
This is an attemptto understand & explain the reasoning of the folks mapping XML semantics to RDF "naturally". It follows from a discussion with Adam Bosworth.
XML is a language for transmitting structured information. If the goal of the web is to enable not only communication between people, but also between machines, then XML seems a good basis not only for documents to be read by people, but for data to be read by machines.
Data in any form can be broken down into a representation as a "directed, labeled graph" (DLG). I just assert this here, and if someone mails me a pointer to a good proof I will paste that in. For DLG, just think "circles and arrows diagram". The arcs of the graph (the arrows) represent relationships between the nodes.
An XML document is a tree, which is a particular sort of directed graph. If we add to XML a way of making arcs which link XML arbitrary elements then it can be a more general DLG. We can use an XML document to represent any data which comes in the form of a DLG. [We actually don't map 1-1 as an XML document can't have disjoint parts, but we can have a convention just use it to contain descriptions of disjoint DLGs].
Lets take an example the statement that Joe lives on Beech Street. That is, a person who has a name Joe lives on a street which has a name "Beech St".
When you represent information as a DLG the nodes don't actually contain any information: it's all in the connections.
We could represent that in an XML document as
<friend>
<name>Joe</name>
<inhabits>
<name>Beech St</name>
</inhabits>
</friend>
and in circles and arrows as:
which you can read as "There is a thing called Joe which inhabits a thing calld Beech St" or more simply as "Joe inhabits Beech St"
The arcs represent the relationship "has name" and "inhabits". .The circles here stand for a person and a street. However, this information is not given explicitly. From the fact that A lives on B you might conclude that A is a person and B is a street -- or we could make it explicit by making an asssertion about the person or about "inhabits".
To make the example slightly more complicated,
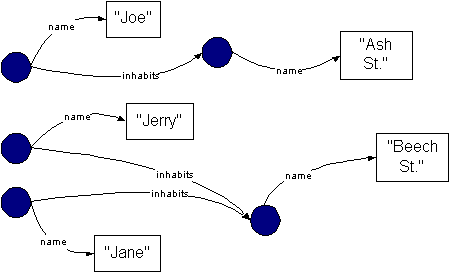
<friend>
<name>Joe</name>
<inhabits>
<name>Ash St</name>
</inhabits>
</friend>
<friend>
<name>Jane</name>
<inhabits>
<name>Beech St</name>
</inhabits>
</friend>
<friend>
<name>Jerry</name>
<inhabits>
<name>Beech St</name>
</inhabits>
</friend>
(This seems to be the model assumed by for example most of the Lore folks (Stanford) and Adam Bosworth (microsoft) at the 1998 W3C Query Language Workshop.)
The element name "friend" represents two things: the relationship between the book and the page, and also what sort of a thing the page. Similarly, "author" described both the relationship that one wrote the other, and also constrains the one that wrote to be (typically) a person.
(The original RDF syntax focussed on the node type but we will not).
In this syntax, we take the element as defining the relationship, and the node type as being constrained indirectly if at all: typically, we assume that the schema defines the range of the relationship.
Each relationship (RDF property) (Adam Bosworth refered to these as "Instance names") introduces a new node. Within that element, subelements define relationships - properties of that node, and so on. For every relationship , the subject is implicitly the object of the enclosinging relationship.
This information maps onto a relational database in which each node is a row in a table:
| id |
Name |
Inhabits |
|---|---|---|
| s1 | Joe | s4 |
| s2 | Jerry | s5 |
| s3 | Jane | s5 |
| id | Name |
|---|---|
| s4 | Ash St |
| s2 | Beech St |
(This might in practice be done in many applications by making a table in which the street-name was defined to be unique and used instead of an identifier. This becomes less efficient when the number of unique streets is very different from the number of unique people.)
This information could be represented as a single (unordered) table of eight arcs.
| Subject | Predicate/relationship/verb | value/object |
| s1 | Name | Joe |
| etc | ... | ... |
The arbitrary node identifiers "s1", "p1" and "p2" are used in a table just allow the graph to be constructed. They are needed because a table only allows disconnected arcs to be defined, but a tree needs more connectivity.
To simply traverse the graph above as though it were a tree in the case above led to a duplication of "Beech St" and in a worse case would lead loops. Clearly when serializing a graph we only want to represent each bit once, and we need a way odding cross-links to the tree. (Strong opionions that IDRefs were the way to do this from many people at QL98) We can write for example
<friend>
<name>Joe</name>
<inhabits>
<name>Ash St</name>
</inhabits>
</friend>
<friend>
<name>Jane</name>
<inhabits id="s2">
<name>Beech St</name>
</inhabits>
</friend>
<friend>
<name>Jerry</name>
<inhabits href="#s2"></inhabits>
</friend>
Here there is a link from the "href" to the "id" indicating that the object descibed by the first "inhabits" element is the same object as is refeerd to also by the second. Discussion betwen relative merits of syntaxes here is omitted: suffice it to show that to make such links is quite simple syntactically.
While Adam Bosworth agreed fervently with the RDF model that order was not relevant in the data model, he suggested there was nesting information in the document has a signficance. The containment of one property within the XML element expressing another has a significance. Of course within most XML documents for human consumption the nesting and order have great significance, but when the data is extraced it has extra value in tha the extracted data stands by itself without context. So what is the significance of containment?
The significance is that the back-end supports a "delete" operation on the data. When an element of a document is deleted, in the document object model, then the expectation is that all contained elements are deleted.
This supposes that the document nesting canonical form - that the document is effectively the "source" and hence "editable" form of the data. There is an analogy with a web document which is available in editable HTML and derived postscript which is not editable. One can also expect data in XML could often be the result of a query in which data has been combined from many sources. In this case, deletion may not correspond to an operation which makes sense or is possible in the supporting database.
If containment is to be significant we have to flag it in some way in the syntax, or express it explicitly in some way.
<employee>
<street-name>Ash St</street-name>
<name>Jerry<name>
</employee>
<employee>
<name>Joe</name>
<inhabits>Beech St</inhabits>
<employee>
<employee>
<name>Jane</name>
<inhabits>Beech St</inhabits>
<employee>
The data which may be cannonically available in the above form might allow deletion from the database by document element deletion. However, a query by road would result in a different tree:Here, what would happen if we deleted a street? It may simply be unsupported. End example. (In this example, "inhabits" is a shorthand for "inhabits->name"
<street> <name>Beech St</name> <inhabitant-name>Joe</inhabitant-name> <inhabitant-name>Jane</inhabitant-name></inhabitant> </street>
</street>
<street> <name>Beech St</name> <inhabitant-name>Joe</inhabitant-name> <inhabitant-name>Jane</inhabitant-name> </street>
Here, what would happen if we deleted a street? It may simply be unsupported. End example. (In this example, "inhabits-streetname" is a shorthand for "inhabits -> name" and "inhabitant-name" is shorthand for "inverse(inhabits) -> name".)
In the example above, the first "cannonical" listing of the database - the deletable one - can be used to derive cannonical URIs for every object. All you need to do is create XML IDs on the elements and use the convention that a reference to that element implies a reference to the object it describes. (This is not a trivial step for those who followed reification in RDF! but never mind for now.)
<employee>
<inhabits id=ashst>
<name>Ash St</name>
</inhabits>
<name>Jerry<name>
</employee>
<employee>
<name>Joe</name>
<inhabits id=beechst>
<name>Beech St</name>
</inhabits>
<employee>
<employee>
<name>Jane</name>
<inhabits href="#beechst" />
<employee>
This is fine, but what happens in the case of a query response which is not the cannonical database document? To use the identity of the XML element in the query result denies the actual identity of the object. This is when we need to be able to identify an object independently of the position of the object
<street fyi="http://foo.com/employees#beechst" /> <name>Beech St</name> <inhabitant-name>Joe</inhabitant-name> <inhabitant-name>Jane</inhabitant-name></inhabitant> </street>
</street>
<street> <name>Beech St</name> <inhabitant-name>Joe</inhabitant-name> <inhabitant-name>Jane</inhabitant-name> </street>
To be added:
Containment in A database
Referring to things in other files
First class objects: IDREF and HREF
| ER Model | Entity | Relationship |
| RDF | Node | Property name |
| SQL output | Record | Field, column |
| Object Oriented | Object | variable |
| diagram | Circle | Arrow |
| A. Bosworth | Node | Instance name |
| Lore | Node | Arc |
| A. Layman XML syntax | Element | Attribute |
| A. Bosworth XML syntax | implicit | Element |
| RDF M&S syntax | Element | Attribute or element |