2.1. Positive Conditions
The sublanguage of positive conditions in RIF-BLD determines what can appear as a body of a rule (also known as the if-part, antecedent, or condition part of the rule) supported by RIF-BLD. As explained in Section Overview, RIF-BLD corresponds to definite Horn rules, and the bodies of such rules are conjunctions of atomic formulas without negation. However, it is well-known that disjunctions of such conditions can also be used in the bodies of rules without changing the essential properties of the rule language. This is based on the fundamental logical tautologies (h ← b ∨ c) ≡ ((h ← b) ∧ (h ← c)) and ∀ x (F ∧ G) ≡ (∀ x F ∧ ∀ x G). In other words, a rule with a disjunction in the body can be split into two or more rules that have no such disjunction.
To make RIF dialects suitable as Web languages, RIF supports XML Schema primitive data types and some other data types. In addition, RIF promotes the use of Internationalized Resource Identifiers (or IRIs) RFC 3987 to refer to individuals, predicates, and functions.
To ensure extensibility and to provide for future higher-order dialects based on formalisms such as HiLog and Common Logic, RIF does not draw a sharp boundary between the symbols used to denote individuals from symbols used as names for functions or predicates. Instead, all constant, predicate, and function symbols are drawn from the same universal set. RIF dialects control the contexts in which the different symbols can occur by attaching signatures to these symbols.
RIF-BLD carefully selects signatures for the symbols so that the corresponding logic will be first-order: each symbol has a unique role as a symbol that represents an individual object, a function symbol of a particular arity, or a predicate symbol of a particular arity. However, dialects extending RIF-BLD will be allowed to use signatures in less restrictive fashions so that symbols could be polymorphic (i.e. be allowed to occur in several different contexts; e.g., as individuals and as predicates) and polyadic (i.e take a varying number of arguments).
We begin by describing a syntax, which is more general than what RIF-BLD permits. This syntax can be used in the various dialects that extend RIF-BLD. Then we introduce the notion of a signature and specify the restrictions on the way signatures are allowed to be assigned to symbols. Next we define the presentation syntax using EBNF and describe the corresponding XML-based exchange syntax. Finally, we give a model-theoretic semantics to RIF-BLD.
2.1.1. Syntax
In this document we will introduce two related but distinct syntaxes:
-
Presentation syntax. This syntax is used in formal definitions, especially for the semantics. It is a human-oriented syntax and, therefore, we use it in the model theory and the examples. The presentation syntax is not meant to be used for exchange of RIF rules.
-
XML syntax. This syntax is the normative XML serialization of the presentation syntax. The key features of this syntax are derived from the presentation syntax, but some aspects related to rule exchange do not have counterparts in the presentation syntax.
2.1.1.1. Symbols and Signatures
The alphabet of RIF Condition Language consists of a countably infinite set of constant symbols Const, a countably infinite set of variable symbols Var (disjoint from Const), connective symbols And and Or, quantifier Exists, the symbol =, and auxiliary symbols, such as "(" and ")". In the RIF presentation syntax, variables are written as Unicode strings preceded with the symbol "?". The syntax for constant symbols is given in Section Symbol Spaces below.
The language of RIF-BLD is the set of formulas constructed using the above alphabet according to the rules spelled out below.
The basic language construct is called term, which is defined inductively as follows:
-
If t ∈ Const or t ∈ Var then t is a term.
-
If t and t1, ..., tn are terms then t ( t1 ... tn ) is a term.
This definition is very general. It makes no distinction between constant symbols that represent individuals, predicates, and function symbols. The same symbol can occur in multiple contexts at the same time. For instance, if p, a, and b are symbols then p ( p ( a ) p ( a p c ) ) is a term. Even variables and general terms are allowed to occur in the position of predicates and function symbols, so p ( a ) ( ?v ( a c ) p ) is also a term. To control the context in which any given symbol can occur in a RIF dialect, the language associates a signature with each symbol (both constant and variable symbols).
Signatures. Let SigNames be a non-empty, partially-ordered finite or countably infinite set of signature names. We require that this set includes at least the name atomic, which represents the context of atomic formulas. Dialects are free to introduce additional signature names. For instance, as we shall soon see, RIF-BLD also introduces another signature, term{ }. The partial order on SigNames is dialect-specific (see, the specifics for RIF-BLD later); it is used in the definition of well-formed terms below.
