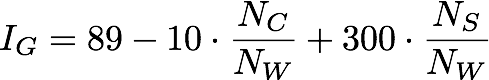
This extended abstract is a contribution to the Easy-to-Read on the Web Symposium. The contents of this paper were not developed by the W3C Web Accessibility Initiative (WAI) and do not necessarily represent the consensus view of its membership.
Reading and understanding texts containing long sentences, unusual words, and complex linguistic structures can be very hard for persons with cognitive or learning disabilities.
Knowing the readability level of a document, users have the opportunity to choose the most suitable text, from a collection of documents delivering the same information.
Considering that the availability of texts annotated with the proper level of readability is strictly relied to the availability of software supporting the authoring, and that the literature is still neglecting this aspect, we have been working on SPARTA2, a tool supporting the authoring of highly accessible texts.
The problem of readability is under investigation since 1920s, when educators discovered a way to use vocabulary difficulty and sentence length to predict the difficulty level of a text (DuBay 2004). Several formulas have then been proposed to predict the readability of texts, and the concept of "readability" itself has been deeply investigated.
The findings were that the two key aspects in measuring readability are structure and semantics. As "structure", the literature often refers to simple parameters such as the average number of syllables in words and the average number of words in sentences. The "semantics" is taken into account mainly by counting the number of "hard words" (with respect to some pre-compiled lists) that are present in the text. The Flesch Reading Ease formula (Flesch 1948) is a well-known index, based on the structure of the text, while the Dale-Chall formula (Chall et al., 1995) considers both aspects.
A more complex evaluation of the structure of text has been considered too difficult to implement in a formula, as one of the main goals of such formulas was simplicity. After all, the evaluation of readability formulas was carried out initially by hand, and then by means of simple computer programs. However, today, the availability of Natural Language Processing tools, powerful enough to extract several features about the syntactic structure of texts, permits to include such complex syntactic structures as a parameter of readability formulas.
SPARTA2 is a tool supporting the authoring of highly accessible texts. It provides two kind of information: numeric estimations of the complexity of texts, and warnings/advices about phrase structures that appear to be the problematic parts of the text.
In contrast with other approaches, SPARTA2 makes a distinction between readability and understandability as, in our opinion, these concepts capture different aspects of the complexity of the text: a text could be highly readable, since the syntax is extremely simple, but extremely hard to understand because of the lexicon used. In our approach, readability gives an evaluation about the structure of sentences, while understandability captures the lexical aspects (Barbieri, et al. 2005; Barbieri, et al. 2005b).
The Readability Index is composed of three sub-indices: the Gulpease Index, the Chunk Index, and the Chunk Type Index.
The Gulpease Index IG (Lucisano, et al. 1988) is a widely used readability formula for the Italian language (SPARTA2 currently analyses Italian texts; it is, however, easily adaptable to different languages). The formula is:
where NC is the number of character in the text, NW the number of words, and NS the number of sentences; the higher is IG, the simpler is the text readability.
The structure of the Gulpease Index suggests that texts with short words and short sentences tend to be more readable. This approach, which is similar to the Flesch’s one - and widely adopted in the literature on readability - does not take into account the deep structure of sentences. In other words, two sentences with the same NC / NW and NS / NW ratios could be very different in terms of readability, depending on their subject/verb/complements structure, while still reporting the same ,I,G, value.
Chunk Index and Chunk Type Index require information about the syntactic structure of sentences. In order to perform such analysis, the literature on Natural Language Processing (NLP) propose two approaches: full parsing and shallow parsing. The first one builds the full parse tree of a sentence (i.e. it works out the whole grammatical structure), while the second one identifies the constituents of a sentence (noun groups, verbs, verb groups, etc.), but does not specify their internal structure or their role in the main sentence. Shallow parsers divide sentences in a set of consecutive chunks; for example, starting from the sentence "The book is on the table", a shallow parser analyses it as [NP The book][VP is][PP on][NP the table] where NP is a Noun Phrase, VP is a Verb Phrase, and PP is a Prepositional Phrase.
The full parsing approach permits an in-dept analysis of the sentence, but is much more difficult to implement and much slower than shallow parsers, as they use complex techniques and huge language models. For these reasons, we based our approach on shallow parsing.
The Chunk Index and the Chunk Type Index take into account the syntactic structure of the sentences in terms of chunks. These indices are based on the analysis performed by the CHAOS (Basili et al. 1992) Italian language shallow parser (once again, the architecture of the tool makes it relatively easy to switch to another parser).
