 DB: Browsing Object-Oriented Databases over the Web
DB: Browsing Object-Oriented Databases over the Web
C. Varela,
D. Nekhayev,
P. Chandrasekharan,
C. Krishnan,
V. Govindan,
D. Modgil,
S. Siddiqui,
O. Nickolayev,
D. Lebedenko,
M. Winslett
Department of Computer Science
1304 W. Springfield Ave
University of Illinois
Urbana, IL 61801. U.S.A.
{
cvarela, d-nekha, p-chand, charuki, govindan, modgil, siddiqui, nickolay, dlebeden, winslett}@uiuc.edu
- Abstract:
- In this paper, we present some critical issues involving the
browsing of object-oriented databases over the World-Wide Web,
as well as performance results using our Database Browser
(DB) implementation.
First, given the statelessness of HTTP, we introduced a
dispatcher script architecture. In this architecture, a
CGI script communicates with an intermediate data server
connected to the database application, which keeps the
database open for faster future transactions.
Second, we used ODL, a standard object
definition language and we defined a simple intermediate
data format for moving database objects across the network.
And lastly, we defined five generic hypertext interfaces for:
a database schema, a class definition, a class query form,
a class extent, and a set of class instances.
We implemented these ideas
using ObjectStore with two database applications, one containing
university registration information and another one
containing electronic mailboxes. An important result was the
dramatic performance improvement gained by introducing our
Database Browser (DB) architecture.
- Keywords:
- World-Wide Web, Object-Oriented Databases, Dispatcher Scripts, ObjectStore, Object Definition Language, Common Gateway Interface.
- Contents:
-
- Introduction
- Background and Related Work
- Database Browser (DB) Architecture
- ObjectStore Examples and Performance Evaluation
- Conclusions
Six years after its conception in 1989, the World-Wide Web
is arguably the most popular and powerful networked information system
to date. Its growth in the past years has been exponential and it
has started an information revolution that will probably continue
to take place until the beginning of the next century. The databases
world with barely 25 years as a basic science research field
[Silberschatz et al. 91] is by no means
less interesting. Needless to say, these two worlds' encounter brings us
many new opportunities for creating advanced information management
applications.
In this paper, we present some critical issues involving the browsing of
object-oriented databases over the web. In particular, we present the
following topics:
- a dispatcher script architecture that answers traditional web
requests in a stateless fashion but keeps the database application
running across several transactions for improving performance,
- a simple intermediate data exchange format, and
- generic hypertext interfaces to object-oriented databases.
We implemented two exemplary applications: a university course
registration system and an electronic mailbox manager.
On the WWW server side, we used C/Lex/Yacc for the dispatcher
script and NCSA HTTPd [NCSA 93a], a high-performance
HTTP server.
On the database server side, we used C++ and ObjectStore
[Lamb et al. 91], an object-oriented database
management system, with a page-server architecture.
A remarkable result was the performance
improvement gained by incorporating the dispatcher script architecture, as
opposed to opening and closing the database server in every transaction.
The structure of this paper is as follows: in Section
2 we will give some background information and introduce related work.
In Section 3,
we will describe our Database Browser (DB) architecture.
Section 4 will show two object-oriented web database
applications in action and will present some performance results. This
paper concludes highlighting
some results and discussing further research issues.
The World-Wide Web [Berners-Lee et al. 92,
94] offers easy access to a universe of information by
providing links to documents stored on a world wide network of computers
in a very simple and understandable fashion. Much of its
success is due to the simplicity with which it allows users to provide,
use and refer to information distributed geographically around the globe.
Another important feature is its compatibility with other existing protocols,
such as gopher, ftp, netnews and telnet. Furthermore, it provides users
with the ability to browse multimedia documents independently
of the computer hardware being used.
The World-Wide Web consists of a network of computers which can act in two
roles: as servers, providing information; or as clients,
requesting for information. Examples of server software are NCSA HTTPd
[NCSA 93a] and Netscape Communication Server
[Netscape 95a], while examples of client software are
NCSA Mosaic [NCSA 93b] and Netscape Navigator
[Netscape 95b].
The World-Wide Web is based on the HyperText Transfer Protocol (HTTP,)
the HyperText Markup Language (HTML,) and Universal Resource Locators
(URLs.)
When the documents to be published are dynamic, like those resulting
from queries to databases, the hypertext needs to be generated by the servers.
