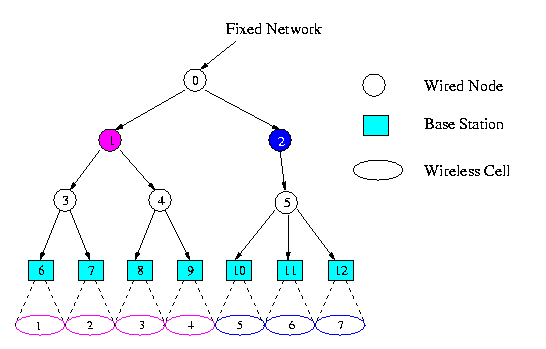
Figure 1 Server Architecture for WLDD querying systems
Jianliang Xu Dik Lun Lee
xujl@cs.ust.hk dlee@cs.ust.hk
Department of Computer Science
Hong Kong University of Science and Technology
Clear Water Bay,
HONG KONG, P. R. China
1 Introduction
In this position paper, we investigate system design issues for querying wireless location-dependent data (WLDD). Several questions we are concerning with are:
We list two examples below to help us understand potential applications for WLDD. While the first example benefits everyone's daily life, the second example is of particular importance in case of emergency situation. Other applications could cover the following applications: Community Services, Dining & Entertainment, Money & Law, Emergency Services, to name but a few [1][2].
Example 1 (Travel Information) Suppose a traveler wants to find a hotel to stay for one night in the middle of his journey, but he/she does not know his current location. The traveler submits a query to WLDD querying system via his wireless handset, "List all hotels with room rate lower than $200 within a 1 Km radius". The system responds with two hotels, Holiday Inn and Shangri-La Hotel, and their other properties. The traveler selects "Holiday Inn" and issues another query, "Find the route to Holiday Inn". The system returns a detailed routing map from the traveler's location to Holiday Inn. Eventually the traveler finds his hotel.
Example 2 (Assistance in Emergency) While walking on the street, a man suffers from a heart attack. His friend immediately queries the WLDD system with "Find the nearest hospital". The system replies "Mary Hospital" as well as its location. Having this information, the friend sends the man to that hospital by taxi in five minutes and the man's life is at last saved due to timely treatment.
3 Server Architecture
Figure 1 Server Architecture for WLDD querying systems
Figure 1 shows a general model for wireless cellular systems. The geographical coverage area for information services is partitioned into wireless cells. Each wireless cell is serviced by a base station (BS), which is a leaf node in the fixed network. A mobile client can connect to a corresponding BS over wireless network to access relevant information at any time. It is assumed that location granularity is cell in this study. We define valid scope of an item value as a set of cells where the item value is valid, and all valid scopes of an item form its scope distribution. For simplicity, we assume valid scopes for all item values are hierarchical and thus they could be represented by a tree (as shown in Figure 1). The server architecture for WLDD querying system is based on the above wireless computing model. Three different server organization methods are discussed in the following paragraphs.
Centralized vs. Distributed Architecture In centralized data server organization, all data item values and their valid scopes are placed in one centralized database. Obviously, this scheme is unattractive in terms of data storage volume. Furthermore, the centralized database could become a performance bottleneck. Alternatively, one may employ distributed data server organization. Every wired node (including base station) is associated with a database. A data item value is placed in the database which is at the least common ancestor of its valid scope. For example, in Figure 1, data item values that are valid at cell 1-4 will be placed in Fixed Node 1. At one extreme, if a data item value is valid only at one cell, then it is stored in the database at the corresponding BS. At the other extreme, if the valid scope of a data item value covers the whole geographical area, it is stored in the database at the root. As can be seen, databases would be redundancy-free under distributed server organization. However, such organization would be hard to administrate for a very large system compared with the centralized solution.
