Narrative
Steve divides the application into four parts:
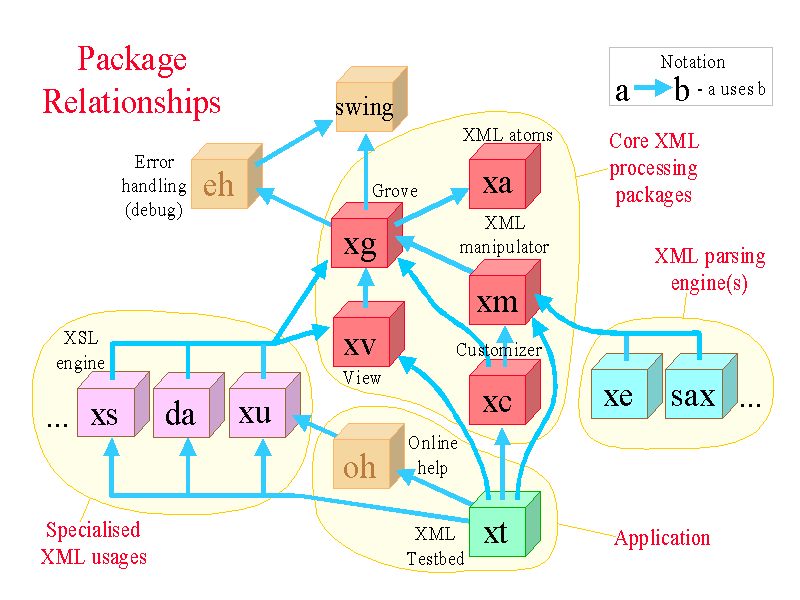
1. Core XML Processing
Five Java packages provide functions for representing and manipulating XML documents (including controlling, but not actually performing, parsing):
Any supported parser can drive the application, in a similar manner to SAX, but at a higher level. (SAX is, however, a supported 'parser'). The engine generates the xg grove as the parse proceeds, and also supports a progress bar (if the parser provides the necessary position information - which SAX does not).
Steve's own parser (package xe) is not covered in this presentation, but follows the lead of the other packages of dividing its processing among many classes; it has a parser class for each type of XML entity (and allows new parser classes to be added via the node type registry). This parser is incomplete, is not fast, and is non-validating, but functions reasonably well in practice.
3. Specialised XML Usages
The vanilla application manipulates vanilla XML documents, but semantic knowledge can be embedded in specialised classes. Three such usages are implemented: an XSL engine (incomplete), UI configuration, and rendering a database schema in XML via JDBC. The basis for expandability is to 'register' information about specific XML element types:
These ideas are brought together in the XML Testbed application (package xt), which implements them all and is also a basic XML authoring environment.
There is also an Online Help package (oh) containing a frame class for the display of HTML help. This also uses the xu package to configure its user interface, especially the menu of what help options are available. (A toolbar can be added simply by editing its XML configuration file, after obtaining the images to display on its buttons.)