For this purpose, there are scripts, which are programs that
perform conversions
from different data formats into HTML on-the-fly. These programs also
need to understand the queries performed by clients through HTML forms
and the results generated by the applications owning the data (for example,
a DataBase Manager System.)
For defining the database schemas, we used the Object Definition Language(ODL)
developed by the Object Database Management Group (ODMG) and specified
in [Cattell et al. 94]. The
ODL specification conforms to the Object Data model, characterized by the
following basic features:
- Object is the base model constructional unit;
- Objects with the same structure can belong to one type;
- Object characterized by its set of properties - attributes and
relationships to other objects;
- Object can have set of operations which is analog to member-functions
in object-oriented languages.
- ODL Object model supports multiple inheritance.
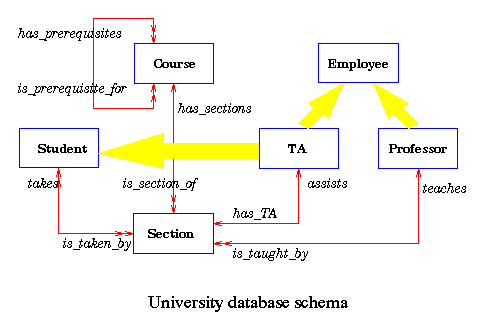
- As an example, the Professor class in this figure would be represented
in ODL as follows:
-
interface Professor: Employee {
extent professors;
keys name, id;
attribute string name;
attribute int id;
attribute string rank;
relationship Set<Section> teaches inverse Section::is_taught_by;
grant_tenure() raises (ineligible_for_tenure);
}
We refer the interested reader to the complete
University schema with all classes as defined in Cattell's book.
We have also annexed our
ODL specification for the Electronic Mailbox Manager.
3. Database Browser (DB) Architecture
In the first version of our hypertext interface to the object databases, the
database was accessed
through cgi-scripts which would open the database, process
the request and close the database everytime. We found that this sequence of
operations was extremely time-consuming and the response was very slow.
We reasoned that this slow response was due to the fact that
Objectstore has a page fault model with prefetch and thus, every time
the
database is opened, the pages containing the data are brought into
memory and the
pointers are swizzled. Under regular circumstances, this paging activity
would
only be a one-time startup overhead and the subsequent database
operations would be very fast. But, since the cgi-scripts are stateless,
(in the sense that they cease to exist after the operation is performed),
this overhead was being incurred on every database request. Each
request entailed a separate "open database, perform operation, close database"
sequence. We were thus
completely losing the performance gains of the paging model adopted by
Objectstore.
In our next and current version, we adopted the database browser (DB)
architecture as illustrated in the figure below. The main components of
this architecture are the dispatcher script, the intermediate data
server and the simple intermediate exchange format each of which are
discussed separately in the following subsections.
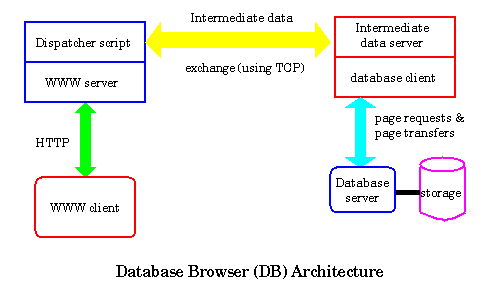
The dispatcher program is a CGI-script, the role of which is to
provide a user-friendly interface to query the database server and
to represent the database schema, extent and object data on the WWW browser
window. Separating this dispatcher from the database server is
beneficial for several reasons.
First, it allows us to keep the server active
even when the transaction is over, so the transaction performance
increases significantly.
Second, this architecture is conducive to customization of the whole
application. The database schema could be changed without causing any interference with the
user interface. On the other hand, the interface itself could be customized
without affecting the database server.
The dispatcher script consists of the following modules:
- 3.1.1. Request manager
This determines the type of the query and
references the appropriate routine.
- 3.1.2. Parser for the ODL schema
It parses the ODL schema
[Cattell et al. 94]
into a generic structure, suitable for handling any
ODL schema. This part was implemented using using lex and yacc.
- 3.1.3. Formatter of the query string
This part constructs the query string in the intermediate
format for the server.
- 3.1.4. Data Parser
Data, coming from the server, is parsed from the intermediate data format and put into the generic data
structure.