In particular, the Chunk Index IK relates the number of chunks in a text to its readability:
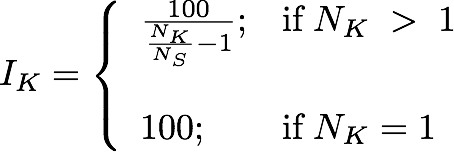
where NK is the number of chunks in the text; the higher is IK, the simpler is the text structure. The simplest text, composed of one sentence and two chunks, gets the maximum value: 100 (if the text is composed of one chunk, as in "Go", the index also gives value 100.) The intuitive idea is that if a text contains a few chunks per sentence, it should be more readable.
However, using the number of chunks does not consider the fact that different chunk types (NP, VP, etc.) could have different readability. Thus, we added the Chunk Type Index IT, which is based on the distribution of chunk types T in the text, and is calculated as:
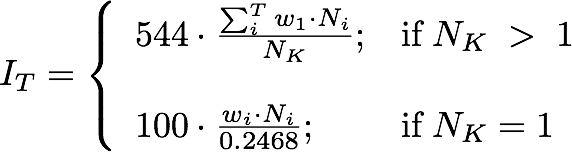
where N i is the number of chunks of type ;i; in the text, and wi is the weight assigned to chunks of type ;i; the higher is IT, the simpler is the phrase structure. The simplest text, composed of a Nominal Phrase and a Verbal Phrase, gets the maximum value: 100 (if the text is composed of one Nominal Phrase chunk, the index also gives value 100).
The weights wi have been calculated analysing the statistical distribution of the chunk types we found in a collection of highly accessible documents. We used the AltaFrequenza (AltaFrequenza 2012) on-line magazine, which publishes carefully written, simplified news; in Table 2 is depicted the distribution we found. The intuitive idea is that chunks with high frequencies inside the collection are more readable, and should be associated with a higher weight; thus, a high value of IT means that the text has a chunk type distribution similar to the one we found in the simplified texts.
|
Chunk Type |
Occurrences |
Frequency = Weight |
|
nominal |
910 |
0.2468 |
|
prepositional |
796 |
0.2159 |
|
finite verbal |
445 |
0.1207 |
|
coordinative |
430 |
0.1165 |
|
nominal verbal |
248 |
0.0672 |
|
subordinative |
158 |
0.0428 |
|
adjectival |
140 |
0.0379 |
|
infinite verbal |
136 |
0.0368 |
|
adverbial |
117 |
0.0317 |
|
predicative verbal |
117 |
0.0317 |
|
participial verbal |
89 |
0.0241 |
|
unknown |
67 |
0.0191 |
|
gerundive verbal |
21 |
0.0056 |
|
others |
12 |
0.0032 |
The final Readability Index IR is then given by the weighted mean:
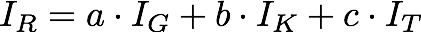
for our initial experimentation, the three weights a, b, and c have value 1/3.
The Understandability Index IU measures the complexity related to the lexicon. The index is based on the De Mauro (De Mauro 1996) basic Italian dictionary, which contains the 4700 more used lemmas of the Italian language. The vocabulary is divided into three sections: basic words, highly used words, and less used words.
The Understandability Index IU we propose is the weighted mean:
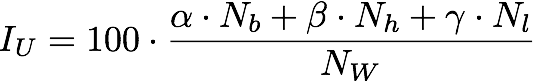
where Nb, Nh, and Nl counts, respectively, the number of words in the basic, highly-used, and less-used vocabularies. For our initial experimentation, we used the values alphaα=1, betaβ=0.75, and gammaγ=0.5. The higher is IU, the simpler is the lexicon used in the text.
Indices are useful to give a measure of the complexity of the text. Exploiting such indices, authors can be aware that the readability and understandability degrees of their texts do not meet a given threshold. Unfortunately, as the literature on readability formulas often points out (see, for example, (Shehadeh, et al. 1994)), indices say nothing about where precisely are the critic parts in the text, and how to fix them.
In our approach, we recognize that authors should be guided through the process of simplifying their texts. Thus, SPARTA2 is able to detect and report potential readability issues, analysing the structure and the lexicon of the sentences. This functionality fully exploits the chunk analysis performed by CHAOS: the result of the analysis is passed to a set of plug-ins, which can generate warnings to the user, suggesting also possible solutions.