We use the symbol < to represent the partial order on SigNames. Informally, α < β means that terms with signature α can be used wherever terms with signature β are allowed.
A signature is a statement of the form η{e1, ..., en, ...} where η ∈ SigNames is the name of the signature and {e1, ..., en, ...} is a countable set of arrow expressions. Such a set can thus be infinite, finite, or even empty. In RIF-BLD, signatures can have at most one arrow expression. Other dialects (such as HiLog, for example) may require polymorphic symbols and thus allow signatures with more than one arrow expression in them.
An arrow expression is defined as follows:
-
If κ, κ1, ..., κn, n≥0, are signature names from SigNames, then (κ1 ... κn) ⇒ κ is an arrow expression. In particular, () ⇒ term and (term) ⇒ term are arrow expressions.
-
If κ above is atomic then the signature is called a Boolean expression.
A set S of signatures is coherent iff
-
S contains the special signature atomic{ }, which represents the context of atomic formulas; and
-
S has at most one signature for any given signature name.
-
Whenever S contains a pair of signatures, ηS and κR, such that η<κ then R⊆S. Here ηS denotes a signature with the name η and the associated set of arrow expression S; similarly κR is a signature named κ with the set of expressions R. The requirement that R⊆S ensures that symbols that have signature η can be used wherever the symbols with signature κ are allowed.
2.1.1.2. Well-formed Terms and Formulas
Signatures help control the context in which various symbols can occur through the notion of well-formed formulas. This is done using the notion of well-formed terms, as explained next.
Each constant and variable symbol is associated with exactly one signature from a coherent set of signatures. Different symbols can be associated with the same signature, but no symbol can be associated with more than one signature. The equality symbol, =, is also given a signature. This signature may vary from dialect to dialect, but RIF requires that it contains only the arrow expressions of the form (κ κ) ⇒ atomic (i.e., the arguments must have the same signature and the result must be atomic). Since signature names uniquely identify signatures in coherent signature sets, we will often use signature names to refer to signatures. For instance, we may say that symbol f has signature atomic rather than that "f has signature atomic{ }" or that "f has signature named atomic."
-
If s is a constant or variable symbol with signature η then s is a well-formed term with signature η.
-
A term t ( t1 ... tn ), 0≤n, is a well-formed term whose signature is σ iff
-
t is a well-formed term that has a signature, which contains an arrow expression of the form (σ1 ... σn) ⇒ σ; and
-
Each ti is a well-formed term whose signature is σ'i, such that σ'i, < σi.
-
A term t ( t1 ... tn ) is a well-formed atomic formula iff it is a well-formed term with the signature atomic.
Since the signature of = contains only the arrow expressions of the form (κ κ) ⇒ atomic, it follows that an expression of the form t1 = t2 is a well formed term and also a well-formed atomic formula, only if t1 and t2 are well-formed terms that have the same signature.
Note that according to the above definition f ( ) and f are distinct terms.
More general formulas are constructed out of atomic formulas with the help of logical connectives. The condition sublanguage of RIF-BLD defines the following general well-formed condition formulas.
-
If φ is a well-formed atomic formula then it is also a well-formed condition formula.
-
If are φ1, ..., φn, n ≥ 0, are well-formed condition formulas then so is And ( φ1 ... φn ). As a special case, And ( ) is allowed and is treated as a tautology true.
-
If φ1, ..., φn, n ≥ 0, are well-formed condition formulas then so is Or ( φ1 ... φn ). When n=0, we get Or ( ) as a special case; it is treated as false -- a formula that is always false.
-
If φ is a well-formed condition formula and ?V1, ..., ?Vn are variables then Exists ?V1 ... ?Vn ( φ ) is a well-formed condition formula.
Examples. We illustrate the above definitions with the following examples. In addition to atomic, the examples also use another signature, term{ }. As we shall soon see, this signature is used in RIF-BLD.