Hashing is used to speedup the search for appropriate field of the structure.
- 3.1.5. Data and extent display
Representation of object contents in HTML form.
This part not only displays data, but also
creates hyperlinks to related objects, superclasses, etc., in the same format as for actual queries.
- 3.1.6. Schema display
This part handles display of the schema of a particular class or shows all the
classes
with links to extent, query, or schema page.
- 3.1.7. Query page
This part handles the display of the page with the query form for each particular class.
- 3.1.8. Client routine
This routine makes a connection with the database server, sends the query and accepts the
result stream from the server for utilization by other routines.
The main characteritic of the intermediate data server is that it remains alive
across multiple requests and thereby eliminates the earlier problem of the
script ceasing to exist after every operation.
The data server was designed to use the standard BSD
sockets and to listen on a pre-determined port for requests. Whenever the
dispatcher script gets a request, it connects to the data server which
is listening for requests and sends the request in our own
simple intermediate data exchange format described in
the following section.
The server performs the database operation and
sends back the results using the same connection to the dispatcher
script. The dispatcher script in turn parses it and converts it to HTML.
This is then forwarded by the web server to the browser.
Thus the high startup overhead occurs
only on the first database operation (which we term as cold time) and
subsequent operations are relatively very fast (termed as warm time).
The server also keeps a queue of requests and therefore, multiple
simultaneous requests are handled serially by the server. The same
server can also be used to handle operations on multiple databases. This
is achieved through the liberal use of lookup tables to perform
name-to-object and name-to-function translations.
The intermediate object exchange format is used for communication
between the CGI dispatcher script and the intermediate data server.
It has two formats: query and data format.
Open-close request
- open database:
database_name;DBOPEN
- close database:
database_name;DBCLOSE
Actually the database server opens the database in response to any data request.
Schema request
- This is used to get the schema from the server.
database_name;SCHEMA
The ODL schema for the database is in a separate file, the server does not open
the database in response to this request.
Extent request
-
database_name;EXTENT
Instance request
- It is based on key values:
database_name;INSTANCE;class=class_name(&key_name=value_name)+
If the key is a composite key, there is a sequence of strings of the form
&key_name=value_name.
Query request
- It is based on attribute or relationship values:
database_name;QUERY;class=class_name(&property_name=property_value)*
Here again, (member)* designates zero or more strings
of type member.
For many of the object oriented databases, the data format
described here is sufficient. This format is based on attribute-value pairs.
In principle, it can be
augmented to fit multimedia data, but in our case, we have only used data in
text or numerical format. In these cases, attribute-value pairs is a
natural intermediate representation.
-
As a response to a query, the database server can return several objects.
In our format we use the line
%#%
-
as a delimiter between successive objects.
The format for an object looks as follows:
attribute_1_name: attribute_1_value
attribute_2_name: attribute_2_value
.
.
attribute_n_name: attribute_n_value
relationship_1_traversal_path: target_instance_1_keys
target_instance_2_keys
.
.
target_instance_n_keys
relationship_2_traversal_path: target_instance_1_keys
.
.
As we see, for attributes we give line-separated name-value pairs.
Attribute values can be complex text with newlines, special symbols, etc.
Ambiguities, may occur when the text of the attribute value at the
beginning of a line coincides with the following attribute name.
The intermediate data server resolves this special case by inserting
a space immediately after the newline.
We assume that the key value is a simple string or number and can not have
commas and newlines. The value part of relationship-value pair is newline-
separated list of keys of all target instances. Each element of this list is a
comma-separated list of all the keys of a particular target instance.
In case of EXTENT queries, the intermediate data server returns the data in a
brief format containing only keys to instances.
The dispatcher script has five different
formats to represent database schemas, query forms and data. We proceed to
describe all of them.
3.4.1. Introduction form
Its main purpose is to show the names of all the classes in the database
schema. Each class name is a hyperlink to the schema format for that
particular class. Additionally, there are three buttons for each class:
SCHEMA, which does the same job as the mentioned hyperlink, EXTENT, which
is a request button for all instances of this class
(presents only if extent is in the class definition),
and QUERY, which invokes the query form for the class.
The CLOSEDB button at the bottom serves to close the database explicitly .
3.4.2. Class schema
This page represents the schema of a particular class.
It has the following fields:
- Superclasses - list of all immediate parents of the class.
All names are hyperlinks to corresponding superclass.
