Figure 1: Database scheme for the book example above
|
Giansalvatore Mecca
(1)
mecca@dia.uniroma3.it |
Paolo Merialdo
(1,2)
merialdo@dia.uniroma3.it |
Paolo Atzeni
(2)
atzeni@dia.uniroma3.it |
|||
| (1) Università della Basilicata | (2) Università di Roma Tre | ||||
XML [XML98] has been proposed as a successor of HTML conceived to ease the task of exchanging, manipulating and reusing data on the Internet (and in other frameworks). The main advantage of XML with respect to its predecessor is a clear separation between the ways in which data, structure (DTD) and layout (stylesheet) are encoded. At the same time, XML preserves and enhances the hypertextual linking mechanism [XLink98, XPointer98] that has been so successful for HTML. It is therefore presumable that we will very soon witness the emergence of XML repositories on the Web, i.e., large collections of Internet-available linked XML documents.
The announced availability of these large repositories imposes to develop suitable techniques for querying and transforming XML data. Recent proposals of query languages for XML -- such as, for example, XML-QL [Deu+98] and XQL [ScLR98] -- concentrate on a single XML document at a time and are based on a ''semistructured'' approach [Abi+97a], in the sense that documents are seen as essentially unstructured graphs, and the query process does not rely on a notion of scheme.
On the contrary, we believe that query support for XML should allow to manage complex collections of linked documents, which we have called XML repositories. Also, although techniques developed for querying semistructured data are definitely relevant here, since XML data do have an associated structure, the DTD, in our opinion the query process should exploit as much of this structure as it is possible. This position is based on the following observations:
|
XML Documents are Typed Objects:Every XML document comes with an associated type, i.e., its DTD. In fact, the DTD is explicitly mentioned in so called valid documents, and is used to validate the document itself. Other documents, called well-formed do not have an explicitly associated DTD. However, due to the special tagging format, a (minimal) DTD for which the document is valid can be derived by a simple syntactic check of the document. |
|
XML Repositories do have a Structure:Since we have a structure associated with each document, we can associate a structure (i.e., a scheme) with the whole repository; it is therefore reasonable to use this structure in the query process. |
In this respect, object-oriented (and object-relational) databases are natural candidates for representing and querying XML. More specifically, we consider the ODMG standard and its query language, OQL [Catt94] a nice basis to develop a flexible query paradigm for XML. We therefore believe that the main efforts towards a query technology for XML should not be in defining the syntax and semantics of a new query language, but rather to adopt the standard and consolidated platform represented by object-databases, and enrich it with new solutions, studied to face the challenges posed by XML. In fact, XML data introduce several peculiar features that depart from conventional databases; research and development should be devoted to extend the object-database platform with techniques for dealing with such features.
In the paper, we try to support these statements. We first discuss the issue of modeling XML repositories as object databases; then, we investigate the use of object query languages for querying and transforming XML sources, listing a number of issues for which current databases cannot be considered satisfactory, along with possible solutions that represent promising research directions.
This paper is inspired on experiments on XML data that we are carrying on in the framework of the Araneus Project [Araneus]. In the paper, we mostly make reference to XML data sources; however, we believe many ideas developed in the paper to be equally applicable to RDF. For a more complete technical treatment of the subject, we refer the readers to an extended version of this paper, to be soon available at http://www.dia.uniroma3.it/Araneus/articles.html.