For example, we wrote a simple plug-in that generates warnings whenever a sentence without explicit subject is found (the Italian language permits to write sentences with implicit subjects); this structure is quite common but, obviously, should be avoided in simplified texts. As an advice, the plug-in just suggests adding an explicit subject. Another plug-in we wrote searches for subordinate clauses, and advice to delete them if these are too long.
The architecture of SPARTA2 makes it easy to write new plug-ins, adding them to the collection. Thus, the tool can be easily tailored in order to detect the reading issues of specific target audiences.
The user interface of SPARTA2 is integrated into Word 2007 and a panel showing the indices is visible to the author at all time. SmatTags appear whenever a warning is reported to the user, and the related menus contain the solutions proposed by the plug-ins.
The main challenge to cope with is the selection of optimal values for the constants a, b, c, alphaα, betaβ, and gammaγ. For our initial experiments we used a naive approach, but a deep experimentation is needed in order to select values that are validated on the field.
A secondary challenge is understanding whether shallow parsing is informative enough - as we argue - or a full parsing is needed is order to capture the structural complexity of sentences.
The main outcome of this work is the development of a prototype, working inside Word 2007 (details can be found in (Sbattella et al. 2008)). Figure 1 depicts the SPARTA2 user interface. On the right, a panel shows the IR and IU indices (for convenience, the panel also shows the Gulpease index, since it is widely used as a standard readability measure). A check box permits to switch from the "auto" mode (where the indices are continually updated) to the "manual" mode (where indices are updated pressing a button). Another check box actives the highlighting of words not belonging to the De Mauro dictionary.
The sentence shows in Figure 1 is underlined with a dotted red line, and a small icon appears on the upper-left corner. This is the SmartTag triggered by a plug-in, which found a problem in the sentence.
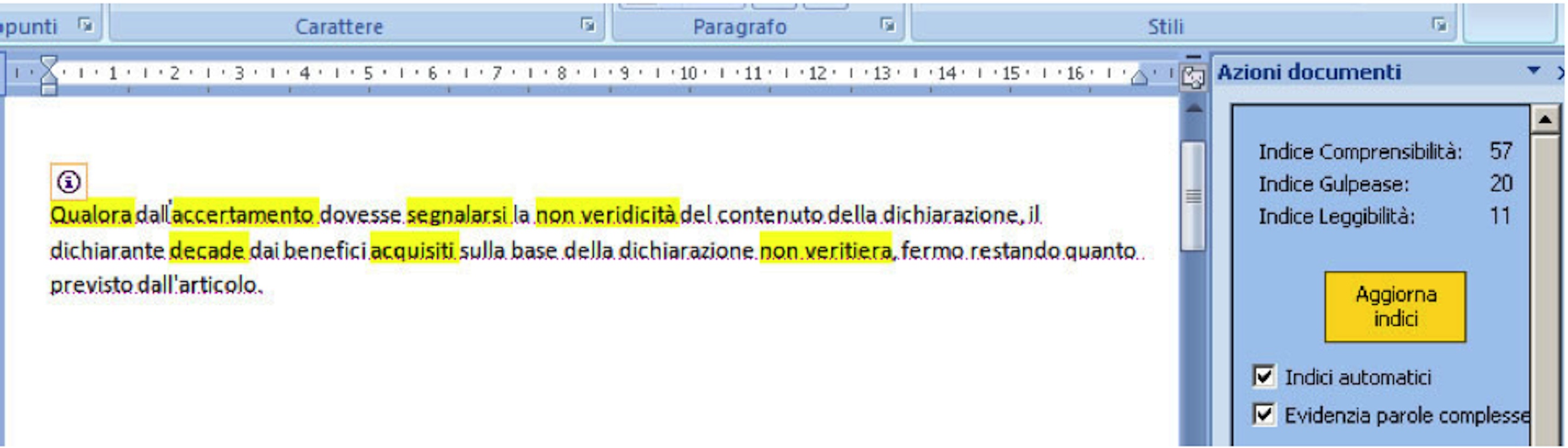
Figure 1 - SPARTA2 detects complex words and generates a SmartTag
Figure 2 shows the contextual menu that opens clicking on the SmartTag. Along with the standard items, the menu contains an item reading "La frase e’ strutturalmente complessa" [The sentence has a complex structure]. This is an example of warning plug-ins can generate. Clicking on the warning, a sub-menu opens showing the related advice "Eliminare una subordinata" [Delete a subordinate phrase].
