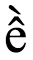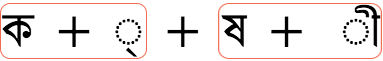Intended audience:
Programatorilor XHTML/HTML (care folosesc editoare sau scripting), dezvoltatorilor software(PHP, JSP, etc.), programatorilor CSS, și tuturor celor care sunt începatori în ceea ce priveste terminologia codării caracterelor și vor să înteleagă conceptele de bază.
Acest articol introduce o serie de concepte de bază necesare întelegerii altor articole care au legatură directă cu caracterele și codarea acestora.
Unicode este un set universal de caractere,un standard care definește, la un loc, toate caracterele necesare pentru scrierea majorității limbajelor folosite pe calculatoare. Se dorește a fii, și deja în mare parte este, un super set al tuturor caracterelor care au fost codate.
Textul dintr-un calculator sau de pe Web este compus din caractere. Caracterele reprezintă literele alfabetului, punctuația, sau alte simboluri.
În trecut, diverse organizații au alăturat diverse seturi de caractere și au creat coduri pentru ele – un set ar putea acoperi doar limbajele Vest-Europene bazate pe limba latina (cu excepția tărilor Europene ca Bulgaria ori Grecia), altul ar putea acoperi o limbă specifică din Estul Indepartat (cum ar fi Japoneza), altele ar putea fi unele din multele seturi împarțite pe loc pentru a reprezenta alte limbaje undeva in lume.
Din păcate, nu poți garanta că aplicația ta va suporta toate codările, nici faptul că o anumită codare va suporta toate necesitațile de a reprezenta un anumit limbaj. În plus, de obicei este imposibil să combini diferite codări pe aceași pagină Web sau într-o bază de date, deci este foarte dificil să oferi suport pentru mai multe limbi folosind abordarea de "moștenire" a codării.
Consorțiul Unicode oferă un set mare de caractere simple, scopul fiind de a include toate caracterele necesare pentru orice sistem de scriere din lume, inclusiv scrieri antice(cum ar fi Cuneiform, Gotic si Hieroglife egiptene). În acest moment este esențial pentru arhitectura Web și pentru sistemele de operare, și este suportat de toate browserele și aplicațiile importante. Standardul Unicode descrie de asemenea proprietăți și algoritmi pentru lucrul cu caractere.
Această abordare face mai ușor lucrul cu paginile sau sistemele miltilingve, și oferă o acoperire a necesităților tale mai mare decât majoritatea sistemelor de codare.
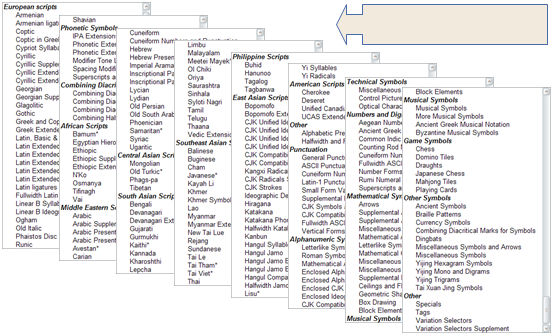
Următoarea imagine arată blocuri de script Unicode de la versiunea Unicode 5.2:
Se spune că primele 65,536 de poziții de puncte de cod din setul de caractere Unicode constituie Planul Multilingv de Bază(Basic Multilingual Plane (BMP)). BMP include majoritatea caracterelor cele mai uzuale.
Numărul 65,536 este 2 la putearea 16. Cu alte cuvinte, numărul maxim de permutari de biți pe care le poți obține în doi bytes.
Setul de caractere Unicode conține de asemenea loc pentru un milion de poziții de puncte de cod adiționale. Caracterele din această gama sunt cunoscute ca și caractere suplimentare.
Este important să distingem clar între conceptul de set de caractere și codarea caracterelor.
Un set de caractere sau repertoriu cuprinde setul de caractere pe care cineva le-ar putea folosii intr-un scop specific – fie cele necesare pentru a suporta limbajele Vest Europene pe calculatoare, fie cele pe care un copil chinez le va invăța la scoala în clasa a treia(nu au nicio legatură cu calculatoarele).