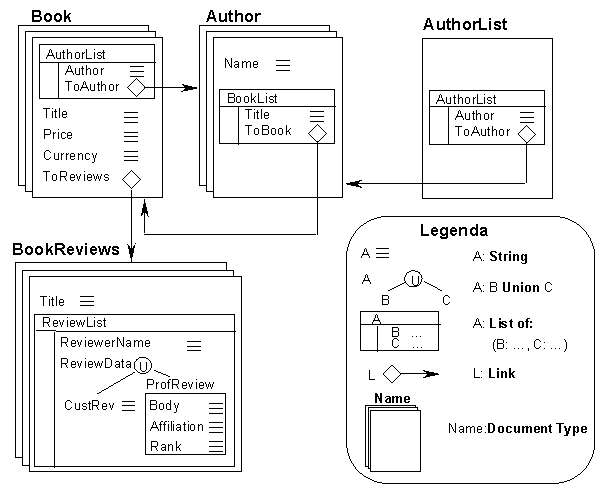
The DTD is a natural candidate to represent the type of a document. However, XML DTDs do mix together both a description of the logical features of the document, with rather ''physical'' ones (such as, for example, entities, which can be more appropriately considered as storage units or macros rather than structural components); in fact, XML is rather a format than a data model. If we abstract with respect to these physical aspects and concentrate on the logical structure, we can see that a DTD is essentially a database type, and an XML document can be seen as a complex database object. Consider for example a hypothetical XML repository about authors, books, and books reviews, organized according to the following DTDs. We have a document containing a list of authors (an entry point), pointing to one document for each author, with links to all of his books; for each book, we have authors, title, price plus a link to a list of reviews; each review may be either from a customer or from a professional; in the latter case, a rank is provided, as follows (links have been specified following the XLink [XLink98] syntax):
<!DOCTYPE AuthorList [
<!ELEMENT AuthorList (Author+)>
<!ELEMENT Author (#PCDATA)>
<!ATTLIST Author xml:link CDATA #FIXED "simple"
href CDATA #REQUIRED>
]> |
<!DOCTYPE Author [
<!ELEMENT Author (Name, BookList)>
<!ELEMENT Name (#PCDATA)>
<!ELEMENT BookList (Title+)>
<!ELEMENT Title (#PCDATA)>
<!ATTLIST Title xml:link CDATA #FIXED "simple"
href CDATA #REQUIRED>
]> |
<!DOCTYPE Book [
<!ELEMENT Book (Author+, Title, Price, ToReviews?)>
<!ELEMENT Author (#PCDATA)>
<!ATTLIST Author xml:link CDATA #FIXED "simple"
href CDATA #REQUIRED>
<!ELEMENT Title (#PCDATA)>
<!ELEMENT Price (#PCDATA)>
<!ATTLIST Price currency (US$|CND$|AU$|UK£))>
<!ELEMENT ToReviews EMPTY>
<!ATTLIST ToReviews xml:link CDATA #FIXED "simple"
href CDATA #REQUIRED>
]> |
<!DOCTYPE BookReviews [
<!ELEMENT BookReviews (Title, Review+)>
<!ELEMENT Title (#PCDATA)>
<!ELEMENT Review (ReviewerName, CustomerReview|ProfReview)>
<!ELEMENT ReviewerName (#PCDATA)>
<!ELEMENT CustomerReview (#PCDATA)>
<!ELEMENT ProfReview (Affiliation, Body, Rank)
<!ELEMENT Affiliation (#PCDATA)>
<!ELEMENT Body (#PCDATA)>
<!ELEMENT Rank (#PCDATA)>
]> |
To abstract the logical features of these DTDs, note that they essentially specify the document structure in terms of a number of ELEMENTS, i.e., attributes for the associated documents; attributes may be optional, and have a type; this can be either simple, like for strings (#PCDATA) or blobs (ANY) or complex; complex attributes are based on a limited number of primitives, that have a natural counterpart in object data models, as follows:
structures, i.e., typed tuples of elements, like in <!ELEMENT Book (Author+, Title, Price, ToReviews?)>;
union types, i.e., disjunctions of elements, like in <!ELEMENT Review (ReviewerName, CustomerReview|ProfReview)> ;
links, i.e., references to other documents or portions of documents, like in <!ATTLIST Title xml:link CDATA ...;
lists, i.e., ordered collections of elements (possibly nested) like in <!ELEMENT BookList (Title+)>;
These fundamental primitives correspond to the ones that are typically offered by object-database systems, the main differences being the absence of hierarchies and inheritance, and the presence of union types. We can therefore consider XML modeling primitives as a subset of ODMG (including simple types, structures, links and nested lists) enriched with union types. Such a model coincides with a data model recently adopted in the framework of the Araneus Project for the description of Web data sources, called ADM (the Araneus Data Model) [AtMM97,MeMM98]. In this respect, each DTD can be seen as a type declaration for a class of documents, and a collection of DTDs describing linked documents like the ones above can be considered a database scheme. Figure 1 below shows a graphical representation of an ADM scheme corresponding to example above. In the scheme, ``stacks'' are used to represent classes of documents; edges denote links. Figure 1 also contains an explanation of the other graphical primitives.
In this perspective, an XML document conforming to a given DTD can be naturally seen as an object (i.e., an instance) of the corresponding class, having the URI as an identifier. Also, the document can be easily loaded into the database: in fact, the DTD is also a grammar specifying how data are organized in the document; this can be used by a parser to "wrap" the document, that is, to extract attribute values from the document and store them into a database object of the given type [Abi+97b].
We would like to emphasize the fact that the data model we have identified do correspond to the core modeling primitives that can be abstracted from XML structures; the model therefore gives a ''faithful'' description of the repository structure. The availability of such a description is important in several respects (for example for optimization purposes, since it reflects the granularity and structure of the actual documents downloaded from the network). However, once this first description is available, the DBMS can be used to build arbitrary views over the data, possibly restructuring them. In this view definition process, the full power of ODMG (including hierarchies, unordered collections etc., that are not in the core model since cannot be considered as base modeling primitives in XML) can be used.
A clear advantage of this abstraction process is that the user can see the XML repository as a full-fledged database, without being concerned with the physical organization of data. To give an example, consider the XML attribute currency of element price in DTD Book; although in the DTD it was considered rather as a metadata, and therefore stored in a slightly different way with respect to elements (such as the title, for example), in the database abstraction of the DTD we may decide to ignore this difference, and model it as a conventional class attribute; the same happens in our example for links; in this way, the system provides a uniform view and query mechanism for data and metadata.
The scheme gives a compact representation of the repository content and of its semantics, supporting users in the formulation of the query; in fact, as standard in databases, query formulation based on a scheme is simpler and more accurate than working without one or with a loose one; also, the system can use the knowledge about the scheme for optimization purposes; efficiency in querying large Internet-available data sources is in fact a critical issue.
In the hypothesis of having documents loaded into the database, we can naturally use (extensions of) OQL to query the data. It is worth noting that querying a single document can be considered as a special case of the more general task of querying a collection of linked documents (we consider the URI of a document as a visible identifier of the corresponding database object; this can be used in the where clause to query a single document). Since object-oriented and object-relational databases are well-established technologies, we inherit a number of consolidated solutions for querying data (extensible type system, aggregation functions, ordered and unordered collections, views and restructuring, embedded queries). We can also make reference to known extensions, that seem particularly appropriate to this framework (generalized path expressions [CACS94,ChCM96], data integration techniques [Ullm97], etc.).
Object-database systems represent a natural platform for the manipulation of XML repositories, and in fact database vendors are rapidly moving towards supporting XML in their products (see, for example, [Oracle98]). However, there are peculiarities of XML data that depart from the traditional database framework, and therefore impose to re-consider some aspects of the query process. In our perspective, there are two main such aspects, as follows:
XML repositories are remote and autonomous data sources: unlike conventional databases, XML repositories will usually be collections of documents available on the Web, rather than be stored in a local storage; the main consequence of this is that these repositories will most probably be autonomous, i.e., beyond the control of the query system; hence, it is not possible to influence the organization of documents in the repository; also, the repository manager can insert, delete and modify documents, or even DTDs, without notifying remote users of the updates.
XLinks are untyped: XLink, the proposed standard for linking in XML documents, does not allow the use of typed links; although it is somehow probable that the final XLink standard will include typed links (the latter are indeed present in HyTime [HyTime], the standard upon which XLink is based), still it will be possible to use untyped links in DTDs.
Both these features have a strong impact on several aspects of the query evaluation process, that we briefly discuss in the following.
Schema Derivation: The query process suggested above relies on the derivation of a database abstraction, i.e., a scheme, over the original XML repository. If we do not have any a priori knowledge about the data, this scheme must be built using some a posteriori analysis. Assuming that all URIs are known to the system, or can be reached starting from some entry-point, this can be done by running a robot on the repository once, analyzing the DTDS and deriving the schema from them. In our book example, the system might start from the entry point, the list of authors, (AuthorList), access all documents about authors, inspect their DTDs, then access all documents about books etc. until all documents in the repository have been inspected. The schema is built by composing types corresponding to DTDs encountered during the navigation. If well-formed documents, for which the DTD is not explicitly mentioned, are encountered, a minimal DTD is derived; the system can then check if this minimal DTD is subsumed by some other known DTD in the repository. A possible approach to this problem is developed in [GrMe99] with respect to a more general framework.
It is worth noting that, depending on the degree of regularity present in the repository, the final schema may in some cases be very small and compact, or rather large. The former case, that we have assumed in our example, is the one in which relatively few DTDs describe the entire document collection. If, however, in our example two (or more) different DTDs are used for books, the system would model them separately and introduce union types for links. As an extreme, in some cases the number of different types may be in the order of the number of documents. We consider this case as rather unlikely (if documents are generated by some automatic procedure) but still possible. In this latter case, language extensions such as the ones developed for semistructured data can be profitably exploited.
Dealing with Updates in the Data: After a scheme has been derived, in order to answer queries there are two possible alternatives: (i) the system may populate classes by loading objects into the database; in essence, this corresponds to materializing a copy of the original data into the local database; (ii) or it may leave documents at their original position, and download only the ones needed to answer the query at query-execution time.
The first ''warehousing'' approach has several advantages, for example in terms of performance, because documents are downloaded off-line, and queries can be executed and optimized locally by the query engine. However, it does not guarantee that query answers are up-to-date. Also, the database needs to be periodically maintained in order to reflect changes at the repository; since, as discussed above, the XML repository is usually to be considered as a completely autonomous data source, we cannot assume that changes in the data are notified to the query system. Therefore, maintaining the database requires in principle to download the whole repository, which in some cases may have unacceptable costs.
The second, ''virtual'' approach, always guarantees that query answers are consistent with the last repository state. On the other side, query costs increase due to the need to download documents across the network. Also, traditional query optimizers are of little help; in fact, query optimization for object databases strongly relies on the availability of suitable access structures (like indices or class extents). One might think of extending such techniques to speed up the evaluation of queries by, for example, storing URIs in some local data structures, and then using them in query evaluation. However, this solution is in general unfeasible because, after the data structures have been constructed, they have to be maintained; since the system is not notified of updates at the original source, maintaining these structures may have a cost comparable to the cost of computing the query itself.
There is therefore a strong need for new query optimization and incremental view maintenance techniques for XML repositories. Similar issues have been recently studied in the framework of queries over Web sites in [MeMM98,MeMM98TR]; many ideas developed in these works also apply to the XML case.
Dealing with Updates in the Schema: Changes in the structure of the repository are equally important. In principle, if changes in the documents, i.e., additions, deletions or updates, impose to maintain the database extent, changes in the repository structure may require to change the database schema. Consider for example links in the book repository above from authors to their books. Suppose the repository has first been examined and the scheme in Figure 1 has been derived; then, at some point, a user adds to the book repository a new book document, organized according to a slightly different DTD, say StrangeBook (this may be possible due to the absence of typed links). The addition of this new DTD, that is, of a new type, changes the scheme, since link ToBook in class Author is now to be modeled as a link to a type which is the union of Book and StrangeBook.
The query language should know the change in the schema before attempting to evaluate queries on the new data. One possible solution is to force the system to validate the schema before executing a query; this, however, may in some cases be unacceptably slow. Since we don't want to give up the benefits of having a scheme for the data, we need to design suitable mechanisms to deal with schema inconsistencies at query execution time. In our opinion, a promising approach consists in introducing exception handling and schema evolution mechanisms in the query language, in order to deal with unexpected changes in the schema, along the lines of [BKKK87, ABDS94]. In this respect, new types are essentially considered as exceptions, to be handled either explicitly, by running some user-specified piece of code, or implicitly, trying to find a correspondence between the expected and the actual type. These ideas will be developed in a forthcoming paper.
References