Abstract
XSPARQL is a query language combining XQuery and SPARQL for transformations between RDF and XML. XSPARQL subsumes XQuery and most of SPARQL (excluding ASK and DESCRIBE). This document defines the XSPARQL language.
Status of this document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications can be found in the W3C technical reports index at http://www.w3.org/TR/.
This document is a part of the XSPARQL Submission which comprises five documents:
- XSPARQL Language Specification (this document)
- XSPARQL: Semantics
- XSPARQL: Implementation
and Test-cases
- XSPARQL: Use cases
- Examples, Test cases and Use cases (ZIP Archive)
By publishing this document, W3C acknowledges that the Submitting Members have made a formal Submission request to W3C for discussion. Publication of this document by W3C indicates no endorsement of its content by W3C, nor that W3C has, is, or will be allocating any resources to the issues addressed by it. This document is not the product of a chartered W3C group, but is published as potential input to the W3C Process.
A W3C Team Comment has been published in conjunction with this Member Submission.
Publication of acknowledged Member Submissions at the W3C site is one of the benefits of W3C Membership. Please consult the requirements associated with Member Submissions of section 3.3 of the W3C Patent Policy. Please consult the complete list of acknowledged W3C Member Submissions.
Table of Contents
1. Introduction
There is a gap within the Web of data: on the one hand, XML provides a popular
format for data exchange with a rapidly increasing amount of semi-structured
data available online. On the other hand, the Semantic Web builds on data
represented in RDF, which is optimized for data interlinking and merging; the
amount of RDF data published on the Web is also increasing. Therefore, the reuse
of XML data in the RDF world and vice versa is becoming increasingly important.
However, with currently available tools and languages, translating between XML
and RDF is not a simple task.
The importance of this issue is currently being acknowledged within the W3C
in several efforts. The Gleaning Resource Descriptions from Dialects of
Languages [GRDDL] (GRDDL) working group faces the issue of
extracting RDF data out of existing (X)HTML Web pages. In the Semantic Web
Services community, RDF-based client software needs to communicate with
XML-based Web services, thus it needs to perform transformations between its
RDF data and the XML messages that are exchanged with the Web services. The
Semantic Annotations for WSDL (SAWSDL) working group calls these
transformations lifting and lowering (see
[SAWSDL]). Both these groups
propose solutions which rely on XSL transformations (XSLT)
[XSLT20] or - more recently - XQuery [XQUERY] for translating
between RDF/XML [RDFXML] and the respective other XML
format at hand. Using XSLT or XQuery for handling RDF data is greatly complicated by
the flexibility of the RDF/XML format. XSLT and XPath [XPATH20] were optimized to
handle XML data with a simple and known hierarchical structure, whereas RDF
is conceptually different, abstracting away from fixed, tree-like structures.
In fact, RDF/XML provides a lot of flexibility in how one and the same RDF graph can be
serialized. Thus, processors that handle RDF/XML as XML data (not as a set of
triples) need to take different possible representations into account when
looking for pieces of data. This is best illustrated by a concrete example:
Figure 1 shows four representations of the same RDF graph using the FOAF
vocabulary (cf. http://www.foaf-project.org).
The first version uses Turtle [TURTLE], a
simple and readable textual syntax for RDF, inaccessible to pure XML
processing tools though; the other three versions are all RDF/XML,
ranging from concise (b) to verbose (d). Apart from the shown formats, yet another representation for RDF within HTML and XHTML documents, namely RDFa [RDFa]
is completing the portfolio of possible representations for RDF.
The three RDF/XML variants in Figure 1 look very different to XML tools, yet exactly the
same to RDF tools. For any variant we could create simple XPath expressions
that extract for instance the names of the persons known to Alice, but a
single expression that would correctly work in all the possible variants
would become more involved. The following particular features of the RDF
data model and RDF/XML syntax complicate XPath+XSLT/XQuery processing:
- Elements denoting properties can directly contain value(s) as nested XML, or reference
other descriptions via the rdf:resource or rdf:nodeID attributes.
- References to resources can be relative or absolute URIs.
-
Container membership may be expressed as rdf:li or
rdf:_1, rdf:_2, etc.
