XProc: An XML Pipeline Language
W3C Working Draft 28 September 2006
- This Version:
- http://www.w3.org/TR/2006/WD-xproc-20060928/
- Latest Version:
- http://www.w3.org/TR/xproc/
- Editor:
- Norman Walsh, Sun Microsystems, Inc. <Norman.Walsh@Sun.COM>
This document is also available in these non-normative formats: XML
Copyright © 2006 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply.
Abstract
This specification describes the syntax and semantics of XProc: An XML Pipeline Language, a language for describing operations to be performed on XML documents.
An XML Pipeline specifies a sequence of operations to be performed on one or more XML documents, producing one or more XML documents as output. Steps in the pipeline may read or write non-XML resources as well.
Status of this Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/.
This document was produced by the XML Processing Model Working Group which is part of the XML Activity. Publication as a Working Draft does not imply endorsement by the W3C Membership. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to cite this document as other than work in progress.
This is a first public Working Draft, based on the previously published Requirements Document. Although not all the details of the design are complete, the Working Group has chosen early publication in order to show the direction we are heading and to encourage feedback from potential users.
Please send comments about this document to public-xml-processing-model-comments@w3.org (public archives are available).
This document was produced by a group operating under the 5 February 2004 W3C Patent Policy. W3C maintains a public list of any patent disclosures made in connection with the deliverables of the group; that page also includes instructions for disclosing a patent. An individual who has actual knowledge of a patent which the individual believes contains Essential Claim(s) must disclose the information in accordance with section 6 of the W3C Patent Policy.
Table of Contents
- 1 Introduction
- 2 Pipeline Concepts
-
- 2.1 Steps, Constructs, and Subpipelines
- 2.2 Inputs and Outputs
- 2.3 Parameters
- 2.4 Flow Graph
- 3 Language Constructs
- 4 Syntax
-
- 4.1 Overview
-
- 4.1.1 Associating Documents with Ports
- 4.1.2 Scoping of Names
- 4.1.3 Extension attributes
- 4.1.4 Extension elements
- 4.2 Detailed Vocabulary
-
- 4.2.1 p:pipeline Element
- 4.2.2 p:declare-input Element
- 4.2.3 p:declare-output Element
- 4.2.4 p:declare-parameter Element
- 4.2.5 p:step Element
- 4.2.6 p.input Element
- 4.2.7 p:param Element
- 4.2.8 p:import-param Element
- 4.2.9 p:for-each Element
- 4.2.10 p:viewport Element
- 4.2.11 p:choose/p:when/p:otherwise Elements
- 4.2.12 p:group Element
- 4.2.13 p:try/p:catch Elements
- 4.2.14 p:declare-step Element
- 4.2.15 p:pipeline-library Element
- 4.2.16 p:import Element
- 5 Errors
-
- 5.1 Static Errors
- 5.2 Dynamic Errors
Appendices
1 Introduction
An XML Pipeline specifies a sequence of operations to be performed on a collection of input documents. Pipelines take zero or more XML documents as their input and produce zero or more XML documents as their output. Steps in the pipeline may read or write non-XML resources as well.
A pipeline consists of components. Like pipelines, components take zero or more XML documents as their input and produce zero or more XML documents as their output. The inputs to a component come from the web, from the pipeline document, from the inputs to the pipeline itself, or from the outputs of other components in the pipeline. The outputs from a component are consumed by other components, are outputs of the pipeline as a whole, or are discarded.
There are two kinds of components: steps and (language) constructs. Steps carry out single operations and have no substructure as far as the pipeline is concerned, whereas constructs can include components within themselves.
This specification defines a standard library, Appendix D, Standard Component Library, of steps. Pipeline implementations may support additional steps as well.
Figure 1, “A simple, linear XInclude/Validate pipeline” is a graphical representation of a simple pipeline that performs XInclude processing and validation on a document.
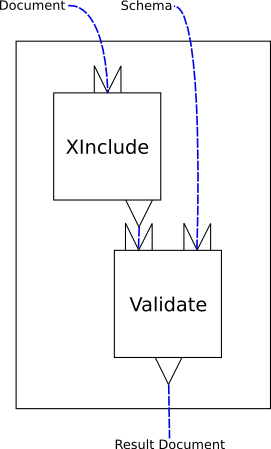
This is a pipeline that consists of two steps, XInclude and Validate. The pipeline itself has two inputs, “Document” and “Schema”. How these inputs are connected to XML documents outside the pipeline is implementation-defined. The XInclude step reads the pipeline input “Document” and produces a result document. The Validate step reads the pipeline input “Schema” and the output from the XInclude step and produces a result document. The result of the validation is the result of the pipeline, “Result Document”. How pipeline outputs are connected to XML documents outside the pipeline is implementation-defined.