Consider the term p ( p ( a ) p ( a b c ) ). If p has the (polymorphic) signature mysig{(term)⇒term, (term term)⇒term, (term term term)⇒term} and a, b, c each has the signature term{ } then p ( p ( a ) p ( a b c ) ) is a well-formed term with signature term{ }. If instead p had the signature mysig2{(term term)⇒term, (term term term)⇒term} then p ( p ( a ) p ( a b c ) ) would not be a well-formed term since then p ( a ) would not be well-formed (in this case, p would have no arrow expression which allows p to take just one argument).
For a more complex example, let r have the signature mysig3{(term)⇒atomic, (atomic term)⇒term, (term term term)⇒term}. Then r ( r ( a ) r ( a b c ) ) is well-formed. The interesting twist here is that r ( a ) is a Boolean rather than an individual, but this is allowed by the arrow expression (atomic term)⇒ term, which is part of r's signature. If r's signature were mysig4{(term)⇒atomic, (atomic term)⇒atomic, (term term term)⇒term} instead, then r ( r ( a ) r ( a b c ) ) would be not only a well-formed term, but also a well-formed atomic formula.
An even more advanced example of using signatures is when the right-hand side of an arrow expression is something other than term or atomic. For instance, let John, Mary, NewYork, and Boston have signatures term{ }; flight and parent have signature h2{(term term)⇒atomic}; and closure has signature hh1{(h2)⇒p2}, where the signature p2 has the form p2{(term term)⇒atomic}. Then flight ( NewYork Boston ), closure ( flight ) ( NewYork Boston ), parent ( John Mary ), and closure ( parent ) ( John Mary ) would be well-formed formulas. Such formulas are allowed in languages like HiLog, which support predicate constructors like closure in the above example.
2.1.1.3. Symbol Spaces
Throughout this document, the xsd: prefix stands for the XML Schema namespace URI http://www.w3.org/2001/XMLSchema#, the rdf: prefix stands for http://www.w3.org/1999/02/22-rdf-syntax-ns#, and rif: stands for the URI of the RIF namespace, http://www.w3.org/2007/rif#. Syntax such as xsd:string should be understood as a compact uri -- a macro that expands to a concatenation of the character sequence denoted by the prefix xsd and the string string. In the next version of this document we intend to introduce a syntax for defining prefixes for compact URIs.
The set of all constant symbols in RIF has a number of predefined subsets, called symbol spaces, which are used to represent XML Schema data types, data types defined in other W3C specifications, such as rdf:XMLLiteral, and to distinguish other sets of constants. Constant symbols that belong to the various symbol spaces have special presentation syntax and semantics.
Formally, a symbol space is a named subset of the set of all constants, Const. The semantic aspects of symbol spaces will be described in Section Model Theory for Condition Language of RIF BLD. Each symbol in Const belongs to a symbol space.
Each symbol space has an associated lexical space and a number of identifiers.
-
The lexical space of a symbol space is a non-empty set of Unicode character strings.
-
An identifier of a symbol space is an absolute IRI. The same symbol space is allowed to have more than one identifier (but different symbol spaces cannot share an identifier).
To simplify the language, this document will often use symbol space identifiers to refer to the actual symbol spaces (for instance, we may say "symbol space xsd:string" instead of "symbol space identified by xsd:string").
To refer to a constant in a particular RIF symbol space, we use the following presentation syntax:
LITERAL^^SYMSPACE
where LITERAL is a Unicode string, called the lexical part of the symbol, and SYMSPACE is an identifier of the symbol space in the form of an absolute IRI string. LITERAL must be an element in the lexical space of the symbol space. For instance, 1.2^^xsd:decimal and 1^^xsd:decimal are legal symbols because 1.2 and 1 are members of the lexical space of the XML Schema data type xsd:decimal. On the other hand, a+2^^xsd:decimal is not a legal symbol, since a+2 is not part of the lexical space of xsd:decimal.
RIF-compliant implementations must support the following symbol spaces. Rule sets that are exchanged through RIF can use additional symbol spaces as explained below.
-
xsd:long (http://www.w3.org/2001/XMLSchema#long).
-
xsd:string (http://www.w3.org/2001/XMLSchema#string).
-
xsd:integer (http://www.w3.org/2001/XMLSchema#integer).
