August 1996
The author is the Director of the World Wide Web Consortium and a principal research scientist at the Laboratory for Computer Science, Massachusetts Institute of Technology, 545 Technology Square, Cambridge MA 02139 U.S.A. http://www.w3.org
Draft response to invitation to publish in IEEE Computer special issue of October 1996. The special issue was I think later abandoned.
The World Wide Web was designed originally as an interactive world of shared information through which people could communicate with each other and with machines. Since its inception in 1989 it has grown initially as a medium for the broadcast of read-only material from heavily loaded corporate servers to the mass of Internet connected consumers. Recent commercial interest its use within the organization under the "Intranet" buzzword takes it into the domain of smaller, closed, groups, in which greater trust allows more interaction. In the future we look toward the web becoming a tool for even smaller groups, families, and personal information systems. Other interesting developments would be the increasingly interactive nature of the interface to the user, and the increasing use of machine-readable information with defined semantics allowing more advanced machine processing of global information, including machine-readable signed assertions.
This paper represents the personal views of the author, not those of the World Wide Web Consortium members, nor of host institutes.
This paper gives an overview of the history, the current state, and possible future directions for the World Wide Web. The Web is simply defined as the universe of global network-accessible information. It is an abstract space with which people can interact, and is currently chiefly populated by interlinked pages of text, images and animations, with occasional sounds, three dimensional worlds, and videos. Its existence marks the end of an era of frustrating and debilitating incompatibilities between computer systems. The explosion of advisability and the potential social and economical impact has not passed unnoticed by a much larger community than has previously used computers. The commercial potential in the system has driven a rapid pace of development of new features, making the maintenance of the global interoperability which the Web brought a continuous task for all concerned. At the same time, it highlights a number of research areas whose solutions will become more and more pressing, which we will only be able to mention in passing in this paper. Let us start, though, as promised, with a mention of the original goals of the project, conceived as it was as an answer to the author's personal need, and the perceived needs of the organization and larger communities of scientists and engineers, and the world in general.
The origins of the ideas on hypertext can be traced back to historic work such as Vanevar Bush's famous article "As We May Think" in Atlantic monthly in 1945 in which he proposed the "Memex" machine which would by a process of binary coding, photocells and instant photography, allow microfilms cross-references to be made and automatically followed. It continues with Doug Englebart's "NLS" system which used digital computers and provided hypertext email and documentation sharing, with Ted Nelson's coining of the word "hypertext". For all these visions, the real world in which the technologically rich field of High Energy Physics found itself in 1980 was one of incompatible networks, disk formats, data formats, and character encoding schemes, which made any attempt to transfer information between dislike systems a daunting and generally impractical task. This was particularly frustrating given that to a greater and greater extent computers were being used directly for most information handling, and so almost anything one might want to know was almost certainly recorded magnetically somewhere.
The goal of the Web was to be a shared information space through which people (and machines) could communicate.
The intent was that this space should span from a private information system to a public information, from high value carefully checked and designed material, to off-the-cuff ideas which make sense only to a few people and may never be read again.
The design of the world-wide web was based on a few criteria.
The author's experience had been with a number of proprietary systems, systems designed by physicists, and with his own Enquire program (1980) which allowed random links, and had been personally useful, but had not been usable across a wide area network.
Finally, a goal of the Web was that, if the interaction between person and hypertext could be so intuitive that the machine-readable information space gave an accurate representation of the state of people's thoughts, interactions, and work patterns, then machine analysis could become a very powerful management tool, seeing patters in our work and facilitating our working together through the typical problems which beset the management of large organizations.
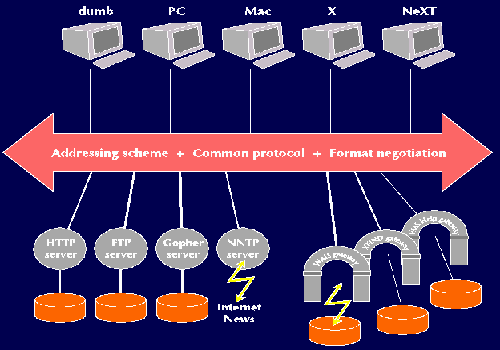
The World Wide Web architecture was proposed in 1989 and is illustrated in the figure. It was designed to meet the criteria above, and according to well-known principles of software design adapted to the network situation.
Fig: Original WWW architecture diagram from 1990. The pink arrow shows the common standards: URL, and HTTP, with format negotiation of the data type.
