Note: (2006). This architectural question has now been decided by the W3C TAG, in a compromise which I think works quite well, and is described in a later short note and a TAG finding.
This question has been addressed only vaguely in the specifications. However, the lack of very concise logical definition of such things had not been a problem, until the formal systems started to use them. There were no formal systems addressing this sort of issue (as far as I know, except for Dan Connolly's Larch work [@@]), until the Semantic Web introduced languages such as RDF which have well-defined logical properties and are used to describe (among other things) web operations.
The efforts of the Technical Architecture Group to create an architecture document with common terms highlighted this problem. (It demonstrates the ambiguity of natural language that no significant problem had been noticed over the past decade, even though the original author or HTTP , and later co-author of HTTP 1.1 who also did his PhD thesis on an analysis of the web, and both of whom have worked with Web protocols ever since, had had conflicting ideas of what the various terms actually mean.)
This document explains why the author find it difficult to work in the alternative proposed philosophies. If it misrepresents those others' arguments, then it fails, for which I apologize in advance and will endeavor to correct.
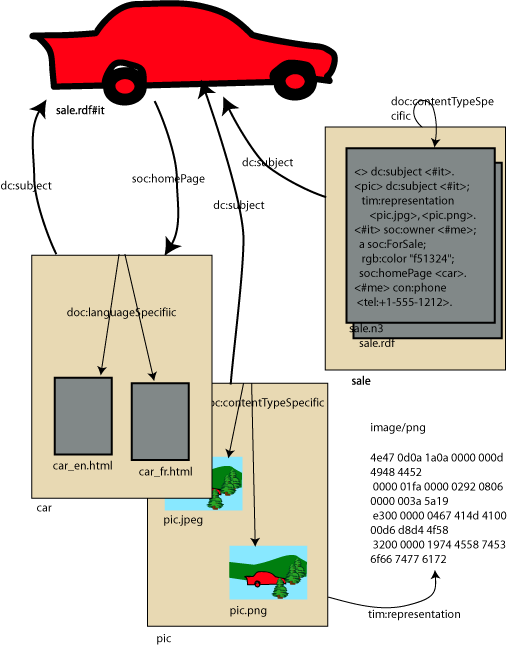
The WWW is a space of information objects. The URI was originally called a UDI, and originally all URIs identified information objects. Now, URI schemes exist which identify more or less anything (e.g. UUIDs) or electronic mailboxes (mailto:) but is we look purely at HTTP URIs, they define a web of information objects. Information objects -- perhaps in Cyc terms ConceptualWorks -- are normally things which
I want to make it clear that such things are generic (See Generic Resources) -- while they are documents, they generally are abstractions which may have many different bit representations, as a function of, for example:
but the philosophy is that an HTTP URI may identify something with a vagueness as to the dimensions above, but it still must be used to refer to a unique conceptual object whose various representations have a very large a mount in common. Formally, it is the publisher which defines the what an HTTP URI identifies, and so one should look to the publisher for a commitment as to the exact nature of the identity along these axes.
I'm going to refer to this as a document, because it needs a term and that is the best I have to date, but the reader should be sure to realize that this does not mean a conventional office document, it can be for example
and so on, as limited only by our imagination.
The Web works because, given an HTTP URI, one can in a large number of cases, get a representation of the document. For a human readable document, the person is presented with the information by virtue of some gadget which is given the bits of a representation. In the case of a hypertext document, a reference to another document is encoded such that, upon user request, the referenced document can in turn be automatically presented. In the case of a machine-readable document, identifiers of concepts, being HTTP URIs, will often allow definitive reference information about those concepts to be pulled in to guide further actions.
The web, then, is made of documents as the internet is made of cables and routers. The documents can be about anything, so when we move to talk about the contents of documents we break away from talking about information space and the whole universe of human -- and machine -- discourse is open to us. Web pages can compare a renaissance choral works with jazz pop hits, and discuss whether pigs have wings. Machine-processable documents can encode information about shoes, and ships, and sealing-wax. Until recently, the Internet protocol standards out of which the Web is built had little to say about such things. They were concerned only with the human-readable side, so it was people, reading natural language (not internet specs) who formed and communicated the concepts at this level. Nowadays, however, semantic web languages allow information to be expressed not only about URIs, TCP ports and documents, but also about arbitrary concepts - the shoes, and ships and sealing wax, and whether pigs have wings. Simple semantic web application allow one to order shoes and travel on ships, and determine that, given the data, pigs do not have wings.
