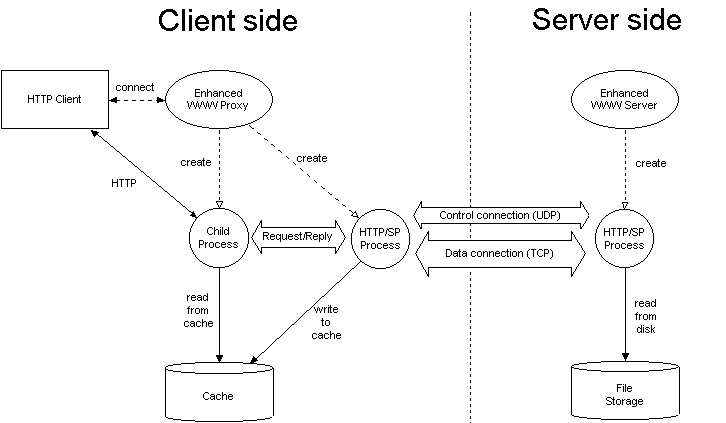
Figure A: Overview of the HTTP/SP System
Although this paper is based on work done in the EC/ACTS-project DOLMEN (Service Machine Development for an Open Long-term Mobile and Fixed Network Environment; ACTS Ref AC036), the paper presents the authors' view and not the view of the DOLMEN project.
This paper describes how a Distributed Processing Environment (DPE) layer is used in the DOLMEN First Year Trial (configuration layout) to be carried out in May 1996. As the DPE we use the freely available Inter-Language Unification (ILU) system (version 2.0alpha). ILU provides high-level interfaces and access transparency between the Enhanced WWW Proxy and Enhanced WWW Server. The interfaces will be defined using ILU's Interface Specification Language (ISL).
Although ILU is far from a full-fledged CORBA implementation, the latest version also supports OMG's IDL and the CORBA Internet Inter-Orb Protocol (IIOP). Unfortunately, these features turned out to be still unstable (at least in the Linux-version) and could not be used. However, ILU's ISL seems similar enough to OMG's IDL so that the transition from ILU to CORBA is expected to be quite easy.
Since ILU does not yet provide a binding service, such as an ORB, bindings between objects in our implementation need to be separately configured. Currently we have only implemented static bindings through a configuration file. However, dynamic binding could be implemented using the hooks available in ILU that allow the use of an external binding service.
In order to demonstrate the separation between kernel transport network and data network, control and data communication will be done in different ways. We use an ILU interface (on the top of UDP/IP) in the control interface. In data connections we use TCP/IP streams. [Actually we tried to use an ILU interface on the top of TCP/IP. At least in the Linux version the asynchronous RPC is implemented in a way that has anomalous features which make it useless for a bulk data stream.] The control interface is used to set up a connection between two communicating HTTP/SP protocol modules. The data stream is then used to transfer document objects between the modules.
Figure A illustrates the basic operation of the HTTP/SP protocol module. The Enhanced WWW Proxy creates a new child process to handle each request received from a client. If the requested document is in the cache and sufficiently new, the child process responds immediately. Otherwise, it checks the bindings defined in the proxy's configuration file to decide whether it should use HTTP or HTTP/SP. If the server is not in the list of Enhanced WWW Servers, the child process enters compatibility mode and retrieves the document using HTTP. If the servers is in the list, the child process initialises its ILU client interface and forwards the request to the HTTP/SP process. The HTTP/SP process then fetches the document as described below.
Figure A: Overview of the HTTP/SP System
Figure B illustrates the HTTP/SP connection setup. When the HTTP/SP protocol module finds that it needs to communicate with a new HTTP/SP server, it calls the server's control interface to negotiate a new data connection (1). If the server agrees (2), a new data connection is established (3). Documents are then transferred over the data connection (4,5). Finally, when the data connection between the proxy and server has been idle long enough, it will be automatically disconnected (6).
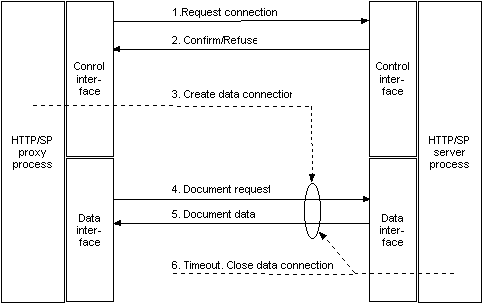
Figure B: HTTP/SP Connection Setup
The document fetch proceeds as follows. The HTTP/SP protocol module requests a document from server side using an RPC call to the data interface. The server side HTTP/SP module receives the request and returns a document identification (or an error code, if the document is not available). Then the server side HTTP/SP module sends the requested document and all embedded objects to the client side HTTP/SP module through the data stream. The previously assigned document identification is used to identify to which document each piece belongs. The basic idea behind this arrangement is that the Enhanced WWW Proxy need not wait for the whole document before being able to start giving it to the client. This is desirable behaviour with browsers that can display documents incrementally.