-
xsd:decimal (http://www.w3.org/2001/XMLSchema#decimal).
-
xsd:time (http://www.w3.org/2001/XMLSchema#time).
-
xsd:dateTime http://www.w3.org/2001/XMLSchema#dateTime).
The lexical spaces of the above symbol spaces are defined in the document XML Schema Part 2: Datatypes.
-
rdf:XMLLiteral (http://www.w3.org/1999/02/22-rdf-syntax-ns#XMLLiteral).
This symbol space represents XML content. The lexical space of rdf:XMLLiteral is defined in the document Resource Description Framework (RDF): Concepts and Abstract Syntax.
-
rif:text (for text strings with language tags attached).
This symbol space represents text strings with a language tag attached. The lexical space of rif:text is the set of all Unicode strings of the form ...@LANG, i.e., strings that end with @LANG where LANG is a language identifier as defined in IETF RFC 3066.
-
rif:iri (for internationalized resource identifier or IRI).
Constant symbols that belong to this symbol space are intended to be used in a way similar to RDF resources. The lexical space consists of all absolute IRIs as specified in RFC 3987; it is unrelated to the XML primitive type anyURI. A rif:iri constant is supposed to be interpreted as a reference to one and the same object regardless of the context in which that constant occurs.
-
rif:local (for constant symbols that are not visible outside of a particular set of RIF formulas).
Symbols in this symbol space are used locally in their respective rule sets. This means that occurrences of the same rif:local-constant in different rule sets are viewed as unrelated distinct constants, but occurrences of the same constant in the same rule set must refer to the same object. The lexical space of rif:local is the same as the lexical space of xsd:string.
Symbols with an ill-formed lexical part. RIF constant symbols that belong to one of the aforesaid RIF-supported symbol spaces must be well-formed, i.e., their lexical part must belong to the lexical space associated with the symbol space. For instance, 123^^xsd:long has a correct lexical part, since 123 belongs to the lexical space of the data type xsd:long. In contrast, abc^^xsd:long is ill-formed, as it does not have a correct lexical part. A compliant RIF-BLD interpreter must reject ill-formed symbols.
Symbols with undefined symbol spaces. RIF allows symbols of the form LITERAL^^SYMSPACE where SYMSPACE is not one of the pre-defined RIF symbol spaces. These are treated as "uninterpreted" constant symbols in the RIF language and the lexical space of such a symbol space is considered to be the set of all Unicode strings. Dialects that extend RIF-BLD might appropriate some of the symbol spaces, which are left undefined in RIF-BLD, and give them special semantics.
2.1.1.4. Signatures Used in RIF-BLD
RIF-BLD presents a much simpler picture to the user by restricting the set of well-formed terms to a specific coherent set of signatures. Namely, the signature set of RIF-BLD contains the following signatures:
-
term{ }, atomic{ }, bi_atomic{ }, where bi_atomic<atomic.
The signature term{ } represents the context in which individual objects (but not atomic formulas) can appear. The signature bi_atomic{ } represents atomic formulas for builtin predicates (such as fn:substring). Since bi_atomic<atomic, builtin atomic formulas are also atomic formulas, but normally most atomic formulas are user-defined and they will have the signature atomic rather than bi_atomic.
-
For every integer n ≥ 0, there are signatures fn{(term ... term) ⇒ term}, pn{(term ... term) ⇒ atomic}, and bin{(term ... term) ⇒ bi_atomic} (in each case there are n terms inside the parentheses), which represent function symbols of arity n, (user-defined) predicate symbols of arity n, and n-ary builtin predicates, respectively. The symbols fn pn, and bin are reserved signature names in RIF-BLD.
-
A symbol in Const can have exactly one signature, fn, pn, or bin, where n ≥ 0. It cannot have the signature atomic or bi_atomic (only terms can have such signatures, not symbols). Thus, in RIF-BLD each constant symbol can be either an individual, a predicate of one particular arity, a builtin of one particular arity, or a function symbol of one particular arity -- it is not possible for the same symbol to play more than one role.
-
The constant symbols that correspond to XML Schema data types all have the signature term in RIF-BLD. The symbols of type rif:iri and rif:local can have the following signatures in RIF-BLD: term, fn, pn, or bin, for n = 0,1,....