- Statements about the same subject
do not need to be grouped in a
single element.
- String-valued property values such as foaf:name in our example (and also values of rdf:type)
may be represented by XML element content or as attribute values.
- The type of a resource can be represented directly as an XML element name, with an explicit
rdf:type XML element, or even with an rdf:type attribute.
These issues complicate the formulation of adequate XPath expressions that cater for every possible
alternative in how one and the same RDF data might be structured in its
concrete RDF/XML representation.
Apart from that, simple reasoning (e.g., RDFS materialization) improves data
queries when accessing RDF data. For instance, in FOAF, every Person (and
Group and Organization etc.) is also an Agent, therefore we should be able to
select all the instances of foaf:Agent. If we wanted to
write such a query in XPath+XSLT, we literally would need to implement an
RDFS inference engine within XSLT. Given the availability of RDF tools and
engines, this should be avoided, and instead adequate languages for formulating transformations of RDF
independent of its syntactical representation is needed.
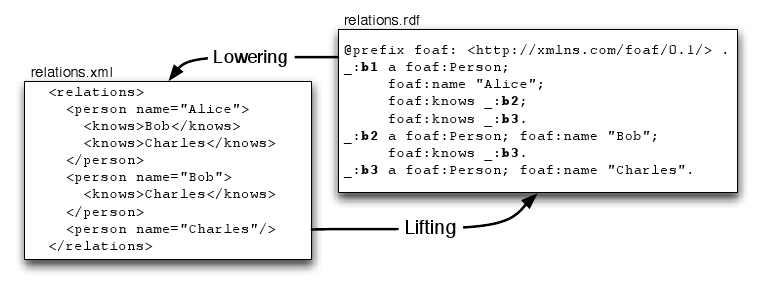
2. Lifting and Lowering
Figure 2 shows a mapping between FOAF data and a
customized XML format. The task here in either direction is to extract for all persons the names of people
they know. For illustration, we use element and
attribute names corresponding to the respective classes and properties
in the FOAF vocabulary (i.e., Person, knows, and
name) in this example. Names in our XML file uniquely
identify a person which actually complicates the transformation from XML to
RDF, since we need to create a unique, distinct blank node per name. The
example data is a slight variant of the data from Figure 1, where
Alice knows both Bob and Charles, Bob knows Charles, and all parties are
identified by blank nodes.
Because semantic data in RDF is on a higher level of abstraction than
semi-structured XML data, the translation from XML to RDF is often
called "lifting" while the opposite direction is called "lowering"
(for instance in the SAWSDL specification
[SAWSDL]) as shown in
Figure 2.
Existing specifications such as GRDDL
[GRDDL] or SAWSDL
[SAWSDL] propose XSLT, XQuery, or combinations
of either of these two languages with SPARQL for performing the
lifting and lowering tasks. For instance Figure 3
shows the lifting task in XQuery and Figure 4 shows the
lowering task in XSLT.
Both these examples generate and consume only one specific RDF/XML
representation shown in Figure 1. If the
consumed RDF data is in a different format, a different transformation
would be needed. Likewise, if the RDF data is to be queried from or
stored into an RDF store, an intermediate transformation into RDF/XML
is undesirable. In contrast to XSLT and XQuery, SPARQL is agnostic of
the concrete RDF representation. Moreover, SPARQL is the standard
format to access RDF stores. However, SPARQL cannot generate or
consume XML. The present specification presents an integrated approach
to combine SPARQL with one of the XML transformation languages -
XQuery - in order to close this gap.
3. Starting Points: XQuery and SPARQL
In order to arrive at a more suitable language for specifying
translations between XML and RDF addressing both the lifting and
lowering use cases outlined above, XSPARQL builds up on two main
starting points: XQuery [XQUERY] and SPARQL [SPARQL].
Whereas the former allows a more convenient and often more concise syntax than XSLT for XML query
processing and XML transformation in general, the latter is the
standard for RDF querying and construction - independent of the syntactic representation of an RDF graph.