For these purposes it is of course quite essential to distinguish between something described by a document and the document itself. Now that we -- for the first time -- have not only internet protocols which can talk about document but also those which talk about real world things, we must either distinguish or be hopelessly fuzzy.
And is this bad, is it an inhibition to have to work our way though documents before we can talk about whatever we desire? I would argue not, because it is very important not to lose track of the reasons for our taking and processing any piece of information. The process of publishing and reading is a real social process between social entities, not mechanical agents. To be socially responsible, to be able to handle trust, and so on, we must be aware of these operations. The difference between a car and what some web page says about it is crucial - not only when you are buying a car.
Some have opined that the abstraction of the document is nonsense, and all that exists, when a web page describes a car, is the car and various representations of it, the HTML, PNG and GIF bit streams. This is however very weak in my opinion. The various representations have much more in common than simply the car. And the relationship to the car can be many and varied: home page, picture, catalog entry, invoice, remote control panel, weblog, and so on. The document itself is an important part of society - to dismiss its existence is to prevent us being aware of human and aspects of information without which we are impoverished. By contrast, the difference between different representations of the document (GIF or PNG image for example) is very small, and the relationship between versions of a document which changes through time a very strong one.
The folks who disagree with the model do so for a number of different arguments. This article, therefore will have to take them one by one but the ones which come to mind are as follows:
Let's take the alternatives in order. These alternatives all make sense. Each one, however, has problems I can't see any way around when we consider them as a basis as
The first was,
Every web page (or many of them) are in fact themselves representations of some abstract thing, and the URI really identifies that thing, not a document at all.
Well, that wasn't the model I had when URIs were invented and HTTP was written. However, let's see how it flies. If we stick with the principle that a URI (or URIref) must unambiguously identify the same thing in any context, then we come to the conclusion that URIs can not identify the web page. If a web page is about a car, then the URI can't be used to refer to the web page.
What, a web page can't be a car? At this point a pedantic line reasoning suggests that we should allow web pages and cars to conceptually overlap, so that something can be both. This is counterintuitive, as a web page is in common sense, not a concrete object whereas a car is. But sure, we could construct a mathematics in which we use the terms rather specially and something can be at the same time a web page and a car.
Frankly, this doesn't serve the social purpose of the semantic web, to be able to deal with common sense concepts and objects. A web page about a car and a car are in most people's minds quite distinct (as I argue further below). A philosophy in which they are identical does not allow me to distinguish between them. not only conflicts with reality as I see it, but also leaves us no way to make statements individually about the two things.
So lets fall back on the idea that the URI identifies the subject of the web page, but not the web page itself. This makes sense. We can build the semantic web on top of that easily.
The problem with this is that there are a large number of systems which already do use URIs to identify the document. This is the whole metadata world. Think of a few:
(I'm sticking with the machine-processable languages as examples because human-processable ones like HTML have a level of ambiguity traditional in human natural language but quite out of place in the WWW infrastructure -- or the Semantic Web. You can argue that people say "I work for w3.org" or "http://www.amazon.com/shrdlu?asin=314159265359" is a great book, just as they happily say "Moby Dick weighs over three thousand tons", "Moby Dick was finished over a century ago" and "I left Moby Dick on the beach" without expecting to be misunderstood. So we won't use human language as a guide when defining unambiguously the question of what a URI identifies. If we want to do that on the Semantic Web, we will say "I work for the organization whose home page is http://www.ww3.org.)
Some argue the the URI which I associate with someone's home page actually identifies that person. They argue that conventionally people use the identifier to identify the person. However, consider another page put together by friends who found a photograph of the same person. A lot of content filtering systems would collect that URI and put put into their list. Even though the photo had many representations which different devices could download using content negotiation and/or CC/PP (color or black and white and versions of different resolutions) the URI itself would be listed as containing nudity. The public are very aware of different works on the web, even though they have the same topic.