-
All variables are associated with signature term{ }, so they can range only over individuals.
-
A equality formula, =, has signature p2{(term term) ⇒ atomic}. This means that equality can compare only those terms whose signature is term; it cannot compare predicate names or function symbols.
RIF-BLD requires no extra syntax for declaring signatures, since signatures can be inferred. Indeed, RIF-BLD requires that each symbol is associated with a unique signature. Therefore, the signature can be determined from the context in which the symbol is used. If a symbol is used in more than one context, the parser should treat it as a syntax error. If no errors are found, all uniterms and atomic formulas are guaranteed to be well-formed. As a consequence, signatures are not part of the RIF-BLD language and term, atomic, and bi_atomic are not reserved keywords.
Builtin predicates are not subject to the above signature inference rule. The signatures of the builtin predicates are defined by List_of_functions_and_operators. In particular, all symbols with the http://www.w3.org/2005/xpath-functions# prefix are considered to be builtins and have signatures of the form bin{... ⇒ bi_atomic}.
In dialects that extend RIF-BLD, signature inference may not always be possible. We expect that most dialects will use signature inference and RIF does not define any special sublanguage for signatures. However, signature inference may not always be possible or desirable in some dialects. In these cases, we expect those dialects to introduce their own primitives for defining signatures.
2.1.1.5. EBNF for the Presentation Syntax of the RIF-BLD Condition Language
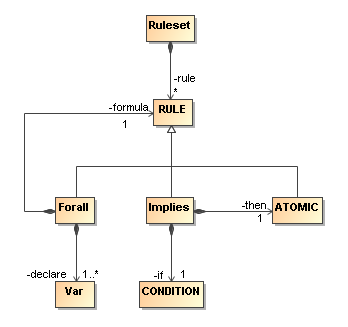
The overall structure of the syntax used in the RIF-BLD condition sublanguage is depicted on the following diagram.

The central syntactic class of RIF, CONDITION, is specified recursively through its subclasses and their parts. The Equal class has two side roles. Two pairs of roles distinguish between the declare and formula parts of the Exists class, and between the operation (op) and arguments (arg) of the Uniterm class, where multiple arguments are subject to an ordered constraint (the natural "left-to-right" order).
The syntactic classes are partitioned into classes that will not be visible in serializations (written in all-uppercase letters) and classes that will be visible in instance markup (written with a leading uppercase letter only).
The three classes Var, CONDITION, and ATOMIC are used in the syntax of Horn Rules.
We now give an EBNF for the RIF presentation syntax. This syntax is somewhat abstract in nature. In particular, it does not address the concrete details of how constants and variables are represented. For instance, it ignores the issues that have to do with delimiters, such as white spaces and escape symbols. Instead, white space is informally used as a delimiter. For instance, TERM* is to be understood as TERM* ::= | TERM TERM*. This is done on purpose, since RIF's presentation syntax is intended to be used for specifying semantics and to illustrate the main RIF concepts through examples. It is not intended as a concrete syntax for a rule language. RIF defines a concrete syntax only for exchanging rules, and that syntax is XML-based.
EBNF grammar
CONDITION ::= 'And' ' ( ' CONDITION* ' ) ' |
'Or' ' ( ' CONDITION* ' ) ' |
'Exists ' Var+ ' ( ' CONDITION ' ) ' |
ATOMIC
ATOMIC ::= Uniterm | Equal
Uniterm ::= Const ' ( ' TERM* ' ) '
Equal ::= TERM ' = ' TERM
TERM ::= Const | Var | Uniterm
Const ::= LITERAL '^^' SYMSPACE
Var ::= '?' VARNAME
The above is a standard syntax for a variant of first-order logic. The application of a constant (Const) symbol to a sequence of terms is called a Uniterm (Universal term); it can play the role of a term or an atomic formula depending on the syntactic context in which the application occurs. The non-terminal ATOMIC stands for atomic formula. The Exists formula, where Var+ stands for the list of variables that are free in CONDITION, is an existential formula. It is the only kind of quantified formulas in RIF-BLD, but other dialects may add universal quantification. The And formula defines conjunctions of conditions, and 'Or' denotes disjunctions. Finally, CONDITION assembles everything into what we earlier called RIF condition formulas.
