2 Overview
This document describes the architecture of the Multimodal
Interaction (MMI) framework [MMIF] and the
interfaces between its constituents. The MMI Working Group is aware
that multimodal interfaces are an area of active research and that
commercial implementations are only beginning to emerge. Therefore
we do not view our goal as standardizing a hypothetical existing
common practice, but rather providing a platform to facilitate
innovation and technical development. Thus the aim of this design
is to provide a general and flexible framework providing
interoperability among modality-specific components from different
vendors - for example, speech recognition from one vendor and
handwriting recognition from another. This framework places very
few restrictions on the individual components or on their
interactions with each other, but instead focuses on providing a
general means for allowing them to communicate with each other,
plus basic infrastructure for application control and platform
services.
Our framework is motivated by several basic design goals:
- Encapsulation. The achitecture should make no assumptions about
the internal implementation of components, which will be treated as
black boxes.
- Distribution. The architecture should support both distributed
and co-hosted implementations.
- Extensibility. The architecture should facilitate the
integration of new modality components. For example, given an
existing implementation with voice and graphics components, it
should be possible to add a new component (for example, a
biomentric security component) without modifying the existing
components.
- Recursiveness. The architecture should allow for nesting, so
that an instance of the framework consisting of several components
can be packaged up to appear as a single component to a
higher-level instance of the architecture.
- Modularity. The architecture should provide for the separation
of data, control, and presentation.
Even though multimodal interfaces are not yet common, the
software industry as a whole has considerable experience with
architectures that can accomplish these goals. Since the 1980s, for
example, distributed message-based systems have been common. They
have been used for a wide range of tasks, including in particular
high-end telephony systems. In this paradigm, the overall system is
divided up into individual components which communicate by sending
messages over the network. Since the messages are the only means of
communication, the internals of components are hidden and the
system may be deployed in a variety of topologies, either
distributed or co-located. One specific instance of this type of
system is the DARPA Hub Architecture, also known as the Galaxy
Communicator Software Infrastructure [Galaxy]. This is a distributed, message-based,
hub-and-spoke infrastructure designed for constructing spoken
dialogue systems. It was developed in the late 1990's and early
2000's under funding from DARPA. This infrastructure includes a
program called the Hub, together with servers which provide
functions such as speech recognition, natural language processing,
and dialogue management. The servers communicate with the Hub and
with each other using key-value structures called frames.
Another recent architecture that is relevant to our concerns is
the model-view-controller (MVC) paradigm. This is a well known
design pattern for user interfaces in object oriented programming
languages, and has been widely used with languages such as Java,
Smalltalk, C, and C++. The design pattern proposes three main
parts: a Data Model that represents the underlying logical
structure of the data and associated integrity constraints, one or
more Views which correspond to the objects that the user
directly interacts with, and a Controller which sits
between the data model and the views. The separation between data
and user interface provides considerable flexibility in how the
data is presented and how the user interacts with that data. While
the MVC paradigm has been traditionally applied to graphical user
interfaces, it lends itself to the broader context of multimodal
interaction where the user is able to use a combination of visual,
aural and tactile modalities.
3 Design versus Run-Time considerations
In discussing the design of MMI systems, it is important to keep
in mind the distinction between the design-time view (i.e., the
markup) and the run-time view (the software that executes the
markup). At the design level, we assume that multimodal
applications will take the form of multiple documents from
different namespaces. In many cases, the different namespaces and
markup languages will correspond to different modalities, but we do
not require this. A single language may cover multiple modalities
and there may be multiple languages for a single modality.
At runtime, the MMI architecture features loosely coupled
software constituents that may be either co-resident on a device or
distributed across a network. In keeping with the loosely-coupled
nature of the architecture, the constituents do not share context
and communicate only by exchanging events. The nature of these
constituents and the APIs between them is discussed in more detail
in Sections 3-5, below. Though nothing in the MMI architecture
requires that there be any particular correspondence between the
design-time and run-time views, in many cases there will be a
specific software component responsible for each different markup
language (namespace).
