The Resource Description Framework (RDF) Model&Syntax Specification describes a metadata infrastructure which can accommodate classification elements from different vocabularies i.e. schemas. The underlying model consists of a labeled directed acyclic graph which can be linearized into eXtensible Markup Language (XML) transfer syntax for interchange between applications.
This paper will demonstrate how a new querying language, Metalog, allows users to write simple logic programs that have equally expressive power to Datalog logic programs. A Metalog query itself can also presented as an RDF Schema which allows distributed usage and refinement of Metalog queries through URI addressing on the Web.
The RDF data model also supports higher-order statements using a special reification construct. We will show how higher order modalities can also be expressed in Metalog so that the evaluation of queries can easily be implemented with resolution strategies such as SLD or SLDNF or semi-naive evaluation.
Finally, we present some practical results which demonstrate that our approach is feasible and extensible to more general logic programs in the future.
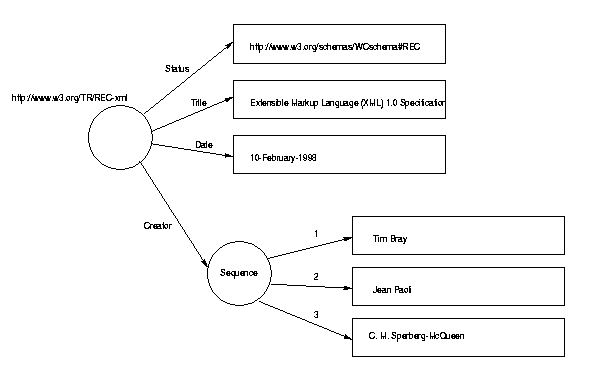
Figure X. An RDF data model
Let's go even one step further. The data model is a labeled directed graph. This can also be represented as predicates which correspond with the arcs of the data model and connect thus two nodes. The example in Figure X corresponds with 25 triples some of which are presented in the following excerpt:
triple("http://www.w3.org/schemas/RDFschema#instanceOf","Authors","http://www.w3.org/schemas/RDFschema#Sequence").
triple("http://www.w3.org/schemas/RDFschema#1","Authors","Tim Bray").
triple("http://www.w3.org/schemas/RDFschema#2","Authors","Jean Paoli").
triple("http://www.w3.org/schemas/RDFschema#3","Authors","C. M. Sperberg-McQueen").
triple("http://www.w3.org/schemas/RDFschema#PropName","genid5","http://purl.org/RDF/DC#Creator").
triple("http://www.w3.org/schemas/RDFschema#PropObj","genid5","http://www.w3.org/TR/REC-xml").
triple("http://www.w3.org/schemas/RDFschema#PropValue","genid5","Authors").
triple("http://www.w3.org/schemas/RDFschema#instanceOf","genid5","http://www.w3.org/schemas/RDFschema#Property").
Figure N. Triple representation of RDF data model
The structure of the triples is as follows:
triple(property,propertyObject,propertyValue).which can also be read as
property(propertyObject,propertyValue).
The example in Figure N. presents us the mechanism how RDF deals with higher order statements. If another property asserts something about another property, the RDF has decided not to allow nesting of triples but a mechanism called reification which provides a unique id for any assertion thus allowing it to be referer to from other triples. This mechanism also sets the recursion limit by not allowing reificated properties to be further reificated.
The following triple corresponds with four triples presented in the following examples:
triple(property,propertyObject,propertyValue).
triple('instanceOf',newID,'Property').
triple('PropName',newID,property).
triple('PropObj',newID,propertyObject).
triple('PropValue',newID,propertyValue).
RDF could have chosen a special syntax but due to the popularity of the XML document encoding syntax, the decision was to build RDF on top of XML. This relieves RDF from some specification work as for example internalization (I18N) which is defined by XML to be based on Unicode.
The following example presents the XML encoding of the data model presented in Figure X.
<?xml version="1.0"?>
<?xml:namespace ns="http://www.w3.org/schemas/RDFschema" prefix="RDF"?>
<?xml:namespace ns="http://www.w3.org/schemas/WCschema" prefix="WC"?>
<?xml:namespace ns="http://purl.org/RDF/DC" prefix="DC"?>
<RDF:RDF>
<RDF:description about="http://www.w3.org/TR/REC-xml">
<WC:Status about="http://www.w3.org/schemas/WCschema#REC"/>
<DC:Title>Extensible Markup Language (XML) 1.0 Specification</DC:Title>
<DC:Date>10-February-1998</DC:Date>
<DC:Creator>
<RDF:Seq ID="Authors">
<RDF:LI>Tim Bray</RDF:LI>
<RDF:LI>Jean Paoli</RDF:LI>
<RDF:LI>C. M. Sperberg-McQueen</RDF:LI>
</RDF:Seq>
</DC:Creator>
<WC:Language>en</WC:Language>
</RDF:description>
</RDF:RDF>
Figure Y. XML encoding of the data model in Figure X.
In general, query languages are formal languages to retrieve data from a database. Standardadized languages already exist to retrieve information from different types of databases such as Structured Query Language (SQL) for relational databases, Object Query Language (OQL) and SQL3 for object databases, and finally logic programs.
...
We feel that the query language we are about to propose and any other to be widely deployed on the Web must address the following requirements:
To address requirement 1, we would like users to use simple syntax with an IF THEN construct as follows:
if B(X) and C(X) then A(X);The grammar for this language is simply (in BNF form):
program ::= procedure+;
procedure ::= IF atoms THEN atoms;
atoms ::= atoms AND atom
| atom
atom ::= ID '(' ID ',' ID ')'
| ID '(' String ',' ID ')'
| ID '(' ID ',' String ')'
| ID '(' String ',' String ')'
To address requirement 2, Metalog builds on definitive logic programs which are defined as follows:
A <- A1 and ... and Am, m >=0.where Ai are positive literals i.e. atoms. Please note that there is a direct mapping of Metalog programs to definite logic programs in this form.
With the metalog syntax we propose, the order in which the predicates in the IF block appear does not matter. Typically, in Prolog evaluation environments the resolution procedure selects predicates starting from left and proceeding to the right. Correspondingly, the order in which the procedures of the logic program are written determines the order in which they are used in the resolutions.
The reason for this is simply that the operational and declarative semantics happen to coincide in metalog. The declarative semantics of metalog programs i.e. the logical deduction taken all procedures gives the same result as any logic program evaluation environment which uses either (semi)naive bottom-up evaluation or top-down evaluation with a specific procedure such as SLD or SLDNF resolution.
The query system should not restrict future work on elaborating the expressivity of the queries. We can already anticipate the introduction of negation and disjunction to the grammar presented in Figure X.
An query evaluation system which has then been developed for an earlier version of the grammar should be able to tell the user that it may not be able to evaluate the query due to the fact that the semantics of the program may not be supported by the query evaluation system. Therefore, we would like to introduce a version tag in the beginning of any Metalog query. [ Is this a good idea? Older version is always more simple semantics than later version. ]
RDF schemas provide as a way to define type systems using the RDF data model. These types allow the authors of RDF entries to use specific properties with corresponding constrained property values with given arity.
We propose that metalog programs must have a corresponding RDF schema representation or extensibility. In this way, an author of a metalog query can point to a specific RDF schema representation of an existing metalog query and refine the query himself.
Metalog allows the use to point to an RDF schema with a namespace
mechanism [wait for a good solid reference] that uses URIs. In this
way, each predicate i.e. propertyName within a metalog query will be
unique.
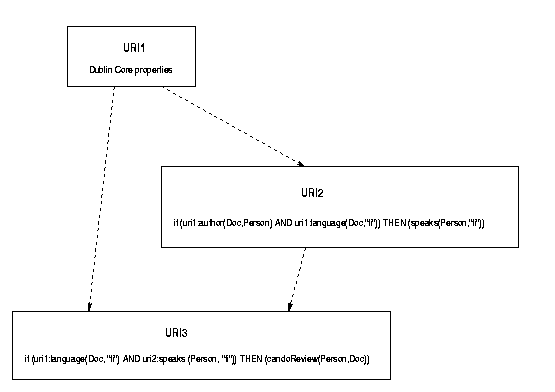
Figure N. Refinement of metalog queries using URI addressing.
[I think we need to say that the following additional procedures have to be introduced to hide the reification mechanism from the query interface level.]
The fact that a property has a certain value may be represented in many ways in the RDF data model. We enumerate them in the following list in increasing order of complexity:
The following default rules define first of all corresponding rules for the previous value cases 1-4 and then rules to determine reification and collection identify with reificated/4 and collection/1 predicates, respectively.
prop(Prop,PropObj,PropValue) :- triple(Prop,PropObj,PropValue),
not(collection(PropObj)),
not(reificated(_,_,_,PropValue)).
prop(Prop,PropObj,PropValue) :- reificated(Prop,PropObj,PropValue,_),
not(collection(PropValue)).
prop(Prop,PropObj,PropValue) :- collection(CollectionObject),
triple(Prop,PropObj,CollectionObject),
triple(_,CollectionObject,PropValue).
