Less than a month old. So I imagine the number of "serious implementations" is very limited. Also: reference required to OWL2 spec that allows punning properties please. (Rob)
- The version you're looking at is a correction made after the OWL group has disbanded. The spec is a REC since 3 years already! http://www.w3.org/TR/2009/REC-owl2-overview-20091027/ -- Antoine
- Yes, my bad. Found F12 in OWL2 about punning properties, but it wasn't clear to me that it allows literal and object. I trust you (all) when you say that it does. -- Rob
- The version you're looking at is a correction made after the OWL group has disbanded. The spec is a REC since 3 years already! http://www.w3.org/TR/2009/REC-owl2-overview-20091027/ -- Antoine
- OWL2 is very new! Less than a month old. So I imagine the number of "serious implementations" is very limited. Also: reference required to OWL2 spec that allows punning properties please. (Rob)
It makes both the JSON-LD serialization and implementation more complex, as the type of the Body would always have to be determined. (current spec)
--Jacob Jett 15:40, 17 January 2013 (UTC)Aren't we doing this anyway since bodies can be specific resources?
- This argument is unclear? Why is it more complex to serialize a string than a complex object? (Bernhard) -> Maybe it's the consumption (parsing) of the serialization (Antoine, interpreting arguments by Bob and others)
- The JSON-LD context would have to not specify any default interpretation for the object of hasBody, and thus all serializations would need to explicitly use a dictionary/object construction to distinguish from a literal. If the object is always a resource, then the literal is interpreted as a URI. This adds complexity to the serialization.
While literals can have their language and datatype associated with them in RDF, there are other aspects of text that are important for interpretation that cannot be associated with a literal. Examples include the MIME type (text/plain vs text/html), the directionality (right-to-left versus left-to-right), the encoding (utf-8 vs ascii), plus of course metadata such as authorship, date of creation and so forth. (current spec)
- But this argument is not against allowing literals as bodies. It just says that in some case, the bodies are sophisticated, document-like resources. Fair enough. But I will argue (and many others will) that many scenarios don't need this. And that it's not reasonable to impose on these latter scenarios the representation details that the former cases need. Caricaturing a bit, it looks as if we prevented string value attributes in object-oriented programming, on the basis that some texts deserve to be treated as objects. (Antoine)
- Strings in Object Oriented programming are almost always objects eg: "fish".upper() so this is an argument in favor of treating them like resources. Many scenarios do not need identity, and this is covered by the blank node model. The argument is against having two different ways of doing exactly the same thing, when there are many many use cases where the more detailed information is required. (Rob)
- Interesting argument, in fact we could in the other direction argue that RDF literals are also RDF resources in order to push literals as objects of oa:hasBody ;-). I suppose String are resources, but you can't give them any attribute, which in turn allows for some simplicity in their processing, no? -- Antoine
- Strings in Object Oriented programming are almost always objects eg: "fish".upper() so this is an argument in favor of treating them like resources. Many scenarios do not need identity, and this is covered by the blank node model. The argument is against having two different ways of doing exactly the same thing, when there are many many use cases where the more detailed information is required. (Rob)
- One could easily default to process plain literals as text/plain (Antoine)
- And one could more easily use the information provided by the Annotation to process them using their given MIME type rather than having to default, frequently incorrectly, to text/plain. (Rob)
- What is this "more easily"?? -- Antoine
- A consumer can more easily determine a media type by reading it out of a property than inferring it by inspecting the data. -- Rob
- And remember, we're starting from cases where the annotations are with simple strings. What would be a case where someone types HTML in a textbox? - Antoine
- People type markup into textboxes all the time. Eg ... this wiki! Also the recent explosion of WYSIWYG "text box" editors. -- Rob
- Yes, but to me I'm ok with considering these complex strings. By text box I meant *really* simple, plain text. Which I believe still covers a lot of use cases.
- People type markup into textboxes all the time. Eg ... this wiki! Also the recent explosion of WYSIWYG "text box" editors. -- Rob
- What is this "more easily"?? -- Antoine
- And one could more easily use the information provided by the Annotation to process them using their given MIME type rather than having to default, frequently incorrectly, to text/plain. (Rob)
Given the previous point, the possibility for a resource to encode an embedded textual Body is essential. As the cost of using a blank node is minimal, the consistency of a single method for embedding content is deemed more important than the option of sometimes using a literal.
- Yes, but one additional triples means millions of additional ones -- I expect that cases of simple text annotation will be very very common.
- Number of triples is a minor concern, both for transfer and modeling. The model does not specify how Annotations are to be maintained, just transfered between systems. (Rob)
- If you tell me than at big sizes (try converting flickr annotations) a difference of 20-30% does not matter, then I'll believe you. (for the 20-30% see below) -- Antoine
- For transfer, in JSON-LD, it adds 6 characters. That's maybe 2%. I assume that Flickr are not going to redo their entire database to use RDF natively, nor should they, and nor does anyone have to. -- Rob
- 6 characters? I'm talking about the triples on the body resource with the SHOULD: type, dc:format, etc.
