WAI R&D Symposia » Metrics Home » Proceedings » This paper.
This paper is a contribution to the Website Accessibility Metrics Symposium. It was not developed by the W3C Web Accessibility Initiative (WAI) and does not necessarily represent the consensus view of W3C staff, participants, or members.
Towards a score function for WCAG 2.0 benchmarking
1. Problem Addressed: Web accessibility benchmarking with WCAG 2.0
Monitoring of web accessibility through regular benchmarks raises awareness and thus incites improvements of web sites. The eGovernment Monitoring (eGovMon) project [1] has collaborated with a group of Norwegian municipalities during more than two years, achieving encouraging results by a combination of evaluations and consultancy.
Initially, eGovMon used benchmarking tools based on the Unified Web Evaluation Methodology 1.2 (UWEM) [2], which describes conformance evaluations and large scale benchmarking for WCAG 1.0. However since WCAG 1.0 was superseded by WCAG 2.0, the eGovMon approach (including the implemented tests) had to be updated to accommodate the new guidelines.
This paper describes the requirements and challenges identified during the update of the metrics and reporting functions for WCAG 2.0 benchmarking. The core part of the reporting is the score function, which summarises the accessibility status of a web page or site into a single number.
First we look at the requirement perspective: What are the desirable properties of an accessibility score function? Then we take a WCAG 2.0 specific view with special consideration to the new properties of WCAG 2.0 (as compared to WCAG 1.0). Beyond that, the final section of the paper presents some ideas for developing a unified WCAG 2.0 score function, which would allow the comparison of WCAG 2.0 evaluations carried out by different tools.
Ideally not only results from different tools should be comparable; it is also desirable to obtain more insights in the comparability of expert evaluations and automated tests. However this topic is beyond the scope of this paper.
2. Background: Requirements for web accessibility indicators
During the work on UWEM 1.2 a process for indicator requirement analysis was established. First all potential properties were collected and grouped according to the parts of the evaluation process. There are requirements for crawling and sampling, requirements addressing mathematical and statistical properties of the score, and requirements that describe how the score reflects certain features of the web content. Afterwards, a theoretical analysis investigated the dependencies and selected a set of non-conflicting properties for the score function. Finally, several suggested score functions were compared with regard to how well they meet the properties and the best candidate function was chosen. This process and its outcomes are described in the UWEM Indicator Refinement Report [3]. Because of the good experience with this process, we applied it also to the case of WCAG 2.0. The structural differences between WCAG 1.0 and 2.0 make it necessary to revise some of the requirements. Section 3 looks into this aspect.
Vigo and Brajnik [4] analysed the desirable properties of web metrics for various application scenarios. They also present some quality attributes for benchmarking. The most relevant items for the score function are low sensitivity towards small changes in the web page and adequacy of scale and range of the score values.
3. Strategy: Definition of web page score
The score function should be tailored to the structure of the test set (in this case WCAG 2.0). Therefore we start out the design of the score function with an analysis of WCAG 2.0.
3.1 New aspects for the WCAG 2.0 score development
The WCAG 1.0 tests (as defined in UWEM 1.2) are independent: failure of a test also means failure of a WCAG 1.0 Checkpoint. The structure of WCAG 2.0 is different. The Techniques with their detailed test procedure provide a natural starting point for the implementation of an evaluation tool. But in the presentation of results the dependencies of the Techniques must be taken into account. On the one hand there are Common Failures which directly cause the web content to fail a Success Criterion (SC). On the other hand, conclusions from Sufficient Techniques can only be drawn if the logical combinations [5] are considered. We suggest the following approach to derive an implementation of tests for a Success Criterion:
- Applicability: Does the web page contain any HTML elements to which the SC is applicable? No: SC passes. Yes: continue.
- Does a Common Failure occur? Yes: SC fails. No: continue.
- Are the Sufficient Techniques successfully implemented for every element? Yes: SC passes or SC passes with warning (human input required). No: continue.
- Does the checker provide tests for all techniques related to the SC? Yes: SC fails with warning (no sufficient technique used). No: warning (not checked).
Moreover, some Techniques are used by several Success Criteria. For these reasons an interpretation of the results below the level of Success Criteria is not meaningful. Success Criteria are selected as the first level of aggregation.
This is a major difference from UWEM 1.2, which has an erratic number of tests per WCAG 1.0 Checkpoint. Each test contributes equally to the score result causing Checkpoints with many tests to be over-represented in the result. Using Success Criteria as intermediary aggregation level has several further advantages. The priority Level of the Success Criterion can be included in the score. The influence of Success Criteria with many Techniques is balanced. In an automated tool it becomes easy to highlight which Success Criteria need human judgement or were not tested.