Un set de caractere codate este un set de caractere pentru care un număr unic a fost repartizat fiecarui caracter. Unitățile unui set de caractere codate sunt cunoscute ca puncte de cod. Valoarea unui punct de cod reprezintă poziția unui caracter în setul de caractere codate. De exemplu, punctul de cod pentru litera á în setul de caractere codate Unicode este 225 în decimal, sau E1 în hexadecimal. (Observați că notația hexadecimală este utilizată frecvent în referinta punctelor de cod, și va fi folosită și aici.) A Unicode code point can have a value between 0x0000 and 0x10FFFF.
Seturile de caractere codate sunt denumite uneori pagini codate.
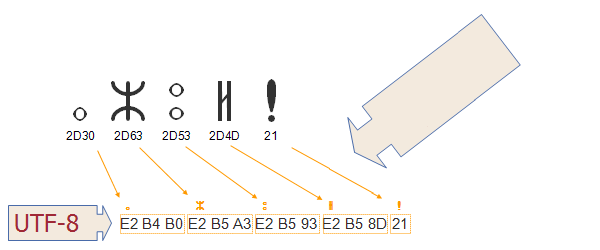
Codarea caracterelor reflectă felul in care setul de caractere codate este organizat în bytes pentru manipularea într-un calculator. Imaginea de mai jos arată cum caracterele și punctele de cod în codul Tifinagh (Berber) sunt organizate pe secvențe de bytes în memorie folosind codarea UTF-8. Valorile punctelor de cod pentru fiecare caracter sunt listate imediat sub reprezentare( reprezentarea vizuală) pentru caracterul din partea de sus a diagramei. Săgețile arată cum acestea sunt organizate pe secvențe de bytes, unde fiecare byte este reprezentat de un numar hexazecimal format din două caractere. Observați că punctele de cod Tifinagh se definesc pe trei bytes, dar semnul exclamării se definește pe un singur byte.
Această explicație atrage atenția asupra unei nomenclaturi detaliate care are legatură cu codarea. Mai multe detalii pot fi găsite în Raportul Tehnic Unicode #17.
Un set de caractere, multiple codări. Multe standarde de caractere codate, cum ar fi seriile ISO 8859, folosesc un singur byte pentru un caracter iar codarea este o organizare simplă pe poziția scalară a caracterului în setul de caractere codate. De exemplu, litera A în setul de caractere codate ISO 8859-1 este poziția caracterului cu numărul 65(începand de la 0), și este codat pentru reprezentarea în calculator folosind un byte cu valoarea 65. Pentru ISO 8859-1 acest lucru nu se schimbă niciodată.
Pentru Unicode, totuși, lucrurile nu sunt atât de simple. Chiar dacă punctul de cod pentru litera á în setul de caractere Unicode este mereu 225 (în decimal), în UTF-8 el este reprezentat în computer de doi bytes. Cu alte cuvinte nu este o banală organizare
unu la unu
între setul de caractere codate și valoarea codată pentru acest caracter.
În plus, în Unicode există mai multe feluri de a coda același caracter. De exemplu, litera á poate fi reprezentată de doi bytes în unul și din patru bytes în altul. Formele de codare care pot fi folosite cu Unicode
sunt denumite UTF-8, UTF-16, și UTF-32.
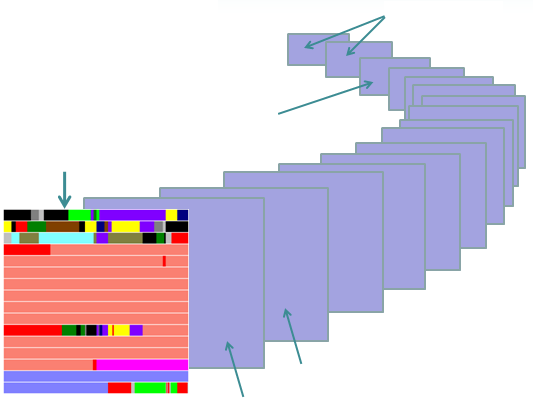
UTF-8 folosește 1 byte pentru a reprezenta caractere în setul ASCII, doi bytes pentru caractere în mai multe blocuri alfabetice, și trei bytes pentru restul BMP. Caracterele suplimentare folosesc 4 bytes.