Figure 2, “A validate and transform pipeline” is a more complex example: it performs schema validation with an appropriate schema and then styles the validated document.
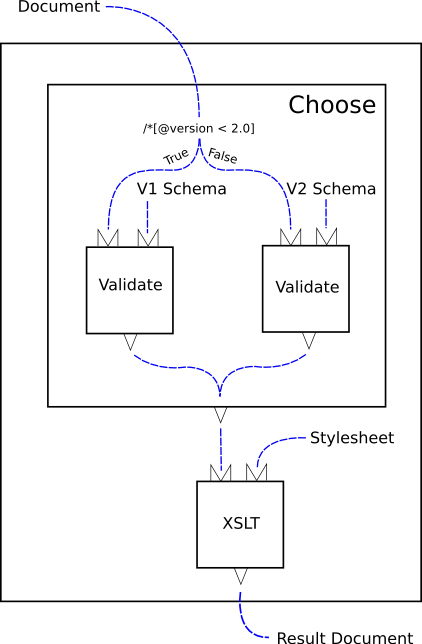
The heart of this example is the conditional construct. The “choose” construct evaluates an XPath expression over a test document. Based on the result of that expression, one or another branch is evaluated. In this example, each branch consists of a single validate component.
2 Pipeline Concepts
[Definition: A pipeline is an acyclic, directed graph of components connected together by inputs and outputs.] In other words, it's a set of components connected together with outputs flowing into inputs without any loops (no component can read its own output, directly or indirectly). A pipeline is itself a construct and must satisfy the constraints on constructs.
The result of evaluating a pipeline is the result of evaluating the components that it contains, in the order determined by the flow graph that connects them. A pipeline must behave as if it evaluated each component each time it occurs in the flow graph. Unless otherwise indicated, implementations must not assume that components are functional (that is, that their outputs depend only on their explicit inputs and parameters) or side-effect free.
2.1 Steps, Constructs, and Subpipelines
Steps are the basic computational units of a pipeline. [Definition: A step is an atomic unit of XML processing, such as XInclude or transformation.] Steps can perform arbitrary amounts of computation but they are indivisible from the point of view of the construct that contains them.
Steps carry out fundamental XML operations. An XSLT step, for example, performs XSLT processing; a validation step validates one input with respect to some schema, etc.
Language constructs, on the other hand, control and organize the flow of documents through a pipeline, reconstructing familiar programming language functionality such as conditionals, iterators and exception handling. As such, they typically contain components, whose evaluation they control.
[Definition: A construct is a unit of XML processing that contains additional components. That is, a construct differs from a step in that its semantics are at least partially determined by the components that it contains.]
Every construct contains zero or more components. [Definition: The components that occur inside a construct are called contained components.] [Definition: A construct which immediately contains a component is called its container.]
[Definition: The flow graph of components immediately contained within a construct forms a subpipeline.]
Steps and constructs have “ports” into which inputs and outputs are connected. Each component has a number of input ports and a number of output ports, all with unique names. A component can have zero input ports and/or zero output ports. (All components have an implicit standard output port for reporting errors that must not be declared.)
Components have any number of parameters, all with unique names. A component can have zero parameters.
2.2 Inputs and Outputs
Although some kinds of components can read and write non-XML resources, what flows between components as inputs and outputs are exclusively XML documents or sequences of XML documents. Each XML document (or document in a sequence) must be a well formed [XML 1.0] or [XML 1.1] document.
Is support for XML 1.1 optional?
The inputs and outputs can be implemented as sequences of characters, events, or object models, or any other representation the implementation chooses.
It's inconsistent to point to the XML Recommendation on the one hand, and on the other hand to specify that the representation doesn't have to be a sequence of characters. Fix this, probably by referring to the Infoset and describing XML 1.0/1.1 in some other way.
It is a dynamic error if a non-XML resource is produced on a component output or arrives on a component input.
What about the cases where it's impractical to test for this error?
An implementation may make it possible for a component to produce non-XML output—for example, writing a PDF document—but that output cannot flow through the pipeline. Similarly, one can imagine a component that takes no pipeline inputs, reads a non-XML file from a URI, and produces an XML output. But the non-XML file cannot be an input to a component or pipeline.
All of the input ports of a component must be connected to inputs. It is a static error if a component has an input port which is not connected. Unconnected output ports are allowed; any documents produced on those ports are simply discarded.
[Definition: The signature of a component is the set of inputs, outputs, and parameters that it is declared to accept.] Each type of step (e.g. XSLT, XInclude) has a fixed signature, declared globally or built-in, which all its instances share, whereas each instance of a construct has its own signature declared locally.