Flexibility was clearly a key point. Every specification needed to ensure interoperability placed constraints on the implementation and use of the Web. Therefore, as few things should be specified as possible (minimal constraint) and those specifications which had to be made should be made independent (modularity and information hiding). The independence of specifications would allow parts of the design to be replaced while preserving the basic architecture. A test of this ability was to replace them with older specifications, and demonstrate the ability to intermix those with the new. Thus, the old FTP protocol could be intermixed with the new HTTP protocol in the address space, and conventional text documents could be intermixed with new hypertext documents.
It is worth pointing out that this principle of minimal constraint was a major factor in the web's adoption. At any point, people needed to make minor and incremental changes to adopt the web, first as a parallel technology to existing systems, and then as the principle one. The ability to evolve from the past to the present within the general principles of architecture gives some hope that evolution into the future will be equally smooth and incremental.
Hypertext as a concept had been around for a long time. Typically, though, hypertext systems were built around a database of links. This did not scale in the sense of the requirements above. However, it did guarantee that links would be consistent, and links to documents would be removed when documents were removed. The removal of this feature was the principle compromise made in the W3 architecture, which then, by allowing references to be made without consultation with the destination, allowed the scalability which the later growth of the web exploited.
The power of a link in the Web is that it can point to any document (or, more generally, resource) of any kind in the universe of information. This requires a global space of identifiers. These Universal Resource Identifiers are the primary element of Web architecture. The now well-known structure starts with a prefix such as "http:" to indicate into which space the rest of the string points. The URI space is universal in that any new space of any kind which has some kind of identifying, naming or addressing syntax can be mapped into a printable syntax and given a prefix, and can then become part of URI space. The properties of any given URI depend on the properties of the space into which it points. Depending on these properties, some spaces tend to be known as "name" spaces, and some as "address" spaces, but the actual properties of a space depend not only on its definition, syntax and support protocols, but also on the social structure supporting it and defining the allocation and reallocation of identifiers. The web architecture, fortunately, does not depend on the decision as to whether a URI is a name or and address, although the phrase URL (locator) was coined in IETF circles to indicate that most URIs actually in use were considered more like addresses than names. We await the definition of more powerful name spaces, but note that this is not a trivial problem.
An important principle is that URIs are generally treated as opaque strings: client software is not allowed to look inside them and to draw conclusions about the object referenced.
Another interesting feature of URIs is that they can identify objects (such as documents) generically: One URI can be given, for example, for a book, which is available in several languages and several data formats. Another URI could be given for the same book in a specific language, and another URI could be given for a bit stream representing a specific edition of the book in a given language and data format. Thus the concept of "identity" of an Web object allows for genericity, which is unusual in object-oriented systems.
As protocols went for accessing remote data, a standard did exist in the File Transfer Protocol (FTP). However, this was not optimal for the web, in that it was too slow and not sufficiently rich in features, so a new protocol designed to operate with the speed necessary for traversing hypertext links, HyperText Transfer Protocol, was designed. The HTTP URIs are resolved into the addressed document by splitting them into two halves. The first half is applied to the Domain Name Service [ref] to discover a suitable server, and the second half is an opaque string which is handed to that server.
A feature of HTTP is that it allows a client to specify preferences in terms of language and data format. This allows a server to select a suitable specific object when the URI requested was generic. This feature is implemented in various HTTP servers but tends to be underutilized by clients, partly because of the time overhead in transmitting the preferences, and partly because historically generic URIs have been the exception. This feature, known as format negotiation, is one key element of independence between the HTTP specification and the HTML specification.
For the interchange of hypertext, the Hypertext Markup Language was defined as a data format to be transmitted over the write. Given the presumed difficulty of encouraging the world to use a new global information system, HTML was chosen to resemble some SGML-based systems in order to encourage its adoption by the documentation community, among whom SGML was a preferred syntax, and the hypertext community, among whom SGML was the only syntax considered as a possible standard. Though adoption of SGML did allow these communities to accept the Web more easily, SGML turned out to have very complex and not very well defined syntax, and the attempt to find a compromise between full SGML compatibility and ease of use of HTML bedeviled the experts for a long time.
The road from conception to adoption of an idea is often tortuous, and for the Web it certainly had its curves. It was clearly impossible to convince anyone to use the system as it was, having a small audience and content only about itself. Some of the steps were as follows.