You can argue that a web page indirectly identifies something, of course, and I am quite happy with that. If you identify an organization as that which has home page http://www.w3.org, then you are not saying that http://www.w3.org/ itself is that organization. This scenario is very very common, just as we identify people and things by their "unambiguous properties": books by ISBN, people by email address, and so forth. So long as we don't think that the person is an email address, we are fine. Some people have thought that in saying "An HTTP URI can't identify an organization" I was ruling out this indirect identification, but not so: I am very much in favor of it. The whole SQL world, after all, only identified things indirectly by a key property. This causes no contradiction. Perhaps I should say "An HTTP URI can't directly identify an organization". But by "identify" I mean "directly identify", and "identity" is a fairly direct word and concept, so I will stick with it.
Conclusion so far: the idea that a URI identifies the thing the document is about doesn't work because we can only use a URI to identify one thing and we have and already do use it to identify documents on the web.
So what's wrong with the URI being taken to identify whatever the owner says?
Let's look at what we mean by identifies. When we say there is identity, that means that there is some form of sameness that we associate with the identifier. Now, for all the philosophical argument, we can never test the identity of an abstract thing. What we can test is a representation which has been returned by the server when given that URI. When we use aURI, and get back several possible representations of it, then what expectation do we have about those representations?
Take the test case that I see the web page which has a picture of a car, and I see in the URI in the URI bar in the browser. I email you the URI, "you see, the car is a Toyota?". You click on the link. Your browser shows the same URI as mine in the "URL bar" but you see a table of the car's weight, length, height, color, and registration number. We are confused. The web didn't work because you didn't get the same information as me. I expected you to get the same information, basically. That is how the Web works. That is the expectation behind every hypertext link - that the follower of the link should get basically the same information as the person who made the link. I say, "basically" because I would not have cared whether you saw or JPEG or a GIF. It probably wouldn't have mattered if you had seen a lower resolution or even black-and-white copy of the picture. If you are visually impaired, you may have been able to manage with a well-written description of the picture. But the the essential information is the same, not just the subject of the page.
So now we have put the four corners on the expectation we have of a URI -- that all representations have essentially the same information content. And what we mean by "essentially" allows in fact some wriggle room, and in the end it rests on a common understanding between publisher of the information and quoter of the URI. The sameness we are after is the sameness of information content. That is what is identified by the URI. That is why we say that the URI identifies that conceptual information content, irrespective of its particular representation: the conceptual work. Without that common understanding, the web does not work.
Some people have said, "If we say that URIs identify people, nothing breaks". But all the time they, day to day, rely on sameness of the information things on the web, and use URIs with that implicit assumption. As we formalize how the web works, we have to make that assumption explicit.
So how can we break free of that line of reasoning? We can try throwing away the rule that a URI identifies only one thing.
There are many levels of identification (representation as a set of bits, document, car which the web page is about) and the URI publisher, as owner of the URI, has the right to define it to mean whatever he or she likes.
Well, this one is tempting from the point of view that the
owner of an identifier should reign supreme when it comes to
saying what it identifies. It is quite a logically consistent
position to take. After all, isn't this the case with
uuid's? And for a new scheme, this would be
interesting. How can we do it though, with HTTP? the problem is
an engineering one: I can't in practice use a URI until I have
some definitive information from the publisher as to what it
identifies.
2.2.1 Default
Why can't a URI default to identifying a web page until you know otherwise? Because the web is open and you will never know when you might lean some other information which will make the default incorrect. (You can't use such "closed world" reasoning).
2.2.2 Web operation
Why can't a URI identify a web page until you have done some well-defined operation -- such as HTTP HEAD or GET -- and checked for information in that? Well, that would certainly work logically. Suppose we we define a return code or HTTP header which means "abstract object requested". It would mean that every web application which deals with web pages as web pages would actually be working under an ambiguity, and RDF processors could be programmed to look for that special information. We can't retrofit the millions of web servers out there, I assume.
I feel that there is a great benefit to fixing this question at the spec level. Otherwise, what happens? I read a web page, I like it and I am going to annotate it as being a great one -- but first I have to find out whether the URI my browser is used, conceptually by the author of the page, to represent some abstract idea? Before I recommend the Vietnam War page, I have to be careful I am not recommending the Vietnam War.
There has been no way to do this before RDF, but then similarly no real need for it. (What, is this just a problem with RDF? No, it will happen with any webized knowledge representation system.). We really need to have communication in which two people use the same URI to mean the same thing. If there
We could fix HTTP so that it would return me some extra semantic headers explaining the whole thing. And in the case that the URI was deemed to be some abstract thing, I would not have the option of recommending the web page. Too bad: it has no URI.
The authors of document <http://www.w3.org/2000/10/rdf-tests/rdfcore/Manifest.rdf> certainly thought that they could use "http://www.w3.org/2000/10/rdf-tests/TestSchema/NegativeParserTest" to identify an abstract thing which is a type of software test. Now they have a choice as to what to make the server return for them when I ask for it. It returns 404 "doesn't match anything we have available". It can't really, because HTTP doesn't allow one to return a class, only a document. And if it were to return a document, then I wouldn't be able to refer to that document without accidentally referring to the class of negative parser tests.
So, we could change HTTP to make this work. We could make a new form of redirect, 343 Abstract Object, please see . . ., which would tell the client that the thing requested was abstract, and would suggest a document to read about it. This avenue of argument is still outstanding. We could take it. It isn't the status quo, but we could make changes in HTTP if the community felt that this was they way to go.
Otherwise,we have to try another way of letting the URI mean sometimes one thing and sometimes another. Here is another.
Actually the URI has to, like in English, identify these different things ambiguously. Machines have to disambiguate using common sense and logic
This is possible in theory. It is a mess. It fails particularly spectacularly when a URI is used ambiguously to refer to a web page and the thing that web page is about, which happens to be another web page. Anyone can write anything about anything is a Web motto, but here it falls down. Anyone can write anything about anything except those things which might get confused with the document they are writing. It breaks the axiom that we mean the same thing by a URI - in all contexts. (And RDF has a model theory in which necessarily in any interpretation, a symbol always denotes one thing).
Actually the URI has to, like in English, identify these different things ambiguously. Machines have to disambiguate using the fact that different properties will refer to different levels.
One way of getting here is to start by considering that HTTP headers can be divided into those which refer to the representation (or the document) and those that refer to, say, a car or a donkey. We can look at all RDF properties and other attributes in other languages and divide them in in such a way. So, when I say "http://example.com/albert is a color photo", I am referring to the representation; when I say "http://example.com/albert used to work down the mill" I am referring to the person; when I say "http://example.com/albert was taken on a rainy day" I am revering to the original photograph, which is basically the representation of Albert.
This one has the problem when a web page refers to a web page. It can still be pursued, by having different verbs for talking about ownership of the web page and ownership of the car. This is a classic example of the 2-level syndrome (see also Dictionaries in the Library). The basic fallacy is that you can make the system general by introducing a second level - a new set of attributes, properties, or whatever, which allow you to refer to the metadata of something separately from the thing itself. These systems either turn out to be just limited 2-level systems (like XML and DTDs) or have to be extended to be recursive in some way later on such that in fact the two levels become unnecessary.
Actually the URI has to, like in English, identify these different things ambiguously. Machines have to disambiguate using extra information which will be provided in other ways along with the URI
This twist now relies on sending extra information with a URI. Effectively, the URI scheme has now failed to identify anything by itself. Those most familiar URIs as used by HTML sometimes suggested adding new attributes to the anchor tags of HTML documents to disambiguate a reference. I guess it would work if HTML anchors were the only uses of URIs. By contrast, they are used in thousands of places and way, many of which I am unaware. The architecture, however, is not that way: the architecture of the WWW is that a URI is a global unambiguous identifier. Not a URI and something else.
(The various designs such a WebDav's propfind which use HTTP methods apart from GET to retreive information suffer from this same problem. the information does not have a URI: it is not on the web.)
Actually the URI has to, like in English, identify these different things ambiguously. Machines have to disambiguate them by context: A catalog card will talk about a document. A car catalog will talk about a car.
This works in the short term, when the two contexts are disjoint groups who do not need to communicate. It is in fact the current state: the groups of people who use HTTP URIs to talk about documents, and those who have just started to use them to talk about abstract concepts haven't collided yet. (Well, they have in my code. I need to be able to model the metadata about an HTTP URI as that about a document, and it being a class at the same time doesn't jive.)
It doesn't work in the long term because it breaks the axiom that a URI must identify one thing,
They may have been used to identify documents up till now, but for RDF and the Semantic Web, we should change that and start to use them as the Dublin Core and RDF Core groups have for abstract concepts.