Note that individuals, function symbols, and predicate symbols all belong to the same set of symbols Const. This syntax is more general than what RIF-BLD actually permits. As explained in Section Symbols and Signatures a set of signatures further restricts this syntax to allow only the standard first-order logic terms.
RIF-BLD presentation syntax does not commit to any particular vocabulary for the names of variables or for the literals used in constant symbols. In the examples, variables are denoted by Unicode character sequences beginning with a ?-sign. Constant symbols have the form: LITERAL^^SYMSPACE, where SYMSPACE is an IRI string that identifies the symbol space of the constant and LITERAL is a Unicode string from the lexical space of that symbol space.
In the condition language of RIF-BLD, a variable can be free or quantified. All quantification is explicit and the variables introduced by quantification must also occur in the quantified formula. Variables that are not explicitly quantified are free.
Conditions with free variables are used as queries and also in the if part of a rule. In the latter case, the free variables in a condition formula must also occur in the then part of the rule. We shall see in Section Horn Rules that such variables are quantified universally outside of the rule, and the scope of such quantification is the entire rule. For instance, the variable ?Y in the first RIF condition of Example 1 is quantified, existentially, but ?X is free. However, when this condition occurs in the if part of the second rule in Example 1, then this variable is quantified universally outside of the rule. (The precise syntax for RIF rules is given in Section Horn Rules.)
Example 1 (A RIF condition in and outside of a rule)
RIF condition:
Exists ?Y ( condition ( ?X ?Y ) )
RIF Horn rule:
Forall ?X ( then_part ( ?X ) :- Exists ?Y ( condition ( ?X ?Y ) ) )
2.1.1.6. XML Syntax
The XML serialization for RIF-BLD presentation syntax given in this section is alternating or fully striped (e.g., Alternating Normal Form). Positional information is optionally exploited only for the arg role elements. For example, role elements (declare and formula) are explicit within the Exists element. Following the examples of Java and RDF, we use capitalized names for class elements and names that start with lowercase for role elements.
The all-uppercase classes in the presentation syntax, such as CONDITION, become XML entities. They act like macros and are not visible in instance markup. The other classes as well as non-terminals and symbols (such as Exists or =) become XML elements with optional attributes, as shown below.
Classes, roles and their intended meaning
- And (conjunction)
- Or (disjunction)
- Exists (quantified formula for 'Exists', containing declare and formula roles)
- declare (declare role, containing a Var)
- formula (formula role, containing a CONDITION formula)
- Uniterm (atomic or function-expression formula)
- op (operation role)
- arg (argument role)
- Equal (prefix version of term equation '=')
- side (left-hand and right-hand side role)
- Const (predicate symbol, function symbol, or individual, with optional 'type' attribute)
- Var (logic variable)
For the XML Schema Definition (XSD) of the RIF-BLD condition language see Appendix Specification.
The XML syntax for symbol spaces utilizes the type attribute associated with XML term elements such as Const. For instance, a literal in the xsd:dateTime data type can be represented as <Const type="xsd:dateTime">2007-11-23T03:55:44-02:30</Const>.
The following example illustrates XML serialization of RIF conditions.
Example 2 (A RIF condition and its XML serialization):
We use the prefix bks as an abbreviation for http://example.com/books#
and curr for http://example.com/currencies#
a. RIF condition
And ( Exists ?Buyer ( purchase^^rif:local ( ?Buyer
?Seller
book^^rif:local ( ?Author bks:LeRif^^rif:iri )
curr:USD^^rif:iri ( 49^^xsd:integer ) )
?Seller=?Author )
b. XML serialization
<And>
<formula>
<Exists>
<declare><Var>Buyer</Var></declare>
<formula>
<Uniterm>
<op><Const type="rif:local">purchase</Const></op>
<arg><Var>Buyer</Var></arg>
<arg><Var>Seller</Var></arg>
<arg>
<Uniterm>
<op><Const type="rif:local">book</Const></op>
<arg><Var>Author</Var></arg>
<arg><Const type="rif:iri">bks:LeRif</Const></arg>
</Uniterm>
</arg>
<arg>
<Uniterm>
<op><Const type="rif:iri">curr:USD</Const></op>
<arg><Const type="xsd:integer">49</Const></arg>
</Uniterm>
</arg>
</Uniterm>
</formula>
</Exists>
</formula>
<formula>
<Equal>
<side><Var>Seller</Var></side>
<side><Var>Author</Var></side>
</Equal>
</formula>
</And>
2.1.1.7. Translation Between the Presentation and the XML Syntaxes
The translation between the presentation syntax and the XML syntax is given by a table as follows.