[Definition: A component matches its signature if and only if it specifies an input for each declared input and it specifies no inputs that are not declared; it specifies no outputs that are not declared; it specifies a parameter for each parameter that is declared to be required; and it specifies no parameters that are not declared.] In other words, every input and required parameter must be specified and only inputs, outputs, and parameters that are declared may be specified. Outputs and optional parameters do not have to be specified.
Each input and output is declared to accept or produce either a single document or a sequence of documents. It is not a static error to connect a port of a component which is declared to produce a sequence of documents to a port that accepts only a single document. It is, however, a dynamic error if the former component actually produces more than a single document at run time.
Steps may also produce error, warning, and informative messages. These messages appear on a special “error output” that is available in the catch clause of a try/catch.
2.3 Parameters
[Definition: A parameter is a QName/value pair.] The value of a parameter must be a string. If a document, node, or other value is given, its (XPath 1.0) string value is computed and that string is used.
2.4 Flow Graph
[Definition: The components contained in a pipeline or other container are the nodes of a flow graph. The input and output ports of the components are connected by arcs in that graph.]
Consider two components in such a graph, “component A” and “component B”.
[Definition: Components A and B are connected if they are either directly or indirectly connected. Component A is directly connected to B if an output of A is associated with an input port of B. Component A is indirectly connected to B if there is a chain of directly connected components that allows traversal from A to B.]
With respect to connected components, we can speak of one component being either before or after another. [Definition: Component A is before component B if component B is a contained component of component A, either directly or indirectly, or if any output from component A is connected to any input of component B, either directly or indirectly.] [Definition: Component A is after component B if component B is the container for component A (or an ancestor of such a container) or if any output from component B is connected to any input of component A, either directly or indirectly.]
It is a static error if a component is either before or after itself. In other words, every flow graph must be acyclic.
3 Language Constructs
This section describes the core language constructs of XProc.
3.1 Pipeline
A pipeline encapsulates the behavior of a subpipeline. It has a number of declared input and output ports and parameters. Viewed from the outside, it is a black box which performs some calculation on the inputs and produces the outputs. From the pipeline author's perspective, the computation performed by the pipeline is described in terms of contained components which read the pipeline's inputs and produce the pipeline's outputs.
For example, a pipeline might accept a document and a stylesheet as input; perform XInclude, validation, and transformation over its inputs; and produce a sequence of formatted documents as its output.
There is one additional constraint imposed on pipelines: a pipeline must not itself be a contained component.
3.2 For-Each
A for-each construct processes a sequence of documents, applying its subpipeline to each document in turn. The for-each construct can be used in cases where a component requires a single document input but a pipeline needs to process a sequence of documents with that component.
The result of the for-each is a sequence of documents produced by processing each individual document in the input sequence. If the subpipeline is connected to one or more output ports on the for-each, what appears on each of those ports is the sequence of documents produced by each iteration of the loop.
For example, a for-each might accept a sequence of DocBook chapters as its input, process each chapter in turn with XSLT, and produce a sequence of formatted chapters as its output.
3.3 Viewport
A viewport construct processes a single document, applying its subpipeline to one or more subsections of the document. The result of the viewport is a copy of the original document with the selected subsections replaced by the results of applying the subpipeline to them.
For example, a viewport might accept an XHTML document as its input, apply encryption to selected div elements within that document, and return an XHTML document that is the same as the original except that each selected div has been replaced by its encrypted result.
3.4 Choose
A choose construct selects exactly one of a list of alternative subpipelines based on the evaluation of XPath expressions.
The list of alternative subpipelines consists of zero or more subpipelines, each guarded by an XPath expression and a context document, followed optionally by a single default subpipeline.
The choose considers each subpipeline in turn and selects the first (and only the first) subpipeline for which the guard expression evaluates to true in the context of its context document. If there are no subpipelines for which the expression evaluates to true, the default subpipeline, if it was specified, is selected.
After a subpipeline is selected, it is evaluated as if only it had been present. The result of the choose is the result of the selected subpipeline.
For example, a choose might test a schema and apply XML Schema validation to an input document if the schema is an XML Schema document, apply RELAX NG validation if the schema is a RELAX NG grammar, or perform no validation otherwise.
In order to ensure that the result of the choose is consistent irrespective of the subpipeline chosen, each subpipeline must declare the same number of outputs with the same names. It is a static error if two subpipeline in a choose declare different outputs.
It is a dynamic error if no subpipeline is selected by the choose and no default is provided.
3.5 Group
A group construct encapsulates the behavior of its subpipeline. It is a convenience wrapper for a collection of components and can be used to perform parameter renaming to aid in reuse of sets of components.
3.6 Try/Catch
A try construct isolates a subpipeline, preventing any errors that arise within it from being exposed to the rest of the pipeline. A try construct begins with two subpipelines: an initial subpipeline and a recovery (or “catch”) subpipeline.