3.1 Markup and The Design-Time View
At the markup level, an application consists of multiple
documents. A single document may contain markup from different
namespaces if the interaction of those namespaces has been defined
(e.g., as part of the Compound Document Formats Activity [CDF].) By the principle of encapsulation, however, the
internal structure of documents is invisible at the MMI level,
which defines only how the different documents communicate. One
document has a special status, namely the Root or Controller
Document, which contains markup defining the interaction between
the other documents. Such markup is called Interaction Manager
markup. The other documents are called Presentation Documents,
since they contain markup to interact directly with the user. The
Controller Document may consist solely of Interaction Manager
markup (for example a state machine defined in CCXML [ccxml] or SCXML [scxml]) or it may contain
Interaction Manager markup combined with presentation or other
markup. As an example of the latter design, consider a multimodal
application in which a CCXML document provides call control
functionality as well as the flow control for the various
Presentation documents. Similarly, an SCXML flow control document
could contain embedded presentation markup in addition to its
native Interaction Managment markup.
These relationships are recursive, so that any Presentation
Document may serve as the Controller Document for another set of
documents. This nested structure is similar to 'Russian Doll' model
of Modality Components, described below in 3.2 Software Constituents and The Run-Time
View.
The different documents are loosely coupled and co-exist without
interacting directly. Note in particular that there are no shared
variables that could be used to pass information between them.
Instead, all runtime communication is handled by events, as
described below in 6.2 Standard
Life Cycle Events.
Furthermore, it is important to note that the asynchronicity of
the underlying communication mechanism does not impose the
requirement that the markup languages present a purely asynchronous
programming model to the developer. Given the principle of
encapsulation, markup languages are not required to reflect
directly the architecture and APIs defined here. As an example,
consider an implementation containing a Modality Component
providing Text-to-Speech (TTS) functionality. This Component must
communicate with the Runtime Framework via asynchronous events (see
3.2 Software Constituents and The Run-Time
View). In a typical implementation, there would likely be
events to start a TTS play and to report the end of the play, etc.
However, the markup and scripts that were used to author this
system might well offer only a synchronous "play TTS" call, it
being the job of the underlying implementation to convert that
synchronous call into the appropriate sequence of asynchronous
events. In fact, there is no requirement that the TTS resource be
individually accessible at all. It would be quite possible for the
markup to present only a single "play TTS and do speech
recognition" call, which the underlying implementation would
realize as a series of asynchronous events involving multiple
Components.
Existing languages such as XHTML may be used as either the
Controller Documents or as Presentation Documents. Further examples
of potential markup components are given in 5.3 Examples
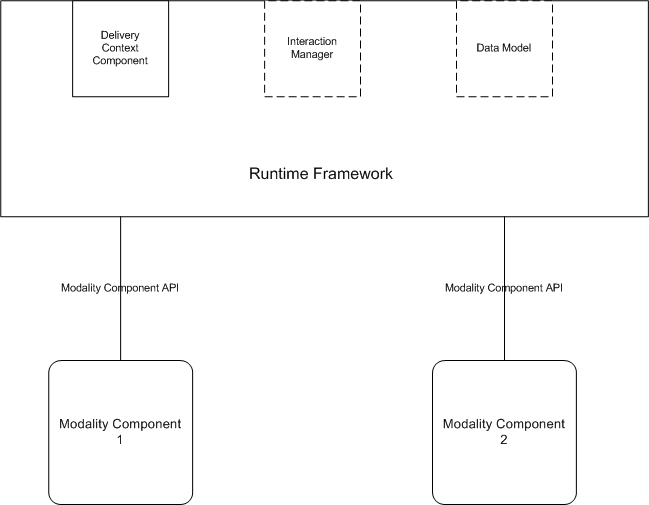
3.2 Software Constituents and The Run-Time View
At the core of the MMI runtime architecture is the distinction
between the Runtime Framework and the Components, which is similar
to the distinction between the Controller Document and the
Presentation Documents. The Runtime Framework interprets the
Controller Document and provides the basic infrastructure which the
various Modality Components plug into. Individual Modality
Components are responsible for specific tasks, particularly
handling input and output in the various modalities, such as
speech, pen, video, etc. Modality Components are black boxes,
required only to implement the Modality Component Interface API
which is described below. This API allows the Modality Components
to communicate with the Framework and hence with each other, since
the Framework is responsible for delivering events/messages among
the Components.
Since the internals of a Component are hidden, it is possible
for a Runtime Framework and a set of Components to present
themselves as a Component to a higher-level Framework. All that is
required is that the Framework implement the Component API. The
result is a "Russian Doll" model in which Components may be nested
inside other Components to an arbitrary depth.
The Runtime Framework is itself divided up into sub-components.