I think that we would have to design a new URI scheme before we change things that much. That is tempting of course. But then -- building a semantic web out of what we have is tempting too. It was tempting to rehash TCP a little when making HTTP. It wasn't practical, and we would have lost a lot more than we would have gained. There is a lot to be said for using common technology. We've got an infrastructure of documents. We want to build an infrastructure of knowledge. Let's build it using the documents. We might find that the commonality with the web of human-readable information is a boon.
An argument which surprised me is that yes, HTTP URIs identify documents, but in fact the frgament identifier must only be used to identify parts -- fragments -- of documents. This means that RDF cannot in fact use HTTP URI schemes at all. A completely different system would have to be put together -- either a new set of URIs, or RDF conventions in which the relationship to the part of a document in which something was described became explicit. In N3 this would like like
[ is rdf:referent of <#fmyCar> ] [ is rdf:referent of <#color> ] [ is rdf:referent of <#blue> ]
Of course, languages would quickly generate special syntax for this. Alternatively, the RDF system would built entirely on the understanding that we were referring always to that denoted by a given bit of document, not the bit of document itself. This would mean that there would be no way for the RDF system to refer to documents themselves directly.
This is actually a consistent way of working. It would be a change only for those people who use RDF to talk about documents as documents. We could change.
I didn't have this thought out a few years ago. It has only been in actually building a relatively formal system on top of the web infrastructure that I have had to clarify these concepts my own mind. I am forced to conclude that modeling the HTTP part of the web as a web of abstract documents if the only way to go which is practical and, by the philosophical underpinnings of the WWW, tenable.
I apologize again if I have misunderstood or misrepresented other's arguments in this process of this explanation of my own position.
Tim Berners-Lee
2002-07-28Z
Q: But surely, if a document is identified by a namespace URI, then when we look up an RDF namespace will millions of words in it we will have too long a document to be practical!
A: It is arguable, for such as situation, whether the namespace itself is more cumbersome to manage than the document is to deliver. You can make an analogy with hypertext: Isn't the model of retrieving a document going to be inefficient when the documents are huge? Answers are twofold in each case,
Firstly, yes it is likely to be less convenient, but that is no reason to skew which is a good engineering design for the vast proportion of namespaces (or hypertext documents) which are not huge.
Secondly, the HTTP protocol actually does have methods of retrieving parts of a large document.
Q: It seems strange that an HTTP URI should be limited to referring to documents, but that all one has to add is this little hash mark and suddenly you say it can be used to identify anything.
A: The hash is not a minor appendage to the URI: It is the most significant piece of punctuation in the whole URIref. The hash adds a whole new level of abstraction and specification! It is true that in a hypertext page and that page scrolled to a given point seem very similar. The same applies to a graphic chart and an object within that chart, especially when it is displayed in the context of the original document. So I suppose it may be a shock when the technique is used with a semantic web language to refer to not the document, but something which the document discusses. That does allow it to break out of the whole concept of documents and into -- anything. But no one promised the Semantic Web would be boring. :-)
Q: I thought you said "anything should be able to have a URI"?
Yes, and it should. There is nothing in the URI spec to say what an individual scheme should or should not be created to identify. A new URI scheme could for example be ale to identify anything. But here we are talking about HTTP URIs. And remember that with semantic web languages, you can use a URIref (very different from a URI) to identify anything, for example with HTTP and RDF.
Q: But what about CGI scripts? Surely you don't mean the HTTP URI identifies the script?
A: Of course not. When we talk about the "document" identified by a URI it is very often an virtual document produced by, for example, a CGI script. The URI identifies the document on the web, with no regard to the process which causes representations of it to be served.
Q: Some HTTP URIs can be POSTed to. Can you still say they identify documents?
A: Well, some HTTP URIs can't be accessed at all, and some access is not allowed, and yes, some URIs are not only documents but also can be posted to. So they object is more complex than simply a document. But that it has this extra functionality doesn't make it any less a HTTP document formally. Something can have extra features and still remain in the same class of things.