- Subclasses - list of all immediate children of the class. All names are hyperlinks to the corresponding derived classes.
- Keys - list of all keys. As we noted before, keys can be
inherited.
- Attributes - list of class attributes. No inherited
attributes is shown.
- Relationships - list of traversal path names.
- Operations - list of operation names.
Additionally this page contains the EXTENT and QUERY buttons at the top.
3.4.3. Query form
The form consists of two main parts: a set of attribute entry
fields and the result filtering specification. By default, the result returns all
attributes and relationships of any particular class. The user can filter the
information by marking the corresponding checkbox.
3.4.4. Data browsing format
This page contains all user-specified fields of matching objects of a given
class.
Comma-separated list of keys of each target
object is a hyperlink to it.
This format does not show inherited properties if they are not keys.
The hyperlink with superclass name allows us to browse the superclass.
3.4.5. Extent format
This has a compact representation for displaying the extent of a class in
which instances instances are indicated by a
comma-separated list of object keys.
These keys have hyperlinks to request the complete instance.
This database was built using the example ODL schema given in the
ODMG-93 book. This demonstrates how an object database
specifed in ODL can be browsed in a generic manner and how one could
build a hypertext interface to navigate through the database. The university
database exemplifies many of the concepts specific to object-oriented
databases like inheritance, operation functions, inverse relationships,
exceptions, multiple inheritance, etc.
The database objects are the typical
entities in a university as illustrated in the schema
diagram and ODL specifications given in the subsection on
ODL. To run this example, please proceed to the
University
Schema presentation page.
This database was created to hold regular email, with particular
emphasis on huge mailboxes. The database mainly consists of two basic
objects, one is the message object and the other the folder object. One
can associate a multiple messages to a folder and also, a message to multiple
folders. A parser was written to parse a regular mail folder and put it into
the database. This database was created to evaluate the
performance of the browser with huge databases and to provide a
hypertext interface to a real-world application. To run this example,
please proceed to the
Mailbox Schema presentation page.
We instrumented the server to obtain the time spent on the various
operations. We measured the performance by taking the times to perform
various operations in different scenarios.
- Cold vs. Warm time - Cold time is the time taken for the
first request. This causes the database to be opened, the data to be
paged in and the pointers swizzled. Warm time is the time taken to
perform subsequent requests. In this case, the data is already in
memory. We performed this to measure the savings obtained by having the
data server which keeps the database open across multiple requests.
- Remote vs. Local request - By remote, we mean a physically very
distant machine. We obtained the time taken for queries made from a
local machine (within the university campus) and a machine in Japan
connected to the Internet through a 64 Kbps link.
We performed this to observe the effect of the network on the times.
- Large vs. Small database - This was performed to observe the
effect of the size of the database itself, on performance. A large
database occupies many more pages than a small one and this will have
effect on paging, swizzling etc.
- Large vs. Small result - This was performed to observe the
effect of the size of the query result on the times.
- Sunday vs. Weekday - We performed this to observe the effect
of network traffic and machine load on the timings.
All the times are for a single user performing queries, we did not measure
the performance with multiple, simultaneous requests.
The results of the performance measurements are summarized in the following
graphs.
4.3.1. Message extent in the mailbox database : (Large database,
large results)

In this case, the size of the result (about 400 KB) causes quite a
big difference in the times, especially in the remote case. We feel that the
network overhead (congestion, packetizing, etc) contributes to a major
part of the time taken. The slow speed of the link (64 Kbps) in the
remote case could also be a major cause for the delay, so a user over
a phone line would get an even slower response.
We thus conclude that network delays are certainly a factor to be
considered, especially for large query results.
4.3.2. Message instance in the mailbox database : (Large database,
small results)

In this case, the network did not seem to play any significant role as
in the earlier case. This could be attributed to the small size of the
query results (< 10 KB). The cold times are still significant as the
database itself is large and therefore, a lot of pages need to be
brought into memory at start-up.
4.3.3. University database : (Small database, small results)

In this case, the time taken is really small as the query results are
very small. Even the cold time is quite small since the database
itself is very small and hence, very few data pages would need to be paged
in.
We also observed that closing the database does not actually result in
a subsequent request taking a "cold time". This, we concluded was because
Objectstore has a page server model which means that even when the database
is closed, the data pages are still in
memory and are not reclaimed unless the data of some other application
is paged into the same place.
