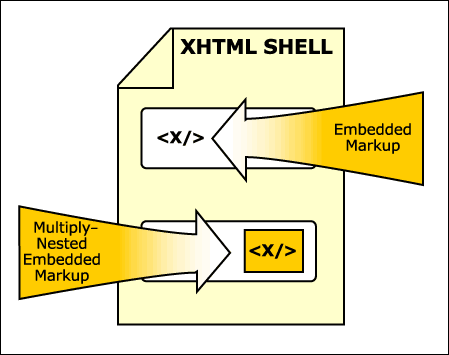
Figure 7.1 A compound document that uses XHTML as its parent document type.
Contents
7.1.
What is a compound document?
7.2.
The need for compound documents
7.3.
Why are compound documents important?
7.4.
Document life-cycle management
7.5.
Expected benefits of compound documents
7.6.
Creating and Using Compound Documents
7.6.1.
The XML family tree
7.6.2.
XHTML as a parent document type
7.6.3.
Using multiple namespaces
7.6.4.
Validity v. well-formedness
7.6.5.
Fragment validation
7.6.6.
Nesting depth of namespaces
7.7.
Current support status
7.7.1.
Browser support
7.7.2.
Editor/Tool support
7.7.3.
Simple examples
7.7.4.
Using XHTML as an XML component grammar
7.8.
Future Work
7.9.
Acknowledgements
This section is informative.
The use of hybrid DTDs to perform structural validation of extended XHTML documents provides a useful way for documents authors and validating web clients to create XML web pages with capabilities not included in the XHTML 1.0 DTDs. However, in the absence of the functionality needed for processing such documents (such as in the case of a non-validating client), how can XHTML be extended? The solution requires that we accept a document authoring mechanism that is non-validating (not necessarily invalid!) but still provides some level of document integrity and sufficient associated information to assure correct rendering of the document.
In the past, HTML was an SGML application, and our discussions regarding its extension were essentially limited to the addition or modification of new elements or attributes to the HTML DTD, or to the deprecation and removal of existing ones. This in many cases occurred in a proprietary way, and often in response to a perceived need in the HTML authoring community for additional page functionality or display capabilities, or to accommodate new web technologies. XML however provides us with a different conceptual scheme for dealing with the rapid pace of technological change on the web. As the acronym implies, XML has built into it the idea of extensibility and adaptation to a rapidly changing document authoring environment, and so allows for new technologies and new perceived needs to be accommodated in a standardized way. Previous chapters of this document described a means of extending XHTML that depends on managing changes to multiple DTDs specific to certain document types, very similar to the SGML-style solutions used in the past to extend HTML. XML also allows for the use of compound documents, which do not require DTDs or their modification. Compound documents may be defined as documents that contain elements or attributes from multiple document types.
In XML, document types are defined in terms of XML Namespaces [XMLNAMES]. These will be described in more detail later, but for now we merely note that our definition above for compound documents can be restated in this way:In XML, compound documents are documents using more than one XML Namespace.
At this point in the development of XML, no sufficiently powerful method has been developed to confirm the structural validity of compound documents. While several steps are being taken in this direction by W3C, a working solution is still in the beginning stages. Because one of the requirements of such a solution is that it must work in the same fashion for all XML documents, the HTML WG alone cannot take on the responsibility for its development. In the interim, the admittedly less-than-perfect but still quite useful solution is to create compound documents using XML Namespaces that are only well formed, but whose structural validity cannot be determined using current means. While these documents cannot be said to strictly conform to the XHTML specification in the absence of any means of testing their validity, document authors will benefit greatly from their use.
Extending XHTML with compound documents provides a solution to the web's extensibility issues that can be used in a non-validating context. This capability is valuable to document authors who want to create pages that make use of several XML -based markup languages in a single document. It is also useful for authors whose intended clients are non-validating, or those who want to create their own elements or component grammars. Another justification for the use of compound documents is in the case of a new and untried technology. The W3C clearly cannot develop a matching specification for each new technological advance on the web, nor would it want to do so. Many of these technologies are untested and some will prove not be useful. In order to determine their usefulness however, a method is needed to be able to easily add the new elements or new grammar to web pages in a standardized way. Of course the associated semantic functionality of the new elements must also be added to the client; how this is done is beyond the scope of this document.
In short, compound documents allow us to quickly and easily extend XML web pages in a standardized way, without any need to resort to modification of DTDs.