Hybrid Architecture To utilize the benefits of both centralized and distributed data server architectures, a hybrid solution is proposed. In hybrid data server organization, the data item values whose valid scopes are below some level (hereafter called centralization root level) in the valid scope tree are placed in a centralized database at the root of the subtree, whereas other data item values remain the same organization as in the distributed server architecture. As an example, suppose the centralization root level is level 2 in Figure 1 (root is level 0). Thus, item values that are valid only at cell 1 and/or cell 2 are stored in the DB at Fixed Node 3; item values that are valid at cell 1-4 at Fixed Node 1; and item values that are valid at cell 1-7 at the root node.
It is noticed that how to represent valid scopes of item values is another issue in centralized data server architecture. One may represent valid scope as a set of ids of the cells where the item value is valid. This method is not effective for a valid scope containing many cells. Alternatively, we can use a bit vector to specify valid scopes. However, obviously it cannot scale well to the system scale. Hybrid architecture can relieve such problems by lowing the centralization root level. In distributed sever architecture, such problems are totally freed since places of item values being stored imply their valid scopes.
In addition, to improve system performance, data replication and caching at either fixed nodes or mobile nodes could be considered. We will discuss them later in this paper.
4 Query Types and Query Processing
We identify five query types in this section. Query processing methods are discussed for distributed data server architecture, since query processing only for centralized server architecture would be somewhat straightforward.
Local vs. Non-local Queries: Local queries refer to the queries whose results are valid in the current cell. Sample queries are like "list the local hotels", "list the local health centers" etc. To process such a query in distributed data server architecture, the system searches relevant items from databases at fixed nodes from the current BS to the root until the query is satisfied. Non-local queries refer to the queries whose results are valid in another cell. Sample queries are like "find the weather in Cell #8", "find the hotels with room rate lower than $200 in Cell #8". To process such a query, the simplest way is that we re-direct the query to the corresponding cell, and then follow the same method as for local queries. More sophisticated approaches could be developed to reduce communication cost.
Geographically Clustered vs. Geographically Dispersed Queries: Geographical clustered queries refer to the queries with spatial constrains, for example, "list all hospitals within a 500 km radius". Such queries can be answered by a cluster of cells that are within the range, and processing at a cell can follow the same method used for local and non-local queries. Of course, enhancement can be investigated to improve response time and communication cost. Geographical dispersed queries refer to the queries that are not associated with any spatial condition, for example, "list all hospitals with a heart surgery facility". Such queries have to be processed in every cell.
Nearest Queries: Nearest queries are another type of useful queries, for example, "find the nearest gas station", "find the nearest heart hospital" etc. A nearest query can be processed as follows: the query is first processed at the current cell, if the result is found, the query is answered; otherwise, it will require other cells to process it from the nearest cell to the farthest until there is some result found. One can request other cells one by one so that the communication cost is minimized; alternatively, one can request several other cells at a time, and hence the response time can be improved for some cases. There is tradeoff between communication cost and response time for these two processing methods.
One additional important issue for WLDD querying system is QoS guarantee of queries. Since mobile clients will move around and hand over from one cell to another, a query should be responded before the client moves out of the current cell. This can be partly addressed by data caching and replication, and partly by query scheduling. QoS requirements for mobile clients with different movement speeds could be different.
5 Data Replication and Caching
5.1 Server-side Replication
Data replication requires the system to keep the replicas up-to-date at any time. Replication can improve response time if the procedure of validity checking is left out. Full data replication for a large system, however, is almost impractical since the update cost would be extremely high. We are investigating a model based on the well-known network flow algorithm to find a solution for partial data replication at BS nodes. In the model, the gain (denoted as gain(i,j)) of replicating a data item value j, Dj, at cell i, Ci, is represented by the difference between the cost savings due to replication and the cost incurred due to update propagation. In the flow network, each edge has two associated attributes: (cost, capacity). There are three kinds of edges in the flow network, i.e. (s, Dj), (Dj, Ci) and (Ci, t), and the associated attributes for them are (0, rj), (-gain(i,j), 1) and (0, ci), respectively, where rj is the maximum number of nodes at which Dj can be replicated and ci is the database capacity associated with cell Ci. Solving the minimum-cost maximum-flow problem on this flow network, one can find an assignment of data item values to data servers such that the benefit gained is maximized. Specifically speaking, we determine that data item value Dj is replicated at cell Ci if edge (Dj, Ci) is saturated in the resultant maximum flow. A classical minimum-cost maximum-flow algorithm could be found in [5]. Data replication at nodes other than BS nodes deserves future investigation.