As shown in a schematic abstraction of both query languages in Figure 6,
queries in each of the two languages can roughly be divided in two parts: (i) the retrieval part
(body) and (ii) the result construction part
(head). XSPARQL combines these components for both languages
in a unified language, where XQuery's and SPARQL's heads and bodies
may be used interchangeably. Before we go into the details of this
merge, we briefly describe the two constituent languages to the extent necessary for the current specification.
3.1. XQuery
As shown in Figure 6(a) an XQuery starts with a (possibly
empty) prolog (P) for namespace, library, function, and variable
declarations, followed by so called FLWOR - or "flower" -
expressions, denoting body (FLWO) and head (R) of the
query.
As for the body, for clauses (F) can be used to declare variables
looping over the XML nodeset returned by an XPath expression. Alternatively,
to bind the entire result of an XPath query to a variable, let assignments
can be used. The where part (W) defines an XPath condition over the
current variable bindings. Processing order of results of a for can be
specified via a condition in the order by clause (O).
In the head (R) arbitrary well-formed XML is allowed following the
return keyword, where variables scoped in an enclosing for or let as well
as nested XQuery FLWOR expressions are allowed.
Any XPath expression in FLWOR expressions can again possibly involve
variables defined in an enclosing for or let, or even nested XQuery
FLWOR expressions. Together with a large catalogue of built-in
functions [XPATHFUNCT], XQuery
[XQUERY,XQUERYSEMANTICS]
thus offers a flexible instrument for arbitrary transformations.
The lifting task of Figure 2 can
be solved with XQuery as shown in Figure
3. The resulting query is quite involved, but completely addresses
the lifting task, including unique blank node generation for each
person: We first select all nodes containing person names from the
original file for which a blank node needs to be created in
variable $p (line 3). Looping over these nodes, we extract
the actual names from either the value of the name attribute
or from the knows element in variable $n. Finally,
we compute the position in the original XML tree as blank node
identifier in variable $id. The where clause
(lines 12-14) filters out only the last name for duplicate occurrences
of the same name. The nested for (lines 19-31) to
create nested foaf:knows elements again loops over persons,
with the only differences that only those nodes are filtered out (line
25), which are known by the person with the name from the
outer for loop.
While this is a valid solution for lifting, we still observe the following
drawbacks:
(1) We still have to build RDF/XML "manually" and cannot make
use of the more readable and concise Turtle syntax; and
(2) if we had to apply XQuery for the lowering task, we still would
need to cater for all kinds of different RDF/XML representations.
As we will see, both these drawbacks are alleviated by adding some
SPARQL to XQuery.
3.2. SPARQL
Figure 6(b) shows a schematic overview of the building blocks
of SPARQL queries, see [SPARQL] for formal details. Like in XQuery, namespace prefixes
can be specified in the Prolog (P). In analogy to FLWOR expressions in
XQuery, we define so-called DWMC expressions for SPARQL.
The body (DWM) offers the following features. A dataset
(D), i.e., the set of source RDF graphs, can be specified in from or
from named clauses (which are optional since the dataset may be implicitly given).
The where part (W) - unlike in XQuery - allows to
match parts of the dataset by specifying a graph pattern possibly
involving variables. This pattern is given
in a Turtle-based syntax, in the simplest case by a set of triple patterns,
i.e., triples with variables. More involved patterns allow unions of graph
patterns, optional matching of parts of a graph, matching of named graphs,
etc. Matching patterns on the conceptual level of RDF graphs rather than on a
concrete XML syntax alleviates the difficulties of having to deal with different
RDF/XML representations; SPARQL is agnostic to the actual XML representation
of the underlying source graphs. Also the RDF merge of several source graphs
specified in consecutive from clauses, which would involve renaming of blank
node identifiers at the pure XML level, comes for free in SPARQL. Finally, variable
bindings matching the where pattern in the source graphs can be
ordered like in XQuery, but also other solution modifiers (M) such as limit and
offset are allowed to restrict the number of solutions considered in the
result.
In the head, SPARQL's construct clause (C) offers convenient and
XML-independent means to create an output RDF graph. Since XSPARQL
focuses on RDF construction, the ask and select SPARQL query forms are ommitted in
Figure 6(b) for brevity. A construct template consists
of a list of triple patterns in Turtle syntax possibly involving variables that carry over bindings from the
where part. SPARQL can be used as transformation language between different
RDF formats, just like XSLT and XQuery can be used for transforming between XML formats.