In this paper, we presented an architecture
for browsing object-oriented databases over the World-Wide Web.
This architecture consists mainly of a CGI dispatcher script, an
intermediate data server, a simple intermediate data format for
communicating between these two modules, and generic hypertext interfaces
for browsing different database elements. We found remarkable
performance improvements by using
this Database Browser (DB) architecture.
- The main reasoning behind our architecture is that opening an
object-oriented database is a time-consuming process that we didn't
want to repeat in every database transaction. Furthermore, HTTP is a
stateless protocol. As a consequence, we needed to introduce new
modules that answer database requests in a stateless fashion, yet
guaranteeing that the database stays open for future requests. These
modules are the CGI dispatcher script in
the WWW side and the intermediate data server
in the database side. We believe that this is the trend that
information providing servers will be taking in the future: having
proxy servers that pass the request down to specialized servers
such as: video servers, annotation servers, database servers, link
servers and so on.
- Furthermore, we defined a simple intermediate
data format for
exchanging information in a generic manner between the dispatcher
script and the intermediate data server. We found five basic
object-oriented database components: a database schema, a class
definition, a class query form, a class extent, and a set of class
instances. Then, based on these fundamental components, we defined
a format for the CGI script to query the server for each of these
elements, as well as a format for the data server to return these
elements to the script. Finally, we composed five generic hypertext
interfaces to these database elements, to present them to the clients.
- We implemented two database applications using ObjectStore: a
university registration system and an electronic mailbox manager. These systems served
as a testbed for our experiments.
There is a need for further work on additional query options, since
ObjectStore doesn't currently support OQL, the ODMG standard for OODB
queries. We would also like to investigate further presentation issues
for huge databases, as well as multimedia object handling.
We didn't consider in our study, security issues that would be
crucial in extending our database operations. Currently, we only
concentrated in browsing databases. There is a lot of
research that needs to be done in authentication and authorization
for databases operating in an open environment.
[Bina et all. 94] is a good study of some of these security
issues. They present a role wrapper-based framework, that
assigns roles to clients and controls their database access
according to these roles.
We believe that there is a need for more research and development
in advancing the state-of-the-art in performance and security for
connecting databases to the World-Wide Web. There are many
applications that could benefit from this research including
bibliographic databases, financial management systems, intelligent
agents, data mining applications and countless others.
We would like to thank Dan
Laliberte at NCSA for setting up our
HyperNews project page;
Mike Jerger for letting us use
bunny, the database answering machine;
Simon Kaplan for allowing
us to use ObjectStore; International
Systems Research, Tokyo and UMDS, Kobe for providing partial support
to the first author; and last but not least, the
WWW Organizing Committee for granting us a small extension to
submit this paper.
- [Berners-Lee 92]
- Berners-Lee T. The Hypertext Transfer Protocol. World-Wide Web
Consortium. Work in
progress. Available at
http://www.w3.org/hypertext/WWW/Protocols/Overview.html
- [Berners-Lee and Connolly 93]
- Berners-Lee T., and Connolly D. The Hypertext Markup Language.
World-Wide Web Consortium. Work in progress. Available at
http://www.w3.org/hypertext/WWW/MarkUp/MarkUp.html
- [Berners-Lee et al. 92]
- Berners-Lee T., Cailliau R., Groff J., Pollermann B.
World-Wide Web: The Information Universe.
Electronic Networking: Research, Applications and Policy, 2(1),
pp. 52-58, Meckler Publications, Westport CT, Spring 1992. Available
in PostScript at
ftp://info.cern.ch/pub/www/doc/ENRAP_9202.ps
- [Berners-Lee et al. 94]
- Berners-Lee, T. Cailliau, R., Luotonen, A., Nielsen, H. F., Secret, A.
The World-Wide Web. Communication of the ACM. Volume 37, Number 8,
August 1994.
- [Bina et al. 94]
- Bina E., Jones V., McCool R., and Winslett M. Secure Access to
Data Over the Internet. Proceedings
of the Third ACM/IEEE International Conference on Parallel and Distributed
Information Systems, Austin, Texas, September 1994. Available in PostScript
at
http://bunny.cs.uiuc.edu/CADR/pubs/SecureDBAccess.ps
- [Cattell et al. 94]
- Cattell, R.G.G., ed.
The Object Database standard: ODMG-93, Release 1.1. San Mateo, CA:
Morgan Kaufmann,1994.