- For transfer, in JSON-LD, it adds 6 characters. That's maybe 2%. I assume that Flickr are not going to redo their entire database to use RDF natively, nor should they, and nor does anyone have to. -- Rob
- If you tell me than at big sizes (try converting flickr annotations) a difference of 20-30% does not matter, then I'll believe you. (for the 20-30% see below) -- Antoine
- Number of triples is a minor concern, both for transfer and modeling. The model does not specify how Annotations are to be maintained, just transfered between systems. (Rob)
- I buy less the argument when it is recommended to type the resource with a dcmitypes class and with cnt:ContentAsClass and to give its MIME type using dc:format. That's 4 triples, not 1. And many of them can be seen as of dubious added value (Antoine) . Give an example that is really only one extra triple, not the four extra triples I count in the current spec (Jacco)
- One _required_ triple. The difference between "anno hasBody literal" and "anno hasBody bnode ; bnode cnt:chars literal". You _cannot_ express the other three recommended triples at all using a literal. This is the same non-issue as the previous (Rob)
- Not sure I get the second part. I cannot, and that's quite in the design, because I don't want them. So indeed it's a non-issue. As for the "one required" triple, I agree, but then the spec could be more explicit about simpler cases. For now the rdf:typing and dc:formatting mentioned above has a big SHOULD that nothing mitigates. -- Antoine
- By the second part I mean that if you want to express the recommended type and format you cannot use a literal. The spec recommends what is good for interoperability, and that is being explicit about the resources, not just hoping that consumers will figure it out. However, it intentionally does not use MUST, to allow for the simple cases where either nothing is known or producers do not want to put in the 5 minutes extra effort to follow the recommendations. -- Rob
- OK. For the 'second part'. Then you didn't have to convince us: if there's more data available, and it's potentially useful, I don't think we'd recommend against using it! On the 'non-MUST' part I still think the spec should be more explicit about it. (ok, that's not a crucial argument in this discussion, but still I'm convinced it would alleviate some issues) - Antoine
- By the second part I mean that if you want to express the recommended type and format you cannot use a literal. The spec recommends what is good for interoperability, and that is being explicit about the resources, not just hoping that consumers will figure it out. However, it intentionally does not use MUST, to allow for the simple cases where either nothing is known or producers do not want to put in the 5 minutes extra effort to follow the recommendations. -- Rob
- Not sure I get the second part. I cannot, and that's quite in the design, because I don't want them. So indeed it's a non-issue. As for the "one required" triple, I agree, but then the spec could be more explicit about simpler cases. For now the rdf:typing and dc:formatting mentioned above has a big SHOULD that nothing mitigates. -- Antoine
- One _required_ triple. The difference between "anno hasBody literal" and "anno hasBody bnode ; bnode cnt:chars literal". You _cannot_ express the other three recommended triples at all using a literal. This is the same non-issue as the previous (Rob)
It is important to distinguish textual tags from general comments. This would not be possible with just a literal.
- This distinction can be made based on the annotation motivation types (e.g., oa:commenting; oa:tagging) (Bernhard)
- If motivations are only optional, this may not really work. On the other hand, typing with oa:Tag is also optional, in essence. As a matter of fact the current oa:Tag pattern is not very informative: the convention to use oa:Tag could be replaced without any loss of information by a convention of using oa:tagging as the motivation of the Annotation, no? (Antoine, new)
- As there can be multiple bodies, some of which are tags and some not, the use of Motivation is not a possibility. Thus it is impossible to distinguish between the two cases. This is a huge disadvantage as it cuts the times when a literal body could be used in half. (Rob)
- I'd be willing to agree on this, but only upon seeing an annotation with oa:tagging or oa:commenting with several bodies of different types. For now I just can't think of one. -- Antoine
- Ask Bernhard about this. He has tagging and commenting in the same annotation for maps. -- Rob
- As he wrote the first line in this thread I did not thought of this - Antoine
- Ask Bernhard about this. He has tagging and commenting in the same annotation for maps. -- Rob
- I'd be willing to agree on this, but only upon seeing an annotation with oa:tagging or oa:commenting with several bodies of different types. For now I just can't think of one. -- Antoine
- As there can be multiple bodies, some of which are tags and some not, the use of Motivation is not a possibility. Thus it is impossible to distinguish between the two cases. This is a huge disadvantage as it cuts the times when a literal body could be used in half. (Rob)
Further, literals are incompatible with the multiplicity constructs. (Rob)
- One can still use resource nodes if multiplicity constructs are required
- Meaning that there are many situations when you would expect to use a literal and cannot. Whereas the blank node model is always consistent. (Rob)