In the context of try/catch, “errors” refers to component failure which is not the same as a static or dynamic error in the pipeline itself. (Though perhaps it will be possible to recover from some dynamic errors.) The notion of component failure as a distinct class of error needs to be described.
It evaluates the initial subpipeline and, if no errors occur, the results of that pipeline are the results of the construct. However, if any errors occur, it abandons the first subpipeline, discarding any output that it might have generated, and evaluates the recovery subpipeline. In this case, the results of the recovery subpipeline are the results of the try construct. If the recovery subpipeline is evaluated and a component within that subpipeline fails, the try fails.
For example, a pipeline might attempt to process a document by dispatching it to some web service. If the web service succeeds, then those results are passed to the rest of the pipeline. However, if the web service cannot be contacted or reports an error, the catch construct can provide some sort of default for the rest of the pipeline.
In order to ensure that the result of the try is consistent irrespective of whether the initial subpipeline provides its output or the recovery subpipeline does, both subpipelines must declare the same number of outputs with the same names. It is a static error if the two subpipelines declare different outputs.
In order to support corrective action in the recovery subpipeline, components inside it have access to all the error output of the components that were in the initial subpipeline on a special port named “#error”.
In evaluating the initial subpipeline, failure of one component can cause other component to fail. In addition, some components that fail might not produce output on their error ports and some components that succeeded might produce such output. This pipeline language places no constraints on the order of error messages provided to the recovery subpipeline, nor does it attempt to guarantee that such output will be available in all cases.
The error documents that appear should conform to Appendix C, The Error Vocabulary.
3.7 Other Steps
A pipeline document may declare additional steps. These can be implementation-defined steps or can be defined through some implementation-dependent extension mechanism. Each declared step must have a name and a signature. It is a static error if a pipeline contains an step that is not recognized by the processor.
4 Syntax
This section describes a set of XML syntactic elements sufficient to represent all the aspects of a pipeline, as set out in the preceding sections.
4.1 Overview
A pipeline is a flow graph of connected components, some of which may themselves contain flow graphs. Elements in a pipeline document represent the flow graphs, using one element for each component and a combination of elements and attributes to specify how the inputs and outputs of each component are connected, and to represent parameter bindings.
Containment is represented naturally using nesting of XML elements.
Elements which represent components all have names, the value of the name attribute. These names are used to establish the bindings between inputs and outputs (e.g. we can speak of “the ‘result’ output port of the component named ‘foo’ being connected to the ‘document’ input port of the component named ‘bar’.”).
4.1.1 Associating Documents with Ports
A document or a sequence of documents can be bound to a port in three ways: by source, by URI, or by providing it “here”, as the content of the element establishing the binding. A document must be specified in exactly one of these ways, otherwise a static error is raised.
- Specified by URI
-
[Definition: A document is specified by URI if it refers to it with a URI.] The href attribute is used for this purpose.
In this example, the input to the Identity step named “otherstep” comes from “http://example.com/input.xml”.
<p:step name="otherstep" type="p:identity"> <p:input port="document" href="http://example.com/input.xml"/> </p:step>
It is a dynamic error if the processor attempts to retrieve the specified URI and fails. (For example, if the resource does not exist or is not accessible with the user's authentication credentials.)
- Specified by source
-
[Definition: A document is specified by source if it refers to a specific port on another component.] The step and source attributes are used for this purpose. (The step attribute may refer to any kind of component, either step or construct, its name notwithstanding.)
There are constraints on what ports can be specified, dependent on context.
When the specification is for an input to a component, the specified port must be
If the specification is for the output of a construct, the specified port must be an output port of some component within that construct.
NoteAlternative 3 above corresponds to a connection between components in two separate subpipelines, for example from a component in the subpipeline of a pipeline itself to a component in the subpipeline of a for-each. This contradicts the definition of subpipeline as a self-contained flow graph in Section 2.1, “Steps, Constructs, and Subpipelines”.
It is the WG's intention to provide for the functionality delivered by such connections, but how this will be accomplished has not yet been decided.
In this example, the “document” input to the XInclude step named “expand” comes from the “result” port of the step named “otherstep”.
<p:step name="expand" type="p:xinclude"> <p:input port="document" step="otherstep" source="result"/> </p:step>
It is a static error if the specified port does not exist.
- Specified by here document
-
[Definition: An document is specified by here document if it is contained in the body of the element that binds it.]
In this example, the “stylesheet” input to the XSLT step named “xform” comes from the content of the p:input element itself.
<p:step name="xform" type="p:xslt"> <p:input port="document" step="expand" source="result"/> <p:input port="stylesheet"> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> ... </xsl:stylesheet> </p:input> </p:step>Here documents are considered “quoted”, they are not interpolated or available to the pipeline processor in any way except as documents flowing through the pipeline.
4.1.2 Scoping of Names
The scope of a port name is the component on which it is defined. The names of all input and output ports on any component must be unique.
The scope of component names is the flow graph of their container and the flow graphs of the constructs therein, recursively.
4.1.3 Extension attributes
[Definition: An element from the XProc namespace may have any attribute not from the XProc namespace, provided that the expanded-QName of the attribute has a non-null namespace URI. These attributes are called extension attributes.] The presence of an extension attribute must not cause the flow graph to differ from the flow graph that any other conformant XProc processor might produce. They must not cause the processor to fail to signal an error that a conformant processor is required to signal. This means that an extension attribute must not change the effect of any XProc element except to the extent that the effect is implementation-defined or implementation-dependent.
A processor which encounters an extension attribute that it does not recognize must behave as if the attribute was not present.
4.1.4 Extension elements
[Definition: Outside the context of a “here document”, any element not in the XProc namespace is an extension element.] The presence of an extension element must not cause the flow graph to differ from the flow graph that any other conformant XProc processor might produce. They must not cause the processor to fail to signal an error that a conformant processor is required to signal. This means that an extension element must not change the effect of any XProc element except to the extent that the effect is implementation-defined or implementation-dependent.
Inside the context of a here document, all content is considered quoted so neither extension elements nor XProc elements are said to occur.
A processor which encounters an extension element that it does not recognize must behave as if neither the element nor its attributes, nor any of its content was present.
4.2 Detailed Vocabulary
This section describes in detail the XML vocabulary that represents a pipeline.
4.2.1 p:pipeline Element
A p:pipeline represents a pipeline. Its children declare the inputs, outputs, and parameters that the pipeline exposes and represent its subpipeline.
<p:pipeline
name? = QName>
(p:declare-input*,
p:declare-output*,
p:declare-parameter*,
p:import*,
p:declare-step*,
subpipeline)
</p:pipeline>
If specified, the name must be unique across all available pipelines. If a p:pipeline occurs as the child of a p:pipeline-library element, it must be named.
A pipeline can declare additional steps (e.g., ones that are provided by a particular implementation or in some implementation-defined way) and import steps from libraries.
<p:pipeline name="buildspec"> <p:declare-input port="document"/> <p:declare-input port="stylesheet"/> <p:declare-output port="result"/> <p:declare-parameter name="validate"/> … </p:pipeline>
4.2.2 p:declare-input Element
A p:declare-input declares an input port.
<p:declare-input
port = QName
sequence? = yes|no />
The port attribute defines the name of the port. It is a static error to define two ports with the same name.
An input declaration can indicate if a sequence of documents is allowed to appear on the declared port. If sequence is specified with the value “yes”, then a sequence is allowed. If the sequence is not specified, or has the value “no”, then it is a dynamic error for a sequence of more than one document to appear on the declared port.
The declaration may be accompanied by a binding (or default binding) for the input. This binding can be accomplished by source:
<p:declare-input
port = QName
step = step name
source = port name
select? = xpath expression
sequence? = yes|no />
<p:declare-input
port = QName
href = URI
select? = xpath expression
sequence? = yes|no />
or by here document:
<p:declare-input
port = QName
select? = xpath expression
sequence? = yes|no>
here document
</p:declare-input>
If a binding is provided, a select expression may also be provided. If provided, the specified XPath select expression is used to filter the document(s) that are read. Each matching node or set of nodes is wrapped in a document and provided to the input port. See Section 4.2.6, “p.input Element”.
4.2.3 p:declare-output Element
A p:declare-output identifies an output port.
<p:declare-output
port = QName
sequence? = yes|no />
The port attribute defines the name of the port. It is a static error to declare two ports with the same name.
An output declaration can indicate if a sequence of documents is allowed to appear on the declared port. If sequence is specified with the value “yes”, then a sequence is allowed. If the sequence is not specified, or has the value “no”, then it is a dynamic error if the component produces a sequence of more than one document on the declared port.
On a construct, the declaration must be accompanied by a binding for the output. This binding can be accomplished by source:
<p:declare-output
port = QName
step = step name
source = port name
sequence? = yes|no />
<p:declare-output
port = QName
href = URI
sequence? = yes|no />
or by here document:
<p:declare-output
port = QName
sequence? = yes|no>
here document
</p:declare-output>
It is a static error if more than one binding is specified.
4.2.4 p:declare-parameter Element
A p:declare-parameter declares a parameter.
<p:declare-parameter
name = token />
Components must declare the parameters that they accept.
The name attribute must be a single asterisk (*), a QName, or a string of the form *:NCName or NCName:*.
A “*” in a declared name functions as a wild card, allowing any parameter with a matching name to be specified.
If name is a QName, then the declaration may include a default value using either content or a select attribute as per p:param.