A session-oriented protocol implies that state is maintained over a longer period, with a number of request-reply interactions occurring during a single session. Implementing a session-oriented protocol as a protocol module in the CERN WWW Library 2.17 is difficult because both the server and the library have been designed to be stateless. It would be possible to maintain state information in a shared memory block allocated for the purpose and shared by all the child processes of the proxy server. However, because of the unportability of this approach we opted for a looser binding between the HTTP/SP protocol engine and the rest of the server.
The HTTP/SP protocol engine is run as a separate process and handles all traffic towards a particular remote WWW server. The HTTP/SP protocol engine is started on demand when a remote server capable of HTTP/SP needs to be accessed. Once started, the HTTP/SP protocol engine functions largely as an independent server while using a common cache with the WWW server. In the current implementation the HTTP/SP module exploits the CERN WWW Server in order to support FTP and WAIS protocols and CGI-scripts.
Figure C illustrates the basic operation of the HTTP/SP protocol module. A document fetch begins with the client making a request. Assuming the requested document is not in the cache, the client HTTP/SP module locks the document and forwards the request to the server side HTTP/SP module. The server side HTTP/SP module fetches the base document as well as any embedded document objects from the server. These objects are forwarded in turn to the client side HTTP/SP module, which stores them in the local cache (In Figure C the document icons with the folded corner indicate where document objects get buffered or cached).

Figure C: Document Fetch in HTTP/SP
When sending a hypertext document to the client side proxy, the server side proxy also queues all the embedded objects, for instance inline images and Java applets, in the document for transfer to the client side proxy. The end result is that the client side proxy receives the whole content of the document in response to a single request.
Because a normal HTTP client will issue a separate request for the hypertext document and each embedded object, it is possible that the client side proxy receives either the embedded object request or the embedded object response first. In HTTP/SP, the server side proxy sends first a list of embedded objects to client side proxy. This prevents the client side proxy from receiving an embedded object request before it knows about the object. When the client side proxy receives a list of embedded objects, it locks all the listed objects in the local cache.
The cache in the HTTP/SP proxy can be simultaneously accessed by the CERN WWW Proxy and its children as well as a number of HTTP/SP protocol modules. Thus, the cache can have multiple writers and readers in different process contexts. In addition, synchronisation between requests and responses must be provided. As seen in the previous section an embedded document object may arrive before the actual request has even been issued. On the other hand, it may be that only advance notification of the arriving object is received and the client must wait for the actual content.
The write locking scheme in our current implementation is based on Unix file system named pipes (FIFOs). Named pipes can be used to implement a blocking binary semaphore as a file system object. When a document request is processes, the cache is first checked to see if the document is already present. If not, an attempt is made to lock the document (by creating a named pipe and opening it for writing). If the document is successfully locked, it is retrieved and written to the cache, after which the document is unlocked. However, if the document is already locked it is already being retrieved. In this case the new reader blocks on the lock (by opening the named pipe for reading and trying to read from it). The reader will eventually be released to access the fetched document when the writer releases the lock (by closing and unlinking the named pipe).
Writing to the cache has been implemented in such a way that partial documents are never visible to readers. New documents are introduced atomically to the cache (using the Unix file system rename() operation). In this case, the Unix FS semantics guarantees that any readers that were still reading the old document will be able to finish without noticing anything while new readers will access the new document. Thus, there is no nead for read locking.
The CERN httpd has a mechanism that removes expired documents from the cache. In our HTTP/SP implementation this mechanism is also utilised to clean any dangling lock files from the cache. Dangling lock files may be left behind if there are problems in the connection to the server side HTTP/SP.
The semantics of a reload request has traditionally been that it must go directly to the original server bypassing all intermediate caches. This applies both to the hypertext page and the embedded objects individually. This poses a problem when using the HTTP/SP protocol to reload a document with embedded objects: the client side proxy will receive a reload request for the actual hypertext page as well as each of the embedded objects. The first request will cause both the hypertext page and the embedded objects to be reloaded. However, as described above an embedded object may arrive to the client side proxy before the actual request for that object is received. An embedded object reload-request would then bypass the cache and cause the object to be re-fetched unnecessarily. The solution is to consider, for a short period of time, a newly cached document to be up-to-date enough even for a reload request.
May 13, 1996
Mika.Liljeberg@cs.Helsinki.FI Heikki.Helin@cs.Helsinki.FI Kimmo.Raatikainen@cs.Helsinki.FI