One important sub-component is the Interaction Manager (IM), which
executes the Interaction Manager markup. The IM receives all the
events that the various Modality Components generate. Those events
may be commands or replies to commands, and it is up to the
Interaction Manager to decide what to do with them, i.e., what
events to generate in response to them. In general, the MMI
architecture follows a 'targetless' event model. That is, the
Component that raises an event does not specify its destination.
Rather, it passes it up to the Runtime Framework, which will pass
it to the Interaction Manager. The IM, in turn, decides whether to
forward the event to other Components, or to generate a different
event, etc. The other sub-components of the Runtime Framework are
the Device Context Component, which provides information about
device capabilities and user preferences, and the Data Component,
which stores the Data Model for the application. We do not
currently specify the interfaces for the IM and the Data Component,
so they represent only the logical structure of the functionality
that the Runtime Framework provides. The interface to the Device
Context Component is specified in [DCI].
Because we are using the term 'Component' to refer to a specific
set of entities in our architecture, we will use the term
'Constituent' as a cover term all the elements in our architecture
which might normally be called 'software components'.
3.3 Relationship to Compound Document Formats
The W3C Compound Document Formats Activity [CDF] is also concerned with the execution of user
interfaces written in multiple languages. However, the CDF group
focuses on defining the interactions of specific sets of languages
within a single document, which may be defined by
inclusion or by reference. The MMI architecture, on the other hand,
defines the interaction of arbitrary sets of languages in
multiple documents. From the MMI point of view, mixed
markup documents defined by CDF specifications are treated like any
other documents, and may be either Controller or Presentation
Documents. Finally, note that the tightly coupled languages handled
by CDF will usually share data and scripting contexts, while the
MMI architecture focuses on a looser coupling, without shared
context. The lack of shared context makes it easier to distribute
applications across a network and also places minimal constraints
on the languages in the various documents. As a result, authors
will have the option of building multimodal applications in a wide
variety of languages for a wide variety of deployment scenarios. We
believe that this flexibility is important for the further
development of the industry.
5 The Constituents
This section presents the responsibilities of the various
constituents of the MMI architecture.
5.1 The Runtime Framework
The Runtime Framework is responsible for starting the
application and interpreting the Controller Document. More
specifically, the Runtime Framework must:
- load and initialize the Controller document
- initialize the Component software. If the Component is local,
this will involve loading the corresponding code (library or
executable) and possibly starting a process if the Component is
implemented as a separate process, etc. If the Component is remote,
the Runtime Framework will load a stub and possibly open a
connection to the remote implementation.
- generate the necessary lifecycle events
- handle communication between the Components
- map between the asynchronous Modality Component API and the
potentially synchronous APIs of other components (e.g., the
Delivery Context Interface)
The need for mapping between synchronous and asynchronous APIs
can be seen by considering the case where a Modality Component
wants to query the Delivery Context Interface [DCI]. The DCI API provides synchronous access to
property values whereas the Modality Component API, presented below
in 6.2 Standard Life Cycle
Events, is purely asynchronous and event-based. The
Modality Component will therefore generate an event requesting the
value of a certain property. The DCI cannot handle this event
directly, so the Runtime Framework must catch the event, make the
corresponding function call into the DCI API, and then generate a
response event back to the Modality Component. Note that even
though it is globally the Runtime Framework's responsibility to do
this mapping, most of the Runtime Framework's behavior is
asynchronous. It may therefore make sense to factor out the mapping
into a separate Adapter, allowing the Runtime Framework proper to
have a fully asynchronous architecture. For the moment, we will
leave this as an implementation decision, but we may make the
Adapter a formal part of the architecture at a later date.
The Runtime Framework's main purpose is to provide the
infrastructure, rather than to interact with the user. Thus it
implements the basic event loop, which the Components use to
communicate with one another, but is not expected to handle by
itself any events other than lifecycle events. However, if the
Controller Document markup section of the application provides
presentation markup as well as Interaction Management, the Runtime
Framework will execute it just as the Modality Components do. Note,
however, that the execution of such presentation markup is internal
to the Runtime Framework and need not rely on the Modality
Component API.
5.1.1 The Interaction Manager
The Interaction Manager (IM) is the sub-component of the Runtime
Framework that is responsible for handling all events that the
other Components generate. Normally there will be specific markup
associated with the IM instructing it how to respond to events.