Q: What do you mean by "identify", anyway, in Model Theory terms? (2003)
The closest term used in Model Theory to the way I am using identify is denote. Model theory analyses communication and understanding by imagining a set of interpretations, where an interpretation is a mapping from a symbol to that which it denotes. Model theorists and linguists tend to complain that one cannot talk about the meaning of a term, as you can never know what anyone means by anything, you can only see how they react. A given agent may have many possible interpretations, but new information the agent believes which mentions a symbol will rule out interpretations with which are inconsistent with the symbol. By the process of exchange of a lot of information, one arrives at a state in which one behaves as though other agents has the effectively the same set of interpretations. Under these conditions, one can think of the thing identified by the symbol in the community as being the set of things denoted by the symbol in the interpretations which agents in the community are left with. There has been much more discussion of this process (which is the essence of the writing of a standard and the purpose of documents like this) in email on www-tag with Pat Hayes and others in 2003.
The rest are from Aaron SwartzQ: Can you point to something in the spec that says HTTP URIs must identify a document?
There are many answers. I can point to things which could be interpreted to say that. The HTTP spec defines resources as network data objects. To me that "data" indicates the information nature of the thing. It precludes, in most people's minds, a car or the Andromeda Galaxy.
I could explain that, as I originally wrote the HTTP spec, that was the author's intent.
But I think the fairest thing is to say that the spec was written it was not sufficiently clear about this particular ambiguity, and for reasons mentioned above, this hasn't been a problem until now.
Q: Isn't it a little weird to start making pronouncements about the entire HTTP Web when neither the spec nor the other TAG members agree?
Pronouncements about the whole Web are really important where they are needed. In that case the TAG has a duty to make them. And so do I. It seems to me that this assumption is one we have been implicitly making and are now breaking, in a way which will make the semantic web either inconsistent or much less efficient. The TAG members do not agree on this: that is why they asked my to write this document. It is written as a TAG action item about tag issue HTTPRange-14. Things get a lot weirder than that. ;-)
Q: Why do we need to use URI-refs to identify abstract concepts in a protocol where we can get more information about them? .I thought URIs were doing just fine. If we have to resort to UUIDs to identify things, I'll get annoyed because I won't be able to put them in my browser.
Well, there you are... you want to be able to put something in your browser, then you must have a representation of it. So somewhere in the picture, representations aside, is a ConceptualWork. If the ConceptualWork is important, then it needs a URI, in my opinion. The alternatives are attractive when you start to look at them, but each has a different snag. I have tried to explain above.
Q: How can you say that the Semantic Web can use the hash mark to make a URI-ref identify anything when the URI RFC is very clear that hash marks only work when you dereference the document.
I wouldn't say that hash marks "only work when you deference a document" any more than your street address "only works when I visit you", or your date of birth "only worked when you were born". I can use your street address -- or your data of birth -- to help identify you. What the spec defines is a way of using this particular URI to get some information over the Internet. The whole web works by what someone recently referred to as a "confusion" between name and address. It isn't a confusion. It is a connection between two pieces of architecture without which the web would not be. Rethink. It is primarily a name. We have made a way of looking it up. So you don't have to look it up for the name to "work" as an identifier. Just as you don't go and look it up when someone quotes the RDF namespace -- it works because the same identifier identifies the same thing in any context. Looked up or not. The same thing is true for foo#bar. If the document foo is never served, one can still (if one owns it) talk about foo#bar with authority. It is of course good practice to serve documents.
Q: Are all Semantic Web agents going to start dereferencing every document they hear about?
No, any more than you have to dereference every hypertext link you see.
Q: Isn't the Semantic Web broken if we have to start disagreeing with major specifications like this?
This philosophy is quite consistent with the HTTP spec as it is.
1) What does "http://www.amazon.com/exec/obidos/ASIN/0679600108/qid=1027958807/sr=2-3/ref=sr_2_3/103-4363499-9407855" identify?
When was the thing it identified last changed?
Have you read the thing it identifies?
2) What does "http://www.vrc.iastate.edu/magritte.gif" identify?

3) What does "http://dm93.org/2002/03/dans-car-23423423" identify?
4) What does "http://dm93.org/y2002/myCar-232" identify?
When was the thing identified last changed?
What does the writing on Dan's car say?
Answers: 1:3. 2:7 Note here the web tolerates vagueness along the axis of different representations of the same image, but not of semantic level between the image and the pipe. 3:1; 4:2
@@@links