There are several motivating factors for using compound documents. Among them are interoperability, scalability, and profiling for both client capabilities and document types. All of these concerns are necessary for effective management of the document life cycle and better workflow:
HTML was designed as a page description language for web pages at a time when the concept of the WWW was rather different than it is now. At the time of its design, developing methods of document management on a large scale, or for mission-critical purposes, was not a goal. Round-trip document management concepts such as revision control, editing, archiving, and media transformation were not part of HTML's design. The astounding growth of the web, both quantitatively in terms of number of users and qualitatively in terms of utility, has created a need for these kinds of extensions to HTML. XML was designed for just this purpose; to provide an extensible way to provide services that HTML did not envision when it was created. HTML is not a document format suitable for storing, authoring or editing documents; its value lies in its ability to define the structure of web pages as they appear on a user's browser. XML will allow us to create 'the right tool for the right job' for these tasks. Advances such as WebDAV [RFC2518], an XML based markup language designed for distributed web page authoring and versioning, is one such example. Compound documents allow us to provide these services, using XML, in a cost-effective and flexible way. By using appropriate tools for authoring, storage, and revision of our documents (as well as document display) we can fulfill XML's promise for the web community, extending the lifetime and value of our XML web pages.
At this point it is reasonable to ask why the HTML WG needs two different methodologies for extending XHTML. The method described earlier in this document, using hybrid DTDs, is useful in many cases, and is compatible with DTD based structural validation. Why then the need for compound documents? The answer is that both compound documents and hybrid DTDs serve a purpose within the HTML authoring community. Design and creation of hybrid DTDs is likely to be limited to a small and finite group of DTDs created and supported by large vendors and organizations. This provides structural validity at the price of limited extensibility. Implementation may also require additional expense for publishers, further raising the bar to entry for authors of web pages. It is also less flexible and adaptable to the swift pace of technological change.
The compound document approach allows for a more flexible, cheaper means of extending HTML, while sacrificing the rigorous error checking of structural validity. New XML document types and extensions can be used by authors without inordinate changes to existing standards and DTDs. Being less formally constrained, it will be easier to incorporate technological advances in our web pages. Authors will not require expensive new tools and training to extend HTML. And since it takes advantage of the natural strengths of XML for extensibility, it is a standardized solution, giving page authors the much needed stability needed for long term web publishing. Compound documents are intended to be an interim solution, useful for some classes of documents and authors, less rigid than formally defined document types using DTDs but more structured and easily automated than today's 'broken' HTML pages.
Overall, the benefits of using compound documents overlap those of hybrid documents to a large degree:
Extending HTML with compound documents requires an understanding of the XML 1.0 specification and XML Namespaces. While authoring compound documents will require more skill and work than documents without extensions, this small amount of additional complexity will repay page authors handsomely in terms of useful extended documents.
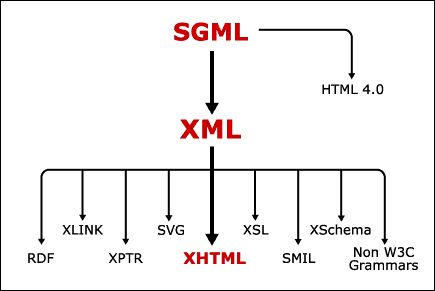
XML, in its simplest definition, is a set of rules for creating new document types. Using XML. s strict formalism, we can construct markup languages designed for a specific purpose, such as creating vector graphics, tracking revisions, and formatting mathematical equations. XML has been conceived by the W3C as a reference platform for the creation of markup languages for specific web needs. These markup languages are often called . XML dialects. or . XML component grammars. . Figure 2 shows the XML family tree, including many XML component grammars that either are currently in development or are already standardized by W3C. Extensibility in XML terms implies that these grammars can be used in XML web pages in a modular fashion, similar to the way software components can be added (or removed) from modern software packages.
Using XML component grammars together in the same web page is what we mean when we refer to "compound documents". These documents clearly defy definition as being one document type or another in the way document types are defined in SGML. XHTML, as the successor markup language to HTML, is expected to be the document type that the majority of users want to extend. It seems quite likely that many more page authors will want to add features from other component grammars to XHTML, rather than vice-versa. This means that XHTML is likely to be the most commonly extended parent document type. The parent document type of a compound document is the document type of the document's root element.
It is, however, perfectly reasonable for authors to want to reverse this process and add XHTML components to their XML documents of other types. XHTML tables or forms might be a good example of a domain-specific set of elements whose functionality can be reused rather than reinvented. The modularization of XHTML should provide for the possibility of using XHTML in compound documents whose parent document is not XHTML.
We can also see that component grammars are not necessarily required to be complete markup languages, but may be a modularized subset of an existing XML based markup language
The XML Namespaces specification is separate from the XML 1.0 specification, having been released after the completion of XML 1.0. The Namespaces specification provides a preliminary method of disambiguating element (and attribute) names in XML documents.