An early metric of web growth was the load on the first web server info.cern.ch (originally running on the same machine as the first client, now replaced by www.w3.org). Curiously, this grew as a steady exponential as the graph (on a log scale) shows, at a factor of ten per year, over three years. Thus the growth was clearly an explosion, though one could not put a finger on any particular date as being more significant than others.
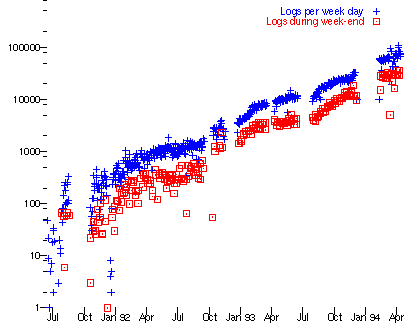
Figure. Web client growth from July 1991 to July 1994. Missing points are lost data. Even the ratio between weekend and weekday growth remained remarkably steady.
That server included suggestions on finding and running clients and servers. It included a page on Etiquette, which included such conventions as the email address "webmaster" as a point of contact for queries about a server, the fact that the URL consisting only of the name of the server should be a default entry point, no matter what the topology of a server's internal links.
This takes development to the point where the general public became aware of it, and the rest is well documented. HTML, which was intended to be the warp and weft of a hypertext tapestry crammed with rich and varied data types, became surprisingly ubiquitous. Rather than relying on the extent of computer availability and Internet connectivity, the Web started to drive it. The URL syntax of the "http:" type became as self-describing to the public as 800 numbers.
Now we summarize the current state of web deployment, and some of the recent developments.
The common standards of URIs, HTTP and HTML have allowed growth of the web, and have also allowed the development resources of companies and universities across the world to be applied to the exploitation and extension of the web. This has resulted in a mass of new data types and protocols.
In the case of new data formats, the ability of HTTP to handle arbitrary data formats has allowed easy expansion, so the introduction, for example, of three dimension scene description language "VRML", or the Java(tm) byte code format for the transfer of mobile program code, has been easy. What has been less easy has been for servers to know what clients have supported, as the format negotiation system has not been widely deployed in clients. This has lead, for example, to the deplorable engineering practice, in the server, of checking the browser make and version against a table kept by the server. This makes it difficult to introduce new clients, and is of course very difficult to maintain. It has lead to the "spoofing" of well-known clients by new less well known ones on order to extract sufficiently rich data from servers. This has been accompanied by an insufficiency in the MIME types used to describe data: text/html is used to refer to many levels of HTML; image/png is used to refer to any PNG format graphic, when it is interesting to know how many colors it encodes; Java(tm) files are shipped around without any visible indication of the runtime support they will require to execute.
Throughout the industry, from 1992 on, there was a strong worry that a fragmentation of the Web standards would eventually destroy the universe of information upon which so many developments, technical and commercial, were being built. This lead to the formation in 1994 of the World Wide Web Consortium. At the time of writing, the Consortium has around 150 members including all the major developers of Web technology, and many others whose businesses are increasingly based on the ubiquity and functionality of the Web. Based at the Massachusetts Institute of Technology in the USA and at the Institute Nationale pour la Récherche en Informatique et Automatique in Europe, the Consortium provides a vendor-neutral forum where competing companies can meet to agree on common specifications for the common good. The Consortium's mission, taken broadly, is to realize the full potential of the Web, and the directions in which this is interpreted are described later on.
Of the developments to web protocols are driven sometimes by technical needs of the infrastructure, such as those of efficient caching, sometimes by particular applications, and sometimes by the connection between the Web and the society which can be built around it. Sometimes these become interleaved. An example of the latter was the need to address worries of parents, schools, and governments that young children would gain access to material which though indecency, violence or other reason, was judged harmful to them. Under threat of government restrictions of internet use, or worse, government censorship, the community reacted rapidly in the form of W3C's Platform for Internet Content Selection (PICS) initiative. PICS introduces new protocol elements and data formats to the web architecture, and is interesting in that the principles involved may apply to future developments.
Essentially, PICS allows parents to set up filters for their children's information intake, where the filters can refer to the parent's choice of independent rating services. Philosophically, this allows parents (rather than centralized government) to define what is too "indecent" for their children. It is, like the Internet and the Web, a decentralized solution.
Technically, PICS involves a specification for a machine readable "label". Unlike HTML, PICS labels are designed to be read by machine, by the filter software. They are sets of attribute-value pairs, and are self-describing in that any label carries a URL which, when dereferenced, provides both machine-readable and human-readable explanations of the semantics of the attributes and their possible values.
Figure: The RSAC-i rating scheme. An example of a PICS scheme.
PICS labels may be obtained in a number of ways. They may be transported on CD-ROM, or they may be sent by a server along with labeled data. (PICS labels may be digitally signed, so that their authenticity can be verified independently of their method of delivery). They may also be obtained in real time from a third party. This required a specification for a protocol for a party A to ask a party B for any labels which refer to information originated by party C.
Clearly, this technology, which is expected soon to be well deployed under pressure about communications decency, is easily applied to many other uses. The label querying protocol is the same as an annotation retrieval protocol. Once deployed, it will allow label servers to present annotations as well as normal PICS labels. PICS labels may of course be used for many different things. Material will be able to be rated for quality for adult or scholarly use, forming "Seals of Approval" and allowing individuals to select their reading, buying, etc, wisely.
If the world works by the exchange of information and money, the web allows the exchange of information, and so the interchange of money is a natural next step. In fact, exchanging cash in the sense of unforgeable tokens is impossible digitally, but many schemes which cryptographically or otherwise provide assurances of promises to pay allow check book, credit card, and a host of new forms of payment scheme to be implemented. This article does not have space for a discussion of these schemes, nor of the various ways proposed to implement security on the web. The ability of cryptography to ensure confidentiality, authentication, non-repudiation, and message integrity is not new. The current situation is that a number of proposals exist for specific protocols for security, and for payment a fairly large and growing number of protocols and research ideas are around. One protocol, Netscape's "Secure Socket Layer", which gives confidentiality of a session, is well deployed. For the sake of progress, the W3 Consortium is working on protocols to negotiate the security and payment protocols which will be used.
To date, the principle machine analysis of material on the web has been its textual indexing by search engines. Search engines have proven remarkably useful, in that large indexes can be searched very rapidly, and obscure documents found. They have proved to be remarkably useless, in that their searches generally take only vocabulary of documents into account, and have little or no concept of document quality, and so produce a lot of junk. Below we discuss how adding documents with defined semantics to the web should enable much more powerful tools.
Some promising new ideas involve analysis not only of the web, but of people's interaction with it, to automatically reap more idea of quality and relevance. Some of these programs, sophisticated search tools, have been described as "agents" (because they act on behalf of the user), though the term is normally used for programs that are actually mobile. There is currently little generally deployed use of mobile agents. Mobile code is used to create interesting human interfaces for data (such as Java "applets"), and to bootstrap the user into a new distributed applications. Potentially, mobile code has a much greater impact on the software architecture of software on client and server machines. However, without a web of trust to allow mobile programs (or indeed fixed web-searching programs) to act on a use's behalf, progress will be very limited.
Having summarized the origins of the Web, and its current state, we now look at some possible directions in which developments could take it in the coming years. One can separate these into three long term goals. The first involves the improvement of the infrastructure, to provide a more functional, robust, efficient and available service. The second is to enhance the web as a means of communication and interaction between people. The third is to allow the web, apart form being a space browseable by humans, to contain rich data in a form understandable by machines, thus allowing machines to take a stronger part in analyzing the web, and solving problems for us.
When the web was designed, the fact that anyone could start a server, and it could run happily on the Internet without regard to registration with any central authority or with the number of other HTTP servers which others might be running was seen as a key property, which enabled it to "scale". Today, such scaling is not enough. The numbers of clients is so great that the need is for a server to be able to operate more or less independently of the number of clients. The are cases when the readership of documents is so great that the load on severs becomes quite unacceptable.
Further, for the web to be a useful mirror of real life, it must be possible for the emphasis on various documents to change rapidly and dramatically. If a popular newscast refers by chance to the work of a particular schoolchild on the web, the school cannot be expected to have the resources to serve copies of it to all the suddenly interested parties.
Another cause for evolution is the fact that business is now relying on the Web to the extend that outages of servers or network are not considered acceptable. An architecture is required allowing fault tolerance. Both these needs are addressed by the automatic, and sometimes preemptive, replication of data. At the same time, one would not wish to see an exacerbation of the situation suffered by Usenet News administrators who have to manually configure the disk and caching times for different classes of data. One would prefer an adaptive system which would configure itself so as to best use the resources available to the various communities to optimize the quality of service perceived. This is not a simple problem. It includes the problems of
Resolution of these problems must occur within a context in which different areas of the infrastructure are funded through different bodies with different priorities and policies.
