Tag(s): unicode
Posts
UTC Document Register Now Public
The Unicode Technical Committee (UTC) document register is now freely available for public access. This change has been made to increase public involvement in the ongoing deliberations of the UTC in its work developing and maintaining the Unicode Standard and other related standards and reports. Open access to the document register makes it easier to search both current and historical documents for topics of interest, using widely available search engines. The UTC document register contains online documents dating back to 1997 and online registers for paper document distributions dating back to 1991.
New Unicode FAQ on Private-use Characters, Noncharacters and Sentinels
A new FAQ page devoted to the topic of private-use characters, noncharacters, and sentinels has been posted on the Unicode web site. This FAQ aims to clear up confusion about whether noncharacters are permitted in Unicode text, and how they differ from ordinary private-use characters. The recently published Corrigendum #9: Clarification About Noncharacters makes it clear that noncharacters are permitted even in interchange, and the new FAQ page addresses some of the fine points about their usage and about differences from other types of Unicode code points. The brief mentions of noncharacters in other FAQ pages have also been updated accordingly.
Are you unclear about what Unicode “noncharacters” even are? The new FAQ page also answers basic questions about noncharacters and private-use characters, and provides a bit of history about how they came to be part of the Unicode Standard.
Unicode 6.2, Core Specification is now available as paperback book
Responding to requests, the editorial committee has created a modestly-priced print-on-demand volume that contains the complete text of the core specification of Version 6.2 of the Unicode Standard. This 692-page volume may be purchased from Lulu.com for $17.24, plus shipping (prices are available in some other local currencies).
Note that this volume does not include the Version 6.2 code charts, nor does it include the Version 6.2 Standard Annexes and Unicode Character Database, all of which are available only on the Unicode website.
Unicode version 6.1 announced
The Unicode Consortium has announced the release of Version 6.1 of the Unicode Standard, continuing Unicode’s long-term commitment to support the full diversity of languages around the world. This latest version adds characters to support additional languages of China, other Asian countries, and Africa. It also addresses educational needs in the Arabic-speaking world. A total of 732 new characters have been added.
This version of the Standard also brings technical improvements to support implementers. Improved changes to property values and their aliases mean that properties now have easy-to-specify labels. The new labels combined with a new script extensions property means that regular expressions can be more straightforward and are easier to validate.
Over 200 new Standardized Variants have been added for emoji characters, allowing implementations to distinguish preferred display styles between text and emoji styles. For example:
26FA FE0F
26FD FE0E
26FD FE0F
Among the notable property changes and additions in Unicode 6.1 are two new line break property values, which improve the line-breaking behavior of Hebrew and Japanese text. Segmentation behavior was also improved for Thai, Lao, and similar languages.
Two other important Unicode specifications are maintained in synchrony with the Unicode Standard, and have updates for Version 6.1. These will be finalized in February:
UTS #10, Unicode Collation Algorithm
UTS #46, Unicode IDNA Compatibility Processing
8 days left for the Internationalization & Unicode Conference Call for Participation
The Unicode® Consortium will close its call for participation in the 35th Internationalization & Unicode® Conference (IUC 35) on Friday, March 25. If you want to talk at the conference, you should submit your proposal soon.
The Program Committee will notify authors by Wednesday, April 20. Final presentation materials will be required from selected presenters by Wednesday, August 3.
The conference will take place in Santa Clara, Calif., USA; October 17-19, 2011, sponsored by Adobe. The conference is produced by OMG®.
This is the premier conference on technologies and practices for the creation and management of global and multilingual software solutions. This annual event is praised for its excellent technical content, industry-tested recommendations and updates on the latest standards.
Unicode Version 6.0 – Complete Text of Core Specification Published
The Unicode 6.0 core specification includes information on scripts newly encoded in Unicode 6.0, as well as many updates and clarifications to other sections of the text. The release of the core specification completes the definitive documentation of the Unicode Standard, Version 6.0.
In Version 6.0, the standard grew by 2,088 characters. Over 1,000 of these characters are symbols used for text exchange on mobile phones. The Unicode Standard now also includes the recently created official symbol for the Indian rupee. After computers and mobile phones update to Version 6.0, the rupee sign will be available for use like the $ or € now.
In addition, this version adds many CJK Unified Ideographs in common use in China, Taiwan, and Japan,as well as characters for African language support, including extensions to the Tifinagh, Ethiopic,and Bamum scripts. Three scripts are supported for the first time: Mandaic, Batak, and Brahmi.
In October of 2010, the other portions of Unicode 6.0 were released: the Unicode Standard Annexes, code charts, and the Unicode Character Database. This allowed vendors to update their implementations of Unicode 6.0 as quickly as possible.
For more information on all of The Unicode Standard, Version 6.0, see http://www.unicode.org/versions/Unicode6.0.0/
Unicode locale extension BCP 47 Extension U published as RFC 6067
RFC 6067 specifies an extension to BCP 47. BCP 47 provides subtags that specify language and/or locale-based behavior.
Many locale identifiers require additional “tailorings” or options for specific values within a language, culture, region, or other variation. This extension provides a mechanism for using these additional tailorings within language tags for general interchange.
The maintaining authority for the extension defined by this document is the Unicode Consortium. The Unicode Consortium defines a standardized, structured set of locale data and identifiers for locale data in the “Common Locale Data Repository” or “CLDR”.
Unicode version 6.0 released
The newly finalized Unicode Version 6.0 adds 2,088 characters, with over 1,000 new symbols.
The October 2010 release includes the Unicode Character Database (UCD), Unicode Standard Annexes (UAXes), and code charts. With the release of these components, implementers are able update their software to Unicode 6.0 without delay. The final text of the core specification will be available in early 2011.

A long-awaited feature of Unicode 6.0 is the encoding of hundreds of symbols for mobile phones. These emoji characters are in widespread use, especially in Japan, and have become an essential part of text messages there and elsewhere. Unicode 6.0 now provides for data interchange between different mobile vendors and across the internet. The symbols include symbols for many domains: maps and transport, phases of the moon, UI symbols (such as fast-forward) and many others – including the symbol for mobile phone itself.
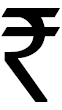
A late-breaking addition is the newly created official symbol for the Indian rupee. “With the help of the Indian government and our colleagues in ISO, we were able to accelerate the encoding process.” said Mark Davis, president of the Consortium. “Once computers and mobile phones update to the new version of Unicode, people will be able to use the rupee sign like they use $ or € now.”
CLDR 1.9 Collation Changes proposed
The Unicode CLDR committee is making Unicode locale-sensitive collation a major focus for the next release, CLDR 1.9. There are specific changes for a large number of languages, plus a change in the default ordering of punctuation vs symbols for all languages.
See the background document for more information:
http://www.unicode.org/review/pr-175.html
If you have any feedback on any of the actions, please contact the Unicode Consortium as described in the background document.
Review period for this issue closes on October 1, 2010.
Last Call draft for Unicode Locale extension published by IETF
In addition to providing the basis for language identification on the Web, BCP 47 language tags also are used to control language and culturally specific APIs on many systems. Based on work done by the Unicode Consortium, the proposed Language Tag Extension ‘U’ provides additional subtags that can be used to refine locale-based details such as calendar, sort order, and other locale details.
More information on Unicode Locales is available at the Unicode CLDR website or in UTS #35, LDML.
W3C® liability, trademark and permissive license rules apply.
Questions or comments? ishida@w3.org