UTF-16 folosește 2 bytes pentru orice caracter în BMP, și 4 bytes pentru caracterele suplimentare.
UTF-32 folosește 4 bytes pentru toate caracterele.
În urmatoarea diagramă, prima linie de numere reprezintă poziția unui caracter în setul de caractere Unicode. Celelalte linii arată valoarea bytes-ilor folosiți pentru a reprezenta acel caracter într-o codare de caracter specifică.
Pentru XML și HTML (începând cu versiunea 4.0) setul de caractere ale documentului este definit ca fiind Setul Universal de Caractere(Universal
Character Set (UCS)) așa cum este definit atât de standardele ISO/IEC 10646 cat și de Unicode. (Pentru simplitate și pentru o practica cât mai simpla, ne vom referi aici la UCS ca Unicode.)
Asta inseamnă că modelul logic care descrie cum sunt procesate XML și HTML este descris ca și set de caractere definit de Unicode. (În termeni practici, asta inseamnă că browserele convertesc în interior tot textul în Unicode.)
Observați că aceasta nu inseamnă că toate documentele HTML și XML trebuie sa folosească codarea Unicode! Inseamnă că, acel document poate conține doar elemente definite de Unicode. Orice codare poate fi folosită pentru documentul tău atâta timp cât este declarată corespunzător și reprezintă un subset al unui repertoriu Unicode.
Although we have used it without much qualification so far in this article, the term 'character' is used here in an abstract and somewhat vague way to refer to the smallest component of written language that has semantic value. However, the term 'character' is often used to mean different things in different contexts: it can variously refer to the visual, logical, or byte-level representation of a given piece of text. This makes the term too imprecise to use when specifying algorithms, protocols, or document formats, unless you explicitly define what you mean by it. If the term 'character' is used in those contexts in a technical sense, the recommendation is to use it as a synonym for code point (described above).
It is particularly important to remember that bytes only rarely equate to characters in Unicode, as shown in the earlier examples.
However, particularly in complex scripts, what a user perceives as a smallest component of their alphabet (and so what we will call a user-perceived character) may actually be a sequence of code points. For example, the Vietnamese letter ề will be perceived as a single letter even if the underlying code point sequence is U+0065 LATIN SMALL LETTER E + U+0302 COMBINING CIRCUMFLEX ACCENT + U+0300 COMBINING GRAVE ACCENT. Similarly, a Bangla speaker may view ksha (ক্ষ), which is composed of the sequence U+0995 BENGALI LETTER KA + U+09CD BENGALI SIGN VIRAMA + U+09B7 BENGALI LETTER SS,) as a single letter.
It is often important to take into account these user-perceived characters. For example, it is common to treat certain combinations of code points as a single unit for various editing operations, such as line-breaking, cursor movement, selection, deletion, etc. It would usually be problematic if a user selection accidentally omitted part of the letters just mentioned, or if a line-break separated a base character from its following combining characters.
In order to approximate user-perceived character units for such operations, Unicode uses a set of generalised rules to define grapheme clusters – sequences of adjacent code points that can be treated as a unit by applications. A single alphabetic character like e is a grapheme cluster, but so also is any combination of base character and following combining character(s), such as ề mentioned above.
Unicode Standard Annex #29: Text Segmentation actually defines two types of grapheme cluster: extended grapheme clusters, and legacy grapheme clusters. Here when we say 'grapheme cluster' we mean the former. It is not recommended to use the latter.
Currently there are, however, some limitations to the grapheme cluster rules: for example, the rules split the Bangla user-perceived character kshī (ক্ষী) into two adjacent grapheme clusters, rather than enveloping the whole orthographic syllable. Applications that need to work with user-perceived characters in Bangla therefore need to apply some script-specific tailoring of the grapheme cluster rules.
user-perceived character
decomposition & grapheme cluster boundaries
The appropriate units for editing operations sometimes vary according to what you want to do. For example, if you backspace over the Hindi word हूँ (U+0939 DEVANAGARI LETTER HA + U+0942 DEVANAGARI VOWEL SIGN UU + U+0901 DEVANAGARI SIGN CANDRABINDU) the application will typically first delete each of the two combining characters, and then the base. However, if you 'forward-delete' while the cursor is at the left of the word most applications will delete the whole grapheme cluster in one go.