This markup will thus contain a lot of the most basic interaction
logic of an application. Existing languages such as SMIL, CCXML,
SCXML, or ECMAScript can be used for IM markup as an alternative to
defining special-purpose languages aimed specifically at multimodal
applications.
Due to the Russian Doll model, Components may contain their own
Interaction Managers to handle their internal events. However these
Interaction Managers are not visible to the top level Runtime
Framework or Interaction Manager.
If the Interaction Manager does not contain an explicit handler
for an event, any default behavior that has been established for
the event will be respected. If there is no default behavior, the
event will be ignored. (In effect, the Interaction Manager's
default handler for all events is to ignore them.)
5.1.2 The Delivery Context Component
The Delivery Context [DCI] is intended to
provide a platform-abstraction layer enabling dynamic adaptation to
user preferences, environmental conditions, device configuration
and capabilities. It allows Constituents and applications to:
- query for properties and their values
- update (run-time settable) properties
- receive notifications of changes to properties
Note that some device properties, such as screen brightness, are
run-time settable, while others, such as whether there is a screen,
are not. The term 'property' is also used for characteristics that
may be more properly thought of as user preferences, such as
preferred output modality or default speaking volume.
5.1.3 The Data Component
The Data Component is a sub-component of the Runtime Framework
which is responsible for storing application-level data. The
Interaction Manager must be able to access and update the Data
Component as part of its control flow logic, but Modality
Components do not have direct access to it.
5.2 Modality Components
Modality Components, as their name would indicate, are
responsible for controlling the various input and output modalities
on the device. They are therefore responsible for handling all
interaction with the user(s). Their only responsibility is to
implement the interface defined in section 4.1, below. Any further
definition of their responsibilities must be highly domain- and
applicaton-specific. In particular we do not define a set of
standard modalities or the events that they should generate or
handle. Platform providers are allowed to define new Modality
Components and are allowed to place into a single Component
functionality that might logically seem to belong to two different
modalities. Thus a platform could provide a handwriting-and-speech
Modality Component that would accept simultaneous voice and pen
input. Such combined Components permit a much tighter coupling
between the two modalities than the loose interface defined
here.
In most cases, there will be specific markup in the application
corresponding to a given modality, specifying how the interaction
with the user should be carried out. However, we do not require
this and specifically allow for a markup-free modality component
whose behavior is hard-coded into its software.
5.3 Examples
For the sake of concreteness, here are some examples of
components that could be implemented using existing languages. Note
that we are mixing the design-time and run-time views here, since
it is the implementation of the language (the browser) that serves
as the run-time component.
- CCXML could be used as both the Controller Document and the
Interaction Manager language, with the CCXML interpreter serving as
the Runtime Framework and Interaction Manager.
- SCXML [SCXML] could be used as the
Controller Document and Interaction Manager language
- In an integrated multimodal browser, the markup language that
provided the document root tag would define the Controller Document
while the associated scripting language could serve as the
Interaction Manager.
- XHTML could be used as the markup for a Modality
Component.
- VoiceXML could be used as the markup for a Modality
Component.
- SVG could be used as the markup for a Modality Component.
- SMIL could be used as the markup for a Modality Component.
6 Interface between the Runtime Framework
and the Modality Components
The most important interface in this architecture is the one
between the Modality Components and the Runtime Framework. Modality
Components communicate with the Framework and with each other via
asynchronous events. Components must be able to raise events and to
handle events that are delivered to them asynchronously. It is not
required that components use these events internally since the
implementation of a given Component is black box to the rest of the
system. In general, it is expected that Components will raise
events both automatically (i.e., as part of their implementation)
and under mark-up control. The disposition of events is the
responsibility of the Runtime Framework layer. That is, the
Component that raises event does not specify which Component it
should be delivered to. Rather that determination is left up to the
Framework and Interaction Manager.
6.1 Event Delivery Protocol
We do not specify the protocol used to deliver events between
the Modality Components and the Runtime Framework. We do place the
following requirements on it:
- Events may not be lost
- Events must be delivered to the destination in the order in
which the source generated them. There is no guarantee on the
delivery order of events generated by different sources. For
example, if Modality Component M1 generates events E1 and E2 in
that order, while Modality Component M2 generates E3 and then E4,
we require that E1 be delivered to the Runtime Framework before E2
and that E3 be delivered before E4, but there is no guarantee on
the ordering of E1 or E2 versus E3 or E4.