A simple example for mapping full names from vCard/RDF
(http://www.w3.org/TR/vcard-rdf) to
foaf:name is given by the SPARQL query
in Figure 5.
Note that SPARQL does not offer the generation of new values in the
head which on the contrary comes for free in XQuery by offering the full
range of XPath/XQuery built-in functions. For instance, the simple query in
Figure 7 which attempts to merge family
names and given names into a single foaf:name is beyond
SPARQL's capabilities.
4. XSPARQL
XSPARQL does not only make reuse of SPARQL for
transformations from and to RDF, but also aims at enhancing SPARQL
itself for RDF-to-RDF transformations enabling queries like the one
in Figure 7. Conceptually, XSPARQL is a
simple merge of SPARQL components into XQuery. In order to benefit
from the more intuitive features of SPARQL in terms of RDF graph
matching for retrieval of RDF data and the use of Turtle-like syntax
for result construction, XSPARQL syntactically just adds these facilities to
XQuery.
Figure 6(c) shows the result of this
combination. First of all, every native XQuery query is also an XSPARQL
query. However we also allow the following modifications, extending
XQuery's FLWOR expressions to so-called FLWOR'
expressions: (i) In the body we allow SPARQL-style F'DWM blocks
alternatively to XQuery's FLWO blocks. The
new F' for clause is very similar to XQuery's
native for clause, but instead of assigning a single
variable to the results of an XPath expression it allows the
assignment of a whitespace separated list of variables
(varlist) to the bindings for these variables obtained by
evaluating the graph pattern of a SPARQL query of the
form: select varlist DWM. (ii) In the
head we allow to create RDF/Turtle directly
using construct statements (C) alternatively to
XQuery's native return (R).
These modifications enable a reformulation of the lifting query
of Figure 3 into the more
concise XSPARQL version of Figure 8.
Figure 9 shows a
lowering query which is unaffected by
the RDF representation in XSPARQL, corresponding to the XSL transformation of Figure 4.
As a shortcut notation, XSPARQL also allows to write "for *" in place of "for
[list of all variables appearing in the where clause]"; this is also
the default value for the F' clause whenever a SPARQL-style where
clause is found and a for clause is missing. By this treatment, XSPARQL is
also a syntactic superset of native SPARQL construct queries, since we
additionally allow the following:
(1) XQuery and SPARQL namespace declarations (P) may be used interchangeably; and
(2) SPARQL-style construct result forms (R) may appear before the retrieval part;
note that we allow this syntactic sugar only for queries consisting of a single FLWOR' expression, with a single construct appearing right after the query prolog, as otherwise, syntactic ambiguities may arise. This feature is mainly added in order to encompass SPARQL style queries, but in principle, we expect the (R) part to appear in the end of a FLWOR' expression.
This way, the queries of Figure 7 are also syntactically valid
for XSPARQL.
Note however, that as opposed to native SPARQL, XSPARQL makes three syntactic restrictions due to consistency with XQuery: Firstly, all keywords (construct, where, from, union, optional, filter, ...) have to be written in lower-case, whereas the native SPARQL grammar is case-insensitive with regards to its keywords. Secondly, variables in XSPARQL are preceded by '$', whereas SPARQL allows alternatively the use of '?'-preceded variables. Thirdly, variable names in XSPARQL are not allowed to contain underscores '_'. These restrictions are explained in more detail below.
4.1. Syntax
The XSPARQL syntax is a small extension of the grammar production
rules in [XQUERY]. To simplify the definition of
XSPARQL, we inherit SPARQL's and XQuery's grammar productions and add
the prime symbol (') to those rules which have been modified. We only
have two new productions: ReturnClause and
SparqlForClause (which loosely reflect lifting and
lowering).
The basic elements of the XSPARQL syntax are the following:
ConstructTemplate' is defined in
the same way as the
production ConstructTemplate
in SPARQL [SPARQL], but we additionally allow XSPARQL nested
FLWORExpr' in subject, verb, and object place. These
expressions need to evaluate to a valid RDF term, i.e.:
- an IRI or blank node in the subject position;
- an IRI in the predicate position;
- a literal, IRI or blank node in the object position.
