
VoiceXML and the Web
Dave Raggett, W3C Fellow (Canon)
W3C Activity Lead for Voice Browsers
and Multimodal interaction
http://www.w3.org/Voice/
An Introduction to the
Voice Browser Activity
- Enabling voice access to suitably designed Web applications
- Builds upon well established Web technology
- Made possible by advances in speaker independent speech
recognition and speech synthesis
- Accessible from over a billion telephones
- Biggest take up is for Call Centers
- Despite current economic setbacks, speech technology and voice
applications remain boyant:
"a recent study by the Radicati Group estimates that
the total market value for Voice Enabled Services will reach $202
million by year end 2002, and grow to over $659 million by
2006"
Voice Browsers
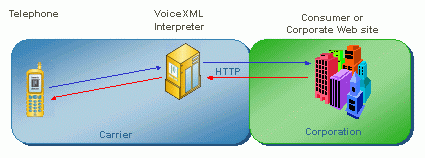
- User dials Voice Browser, e.g. +1 800 555
8355
- Browser downloads markup from Web server
- VoiceXML markup directs browser to:
- Prompt user using recorded or synthetic speech
- Interpret user's spoken response using speech grammar
- Determine what to do next
- VoiceXML provides a form filling metaphor
W3C Speech Interface Framework
- VoiceXML — markup for voice dialogs
- Candidate Recommendation - 28 Jan 2003
- SRGS — markup for speech grammars
- Candidate Recommendation — 26 June 2002
- SSML — markup for speech synthesis
- Candidate Recommendation expected 2nd quarter 2003
- Semantic Interpretation — extracting recognition results
(in an ECMAScript variable or as XML)
- Latest Working Draft — 1 April 2003
- CCXML — markup for call control
- Latest Working Draft — 11 October 2002
Call Control eXtensible Markup Language (CCXML)
- Designed as an adjunct language to provide telephony call
control support for VoiceXML or other dialog systems
- CCXML adds support for:
- Multi-party conferencing
- Sophisticated multiple-call handling and control, including the
ability to place outgoing calls
- Handling for richer and more asynchronous events
- Ability to receive events and messages from external
computational entities. Interacting with an outside call queue, or
placing calls on behalf of a document server
CCXML Features
CCXML defines an event driven state machine which can:
- Accept or reject an incoming phone call
- Make an outbound call
- Terminate a phone connection
- Create and destroy multi-party audio conferences
- Redirect an incoming call to a new end-point
- Connect and disconnect two audio sources
- Start and stop a dialog (VoiceXML)
CCXML - markup sample
<?xml version="1.0" encoding="UTF-8"?>
<ccxml version="1.0">
<var name="in_callid" expr="'''"/>
<var name="currentstate" expr="'initial'"/>
<eventhandler statevariable="currentstate">
<transition state="'initial'"
event="connection.CONNECTION_ALERTING" name="evt">
<assign name="currentstate" expr="'alerting'"/>
<assign name="in_callid" expr="evt.callid"/>
<accept callid="in_callid"/>
</transition>
<transition state="'alerting'"
event="connection.CONNECTION_CONNECTED" name="evt">
<assign name="currentstate" expr="'fetching'"/>
<fetch next="'http://acme.com/conference.asp'" namelist="in_callid"/>
</transition>
<transition state="'fetching'" event="fetch.done" name="evt">
<goto fetchid="evt.fetchid"/>
</transition>
</eventhandler>
</ccxml>
Related work
- ECMA standard Computer Supported Telecommications Applications
(CSTA)
- SALT Forum: SALT Call control object
- SALT provides speech tags for use with markup languages like
HTML and scripting languages like ECMAScript
- Call Processing Language (CPL) is an XML based language for
user scripting of incoming VoIP calls
Speech Synthesis (SSML)
- Markup language for prompting users via a combination of
prerecorded speech, synthetic speech and music
- You can select voice characteristics (name, gender and age) and
the speed, volume, pitch, and emphasis
- Provision for overriding the synthesis engine's default
pronunciation
- Used within VoiceXML 2.0
- Expect to advance SSML to W3C Candidate Recommendation status
during Summer 2003
- Matching Speech Synthesis style sheet module for CSS3
- Replaces aural cascading style sheets in CSS2
- Developed as collaboration between VBWG and CSS WG
SSML markup sample
<?xml version="1.0" encoding="ISO-8859-1"?>
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/10/synthesis
http://www.w3.org/TR/speech-synthesis/synthesis.xsd"
xml:lang="en-US">
<voice gender="female">
Any female voice here.
<voice age="6">
A female child voice here.
<paragraph xml:lang="ja">
<!-- A female child voice in Japanese. -->
</paragraph>
</voice>
</voice>
</speak>
Speech Recognition Grammar (SRGS)
- Context free grammar for expressing user's response
- Expressed in XML as a grammar over words/characters
- Used to guide speech recognition
- Recognizer maps words into an internal phonetic
representation
- Used in statistical recognition process (Hidden Markov
Models)
- May return an N-best list of results
- Also used as a basis for extracting information from spoken
utterances (see next slide)
- Alternative augmented BNF syntax (little used)
- Includes support for touch tone (DTMF) input
- Expect to advance SRGS to W3C Proposed Recommendation status in
Summer 2003
SRGS markup sample
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE grammar PUBLIC "-//W3C//DTD GRAMMAR 1.0//EN"
"http://www.w3.org/TR/speech-grammar/grammar.dtd">
<!-- the default grammar language is US English -->
<grammar xmlns="http://www.w3.org/2001/06/grammar"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/06/grammar
http://www.w3.org/TR/speech-grammar/grammar.xsd"
xml:lang="en-US" version="1.0">
<!--
single language attachment to tokens
"yes" inherits US English language
"oui" is Canadian French language
-->
<rule id="yes">
<one-of>
<item>yes</item>
<item xml:lang="fr-CA">oui</item>
</one-of>
</rule>
<!-- Single language attachment to an expansion -->
<rule id="people1">
<one-of xml:lang="fr-CA">
<item>Michel Tremblay</item>
<item>André Roy</item>
</one-of>
</rule>
<!--
Handling language-specific pronunciations of the same word
A capable speech recognizer will listen for Mexican Spanish
and US English pronunciations.
-->
<rule id="people2">
<one-of>
<item xml:lang="en-US">Jose</item>
<item xml:lang="es-MX">Jose</item>
</one-of>
</rule>
<!-- Multi-lingual input is possible -->
<rule id="request" scope="public">
<example> may I speak with André Roy </example>
<example> may I speak with Jose </example>
may I speak with
<one-of>
<item> <ruleref uri="#people1"/> </item>
<item> <ruleref uri="#people2"/> </item>
</one-of>
</rule>
</grammar>
Semantic Interpretation
- Annotations for speech grammars
- Written in a subset of ECMAScript
- Used to extract results from speech recognition
- Result is either a ECMAScript variable or XML (EMMA)
- EMMA is being developed in the W3C Multimodal Interaction
working group
- Example:
- User says "I want to fly to Chicago"
- Application sees:
<destination>Chicago</destination>
- Implementation adds further information about recognition
confidence, timestamps and alternative interpretations
- Expect to publish Last Call working draft in Summer 2003
VoiceXML 2.0
- VoiceXML is a dialog markup language aimed at telephony
applications
- synthesized speech, digitized audio, recognition of spoken and
DTMF key input, recording of spoken input, telephony, and simple
mixed initiative conversations
- Builds upon other W3C Speech Interface Framework
specifications
- Menus and Links — support for navigation commands like
"main menu", "help", "appointments", "sport", "news"
- Form filling support
- Leading user through sequence of form fields
- Form level grammars for utterances that fill out multiple
fields
- Tapered prompts — giving progressively stronger guidance
when user is having difficulties
- Adapting to user's level of experience (novice vs power
user)
- Uses ECMAScript for storing data and conditional behavior
- Sessions that persist over a number of VoiceXML pages
VoiceXML markup sample
<?xml version="1.0" encoding="ISO-8859-1"?>
<vxml version="2.0" lang="en">
<form>
<field name="city">
<prompt>Where do you want to travel to?</prompt>
<option>Edinburgh</option>
<option>New York</option>
<option>London</option>
<option>Paris</option>
<option>Stockholm</option>
</field>
<field name="travellers" type="number">
<prompt>How many are travelling to <value expr="city"/>?</prompt>
</field>
<block>
<submit next="http://localhost/handler" namelist="city travellers"/>
</block>
</form>
</vxml>
Some possible applications
with thanks to Jim Larson
- Be notified of interesting events — stock movements,
availability of special offers, flight delays, ...