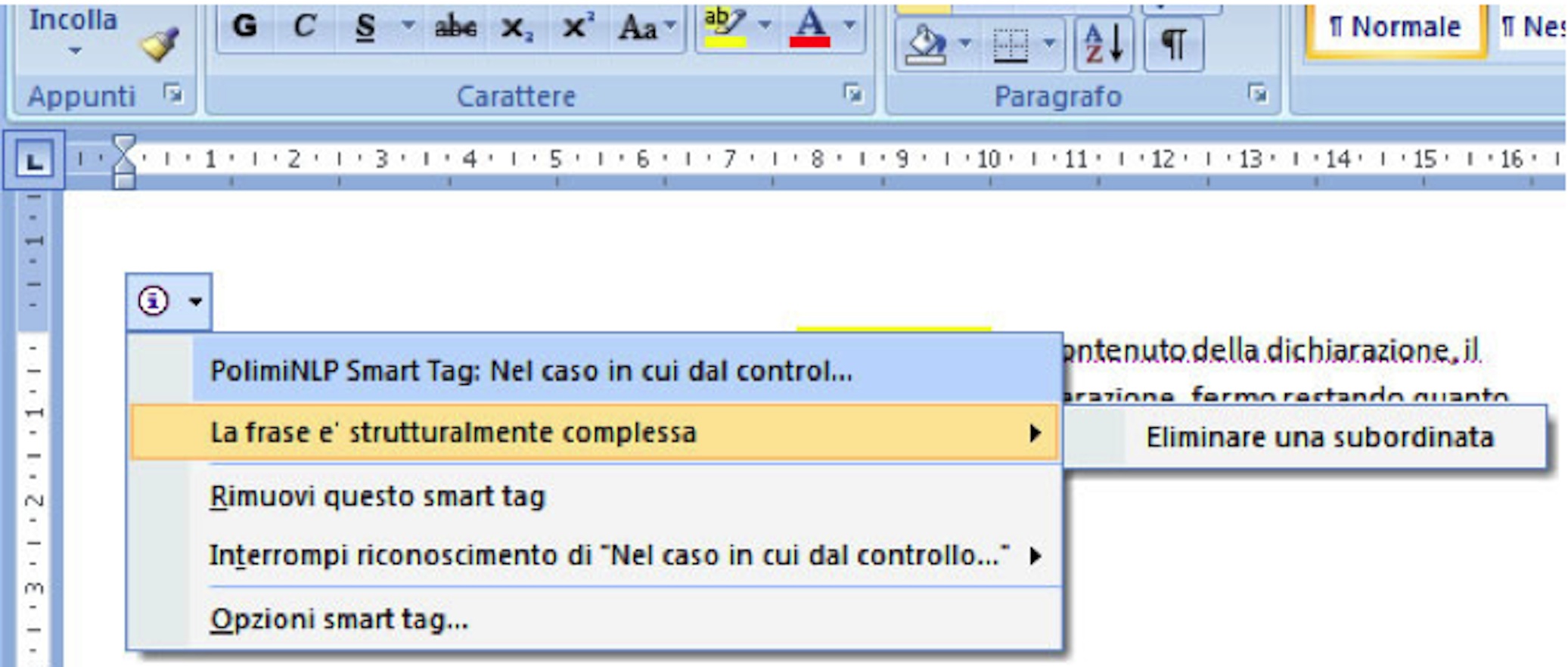
Figure 2 - The SmartTag contains a warning and an advice about the sentence
Finally, Figure 3 shows the same sentence, modified by the author, who removed all the complex words and simplified the structure of the sentence, following the advice given by the system. Now the values of the indices are much higher, meaning that the sentence is much more readable and understandable.