To define this we use the SPARQL grammar rules as a starting point and
replace the following productions:
The SourceSelector
SPARQL [SPARQL] production is also extended,
allowing the source to be specified by a previously bound XSPARQL
variable. A possible use case for this extension is shown
in Section 2.2 of
[XSPARQLUSECASES].
Without loss of generality, we make two slight restrictions on variable names
in XSPARQL compared with XQuery and SPARQL. Firstly, we disallow variable
names with '_' in it; we need this restriction in XSPARQL
to distinguish new auxiliary variables which we introduce in the semantics
definition and in our rewriting algorithm and avoid ambiguity with
user-defined variables. Secondly, in SPARQL-inherited parts we only allow
variable names prefixed with '$' in order to be compliant with variable
names as allowed in XQuery. Pure SPARQL allows variables of this form, but
additionally allows '?' as a valid variable prefix.
Likewise, we also disallow other identifier names to start with
'_', namely namespace prefixes, function identifiers, and
also blank node identifiers, for similar considerations: In our
normalization we assume fixed namespaces (e.g. we always need the
namespace prefix _sparql_result: associated with the namespace-URI
http://www.w3.org/2005/sparql-results#
which when overridden by the user might create ambiguities. Similarly, we use
underscores in our rewriting to disambiguate blank node identifiers created
from constructs from those extracted from a query result, by appending
'_' to the latter. As for function names, we use
underscores to denote auxiliary functions defined in our rewriting algorithm,
which again we do not want to be overridden by user-defined functions. For further details we refer to [XSPARQLIMPLEMENTATION].
In total, we restrict the SPARQL grammar by redefining
VARNAME to disallow leading underscores:
And likewise in the XQuery grammar we do not allow underscores in the
beginning of NCNames (defined in Namespaces in XML 1.0 (Second Edition)), i.e. we
modify:
Finally, we understand the SPARQL grammar
[SPARQL] and all references to it with all
keywords in lower-case, and being case-sensitive, that is, XSPARQL
does not allow the capitalized versions of SPARQL keywords
(construct, where, from, union, optional, filter,
...). This restriction is made to be in line with XQuery, where all
keywords are lower-case.
Note that XSPARQL allows nesting of FLWOR' expressions within SPARQL
heads (i.e., in SPARQL construct clauses), cf. grammar productions [42a,43a,45a] above, but not in SPARQL
bodies (i.e., in SPARQL where clauses). However, certain
interaction with SPARQL where clauses is allowed. That is,
previously bound variables used within SPARQL where clauses
keep their binding from outside the where clause. This means
a subtle difference between the treatment of unbracketed variables in
XSPARQL construct clauses and where clauses, though,
as illustrated by the following
examples. Figure 10 shows that for
instance for injecting an IRI value into the where clause,
the user needs to ensure that the variable value is properly delimited
by angle brackets as required by Turtle syntax, whereas for injecting
an IRI value into the construct clause
(Figure 11), the special syntax
for iriConstruct has to be used.
The latter will ensure that the constructed output is checked for
validity according to the Turtle syntax.
Note further that any bound variables used within SPARQL style where or construct clauses is supposed to hold a value of type xs:anyAtomicType (cf. Section 1.6 of [XPATHFUNCT]). If this is not the case, it is not a syntax error, but implementations are expected to return a type error err:XPTY0004 (cf. Section Appendix G of [XPATH20]). For further details we refer to [XSPARQLSEMANTICS].2 That means that for instance the query in Figure 12 will only return a result if there is only at maximum one element <a> in the file example.xml.
Comments in XSPARQL queries take the form of '#', outside an IRI, or string expressions and continue to the end of line (marked by characters 0x0D or 0x0A) or end of file if there is no end of line after the comment marker. Comments are treated as white space. Note that XSPARQL in its current version does not support XQuery extension expressions (cf. Section 3.14 of [XQUERY]), since the '(#' and '#)' delimiters for these expressions conflict with SPARQL style comments. Likewise, XQuery style comments (cf. Section 2.6 of [XQUERY]) are not supported, due to possible ambiguities of the '(:' and ':)' delimiters with valid SPARQL filter expressions.