These are some of the long term concerns about the infrastructure, the basic architecture of the web. In the shorter term, protocol designers are increasing the efficiency of HTTP communication, particularly for the case of a user whose performance limiting item is a telephone modem.
In the short term, work at W3C and elsewhere on improving the web as a communications medium has mainly centered around the data formats for various displayable document types: continued extensions to HTML, the new Portable Network Graphics (PNG) specification, the Virtual Reality Markup Language (VRML), etc. Presumably this will continue, and though HTML will be considered part of the established infrastructure (rather than an exciting new toy), there will always be new formats coming along, and it may be that a more powerful and perhaps a more consistent set of formats will eventually displace HTML. In the longer term, there are other changes to the Web which will be necessary for its potential for human communication to be realized.
We have seen that the Web initially was designed to be a space within which people could work on an expression of their shared knowledge. This was seen as being a powerful tool, in that
The intention was that the Web should be used as a personal information system, as a group tool at all scales from the team of two, to the world population deciding on ecological issues. An essential power of the system, as mentioned above, was the ability to move and link information between these layers, bringing the links between them into clear focus, and helping maintain consistency when the layers are blurred.
At the time of writing, the most famous aspect of the web is the corporate site which addresses the general consumer population. Increasingly, the power of the web within an organization is being appreciated, under the buzzword of the "Intranet". It is of course by definition difficult to estimate the amount of material on private parts of the web. However, when there were only a few hundred public servers in existence, one large computer company had over a hundred internal servers. Although to set up a private server needs some attention to access control, once it is done its use is accelerated by the fact that the participants share a level of trust, by being already part of a company of group. This encourages information sharing at a more spontaneous and direct level than the publication rituals of passage appropriate for public material.
A recent workshop shed light on a number of areas in which the Web protocols could be improved to aid collaborative use:
among others.
At the microcosmic end of the scale, the web should be naturally usable as a personal information system. Indeed, it will not be natural to use the Web until global data and personal data are handled in a consistent way. From the human interface point of view, this means that the basic computer interface which typically uses a "desktop" metaphor must be integrated with hypertext. It is not as though there are many big differences: file systems have links ("aliases", "shortcuts") just like web documents. Useful information management objects such as folders and nested lists will need to be transferable in standard ways to exist on the web. The author also feels that the importance of the filename in computer systems will decrease until the ubiquitous filename dialog box disappears. What is important about information can best be stated in its title and the links which exist in various forms, such as enclosure of a file within a folder, appearance of an email address in a "To:" field of a message, the relationship of a document to its author, etc. These semantically rich assertions make sense to a person. If the user specifies essential information such as the availability and reliability levels required of access to a document, and the domain of visibility of a document, then that leaves the system to manage the niceties of disk space in such a way as to give the required quality of service.
The end result, one would hope, will be a consistent and intuitive universe of information, some part of which what one sees whenever one sees a computer screen, whether it be a pocket screen, a living room screen, or an auditorium screen.
As mentioned above, an early but long term goal of the web development was that, if the web came to accurately reflect the knowledge and interworkings of teams of people, that machine analysis would become a tool enabling us to analysis the ways in which we interact, and facilitating our working together. With the growth of commercial applications of the web, this extends to the ideal of allowing computers to facilitate business, acting as agents with power to act financially.
The first significant change required for this to happen is that data on the web which is potentially useful to such a program must be available in a machine-readable form with defined semantics. This could be done along the lines of the Electronic Document Interchange (EDI) [ref], in which a number of forms such as offers for sale, bills of sale, title deeds, and invoices are devised as digital equivalents of the paper documents. In this case, the semantics of each form is defined by a human readable specification document. Alternatively, general purpose languages could be defined in which assertions could be made, within which axiomatic concepts could be defined from time to time in human readable documents. In this case, the power of the language to combine concepts originating from different areas could lead to a very much more powerful system on which one could base machine reasoning systems. Knowledge Representation (KR) languages are something which, while interesting academically, have not had a wide impact on applications of computer. But then, the same was true of hypertext before the Web gave it global scope.
There is a bi-directional connection between developments in machine processing of global data and in cryptographic security. For machine reasoning over a global domain to be effective, machines must be able to verify the authenticity of assertions found on the web: this requires a global security infrastructure allowing signed documents. Similarly, a global security infrastructure seems to need the ability to include, in the information about cryptographic keys and trust, the manipulation of fairly complex assertions. It is perhaps the chicken-and-egg interdependence which has, along with government restrictions on the use of cryptography, delayed the deployment of either kind of system to date.