prop(Prop,PropObj,PropValue) :- reificated(Prop,PropObj,_,reificatedNode),
collection(CollectionObject),
reificated(Prop,PropObj,CollectionObject,reificatedNode),
triple(_,CollectionObject,PropValue).
reificated(Prop,PropObj,PropValue,GenPropObj) :-
triple('http://www.w3.org/schemas/RDFschema#instanceOf', GenPropObj, 'http://www.w3.org/schemas/RDFschema#Property'),
triple('http://www.w3.org/schemas/RDFschema#PropObj', GenPropObj, PropObj),
triple('http://www.w3.org/schemas/RDFschema#PropName', GenPropObj, Prop),
triple('http://www.w3.org/schemas/RDFschema#PropValue', GenPropObj, PropValue).
collection(Object) :- triple('http://www.w3.org/schemas/RDFschema#instanceOf',Object,'http://www.w3.org/schemas/RDFschema#Bag').
collection(Object) :- triple('http://www.w3.org/schemas/RDFschema#instanceOf',Object,'http://www.w3.org/schemas/RDFschema#Alt').
collection(Object) :- triple('http://www.w3.org/schemas/RDFschema#instanceOf',Object,'http://www.w3.org/schemas/RDFschema#Sequence').
Figure N. Managing reification, collections, and their combination with additional rules.
During the tests we have been using the following setup:
We would like to emphasize the fact that both compilers are easily ported to different platforms from the Solaris 2.6 environment we have been using. The evaluation environment is something we hope people will be able to embed into different applications using different evaluation strategies.
As input data we have been using a set of 2700 RDF data model triples that correspond with the data available at the World Wide Web Consortium technical reports page. This page presents the public documents the consortium has published along with their authors, dates, and URIs. The first example in Figure N is an excerpt of this data.
The queries we wanted to test were of N different types that will be discussed in the following test set-ups.
We start with straight-forward queries using the example described already in Figure N as our case example.
NAMESPACE URI "http://purl.org/schemas/DublinCore/RDF" ALIAS uri1
IF { uri1:Creator(Doc,Person) AND uri1:Language(Doc,Language) }
THEN { Speaks (Person, Language) }
Query 1 - Metalog syntax
prop("Speaks",Person,Language) <-
prop("http://purl.org/RDF/DC#Creator",Doc,Person),
prop("http://purl.org/RDF/DC#Language",Doc,Language).
Query 1 - logic program syntax as produced by Metalog compiler
NAMESPACE URI "http://purl.org/schemas/DublinCore/RDF" ALIAS uri1
NAMESPACE URI "http://www.w3.org/Metadata/RDF/Metalog/query1.rdf" ALIAS uri2
IF { uri1:Language(Doc, Language) AND uri2:Speaks(Person,Language) }
THEN { candoReview(Person,Doc) }
Query 2 - Metalog syntax
prop("candoReview",Person,Doc) <-
prop("http://purl.org/RDF/DC#Language",Doc,Language),
prop("http://www.w3.org/Metadata/RDF/Metalog/query1.rdf#Speaks",Person,Language).
Query 2 - logic program syntax as produced by Metalog compiler
As an example, we study the versioning of different resources using the RDF data model. We expect that documents link always to previous version allowing branching versioning.
We would like to see what are all the previous document of a given document Doc. The query written in Metalog will look like
NAMESPACE URI http://www.w3.org/Metadata/RDF/Metalog/WebCollections.rdf ALIAS uri1
IF { uri1:previousVersion(Doc, Doc2) AND uri1:previousVersion(Doc2, Doc3) }
THEN { previousVersion(Doc,Doc3) }
Query 3 - Metalog syntax for a transitive query
prop("previousVersion",Doc,Doc3) <-
prop("http://www.w3.org/Metadata/RDF/Metalog/WebCollections.rdf#previousVersion",Doc,Doc2),
prop("http://www.w3.org/Metadata/RDF/Metalog/WebCollections.rdf#previousVersion",Doc2,Doc3).
Query 3 - Logic program syntax as produced by Metalog compiler
Now, previousVersion property is defined in two places: one in the RDF schema references through the namespace mechanism and another one in this query (which can again be placed on the Web as RDF schema). If a user wishes to use this specific property, he will have very different results whether he uses the transitive previousVersion or a simple version that only connects two resources together.
The use of Web infrastructure to accommodate logic programs has been suggested by (Sandevall, 1996) and (Loke & Davidson, 1996). The latter approach suggests using familiar logic program notation to place facts and queries on HTML pages. The embedded rules also have the ability to refer to other HTML pages with other predicates using a namespace mechanism. In this way, their evaluation context increases over the amount of HTML pages they retrieve to find facts that satisfy the queries.
The authors would like to thank Bert Bos for his help in running the test sets.