CSS, in order to refer to an indivisible text unit in a given context, uses the term typographic character unit. The definition of what constitutes a typographic character unit depends on the operation that is being applied. So when working with the example of ề above, when deleting forwards there would be a single typographic character unit, but three when backspacing. Also, typographic character units cover the cases such as Bengali ksha, which grapheme clusters currently don't. The determination of what constitutes a typographic character unit in a given language and editing context is deferred to the application, rather than spelled out in rules.
A font is a collection of glyphs. In a simple scenario, a glyph is the visual representation of a code point. The glyph used to represent a code point will vary with the font used, and whether the font is bold, italic, etc. In the case of emoji, the glyphs used will vary by platform.
In fact, more than one glyph may be used to represent a single code point, and multiple code points may be represented by a single glyph.
Emoji provide another example of the complex relationship between code points and glyphs.
The emoji character for "family" has a code point in Unicode: 👪 [U+1F46A FAMILY]. It can also be formed by using a sequence of code points: 👨👩👦 [U+1F468 U+200D U+1F469 U+200D U+1F466]. Altering or adding other emoji characters can alter the composition of the family. For example the sequence 👨👩👧👧 [U+1F468 U+200D U+1F469 U+200D U+1F467 U+200D U+1F466] results in a composed emoji glyph for a "family: man, woman, girl, boy" on systems that support this kind of composition. Many common emoji can only be formed using sequences of code points, but should be treated as a single user-perceived character when displaying or processing the text.
O alternativă la caractere reprezintă o cale de a reprezenta un caracter fără a folosi caracterul în sine.
De exemplu, nu există o cale de a reprezenta direct caracterul ebraic א în document dacă folosiți codarea ISO 8859-1(care acoperă limbajele Vest Europene). O cale de a indica faptul că vrei să incluzi acel caracter în HTML este acela de a folosi ca alternativă א. Deoarece setul de caractere este Unicode, utilizatorul ar trebui să recunoască că acesta reprezintă caracterul ebraic aleph.
Exemple de alternative în HTML / XHTML și CSS, și sfaturi referitoare pentru când și cum să le folosim pot fi gasite în aticolul Folosirea alternativelor în marcare și CSS.
Când cereți un document de la un server, serverul trimite în mod normal niște informații în plus alături de document. Acestea se cheamă antet HTTP. Aici este un exemplu de tip de informație despre document care este returnată de antetul HTTP cu un document în drumul său de la server la client.
A doua linie de jos în sus din acest exemplu oferă informații despre codarea caracterelor din document.
HTTP/1.1 200 OK
Date: Wed, 05 Nov 2003 10:46:04 GMT
Server: Apache/1.3.28 (Unix) PHP/4.2.3
Content-Location: CSS2-REC.en.html
Vary: negotiate,accept-language,accept-charset
TCN: choice
P3P: policyref=http://www.w3.org/2001/05/P3P/p3p.xml
Cache-Control: max-age=21600
Expires: Wed, 05 Nov 2003 16:46:04 GMT
Last-Modified: Tue, 12 May 1998 22:18:49 GMT
ETag: "3558cac9;36f99e2b"
Accept-Ranges: bytes
Content-Length: 10734
Connection: close
Content-Type: text/html; charset=UTF-8
Content-Language: en
Dacă documentul este creat dinamic folosind limbaje de scripting, poți adăuga această informație în mod explicit în antetul HTTP. Dacă oferi fișiere statice, serverul poate asocia această informație cu aceste fișiere. Modul de a seta serverul ca să ofere informații despre codarea caracterelor în acest mod va varia de la server la server. Ar trebui să luați legatura cu administratorul serverului.
Ca și exemplu, serverele Apache ofera o codare implicită a caracterelor, care poate fi de obicei suprascrisă de setări specifice directoarelor. De exemplu, un webmaster poate adăuga urmatoarea linie la un fișier .htaccess pentru a returna toate fisierele cu extensia .html ca și UTF-8 în acest director cât și în directoarele pe care le conține: