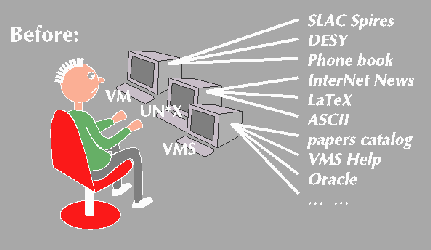
The W3 principle of universal readership is that once information is available, it should be accessible from any type of computer, in any country, and an (authorized) person should only have to use one simple program to access it. This is now the case.In practice the web hangs on a number of essential concepts. Though not the most important, the most famous if that of hypertext.

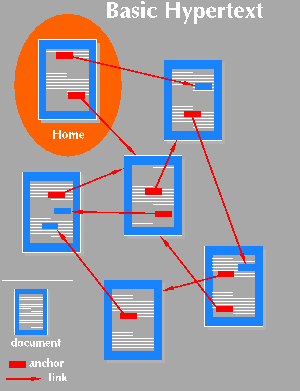
W3 uses hypertext as the method of presentation, although as we shall see, this does not necessarily require that authors write hypertext. In W3, links can lead from all or part of a document to all or part of another document. Documents need not be text: they can be graphics, movies and sound, so the term "hypermedia", meaning "multimedia hypertext" applied equally well to W3.
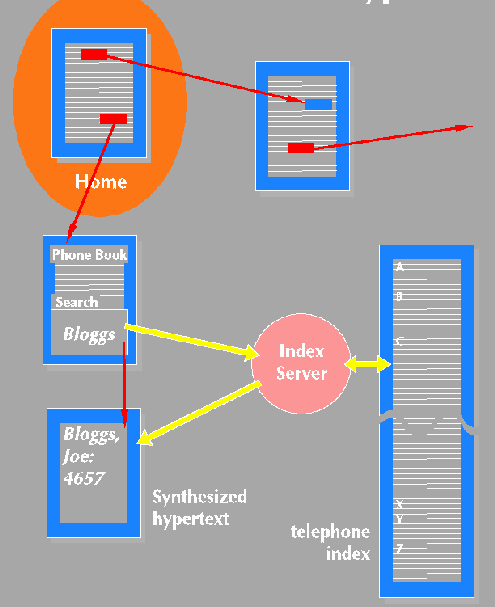
Whilst hypertext is a powerful tool for finding information, it cannot cope with large amorphous masses of data. For these cases, computer-generated indexes allow the user to pick out interesting items from textual input. There are therefore two operations a reader can use: the hypertext jump and the text search. Indexes appear within the web just like other documents, but a search panel (or FIND command) accompanies them which allows the input of text. Behind each index is some search engine: many different search engines with different capabilities exist on different servers. However, they are all used in exactly the same simple way: you type in some text, and you get back a hypertext answer which points you to things which were found by the search.
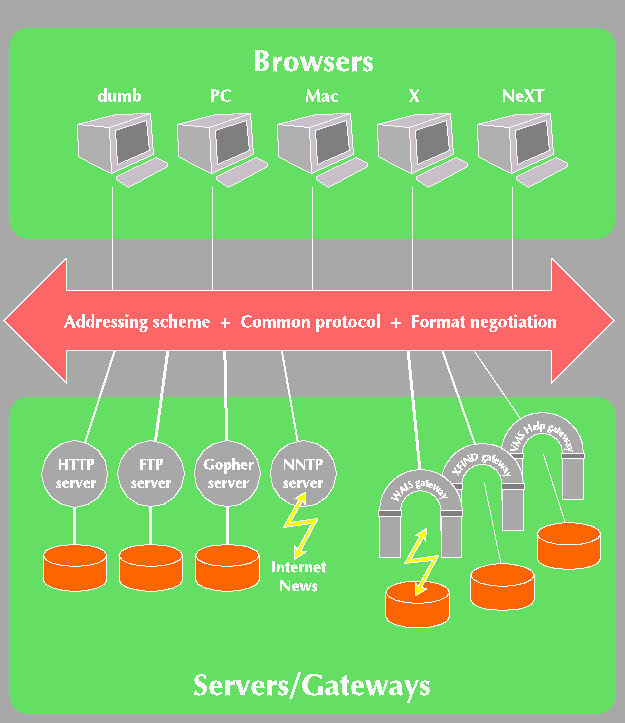
To allow the web to scale, it was designed without any centralized facility. Anyone can publish information, and anyone (authorized) can read it. There is no central control. To publish data you run a server, and to read data you run a client. All the clients and all the servers are connected to each other by the Internet. The W3 protocols and other standard protocols allow all clients to communicate with all servers.
A feature of HTTP is that the client sends a list of the representations it understands along with its request, and the server can then ensure that it replies in a suitable way. We needed this feature to cope with the existing mass of graphics formats for example (GIF, TIFF, JPEG to name but a few). If we cannot cope with the existing formats, how can we hope to evolve to take advantage of all the exciting new formats yet to be invented? Format negotiation allows the web to distances itself from the technical and political battles of the data formats.
A spin-off of this involves high-level formats for specific data. In certain fields, special data formats have been designed for handling for example DNA codes, the spectra of stars, classical Greek, or the design of bridges. Those working in the field have software allowing them not only to view this data, but to manipulate it, analyse it, and modify it. When the server and the client both understand such a high-level format, then they can take advantage of it, and the data is transferred in that way. At the same time, other people (for example high school students) without the special software can still view the data, if the server can convert it into an inferior but still useful form. We keep the W3 goal of "universal readership" without compromising total functionality at the high level.
Part of the W3 seminar . On to W3 protocols.
Tim BL