4.2.5 p:step Element
A p:step represents an step in a pipeline.
<p:step
type = QName
name = QName>
(p:input*,
p:import-param*,
p:param*)
</p:step>
The type attribute identifies the component to be instantiated. It is a static error if the name is not unique in the current scope, if the specified type is not known to the processor, or if the specified inputs, outputs, and parameters do not match the signature for steps of that type.
4.2.6 p.input Element
A p:input identifies input for a component.
Inputs identify their source in exactly one of three ways, by source:
<p:input
port = NCName
step = step name
source = port name
select? = xpath
expression />
<p:input
port = NCName
href = URI
select? = xpath
expression />
or by here document:
<p:input
port = NCName
select? = xpath expression>
here document
</p:input>
It is a static error if more than one of source, uri or here document is specified.
The port attribute identifies the input port of the component that will read from the specified source. It is a static error if the name given does not match the name of an input port for the component or if more than one input is specified for any given port.
The select expression, if specified, applies the specified XPath select expression to the document(s) that are read. Each matching node or set of nodes is wrapped in a document and provided to the input port. In other words,
<p:input port="document" href="http://example.org/input.html"/>
provides a single document, but
<p:input port="document" href="http://example.org/input.html" select="//html:div"/>
provides a sequence of zero or more documents, one for each matching html:div in http://example.org/input.html.
<p:input port="document" step="origin" source="portname" select="//html:div"/>
provides a sequence of zero or more documents, one for each matching html:div in the document (or each of the documents) that is read from the portname port of the component named origin.
4.2.7 p:param Element
A p:param associates a particular value with a parameter.
The value of the parameter can be specified in several ways; as the content of the p:param element:
<p:param
name = QName>
any content
</p:param>
In this case, the (XPath 1.0) string value of the content becomes the value of the parameter.
With a value attribute:
<p:param
name = QName
value = string />
Or as an XPath expression. In this case, the context in which the expression is evaluated must be specified in exactly one of three ways, by source:
<p:param
name = QName
step = step name
source = port name
select? = xpath
expression />
<p:param
name = QName
href = URI
select? = xpath
expression />
or by here document:
<p:param
name = QNName
select? = xpath expression>
here document
</p:param>
The (XPath 1.0) string value of the result of evaluating the expression becomes the value of the parameter.
4.2.8 p:import-param Element
An p:import-param provides a set of in-scope parameters to a component.
<p:import-param
name = token />
All in-scope parameters which match the name are made available to the component as if they had been specified with individual p:param elements.
The name attribute must be a single asterisk (*), a QName, or a string of the form *:NCName or NCName:*.
4.2.9 p:for-each Element
A p:for-each represents a for-each.
<p:for-each
name = NCName>
(p:declare-input,
p:declare-output*,
p:declare-parameter*,
subpipeline)
</p:for-each>
Exactly one input must be declared and it must include a binding for the port it declares. If outputs are declared, they must also include a binding.
The processor will provide each document read through the input binding to the subpipeline represented by the children of the p:for-each, one at a time. For each declared output, the processor will collect all the documents that are produced for that output from all the iterations, in order, into a sequence. The result of the p:for-each is that set of document sequences.
Example 2, “A Sample For-Each” shows an example of a p:for-each in action.
<p:for-each name="chapters">
<p:declare-input port="chap" href="http://example.org/docbook.xml" select="//chapter"/>
<p:declare-output port="html" step="xform-to-html source="result"/>
<p:declare-output port="fo" step="xform-to-fo" source="result"/>
<p:step name="xform-to-fo" type="p:xslt">
<p:input name="document" step="chapters" source="chap"/>
<p:input name="stylesheet" href="fo/docbook.xsl"/>
</p:step>
<p:step name="xform-to-html" type="p:xslt">
<p:input name="document" step="chapters" source="chap"/>
<p:input name="stylesheet" href="html/docbook.xsl"/>
</p:step>
</p:for-each>
The //chapters of the DocBook document are selected. Each chapter is transformed into HTML and XSL FO using an XSLT step. The resulting HTML and FO documents are aggregated together and appear on the html and fo ports, respectively, of the chapters construct itself.
It is a static error if there is not exactly one p:declare-input child of p:for-each or if the declared input does not specify a binding.
It is a static error if any declared output does not specify a binding.
4.2.10 p:viewport Element
A p:viewport represents a viewport.
<p:viewport
name = NCName>
(p:declare-input,
p:declare-output,
p:declare-parameter*,
subpipeline)
</p:viewport>
Exactly one input must be declared and it must include both a binding and a select expression. Exactly one output must be declared and it must include a binding. The processor will provide a document that contains each set of nodes that matches the specified select expression through the input binding to the subpipeline represented by the children of the p:viewport, one at a time. What appears on the output from the p:viewport will be a copy of the input document except that where each matching node or set of nodes appears, the result of applying the subpipeline to those nodes will be output.