Summarizing, we replace the XQuery grammar rule [151] by an empty production and allow SPARQL style comments outside IRI, or string expressions and secondly we replace production [59] of the XQuery grammar by
1 literalConstruct, iriConstruct, and bnodeConstruct are only allowed in GroupGraphPatterns within a ConstructTemplate'.
2Typing errors by variables which are bound to sequences and used within SPARQL style where or construct clauses are implicit in XSPARQL's semantics, since they are normalized using the fn:concat (cf. [XPATHFUNCT]) function which only accepts arguments of type xs:anyAtomicType.
5. References
-
[GRDDL]
-
Dan Connolly (ed.).
Gleaning Resource Descriptions from Dialects of Languages (GRDDL).
W3C Recommendation, 11 September 2007.
Available at http://www.w3.org/TR/grddl/.
-
[RDFa]
-
Ben Adida,
Mark Birbeck,
Shane McCarron, and
Steven Pemberton (eds.).
RDFa in XHTML: Syntax and Processing, W3C Recommendation, 14 October 2008,
Available at http://www.w3.org/TR/rdfa-syntax/.
-
[RDFXML]
-
Dave Beckett and Brian McBride (eds.)
RDF/XML Syntax Specification (Revised).
W3C Recommendation, W3C, 10 February 2004.
Available at http://www.w3.org/TR/rdf-syntax-grammar/.
-
[SAWSDL]
-
Joel Farrell and Holger Lausen (eds.).
Semantic Annotations for WSDL and XML Schema.
W3C Recommendation, W3C, 28 August 2007.
Available at http://www.w3.org/TR/sawsdl/.
-
[SPARQL]
-
Eric Prud'hommeaux and Andy Seaborne (eds.).
SPARQL Query Language for RDF, 15 January 2008.
W3C Recommendation, available at
http://www.w3.org/TR/rdf-sparql-query/.
-
[TURTLE]
-
David Beckett and Tim Berners-Lee.
Turtle - Terse RDF Triple Language, W3C Team Submission, 14 January 2008,
Available at http://www.w3.org/TeamSubmission/turtle/.
-
[XPATH20]
-
Anders Berglund, Scott Boag, Don Chamberlin, Mary F. Fernández, Michael Kay, Jonathan Robie, and Jérôme Siméon (eds.).
XML Path Language (XPath) 2.0.
W3C Recommendation, 23 January 2007.
Available at
http://www.w3.org/TR/xpath20/.
-
[XPATHFUNCT]
-
Ashok Malhotra, Jim Melton, and Norman Walsh (eds.).
XQuery 1.0 and XPath 2.0 Functions and Operators.
W3C Recommendation, 23 January 2007. Available at
http://www.w3.org/TR/xpath-functions/.
-
[XQUERY]
-
Don Chamberlin, Jonathan Robie, Scott Boag, Mary F. Fernández,
Jérôme Siméon, and Daniela Florescu (eds.).
XQuery 1.0: An XML Query Language.
W3C Recommendation, 23 January 2007.
Available at http://www.w3.org/TR/xquery/.
-
[XQUERYSEMANTICS]
-
Denise Draper, Peter Fankhauser, Mary Fernández, Ashok Malhotra, Kristoffer
Rose, Michael Rys, Jérôme Siméon, and Philip Wadler (eds.).
XQuery 1.0 and XPath 2.0 Formal Semantics.
W3c Recommendation, W3C, 23 January 2007.
Available at
http://www.w3.org/TR/xquery-semantics/.
-
[XSLT20]
-
Michael Kay (ed.).
XSL Transformations (XSLT) Version 2.0.
W3C Recommendation, 23 January 2007. Available at http://www.w3.org/TR/xslt20.
-
[XSPARQLIMPLEMENTATION]
-
XSPARQL: Implementation and Test-cases.
Document included in the present W3C Member Submission.
-
[XSPARQLSEMANTICS]
-
XSPARQL: Semantics.
Document included in the present W3C Member Submission.
-
[XSPARQLUSECASES]
-
XSPARQL: Use cases.
Document included in the present W3C Member Submission.