Character Sets and Entity Definitions
[Top] [Up] [Next] [Previous]
5.1 - Character Sets and Entity Definitions
By default, HTML+ documents are made up of 8-bit characters from the ISO 8859 Latin-1 character set. The network protocol used to retrieve documents may translate the character set into a locally acceptable form, e.g. EBCDIC. The HTTP protocol uses the MIME standard (RFC 1341) to specify the document type and character set. ISO SGML entity definitions are used to include characters which are missing from the character set or which would otherwise be confused with markup elements, e.g:
- &
- ampersand &
- <
- less than sign <
- >
- greater than sign >
- "
- the double quote sign "
Appendix II lists a broad range of characters and symbols, relating their ISO names to the corresponding character codes in common character sets. They allow authors to include accented characters in 7-bit ASCII documents. Some other useful entity definitions are:
- –
- en dash (half the width of an em unit)
- —
- em dash (equal to width of an "m" character)
-  
- en space
-  
- em space
-
- non breaking space
- ­
- soft hyphen (normally invisible)
- ©
- copyright sign
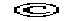
- ™
- trade mark sign
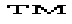
- ®
- registered sign
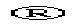
There are a large number of entities defined by the ISO, covering most languages and symbols for publishing and mathematics. Requiring all browsers to support these would be impractical, e.g. how should a dumb terminal show such symbols. In some cases there will be accepted ways of mapping them to normal characters, e.g. æ as ae and è as e. Perhaps the safest recommendation is that where authors need to use a specialised character or symbol, they should use ISO entity names rather than inventing their own. Browsers should leave unrecognised entity names untranslated.
In some cases it is useful to specify the language used in a given element, with the LANG attribute. The ISO defines abbreviations for most languages, e.g. FR for french as in:
<Q LANG="FR">Je m'aveugle.</Q>. This attribute permits language dependent layout and hyphenation decisions, e.g. Hebrew uses right to left word order.
To allow SGML parsers to recognise entity names, authors should declare them before use, for example:
<!ENTITY % ISOcyr1 PUBLIC "ISO 8879-1986//ENTITIES Russian Cyrillic/EN">
%ISOcyr1;
This introduces ISOcyr1 as a local name for the ISO public identifier for the cyrillic alphabet and then includes the associated set of entity definitions as part of the current document. This declaration is unnecessary for entities defined within the HTML+ DTD.
HTML+ Discussion Document - November 8, 1993
[Top] [Up] [Next] [Previous]