The purpose of XML Namespaces is to provide an adequate scoping mechanism for elements in compound documents. The XML Namespaces methodology requires that a new attribute "xmlns" be added to define a namespace identifier for all document elements. In the case of compound documents, multiple namespace attributes are required. These namespace attributes define a prefix for element and attribute names from that namespace, thereby distinguishing them from elements from other document types. In general, each XML Namespace is specific to a particular document type.
Namespaces can be assigned to any element at any point in the document, but in order to aid document parsing are generally declared on the document's root element. Elements are then prefixed (or 'colonized') with the defined prefix to indicate their parent namespace. A document may have a default namespace, which does not require a prefix.
This example displays the text "Hello World" and then a rectangle 100 pixels on each side, located at 100,100 and colored red.
<?xml version="1.0"?>
<html xmlns="http://www.w3.org/Profiles/xhtml1-strict" xmlns:SVG="http://www.w3.org/Profiles/SVG1">
<head>...</head>
<body>
<p> Hello World!</p>
<SVG:rect x="100" y="100" width="100" height="100" fillcolor="red"/>
</body>
</html>
This document defines xhtml1-strict as its default namespace; elements from this namespace are not prefixed. It also declares an additional namespace for some SVG (scalable vector graphics) [REC-SVG] elements. These elements are prefixed using the XML Namespaces notation. The 'SVG' prefix indicates the namespace in use by the rect element. All elements and attributes from other namespaces must be prefixed to prevent ambiguity.
Note that the value of the xmlns attribute is a URI [RFC2396]. The XML Namespaces specification says that this value must be a valid URI. However, it is not necessarily true that the URI used will actually serve as a locator of an associated resource (like a DTD or profile). The namespace URI, according to the specification, serves only as a unique identifier for that namespace. Accordingly, software may use the namespace URI to disambiguate element and attribute names, but may not depend on traversing the URI in order to obtain further information. Further work on XML Namespaces may make use of the URI properties of namespaces as part of some future validation scheme.
HTML, as an SGML application, inherited a method of defining and checking structural integrity based on the notion of document types. Documents that identified themselves as being of a specific document type could be checked for errors or 'validity' against a DTD or Document Type Definition. Each distinct document type in SGML has its own DTD. Because compound documents are by definition composed of more than one document type, DTDs cannot be utilized to determine their validity. Document types cannot be mixed in SGML, so compound documents cannot be validated. (SGML provides for a 'subdoc' facility similar to compound documents as discussed here that is not in wide use.)
While traditional DTD validation cannot be used with compound documents, issues of structural integrity are still of importance, especially to authors seeking some measure of insurance that their documents will be displayed properly by user agents. XML provides an incremental approach to checking structural integrity, using the concepts of well-formedness and validity to define different stages of document checking, depending on the nature of the needs of the author. Compound documents as defined here are not valid XHTML documents, but are well-formed. This means that at a minimum, elements in compound documents must be nested correctly; conform to proper XML character usage, and properly use attributes. It is worth repeating that compound documents cannot be valid XHTML documents. Authors wanting to extend XHTML at this point in time must chose to either modify the XHTML DTDs as described earlier in this document, or make use of compound documents and XML Namespaces, thereby giving up the ability to determine structural validity using DTDs.
A compound document can be thought of as consisting of a parent document in which one or more XML document fragments are embedded (fig. 7.1). Considered in this fashion, each individual fragment out of which a document is composed might be validated separately, and then the whole composed into the final document. Thus the author could be assured that the different parts of the document each had their own individual structural integrity. This is a complex subject in itself and is the proper responsibility of the XML Fragment Interchange Working Groups [FRAG] and is under discussion in other document areas as well [TC9601] .
Validation using DTDs does not require that each document validated begin with the document's root element. In fact, DTDs do not specify the root elements of documents explicitly; the document's DOCTYPE identifier is intended to be used for this purpose. Fragment validation as described here is essentially conceptual; this is a rather brief and simplistic overview.
The embedding of document fragments of one type into documents of other types leads to the 'nesting problem' for XML documents. It appears clear that without imposed constraints, it is possible for a document of type a to contain a document fragment of type b, which contains a document fragment of type c, which contains...ad infinitum. This presents some difficulty for parsers attempting to process documents as a stream, which is required by XML 1.0 . While no arbitrary nesting depth can be imposed externally, authors are advised that many levels of nesting may increase processing times for their documents.