The PICS system may be a first step in this direction, as its labels are machine readable.
At the first International World Wide Web Conference in Geneva in May 1994, the author made a closing comment that, rather than being a purely academic or technical field, the engineers would find that many ethical and social issues were being addressed by the kinds of protocol they designed, and so that they should not consider those issues to be somebody else's problem. In the short time since then, such issues have appeared with increasing frequency. The PICS initiative showed that the form of network protocols can affect the form of a society which one builds within the information space.
Now we have concerns over privacy. Is the right to a really private conversation one which we enjoy only in the middle of a large open space, or should we give it to individuals connected across the network? Concepts of intellectual property, central to our culture, are not expressed in a way which maps onto the abstract information space. In an information space, we can consider the authorship of materials, and their perception; but we have seen above how there is a need for the underlying infrastructure to be able to make copies of data simply for reasons of efficiency and reliability. The concept of "copyright" as expressed in terms of copies made makes little sense. Furthermore, once those copies have been made, automatically by the system, this gives the possibility them being seized, and a conversation considered private being later exposed. Indeed, it is difficult to list all the ways in which privacy can be compromised, as operations which were previously manual can be done in bulk extremely easily. How can content providers get feedback out the demographic make-up of those browsing their material, without compromising individual privacy? Though boring in small quantities, the questions individuals ask of search engines, in bulk, could be compromising information.
In the long term, there are questions as to what will happen to our cultures when geography becomes weakened as a diversifying force? Will the net lead to a monolithic (American) culture, or will it foster even more disparate interest groups than exist today? Will it enable a true democracy by informing the voting public of the realities behind state decisions, or in practice will it harbor ghettos of bigotry where emotional intensity rather than truth gains the readership? It is for us to decide, but it is not trivial to assess the impact of simple engineering decisions on the answers to such questions.
The Web, like the Internet, is designed so as to create the desired "end to end" effect, whilst hiding to as large an extent as possible the intermediate machinery which makes it work. If the law of the land can respect this, and be couched in an "end to end" terms, such that no government or other interference in the mechanisms is legal that would break the end to end rules, then it can continue in that way. If not, engineers will have to learn the art of designing systems so that the end to end functionality is guaranteed whatever happens in between. What TCP did for reliable delivery (providing it end-to-end when the underlying network itself did not provide it) , cryptography is doing for confidentiality. Further protocols may do this for information ownership, payment, and other facets of interaction which are currently bound by geography. For the information space to be a powerful place in which to solve the problems of the next generations, its integrity, including its independence of hardware, packet route, operating system, and application software brand, is essential. Its properties must be consistent, reliable, and fair, and the laws of our countries will have to work hand in hand with the specifications of network protocols to make that so.
Space is insufficient for a bibliography for a field involving so much work by so many. The World Wide Web has a dedicated series of conferences run by an independent committee. For papers on advances and proposals on Web related topics, the reader is directed to past and future conferences. The proceedings of the last two conferences to date are as below.
Proceedings of the Fourth International World Wide Web Conference (Boston 1995), The World Wide Web Journal, Vol. 1, Iss. 1, O'Reilly, Nov. 1995. ISSN 1085-2301, ISBN: 1-56592-169-0. [[Later issues may also be of interest.]
Proceedings of the Fifth Internatonal World Wide Web Conference, Computer Networks and ISDN systems, Vol 28 Nos 7-11, Elsevier, May 1996.
Also refered to in the text:
[1] Bush, Vannevar, "As We May Think", Atlantic Monthly, July 1945. (Reprinted also in the following:)
[2] Nelson, Theodore, Literary Machines 90.1, Mindful Press, 1990
[3] Englebart, Douglas, Boosting Our Collective IQ - Selected Readings, Boostrap Institute/BLT Press, 1995, <AUGMENT,133150,>, ISBN:1-895936-01-2
[5] On Gopher, See F. Anklesaria, M. McCahill, P. Lindner, D. Johnson, D. John, D. Torrey, B. Alberti, "The Internet Gopher Protocol (a distributed document search and retrieval protocol)", RFC 1436 03/18/1993. , http://ds.internic.net/rfc/rfc1436.txt
[6] On EDI, See http://polaris.disa.org/edi/edihome.htp