6.2 Standard Life Cycle Events
The Multimodal Architecture defines the following basic
life-cycle events which must be supported by all modality
components. These events allow the Runtime Framework to invoke
modality components and receive results from them. They thus form
the basic interface between the Runtime Framework and the Modality
components. Note that the 'data' event offers extensibilty since it
contains arbitrary XML content and be raised by either the Runtime
Framework or the Modality Components at any time once the context
has been established. For example, an application relying on speech
recognition could use the 'data' event to communicate recognition
results or the fact that speech had started, etc.
The concept of 'context' is basic to these events described
below. A context represents a single extended interaction with one
(or possibly more) users. In a simple unimodal case, a context can
be as simple as a phone call or SSL session. Multimodal cases are
more complex, however, since the various modalities may not be all
used at the same time. For example, in a voice-plus-web
interaction, e.g., web sharing with an associated VoIP call, it
would be possible to terminate the web sharing and continue the
voice call, or to drop the voice call and continue via web chat. In
these cases, a single context persists across various modality
configurations. In general, we intend for 'context' to cover the
longest period of interaction over which it would make sense for
components to store state or information.
6.2.1 NewContextRequest
Optional event that a Modality Component may send to the Runtime
Framework to request that a new context be created. If this event
is sent, the Runtime Framework must respond with the
NewContextResponse event.
6.2.1.1 NewContextRequest Properties
RequestID. An arbitrary identifier generated by
the Modality Component used to identify this request.Media One or more valid media types indicating the
media to be associated with the context.Data Optional semi-colon separated list of data
items. Each item consists of a name followed by a space and an XML
tree value.
6.2.2 NewContextResponse
Sent by the Runtime Framework in response to the
NewContextRequest message.
6.2.2.1 NewContextResponse Properties
RequestID. Matches the RequestID in the
NewContextRequest event.Status An enumeration of Success or Failure. If
the value is Success, the NewContextRequest has been accpeted and a
new context identifier will be included. (See below). If the value
is Failure, no context identifier will be included and further
information will be included in the Errorinfo
field.Context A URI identifying the new context. Empty
if status is Failure.Media One or more valid media types indicating the
media to be associated with the context. Note that these do not
have to be identical to the ones contained in the
NewContextRequest.Errorinfo If status equals Failure,
this field holds further information.Data Optional semi-colon separated list of data
items. Each item consists of a name followed by a space and an XML
tree value.
6.2.3 Prepare
An optional event that the Runtime Framework may send to allow
the Modality Components to pre-load markup and prepare to run.
Modality Components are not required to take any particular action
in reponse to this event, but they must return a PrepareResponse
event. Modality Components that return a PrepareResponse event with
Status of 'Success' should be ready to run with close to 0
delay upon receipt of the Start event.
6.2.3.1 Prepare Properties
Cookie An optional cookie. Note that the Runtime
Framework may send the same cookie to multiple Modality
Components.Context. A unique URI designating this context. It
must be included in all events sent between the Runtime Framework
and Modality Component until the interaction ends. Note that the
Runtime Framework may re-use the same context value in successive
calls to Start if they are all within the same
session/call.ContentURL Optional URL of the content (in this
case, VoiceXML) that the Modality Component should execute.
Includes standard HTTP fetch parameters such as max-age, max-stale,
fetchtimeout, etc. Incompatible with content.Content Optional Inline markup for the Modality
Component to execute. Incompatible with contentURL.
Note that it is legal for both contentURL and
content to be empty. In such a case, the Modality
Component will revert to its default hard-coded behavior, which
could consist of returning an error event or of running a
preconfigured or hard-coded script.Data Optional semi-colon separated list of data
items. Each item consists of a name followed by a space and an XML
tree value.
6.2.4 PrepareResponse
Sent by the Modality Component in response to the Prepare
event.
6.2.4.1 PrepareResponse Properties
Context Must match the value in the
Prepare event.Status Enumeration: Success or Failure.Errorinfo If Status equals Failure,
this field holds further information (examples: NotAuthorized,
BadFormat, MissingURI, MissingField.)DataOptional semi-colon separated list of data
items. Each item consists of a name followed by a space and an XML
tree value.