- Is the proposal that in this case no plain literals would be supported? If so very little is gained over the use of cnt: or something like it. Consuming software would still have to support both. If it doesn't, what is the meaning of an annotation in which some bodies are literals and some are resource references? (Bob)
- Fully agree on this: the point is that for these cases that have complex annotations (and this seems like one) then bodies as resources should be used. We're not saying that all lunches should come for free :-) -- Antoine
- And I'm saying I don't the majority of developers to pay extra to make the lunch of the lazy developer slightly cheaper :) -- Rob
- It seems we're coming back to the same dilemma. Note that I wouldn't put it entirely as laziness. Developers having to handle simple cases only may rightfully object to being imposed more complex stuff. Though the laziness certainly kicks in when appreciating how much the extra complexity hampers development in reality - Antoine
- And I'm saying I don't the majority of developers to pay extra to make the lunch of the lazy developer slightly cheaper :) -- Rob
- Fully agree on this: the point is that for these cases that have complex annotations (and this seems like one) then bodies as resources should be used. We're not saying that all lunches should come for free :-) -- Antoine
Possible Solution 2: Shortcut property for plain text bodies
Model
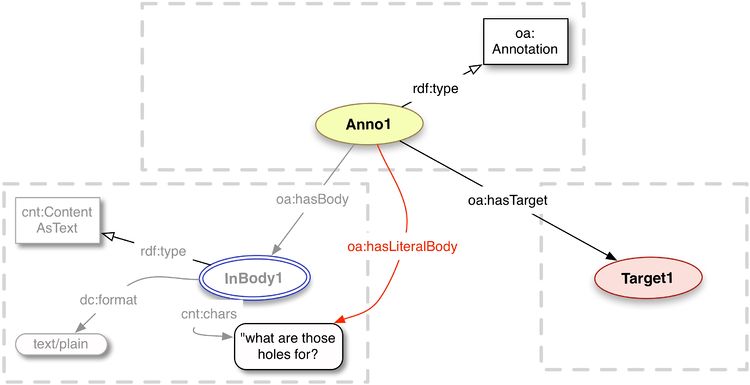
Example
flickr:notes/72157625204794737 a oa:Annotation ; oa:hasLiteralBody "what are those holes for?" ; oa:hasTarget <http://www.flickr.com/photos/nationalmediamuseum/3588905866#xywh=307,163,88,106> .
Guidelines on when to use oa:hasLiteralBody and oa:hasBody with (simple) embedded text content
- bodies that are specific resources must obviously use oa:hasBody
- users with constraints on annotation bodies should use oa:hasBody, though they will probably be able to express some constraints (e.g., cardinality constraints) in a simple way with oa:hasBodyLiteral
- users with unconstrained bodies can use the simple pattern (oa:hasBodyLiteral)
- ...
Conversion Axiom
The following axiom can be used by OA implementers to convert data from one less-desired pattern into their pattern of choice. It is not mandatory to apply the conversion rules when producing or consuming OA data; but it provides the only solution for full interoperability between two patterns.
The property chain (oa:hasBody,cnt:chars) is equivalent to the property oa:hasLiteralBody.
flickr:notes/72157625204794737 a oa:Annotation ; oa:hasLiteralBody "what are those holes for?" ; oa:hasTarget <http://www.flickr.com/photos/nationalmediamuseum/3588905866#xywh=307,163,88,106> .
is equivalent to
flickr:notes/72157625204794737 a oa:Annotation ; oa:hasBody [ cnt:chars "what are those holes for?" ]; oa:hasTarget <http://www.flickr.com/photos/nationalmediamuseum/3588905866#xywh=307,163,88,106> .
Pros
Using oa:hasLiteralBody allows a direct mapping to schema.org Comment and UserComment (Bernhard)
- In schema.org, the Comment's content is expressed via the "text" property that has range Text only. I am not sure if, according to the guidelines, swapping Text with a Thing is also expected behavior. It is also interesting to notice the presence of the property 'mentions' (range Thing):Indicates that the CreativeWork contains a reference to, but is not necessarily about a concept. It seems very close to tagging (Paolo)
- In schema.org, the UserComments (not sure why it is plural) content is expressed via the "commentText" property that has range Text only. Again, I am not sure if, according to the guidelines, swapping Text with a Thing is also expected behavior.(Paolo)
No interference with current spec (Bernhard)
It is possible to specify simple "conversion rules" to switch data from one pattern to the other, as in axiom S55 in SKOS-XL. Data expressed in one pattern can be converted to the other, which enables to apply definitions/constraints that are specified only on the other pattern (Antoine)
The pattern specifies (as a side effect) how bodies-as-resources should be used in language-specific setting: a language tag has to be used on the object of the cnt:chars statement attached to the body resource (Antoine, new)
Cons
Simple but wide-spread use of bodies requires a separate property (Bernhard)
More properties and patterns make the OA specification more complex to learn (only in absolute, because learners interested in the simple pattern would benefit) (Antoine)
This and the issue itself are conflating user needs with modeling requirements. There is no dispute that a cnt-like approach supports strings as the meaningful content of the Body (the user need). But in practice, this is easily solved with user interface software that only involves the user with adding strings. It really is not very difficult to make UIs that require of users only that they produce strings. (This point is Textual Bodies#Pros)(Bob) --Robert Morris 14:23, 17 January 2013 (UTC)
The definition of conversion rule is likely to be outside of OWL2(DL) (because property chains are for object properties) and even SPARQL CONSTRUCT queries and efforts like http://spinrdf.org/ (as conversion in one of the directions "creates" a blank node). On the other hand, this would help keeping aligned with the OA objective that any annotation base loaded with the full OA OWL ontology would remain in OWL-DL (Antoine, new) TODO: further investigation is required