It is a dynamic error if the input source is a sequence of more than one document or if the output from any iteration is a sequence of more than one document.
Example 3, “A Sample Viewport” shows an example of a p:viewport in action.
<p:viewport name="encdivs">
<p:declare-input port="div" step="step" source="port" select="//h:div[@class='enc']"/>
<p:declare-output port="html" step="encrypt" source="result"/>
<p:step name="encrypt" type="p:encrypt-document">
<p:input name="document" step="encdivs" source="div"/>
</:step>
</p:viewport>
The //h:div[@class='enc']s of the document are selected. Each selected div is encrypted and the resulting encrypted version replaces the original div. The result of the whole construct is a copy of the input document with each selected div encrypted.
It is a static error if there is not exactly one p:declare-input child and exactly one p:declare-output child of p:viewport or if the declared ports do not specify a binding.
4.2.11 p:choose/p:when/p:otherwise Elements
A p:choose represents a choose.
<p:choose
name = NCName>
(p:when*,
p:otherwise?)
</p:choose>
The p:choose can specify a context in which the XPath expressions that occur on each branch are evaluated. If a context is specified, it must be specified in exactly one of two ways, by source:
<p:choose
name = NCName
step = step name
source = port name>
(p:when*,
p:otherwise?)
</p:choose>
or by URI:
<p:choose
name = NCName
href = URI>
(p:when*,
p:otherwise?)
</p:choose>
Each conditional subpipeline is represented by a p:when element.
<p:when
test = expression>
(p:declare-output*,
p:declare-parameter*,
subpipeline)
</p:when>
The p:when can specify a context in which its XPath expression is to be evaluated. If a context is specified, it must be specified in exactly one of two ways, by source:
<p:when
test = expression
step = step name
source = port name>
(p:declare-output*,
p:declare-parameter*,
subpipeline)
</p:when>
or by URI:
<p:when
test = expression
href = URI>
(p:declare-output*,
p:declare-parameter*,
subpipeline)
</p:when>
If no context is specified on the p:when, the context specified on the p:choose is used. It is a static error if no context is specified in either place.
The p:choose/p:when elements are inconsistent with p:for-each and p:viewport. It would be consistent to allow exactly one p:declare-input to specify the context, instead of specifying the context directly on the p:choose and p:when elements. (Or conversely, to remove the p:declare-input elements from p:for-each and p:viewport.)
Note, in particular, that without the p:declare-input, there's no direct way to specify a here document for the context.
The test attribute provides the guard expression for the subpipeline.
The default branch is represented by a p:otherwise element.
<p:otherwise>
(p:declare-output*,
p:declare-parameter*,
subpipeline)
</p:otherwise>
All of the p:when branches and the p:otherwise must declare the same number of output ports with the same names. It is a static error if they do not.
The result of the p:choose is the result of the selected subpipeline. It is a dynamic error if no p:when is selected and no p:otherwise is specified.
4.2.12 p:group Element
A p:group is a wrapper for a subpipeline.
<p:group
name = NCName>
(p:declare-output*,
p:declare-parameter*,
subpipeline)
</p:group>
The result of a p:group is its declared outputs.
4.2.13 p:try/p:catch Elements
A p:try represents a try/catch.
<p:try
name = NCName>
(p:group,
p:catch)
</p:try>
Where p:group represents the initial subpipeline. The recovery (or “catch”) pipeline is identified with a p:catch element:
<p:catch>
(p:declare-output*,
p:declare-parameter*,
subpipeline)
</p:catch>
Within the p:catch block, the special input port #error is defined. The document(s) on that port constitute the error messages received from the component which failed. Note that the order of the messages on that port is undefined. Note also that the failure of one component can cause others to fail and the component which signaled the error might not be the only or even the first component that failed.
Both the p:group and the p:catch must declare the same number of output ports with the same names. It is a static error if they do not.
4.2.14 p:declare-step Element
A p:declare-step provides the type and signature of an implementation-dependent type of step. It declares the inputs, outputs, and parameters for all steps of that type.
<p:declare-step
type = QName>
(p:declare-input*,
p:declare-output*,
p:declare-parameter*)
</p:declare-step>
We need to make some provision for identifying the implementation of a declared step, even if it's no more than implementation-defined extension attributes. We'll need some sort of mechanism for declaring multiple implementations too.
It is a static error if the type attribute of a p:step is not recognized by the processor. It is not an error to declare such an step, only to use it.
Exactly one input declaration of a p:declare-step may use the name “*” to indicate that the step accepts an arbitrary number of inputs.
4.2.15 p:pipeline-library Element
A p:pipeline-library contains one or more step declarations and/or pipelines. It declares steps that pipelines can import.
