While the value of structure--i.e. discrimination of (meta)data by
field--to improve the precision of query resolution is undeniable, it is
rarely used effectively in the centralized Web
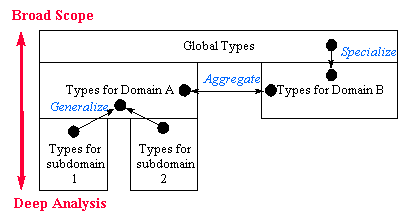
The current Web architecture requires a tradeoff between depth of analysis and breadth of scope. To be used effectively, structural definitions must span the collected resources. Within the scope of a single domain--either topical or administrative--an index can specify and enforce a standard schema for data with rich syntactic and semantic meaning. In the global web, however, autonomy vastly limits the acceptance of any standard. A centralized index is forced to use a "least common representation" for any structure that exists. In practice this means plain text.
We propose a framework for representing shared structure through a hierarchical type system. At the top level, very general document types specify a restricted set of structural elements; e.g. the fields specified in the Dublin core. Restricted domains such as the HPCC Software Reuse Interoperability Groupt (RIG) define domain-specific subtypes of the very general global types. For example, the RIG has a metadata standard called the Basic Interoperability Data Model (BIDM). Subtypes like those in the BIDM inherit the structural definition (i.e. the schema) of their parents and add additional fields. At the lowest levels of the hierarchy, individual users add personal elements to the structured data that is collected.
This approach has several benefits:
My intent for this workshop is to begin the definition of standards that increase the availability and usefulness of structured data. I believe that a common representation for structured schemas like the hierarchical system we prpose is possible and would be highly advantageous.