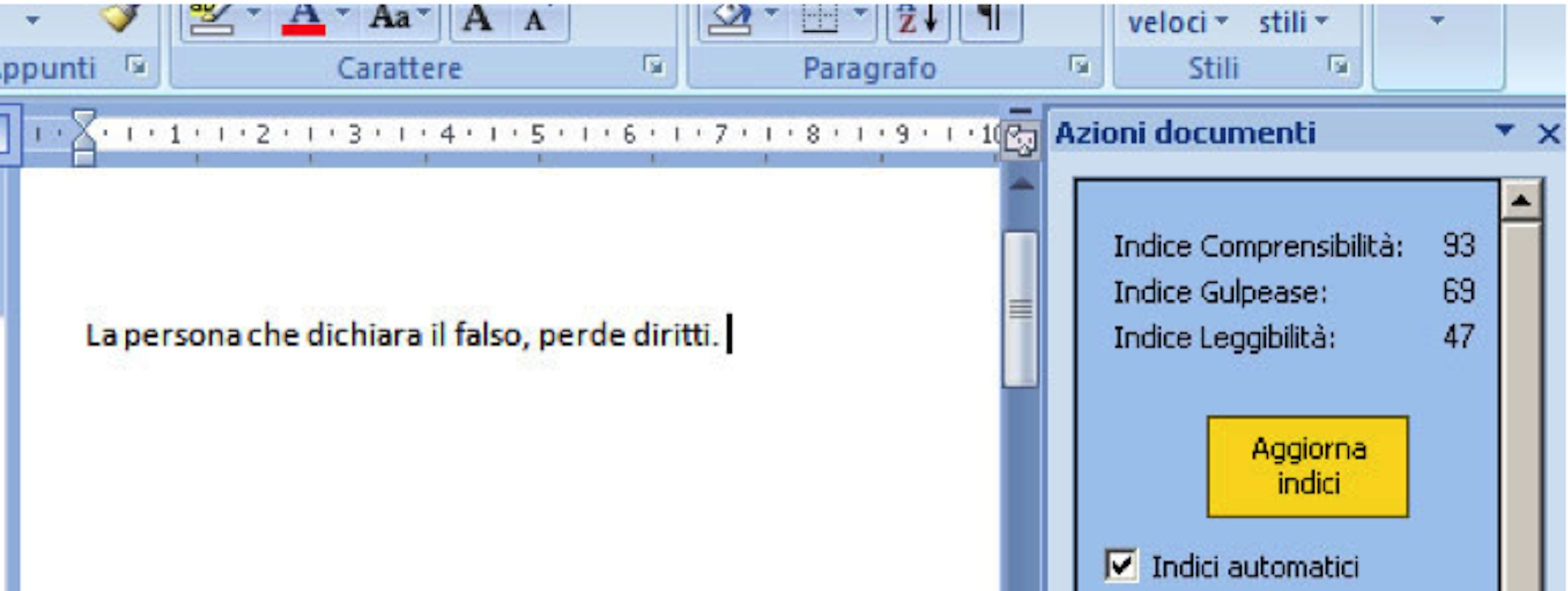
Figure 3 - The simplified sentence
We presented SPARTA2, a tool supporting the authoring of highly accessible texts. The tool computes indices about the complexity of Italian texts, exploiting the syntactic structure reported by a shallow parser. Moreover, the tool is able to detect the readability issues, providing warnings and advices. Thus, the tool not only calculates the current readability level of the text, but also actively supports authors suggesting where the critical parts are, and how to modify them.
We plan to release SPARTA2, under an open-source license (see the ARCSLab web site), as a Word plug-in. Porting the tool to other word processors should be a matter of integrating it inside the new environment. The tool could also be exploited in CMS editors, implementing a server-side service (containing index calculation) and a plug-in for integrating the results inside the editor interface. Finally, we plan to support other languages.
About the SPARTA2 "core", we plan to validate our indices, experimenting with the parameters a, b, c, alphaα, betaβ, and gammaγ? in order to find the optimal set of values. Moreover, we will experiment with new plug-ins able to detect and report more warnings and suggestions.
In our opinion, our complexity indices permit to measure the linguistic competences, from different points of view: lexical, syntactical, and structural. We conducted some experiments involving children (8 to 12 years old) and young persons (15 to 20 years old) with down syndrome, dyslexia, and sight problems. In such experiments we proposed tales and newspaper articles, evaluated using our indices, to the subjects. As a result, we obtained that users appreciated the possibility to know the readability of the text they were going to read, as that information permitted them to choose texts with the "preferred" complexity (we gathered such results by means of closed-ended and open-ended questionnaires); moreover, we measured improvements in reading speed and comprehension level (the latter was measured by means of questions on the contents of the texts).
As a final remark, developing this tool the lesson we learned is that, following the Universal Design principles, if authors prepare texts that are simple to read and understand, the result is not only more accessible to people with cognitive disabilities, but also more effective for all users. Thus, the general guideline we could assert is that: (1) texts of a web site should be pre-checked for readability and understandability, taking into account the expected audience; (2) a single version of the text should be simple enough to meet the requirements of all the expected audience (in other words, multiple versions of the same text, tailored to different parts of the audience, should be avoided unless it is absolutely necessary).
The authors wish to thank Alessandro Colombo, who wrote the code of SPARTA2.