Software that complies with the XML 1.0 specification and the XML Namespaces specification will support compound documents as described here. Additionally the software must support the particular semantics of the elements (and their attributes) used in a particular compound document. Clearly every software application will not support every possible XML component grammar. In effect, software will provide support for specific XML Namespaces, which can then be used in compound documents reliably. In the case of a document containing elements contained in namespaces not supported by a given piece of software, the software should, in the time-honored fashion of the web, simply ignore the elements that it does not understand.
While software response to elements from an unsupported namespace is certainly implementation specific, a best effort attempt should be made to render the page, so long as it is a well formed XML document.
This line of thought will lead you to the conclusion that there are two kinds of XML elements; those with purely presentational qualities and those with deeper semantic qualities that cannot be specified in a stylesheet. Examples might be the <A> or <IMG> elements, which have semantics whose result for the user is outside the scope a stylesheet (or a DTD). Purely structural/presentational elements are simple to add to a DTD in this fashion; trivial really. but they are essentially just containers for hanging a CSS style rule on. Why have more than one? Deeper semantic modules (such as SVG, or forms) have meaning in the document context that requires the browser to have accompanying functionality. Without this functionality, the document may well validate but won't work; be purely conforming and result in an error.
One major browser manufacturer [MSIE5] currently supports compound documents as described here, essentially in full. Many component grammars are currently under development, in different stages of development, making support for them difficult if not impossible. However in the future it is expected that all popular browser makers will support compound documents in some fashion.
XML tools and editors are currently in the developmental stage. The XML Namespaces specification was only recently approved as a specification, so software vendors are currently working to fully support it. Some of the facilities described here, such as validation of document fragments, are available in existing software. Hopefully XML' s ease of automation and widespread use will encourage software makers to provide further support for XML in their products.
The compound document examples shown here all require the use of supporting software to be viewed properly. With a very limited set of component grammars fully completed, support for them is limited to specific preliminary implementations. Because this draft is a work in progress, and the status of other XML component grammars, these examples will become obsolete quickly, and so should be considered as examples intended to illustrate the concepts of using compound documents rather than examples that are intended to work 'out of the box.'.
(Note that because compound XHTML documents (compound documents with an XHTML root element) are not intended to be 'valid' in the SGML sense of structural validity, it is not useful to include a standard DOCTYPE identifier for the document.)
(SVG stands for Scalable Vector Graphics, an XML component grammar that is still under development by W3C.)
This example would display a pie chart showing quarterly sales by region, along with some appropriate text.
<?xml version="1.0"?>
<html xmlns:HTML="http://www.w3.org/Profiles/xhtml1-strict" xmlns:SVG="http://www.w3.org/Profiles/SVG1">
<HTML:head>...</HTML:head>
<HTML:body>
<HTML:p>The following pie chart displays this quarter's sales in different regions.</HTML:p>
<SVG:g>
<SVG:defs>
<SVG:private xmlns:myapp="http://mycompany/mapapp">
<SVG:myapp:piechart title="Sales by Region">
<SVG:piece label="Northern Region"value="1.23"/>
<SVG:piece label="Eastern Region" value="2.53"/>
<SVG:piece label="Southern Region" value="3.89"/>
<SVG:piece label="Western Region" value="2.04"/>
</SVG:myapp:piechart>
</SVG:private>
</SVG:defs>
</SVG:g>
<HTML:p>As you can see, the company is doing well.<HTML:p>
</HTML:body>
</HTML:html>
In this example, I've explicitly prefixed all the document elements to make clear the compound nature of the document. This web page would display some XHTML text along with a pie chart showing a SVG vector graphic with labels and colored pie sections. (Thanks to the SVG Working Group, from whom this SVG code was borrowed.)
XHTML, being just one of many XML component grammars, may be used by authors in compound documents of a different parent type. This is anticipated in the case where the author wants to add structured text to their documents, or XHTML tables or forms, especially for transmission over the Web. This works no differently than in any other compound document. The modular, component-based design of the XML family of languages provides the ability to 'mix and match' elements from a large variety of XML document types in order to create fully functional web pages.
An example using XHTML elements in a MathML document
TBD
Several W3C Working Groups are tasked with developing parts of a more comprehensive structural validation mechanism for XML. Among these are the XML Syntax Group, under whose purview falls XML Namespaces; the XML Fragment Interchange Working Group [REC-FRAG], which deals with processing of XML fragments outside their document context, and the XML Schema Working Group [XSCHEMA], now considering several proposals for an XML component grammars to replace DTDs as a means of determining structural validity.
The author would like to thank Casey Caston (caseyc@cnet.com) for creating the images used in this chapter.