- Conference with colleagues — meet at a specific Web site,
with ability to whisper private messages
- Find me — application uses information about the
whereabouts of the called person to handle the call
- Find the whereabouts of a friend — based upon cellular
network's knowledge of the location your friend's cellphone
- Instant voice messaging. "Notify me when John Smith calls into
his voicemail." Or "Voicemail from John Smith. He's checking his
messages right now, would you like me to connect you?"
- Voice control your home appliances — when returning from
a vacation phone home to switch the heating on in advance
Patents
- Voice Browser activity is chartered to produce specifications
that can be implemented without the need to pay royalty fees
- Current Patent Pratice Note — a Patent Advisory Group
(PAG) must be launched upon:
- Incomplete patent disclosures by working group members
currently in good standing
- Disclosure of essential claims for patents that are not
available on royalty free (RF) terms
- Several such patents were disclosed and as a result a PAG was
launched
- Unless resolved, this would prevent affected Voice Browser
specifications from advancing to Proposed Recommendation
status
- The outlook is now positive, as companies have either offered
to license the patents on royalty free terms or have indicated that
the patent doesn't have essential claims on the Voice Browser
specifications
- The Voice Browser PAG expects to complete its work in June
2003
Next Steps
- Driving current specs through to W3C REC status
- Gathering requirements for next version of VoiceXML, e.g.
- Modularization
- For use with XHTML for multimodal interaction
- Incremental changes building on success of 2.0
- Richer kinds of dialog with better support for tuning
- Support for XForms?
- Possible interest in resuming work on pronunciation lexicons
and stochastic language models
Demo1 — a small
sample of what it would feel like to access the W3C website via
VoiceXML
Demo2 — an example
of the improvement in speech synthesis, and a hint at the
opportunities for richer dialog
Note: commercial applications generally use precorded
prompts made using human actors
What lies beyond ...
A personal view of the
challenges for voice interaction
More Robust Speech Recognition
- Picking the nuances of speech out of the sound field
- Understanding the acoustic environment
- Combining stochastic and linguistic models of speech
- Using better knowledge about groups of speakers
- Something in between speaker dependent and speaker independent
recognition?
Reducing the effort needed to tune new applications
- Today this involves collecting lots of usage data, and
carefully tuning the prompts and grammars accordingly
- How can we make this easier?
- By sharing knowledge across applications
- By combining task specific knowledge with general
knowledge
- With deeper natural language understanding
- This is a research challenge!
Helping computers to understand things our way
- Today's computers know nothing about the everyday world and
that's why they are so stupid!
- Computers need to learn some common sense!
- Common sense is estimated to involve hundreds of millions of
ideas
- Cyc, Thought Treasure and Open Mind
- Projects that have tackled common sense
- Broad coverage natural language parsers
- Combining statistical and linguistic knowledge
- Natural language for knowledge representation
- Harnessing the Web to tackle really big projects
- Open source projects with thousands of volunteers
Thank you for listening ....
Any Questions?