- [Eichmann et al. 94]
- Eichmann, D., McGregor, T., Danley, D. Integrating structured databases
into the Web: The MORE system. The First International Conference on the
World-Wide Web, May 25-27, 1994, CERN, Geneva. Available in PostScript at
http://www1.cern.ch/PapersWWW94/more.ps
- [Kahle and Medlar 91]
- Kahle B., and Medlar A.
An Information System for Corporate Users: Wide Area Information Servers.
ConneXions - The Interoperability Report,
5(11), pp 2-9, Interop, Inc., Nov. 1991. Available at
http://www.w3.org/hypertext/Products/WAIS/Overview.html
- [Lamb et al. 91]
- Lamb C., Landis G., Orenstein J., and Weinreb D.
The ObjectStore Database System. Communication of the ACM.
Volume 34, Number 10, October 1991, pp 50-63.
- [McCool 93]
- Rob McCool. National Center for Supercomputing Applications,
University of Illinois at Urbana-Champaign.
Common Gateway Interface Overview. Work in progress.
Available at
http://hoohoo.ncsa.uiuc.edu/cgi/overview.html
- [NCSA 93a]
- National Center for Supercomputing Applications, University of
Illinois at Urbana-Champaign. NCSA HTTPd. A WWW Server. Work
in progress. Available at
http://hoohoo.ncsa.uiuc.edu/docs/Overview.html
- [NCSA 93b]
- National Center for Supercomputing Applications, University of
Illinois at Urbana-Champaign. NCSA Mosaic. A WWW Browser. Work
in progress. Available at
http://www.ncsa.uiuc.edu/SDG/Software/Mosaic/Docs/help-about.html
- [Netscape 95a]
- Netscape Communications Corporation. Netscape Communications Server.
A WWW Server. Work in progress. Available at
http://www.netscape.com/comprod/netscape_commun.html
- [Netscape 95b]
- Netscape Communications Corporation. Netscape Navigator.
A WWW Browser. Work in progress. Available at
http://www.netscape.com/comprod/netscape_nav.html
- [Ng 93]
- J. Ng. GSQL: A Mosaic-SQL gateway. National Center for
Supercomputing Applications. University of Illinois at Urbana-Champaign.
Work in progress. Available at:
http://www.ncsa.uiuc.edu/SDG/People/jason/pub/gsql/back/starthere.html
- [Perrochon and Fischer 95]
- Perrochon, L. and Fischer R. IDLE: Unified W3-Access to Interactive
Information Servers. The Third International Conference on the
World-Wide Web, April 10-14, 1995, Darmstadt, Germany. Available at
http://www.igd.fhg.de/www/www95/proceedings/papers/58/www95.html
- [Putz 94]
- Putz, S. Interactive information services using World-Wide Web
hypertext. The First International Conference on the World-Wide Web
(WWW'95), May 25-27, 1994, CERN, Geneva. Available at
http://pubweb.parc.xerox.com/hypertext/www94/iisuwwwh.html
- [Silberschatz et al. 91]
- Silberschatz A., Stonebraker M., Ullman J., eds.
Database Systems: Achievements and Opportunities. Communication of
the ACM. Volume 34, Number 10, October 1991, pp 110-120.
- [Sjolin 94]
- Sjolin M. A WWW Front End to an OODBMS. The Second International
Conference on the World-Wide Web, Oct 17-21, 1994, Chicago, Illinois, U.S.A.
Available at
http://www.ncsa.uiuc.edu/SDG/IT94/Proceedings/Databases/sjolin/sjolin.html
- [Varela and Hayes 94a]
- Varela C., and Hayes C. Zelig: Schema-based Generation of Soft WWW
Database Applications. The First International Conference on the
World-Wide Web, May 25-27, 1994, CERN, Geneva, Switzerland. Available at
http://fiaker.ncsa.uiuc.edu:8080/WWW94.html and in
PostScript at
http://www1.cern.ch/PapersWWW94/cvarel.ps
- [Varela and Hayes 94b]
- Varela C., and Hayes C. Providing Data on the Web: From Examples to
Programs. The Second International Conference on the
World-Wide Web, Oct 17-21, 1994, Chicago, Illinois, U.S.A.
Available at
http://www.ncsa.uiuc.edu/SDG/IT94/Proceedings/DDay/varela/paper.html