Odpowiedź
Normalizacja jest ważna, kiedy tworzymy strony w HTML z wykorzystaniem arkuszy stylu CSS w UTF-8 (lub innym kodzie Unicode), zwłaszcza gdy tekst w skrypcie występuje z akcentami lub znakami diakrytycznymi.
Jakie są formy normalizacji?
W Unicode można stworzyć ten sam tekst z różnymi sekwencjami znaków. Weźmy na przykład słowo világw języku węgierskim. Czwartą literę można by zapisać w pamięci jako prekomponowaną U+00E1 ŁACIŃSKA MAŁA LITERA A (pojedynczy znak) lub jako dekomponowaną sekwencję U+0061 ŁACIŃSKA MAŁA LITERA A, a następnie U+0301 Z AKCENTEM AKUTOWYM (dwoma znakami)

Standard Unicode dopuszcza użycie każdej opcji, ale wymaga równego ich traktowania. Aby poprawić wydajność, aplikacja zwykle normalizuje tekst, zanim nastąpi wyszukiwanie lub porównanie. W tym przypadku normalizacja oznacza konwersję tekstu z użyciem albo prekomponowanych albo dekomponowanych znaków.
Standard Unicode wyróżnia cztery formy normalizacji: NFC, NFD, NFKC i NFKD. C oznacza (pre-)komponowany, D dekomponowany. A K oznacza kompatybilność. Aby usprawnić interoperacyjność, W3C zaleca użycie tekstu z przeznaczeniem do sieci znormalizowanego zgodnie z NFC.
Co trzeba wiedzieć o normalizacji?
Niestety, normalizacja nie zawsze poprzedza porównanie treści. Szczególnie ważne jest użycie selektorów i nazw klas lub identyfikatorów w HTML i CSS. Jeśli wspomniane słowo világ jest użyte w formie prekomponowanej w HTML (np. <span class="világ">), ale w formie dekomponowanej w CSS (np. .világ { font-style: italic; }), wówczas selektor nie będzie odpowiadał nazwie klasy.
Oznacza to, że przy tworzeniu treści, należy sprawdzić znak po znaku, czy selektory oraz nazwy klas lub identyfikatorów są identyczne. Najczęściej tego typu problemu mogą wystąpić jeśli znaczniki lub style CSS są tworzone lub zarządzane przez różne osoby.
Najlepszym rozwiązaniem jest użycie jednej formy normalizacji Unicode dla całego tworzonego tekstu. Jak już zostało wspomniane, W3C zaleca użycie NFC.
Większość klawiatur z użyciem języków europejskich tworzy już od pewnego czasu teksty w NFC, jednak sytuacja wygląda inaczej w przypadku wielu języków pozaeuropejskich.
W niektórych przypadkach edytor może zapisać dane w wybranej formie normalizacji. Poniższy obraz pokazuje opcję ustawienia danej formy normalizacji jako domyślnej przy otwieraniu nowych plików w programie Dreamweaver (wybrano NFC). Podobny wybór pojawia się przy zapisywaniu dokumentu.
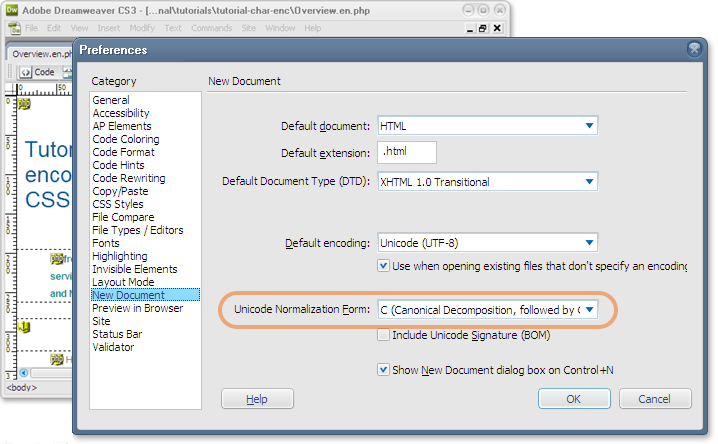
W jaki sposób mogę wyszukać ewentualne problemy na stronach?
Można sprawdzić, czy strona w HTML zawiera nazwy klas i wartości identyfikatorów niezgodne z normami NFC, korzystając z Kontrolera Internacjonalizacji W3C.
Jeżeli problemy już wystąpiły, należy poszukać edytora lub narzędzia konwersji, który umożliwi wybór formy normalizacji i użyć go do ponownego zapisania strony.