Disadvantages of the approach are that the number of instances of a specific feature (such as form control) does not influence the score. If a tool does not implement all Techniques related to a SC, no conclusion can be drawn.
3.2 WCAG 2.0 web page score
We suggest the following score function, which takes into account the above considerations: The SC-level result for page p is defined as one minus the ratio of instances where tests for Success Criterion c failed on page p. (In the formula f_c(p) denotes the number of instances where tests for c failed and n_c(p) denotes number of all instances where tests for c were applied.)
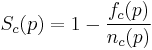
The tests are designed in such a way that each test results in either pass or fail. In some cases an additional warning message is returned to provide further information for the detailed accessibility report.
The page score S is calculated as the average of the SC-level page-results.
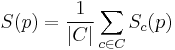
The page score can be refined by replacing the simple average with a weighted average which includes parameters to capture the priority of the Success Criteria.
4. Outcome and conclusions
The eGovMon project is developing an online checker for WCAG 2.0 that uses the new page score function. Initial experiments show that the results of the function meet the requirements and are understandable for the potential users of the checker. We have also started the work on a web site score function. This involves addressing the following open questions:
- How can the score calculation accommodate results of tests that are applied on site level?
- How to distinguish Success Criteria that are not applicable from those for which no tests are available ("undocumented Techniques")?
- How does the score function deal with conforming alternate versions?
Finally, further testing of the checker tool is planned to ensure that the score function meets the main "soft requirement": the score value must make sense when presented to the users.
5.Open Research Avenues: A unified WCAG 2.0 score
Large scale benchmarking of web accessibility often relies on tools due to resource limitations. Although there exist a number of tools which claim to check according to WCAG 2.0, their result are still not comparable.
This problem is mainly caused by the varying granularity of tests (Some tools implement several tests per Success Criterion while others only have one test.) and the differences in counting the instances (Some tools count every checked HTML element while others only count each instance once.). The tools also differ in how outcomes are grouped into categories like "error", "potential error", "warning". Some tools only report the absolute numbers for each outcome category, while some tools use some kind of score function. Presently, a generally accepted practice for reporting WCAG 2.0 evaluation results does not exist.
Another reason lies in the WCAG 2.0 documents themselves. Sometimes the aggregation of results from the Techniques is not documented well. Alonso et al. [6] describe the consequences of this challenge:
"This could lead to a situation where different evaluators use different aggregation strategies and thus produce different evaluation results."
A first simple step to increase the comparability of the results from different tools would be the introduction of aggregation on the level of Success Criteria, as suggested in this paper.
To define a truly unified WCAG 2.0 score and thus achieve actual inter-tool reliability—as demanded by Vigo and Brajnik [4]—a dedicated collaboration between tool developers and researches would be necessary to address the following tasks:
- Define comparable tests on atomic level.
- Follow the logical combinations defined in "How to meet WCAG 2.0" (and clarify any ambiguities).
- Agree on indicator requirements.
- Define score function.
For a start the validity of such an approach is ensured by the strong link with WCAG 2.0. Additional proof of the validity of automated testing could be established in an experiment similar to the one described by Casado Martínez et al. [7].
Acknowledgements
The eGovMon project is co-funded by the Research Council of Norway under the VERDIKT program. Project no.: VERDIKT 183392/S10.
References
- URL: eGovMon web page checker http://accessibility.egovmon.no/en/pagecheck/ (retrieved 2011-10-21)
- Report: Web Accessibility Benchmarking Cluster (2007) Unified Web Evaluation Methodology, UWEM 1.2 http://www.wabcluster.org/uwem1_2/ (retrieved 2011-10-24)
- Report: Nietzio, A., Ulltveit-Moe, N., Gjøsæter, T., Olsen, M. G., & Snaprud, M. (2007) Unified Web evaluation methodology indicator refinement.
- Journal: Vigo, M., & Brajnik G. (2011) Automatic web accessibility metrics: where we are and where we can go. Interacting with Computers 23(2), 137-155. DOI: 10.1016/j.intcom.2011.01.001
- URL: How to meet WCAG 2.0. http://www.w3.org/WAI/WCAG20/quickref/20101014/ (retrieved 2011-10-24)
- Book Chapter: Alonso, F., Fuertes, J., González, Á., & Martínez, L. (2010) Evaluating Conformance to WCAG 2.0: Open Challenges. In: Computers Helping People with Special Needs (ICCHP) DOI: 10.1007/978-3-642-14097-6_67
- Book Chapter: Casado Martínez, C., Martínez-Normand, L., & Olsen, M. G. (2009) Is it possible to predict manual web accessibility results using automatic results? In: Universal Access in Human-Computer Interaction. Applications and Services (HCII) DOI: 10.1007/978-3-642-02713-0_68