| Presentation Syntax | XML Syntax |
|---|
And (
conjunct1
. . .
conjunctn
) | <And>
<formula>conjunct1</formula>
. . .
<formula>conjunctn</formula>
</And> |
Or (
disjunct1
. . .
disjunctn
) | <Or>
<formula>disjunct1</formula>
. . .
<formula>disjunctn</formula>
</Or> |
Exists
variable1
. . .
variablen (
body
) | <Exists>
<declare>variable1</declare>
. . .
<declare>variablen</declare>
<formula>body</formula>
</Exists> |
predfunc (
argument1
. . .
argumentn
) | <Uniterm>
<op>predfunc</op>
<arg>argument1</arg>
. . .
<arg> argumentn</arg>
</Uniterm> |
left = right | <Equal>
<side>left</side>
<side>right</side>
</Equal> |
name^^space | <Const type="space">name</Const> |
?name | <Var>name</Var> |
2.1.2. Model Theory for Condition Language of RIF BLD
The first step in defining a model-theoretic semantics for a logic-based language is to define the notion of a semantic structure, also known as an interpretation. (See end note on the rationale.) In this section we define basic semantic structures. This definition will be extended in Extension of Semantic Structures for Frames when we introduce frame syntax.
2.1.2.1. Basic semantic structures
Semantic structures are used to assign a truth value to each formula. Currently, by formula we mean anything produced by the CONDITION production in the presentation syntax. Later on, formulas will also include rules. We first define the notion of a truth value formally and then introduce semantic structures. Next we give the semantics to symbol spaces and, finally, define truth values of formulas with respect to semantic structures.
Truth values. The set of truth values is denoted by TV. For RIF-BLD, TV includes only two values, t (true) and f (false). (See end note on truth values.)
In RIF, TV has a total or partial order, called the truth order, and denoted with <t. In RIF-BLD, f <t t, and it is a total order. (See end note on ordering truth values.)
Semantic structures. A basic semantic structure, I, is a tuple of the form <D,IC, IV, IF, IR>.
Here D is a non-empty set of elements called the domain of interpretation of I. We will continue to use Const to refer to the set of all constant symbols and Var to refer to the set of all variable symbols.
The other components of I are mappings defined as follows:
-
IC from Const to elements of D
-
IV from Var to elements of D
-
IF from Const to functions from D* into D (here D* is a set of all tuples of any length over the domain D)
-
IR from Const to truth-valued mappings D* → TV
We also define the following mapping, I, based on the mappings IC, IV, and IF:
-
I(k) = IC(k), if k is a symbol in Const
-
I(?v) = IV(?v), if ?v is a variable in Var
-
I(f ( t1 ... tn )) = IF(f)(I(t1),...,I(tn))
Semantics of symbol spaces. Symbol spaces affect the domain of I and the mapping IC as follows. First, some symbol spaces, called primitive data types, have a value space, denoted VSsymsp, and a mapping from the lexical space to the VSsymsp, denoted Lsymsp, where symsp is an identifier for the symbol space.
The value space and the lexical-to-value-space mapping are defined as part of the data type definition and do not depend on I. For every primitive datatype symsp it must hold that:
-
VSsymsp ⊆ D; and
-
For each constant lit^^symsp in the symbol space symsp, IC(lit^^symsp) = Lsymsp(lit).
That is, when restricted to a symbol space, symsp, IC must map the corresponding constants according to Lsymsp.
RIF-BLD does not impose restrictions on the interpretation of constants (the mapping IC) in symbol spaces which are not primitive datatypes. Other dialects may do so. An example of such a restriction is that no constant in a particular symbol space may be mapped to an element in the value space of any XML Schema data type.