6.2.5 Start
The Runtime Framework sends this event to invoke a Modality
Component. The Modality Component must return a StartResponse event
in response. If the Runtime Framework has sent a previous Prepare
event, it may leave the contentURL and content fields empty, and
the Modality Component will use the values from the Prepare event.
If the Runtime Framework includes new values for these fields, the
values in the Start event override those in the Prepare event.
6.2.5.1 Start Properties
Context. A unique URI designating this context. It
must be included in all events sent between the Modality Component
and Runtime Framework until the interaction ends. Note that the
Runtime Framework may re-use the same context value in successive
calls to Start if they are all within the same
session/call.ContentURL Optional URL of the content (in this
case, VoiceXML) that the Modality Component should execute.
Includes standard HTTP fetch parameters such as max-age, max-stale,
fetchtimeout, etc. Incompatible with content.Content Optional Inline markup for the Modality
Component to execute. Incompatible with contentURL.
Note that it is legal for both contentURL and
content to be empty. In such a case, the Modality
Component will either use the values provided in the preceeding
Prepare event, if one was sent, or revert to its default hard-coded
behavior, which could consist of returning an error event or of
running a preconfigured or hard-coded script.Cookie An optional cookie.Data Optional semi-colon separated list of data
items. Each item consists of a name followed by a space and an XML
tree value.
6.2.6 StartResponse
The Modality Component must send this event in response to the
Start event.
6.2.6.1 StartResponse Properties
Context Must match the value in the
Start event.Status Enumeration: Success or Failure.Errorinfo If status equals Failure,
this field holds further information (examples: NotAuthorized,
BadFormat, MissingURI, MissingField.)DataOptional semi-colon separated list of data
items. Each item consists of a name followed by a space and an XML
tree value.
6.2.7 Done
Returned by the Modality Component to indicate that it has
reached the end of its processing.
6.2.7.1 Done Properties
Context Must match the value in the
Start event.Status Enumeration: Success or Failure.Errorinfo If status equals Error,
this field holds further information.Data Optional semi-colon separated list of data
items.
6.2.8 Cancel
Sent by the Runtime Framework to stop processing in the Modality
Component. The Modality Component must return CancelResponse.
6.2.8.1 Cancel Properties
Context Must match the value in the
Start event.Immediate Boolean value indicating whether a hard
stop is requested.
6.2.9 CancelResponse
Returned by the Modality Component in response to the Cancel
command.
6.2.9.1 CancelResponse Properties
Context Must match the value in the
Start event.Status Enumeration: Success or Failure.Errorinfo If status equals Error,
this field holds further information.Data Optional semi-colon separated list of data
items.
6.2.10 Pause
Sent by the Runtime Framework to suspend processing by the
Modality Component. Implementations may ignore this command if they
are unable to pause, but they must return PauseResponse.
6.2.10.1 Pause Properties
Context Must match the value in the
Start event.Imediate Boolean value indicating whether a hard
pause is requested.
6.2.11 PauseResponse
Returned by the Modality Component in response to the Pause
command.
6.2.11.1 PauseResponse Properties
Context Must match the value in the
Start event.Status Enumeration: Success or Failure.Errorinfo If status equals Failure,
this field holds further information.Data Optional semi-colon separated list of data
items.
6.2.12 Resume
Sent by the Runtime Framework to resume paused processing by the
Modality Component. Implementations may ignore this command if they
are unable to pause, but they must return ResumeResponse.
6.2.12.1 Resume Properties
Context Must match the value in the
Start event.Data Optional semi-colon separated list of data
items.
6.2.13 ResumeResponse
Returned by the Modality Component in response to the Resume
command.
6.2.13.1 ResumeResponse Properties
Context Must match the value in the
Start event.Status Enumeration: Success or Failure.Errorinfo If status equals Error,
this field holds further information.Data Optional semi-colon separated list of data
items.
6.2.14 Data
This event may be generated by either the Runtime Framework or
the Modality Component and is used to communicate (presumably
changed) data values to the other component.
6.2.14.1 Data Properties
Context Must match the value in the
Start event.Data Optional semi-colon separated list of data
items.
6.2.15 ClearContext
Sent by the Runtime Framework to indicate that the specified
context is no longer active and that any resources associated with
it may be freed. (More specifically, the next time that the Runtime
Framework uses the specified context ID, it should be understood as
referring to a new context.)
6.2.15.1 ClearContext
Properties
Context Must match the value in the
Start event.Data Optional semi-colon separated list of data
items.