5.2 Server-side Caching
Every time a query is issued from a cell, a copy of the required data item could be cached at some node on the path from the cell to the qualified data server. Several issues are remained open for discussion:
As mentioned before, data replication needs to keep the replica up-to-date at any time. This would be much difficult for mobile clients. First, mobile clients can go into disconnected state. How could the server propagate updated item values to disconnected mobile clients immediately? Second, a mobile client may move to other locations, how could an updated location-dependent item value be delivered to every relevant client? Therefore, we believe, rather than data replication, data caching is more attractive for mobile clients.
5.4 Caching at Mobile Clients
Client data caching is of particular importance in mobile environments. This is because besides improving system performance, it can save power due to less data transmission and improve data availability in case of disconnection. However, a difficult problem about data caching is to maintain cache consistency. In general, cached data items become invalid if they are updated at the data server. We call such invalidation as temporal-dependent invalidation. For temporal-dependent invalidation, it has been shown that periodic invalidation report broadcasting is an effective method [8][9][10]. In WLDD systems, there is yet another type of invalidation, called location-dependent cache invalidation [11]: cached data items become obsolete due to the change of the mobile client's location. We have proposed three schemes to deal with location-dependent cache invalidation, namely BVC, GBVC and ISI. Interested readers are referred to [11] for details.
The change of the mobile client's location also opens other questions for client data caching. When the mobile client moves around, intuitively it should drop "faraway" items first during replacement if only the distance factor is considered. How can the distance factor be integrated into existing policies? Also, with spatial properties, how could semantic data caching be applied in the context of WLDD systems?
6 Conclusion
In this position paper, we identified potential applications for WLDD query systems and investigated various design issues. We are extending our work on wireless caching and data dissemination to a location dependent environment. Several preliminary solutions are presented to address some of the issues, while open questions provide future directions to research in this area.
[1] http://www.altavista.com
[2] http://www.yahoo.com
[3] Report
of National Science Foundation Workshop on Tetherless T3 and Beyond,
Nov. 1998.
[4] M. Taylor, W. Waung and M. Banan. Internetwork
mobility: The CDPD approach. Prentice Hall, 1997.
[5] T.H. Cormen, C.L. Leicerson and R.L. Rivest.
Introduction to Algorithms. MIT Press and McGraw-Hill, New York, 1990.
[6] Howard, J.H., Kazar, M.L. Menees, S.G., Nichols,
D.A., Satyanarayanan, M., Sidebotham, R.N., and West, M.J. Scale and performance
in a distributed file system. ACM Transaction on Computer System,
Vol 6(1): 51-81, 1988.
[7] Jianliang Xu, Qinglong Hu, Dik Lun Lee. Client
cache management issues in on-demand broadcast systems. Under preparation.
[8] D. Barbara and T. Imielinksi. Sleepers and workaholics:
Caching strategies for mobile environments. Proceedings of the ACM SIGMOD
Conference on Management of Data, Minneapolis, MN, pages 1-12, May
1994.
[9] Qinglong Hu and Dik Lun Lee. Cache
algorithms based on adaptive invalidation reports for mobile environments.
Cluster
Computing, 1(1):39-48, Feb. 1998.
[10] Qinglong Hu, Dik Lun Lee, and W.-C. Lee. Performance
Evaluation of a Wireless Hierarchical Data Dissemination System. Proceedings
of MobiCom'99, Seattle, WA, Aug. 1999.
[11] Jianliang Xu, Xueyan Tang, Dik Lun Lee and
Qinglong Hu. Cache
Coherency in Location-Dependent Services for Mobile Environment. Proceedings
of the First International Conference on Mobile Data Access, Hong Kong,
Dec. 1999.