<p:pipeline-library>
(p:import*,
p:declare-step*,
p:pipeline*)
</p:pipeline-library>
<p:pipeline-library> <p:declare-step> name="extension-component">…</p:declare-step> <p:pipeline name="xinclude-and-validate">…</p:pipeline> <p:pipeline name="validate-and-transform">…</p:pipeline> … </p:pipeline>
4.2.16 p:import Element
An p:import loads a pipeline or pipeline library, making it available in the current context.
<p:import
href = URI />
An import statement loads the specified URI and makes any pipelines declared within it available to the current pipeline.
It is a dynamic error if the URI cannot be retrieved or if, once retrieved, it does not point to a p:pipeline-library or p:pipeline. If it points to a p:pipeline, it is a dynamic error if the pipeline does not have a name.
5 Errors
Errors in a pipeline can be divided into two classes: static errors and dynamic errors.
5.1 Static Errors
[Definition: A static error is one which can be detected before pipeline evaluation is even attempted.] Examples of static errors include cycles, incorrect specification of inputs and outputs, and reference to unknown components.
Static errors are fatal and must be detected before any components are evaluated.
5.2 Dynamic Errors
A [Definition: A dynamic error is one which occurs while a pipeline is being evaluated.] Examples of dynamic errors include references to URIs that cannot be resolved, components which fail, and pipelines that exhaust the capacity of an implementation (such as memory or disk space).
If a component fails due to a dynamic error, failure propagates upwards until either a try is encountered or the entire pipeline fails. In other words, outside of a try, component failure causes the entire pipeline to fail.
A References
[XML Core Req] XML Processing Model Requirements Dmitry Lenkov, Norman Walsh, editors. W3C Working Group Note 05 April 2004
[Infoset] XML Information Set (Second Edition) John Cowan, Richard Tobin, editors. W3C Working Group Note 04 February 2004.
[XML 1.0] Extensible Markup Language (XML) 1.0 (Fourth Edition) Tim Bray, Jean Paoli, C. M. Sperberg-McQueen, et. al. editors. W3C Recommendation 16 August 2006.
[XML 1.1] Extensible Markup Language (XML) 1.1 (Second Edition) Tim Bray, Jean Paoli, C. M. Sperberg-McQueen, et. al. editors. W3C Recommendation 16 August 2006.
B Glossary
- after
-
Component A is after component B if component B is the container for component A (or an ancestor of such a container) or if any output from component B is connected to any input of component A, either directly or indirectly.
Note: defined but never referenced.
- before
-
Component A is before component B if component B is a contained component of component A, either directly or indirectly, or if any output from component A is connected to any input of component B, either directly or indirectly.
Note: defined but never referenced.
- by source
-
A document is specified by source if it refers to a specific port on another component.
- by URI
-
A document is specified by URI if it refers to it with a URI.
- connected
-
Components A and B are connected if they are either directly or indirectly connected. Component A is directly connected to B if an output of A is associated with an input port of B. Component A is indirectly connected to B if there is a chain of directly connected components that allows traversal from A to B.
- construct
-
A construct is a unit of XML processing that contains additional components. That is, a construct differs from a step in that its semantics are at least partially determined by the components that it contains.
- contained components
-
The components that occur inside a construct are called contained components.
- container
-
A construct which immediately contains a component is called its container.
- dynamic error
-
A dynamic error is one which occurs while a pipeline is being evaluated.
- extension attributes
-
An element from the XProc namespace may have any attribute not from the XProc namespace, provided that the expanded-QName of the attribute has a non-null namespace URI. These attributes are called extension attributes.
Note: defined but never referenced.
- extension element
-
Outside the context of a “here document”, any element not in the XProc namespace is an extension element.
Note: defined but never referenced.
- flow graph
-
The components contained in a pipeline or other container are the nodes of a flow graph. The input and output ports of the components are connected by arcs in that graph.
- here document
-
An document is specified by here document if it is contained in the body of the element that binds it.
- matches
-
A component matches its signature if and only if it specifies an input for each declared input and it specifies no inputs that are not declared; it specifies no outputs that are not declared; it specifies a parameter for each parameter that is declared to be required; and it specifies no parameters that are not declared.
- parameter
-
A parameter is a QName/value pair.
Note: defined but never referenced.
- pipeline
-
A pipeline is an acyclic, directed graph of components connected together by inputs and outputs.
Note: defined but never referenced.
- signature
-
The signature of a component is the set of inputs, outputs, and parameters that it is declared to accept.
- static error
-
A static error is one which can be detected before pipeline evaluation is even attempted.
- step
-
A step is an atomic unit of XML processing, such as XInclude or transformation.
Note: defined but never referenced.
- subpipeline
-
The flow graph of components immediately contained within a construct forms a subpipeline.