The above semantics is not limited to any particular set of symbol spaces or primitive data types. Any symbol space is covered as long as its lexical space is well-defined, and any data type is acceptable as long as its value space and the lexical-to-value mapping are known.
The primitive data types that are currently supported by RIF, xsd:long, xsd:integer, xsd:decimal, xsd:string, xsd:time, and xsd:dateTime, rdf:XMLLiteral, and rif:text, are required to be covered by every interpretation. Their value spaces and the lexical-to-value space mappings are defined as follows:
-
For XML Schema data types (xsd:long, xsd:integer, xsd:decimal, xsd:string, xsd:time, and xsd:dateTime), these are defined in the XML Schema Part 2: Datatypes specification.
-
The value space for the primitive data type rdf:XMLLiteral is defined in Resource Description Framework (RDF): Concepts and Abstract Syntax.
-
The value space of rif:text is the set of all pairs of the form (string, lang), where string is a Unicode character sequence and lang is a lowercase Unicode character sequence which is a natural language identifier as defined by RFC 3066. The lexical-to-value mapping of rif:text, Lrif:text, maps each symbol string@lang in the lexical space of rif:text to (string, lower-case(lang)), where lower-case(lang) is lang written in all-lowercase letters.
The value space and the lexical-to-value mapping for rif:text defined here are compatible with RDF's semantics for strings with named tags.
The value space of a data type should not be confused with the lexical space. Lexical spaces define the syntax of the constant symbols that belong to the various primitive data types. In contrast, value spaces define the meaning of the constants in data types. The lexical and the value spaces are often not even isomorphic. For instance, 1.2^^xsd:decimal and 1.20^^xsd:decimal are two legal constants in RIF because 1.2 and 1.20 belong to the lexical space of xsd:decimal. However, these two constants are interpreted by the same element of the value space of the xsd:decimal type. Therefore, 1.2^^xsd:decimal = 1.20^^xsd:decimal is a RIF tautology. Likewise, RIF semantics for data types implies certain inequalities. For instance, abc^^xsd:string ≠ abcd^^xsd:string is a tautology, since IC must map these two constants into distinct elements in the value space of xsd:string. On the other hand, abc^^rif:local ≠ abcd^^rif:local is not a tautology in RIF, since IC is not restricted over the lexical space of rif:local and these two constants can be mapped to the same element in D in some semantic structures and to different elements in others.
Semantics of undefined symbol spaces. Section Symbol Spaces addressed the syntactic aspects of the treatment of "unknown" symbol spaces, i.e., symbol spaces that are not defined by the RIF specification. It defined the lexical space of those symbols as the set of all Unicode strings. Semantically, unknown symbol spaces are treated as follows. First, they are not assigned any value space. Thus, such symbol spaces are not considered to be primitive data types by RIF even though they may be viewed as data types by some concrete rule languages that use RIF for exchange. Second, RIF does not impose any restrictions on the mapping IC over the unknown symbol spaces.
Truth valuation of formulas. Observe that the notion of signatures from Section Symbols and Signatures is used only to constrain the syntax and does not appear in the definition of the semantic structure. This is because when we define truth valuations for formulas, below, all formulas are assumed to be well-formed.
Truth valuation for well-formed formulas in RIF-BLD is determined using the following function, denoted ITruth:
-
Atomic formulas: ITruth(r ( t1 ... tn )) = IR(r)(I(t1),...,I(tn))
-
Equality: ITruth(t1 = t2) = t iff I(t1) = I(t2); ITruth(t1=t2) = f otherwise.
-
Conjunction: ITruth(And ( c1 ... cn )) = mint(ITruth(c1),...,ITruth(cn)), where mint is minimum with respect to the truth order.
-
Disjunction: ITruth(Or ( c1 ... cn )) = maxt(ITruth(c1),...,ITruth(cn)), where maxt is maximum with respect to the truth order.
-
Quantification: ITruth(Exists ?v1 ... ?vn ( c )) = maxt(I*Truth(c)), where maxt is taken over all interpretations I* of the form <D,IC, I*V, IF, IR>, where the mapping I*V has the same value as IV on all variables except, possibly, on the variables ?v1,...,?vn.