A Schema Based Approach to HTML Authoring
Marcus Kesseler
- Abstract:
-
This paper presents a novel approach
to high-productivity authoring of large, regularly-structured
hypertexts. By explicitly representing the objects in the hypertext
and the relationships between them in a schema, it is possible to
create, manipulate and maintain large hyperdocuments with high
efficiency. In the implementation, called the HSDL, all such schema operations
are performed on a graphical user interface (GUI). Special attention
has been given to the problem of schema evolution. In HSDL, the
author can do non-trivial schema update operations even if classes
have already been instantiated. The mapping from the schema to HTML,
called compilation, is done
by a series of programs in the programming language Scheme.
These programs, called expanders, are integral part of every
schema. Although the default set of expanders will already provide
fairly sophisticated HTML layout, users may easily adapt them to suit
their special needs.
A built-in, schema-aware HTML editor allows the integration
of links defined in the schema into the HTML contents of a node.
- Keywords:
-
Authoring Environments, Information Representation
and Modelling, Consistency, Integrity, Authoring-in-the-Large,
Schema Evolution, Hypertext Linearization
Introduction
Like Garzotto et al.
[7],
we would like to see the task
of producing large hypertexts split into two intertwined but
nevertheless clearly distinguishable activities: First, those that
deal with the hypertext on a per node basis, which is called
Authoring-in-the-Small (AIS), and second, those that deal with
structuring decisions on a larger scale, possibly encompassing
hundreds of nodes, accordingly called Authoring-in-the-Large
(AIL). AIS usually involves dealing with layout oriented problems,
or, in HTML, with local structuring decisions.
The general idea of schema-based AIL is best conveyed by a four step
procedure:
- The author models the objects that exist in the target domain,
ie, the domain the document is about, and the relationships that exist
between these objects. This model is called the class schema.
- Using the classes in the class schema as templates, the author
proceeds to create instances of the classes and instances of the
relationships in the instance schema. These operations are
fairly intuitive when performed visually on the
graphical user interface of the implementation.
- The author then proceeds to fill the as yet empty instances with
content. This is where AIS in the conventional sense is done.
- In a compilation step, the structural information in the schema
is merged with the contents of the instances and gets translated into
the target hypertext representation (HTML).
Of course, any approach that forces authors to proceed in such a
strictly top-down manner is completely at odds with the way that
authoring is actually done. Authoring, which is among the so
called complex design activities [12], is
an intrinsically opportunistic process. By this, we mean that authors
seldom adhere to schematic procedures while creating large documents.
Authors seem to randomly switch between contexts and levels (AIS,
AIL).
To develop this approach, a great deal of effort has been invested
to reconcile the inflexibility inherent in schema-based approaches
with the chaotic ways human authors usually go after their business.
The implementation, called HSDL (Hypertext Structure Description
Language), evolved from initial experiments with a programming
language into a full-blown visual hypertext authoring environment.
The Structure Description Language as such, although now invisible to
the user, lives on in HSDL as the base for the persistent schema
storage mechanism.
The rest of this paper is structured as follows: We give a more
detailed overview of the
schema and
the problems of
schema evolution.
We then proceed to show how a schema is
compiled into HTML.
After discussing
related work
in this area, we finish with our
conclusions
and
future research directions.
The Schema
The schema consists of an intentional description, the class schema,
and an extentional description, the instance schema.
The Class Schema
The class schema consists of classes and link-classes
between them. A class is a tree-structured composite object.
The objects in a class tree are called components. The top
component is called the root component. Consider the class
Painter in Figure 1:

Figure 1: The painter class
Painter has a root component of the same name, which has
the subcomponents Biography and Works.
Biography has two further subcomponents, called
Childhood and Adult Life respectively.
An arbitrary number of link classes may be defined between
any two components or even from a component to itself (see below).
Link classes are directed: We distinguish between the source
component and the target component of a link class.
The Instance Schema
The instance schema consists of instances and link
instances. All instances of a class are exactly alike, that is,
classes are used as templates that are always instantiated as a
whole. The nodes of an instance are called instance-nodes (or
i-nodes for short).
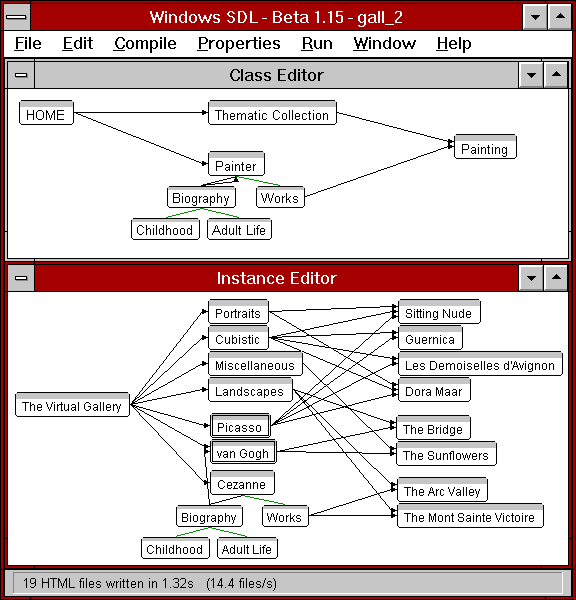
Figure 2: The class and instance schemas representing a gallery
Figure 2 shows an HSDL screen dump which contains the class and
instance schemas of a gallery. The gallery consists of three painters
and eight of their paintings. The paintings are also classified into
four thematic collections. Note that the instances Picasso and van
Gogh are not fully visible: the double frame around their root i-nodes
indicates that they are imploded.
Link Instances Induce Ordered Collections
Large hypertexts are often organized as hierarchies. It is common
practice to make the members of a set of nodes linked under a same
anchor node (e.g. the sections of chapter, the paintings of Picasso)
traversable by previous/next links.
We refer to such a set of nodes connected by previous/next links
as an ordered collection, or simply a collection. The anchor
node of the hierarchy is called the owner of the collection.
In HSDL we generalize the idea of an ordered collection, by specifying
that the order within a collection is not a property of the i-nodes
themselves, but rather of the link instances leading to them. A set
of link instances of the same link class coming from a same source
i-node is said to induce a collection of i-nodes. With this
definition, it is possible to embed an i-node into an arbitrary number
of collections. We move from hierarchies to true networks.
Furthermore, a link instance induces a collection in both
directions. The i-nodes that are the targets of a set of links from
a same source are said to belong to a target collection.
Likewise, the i-nodes that are the sources of a set of links to a same
target are said to belong to a source collection.
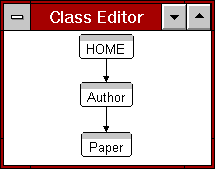
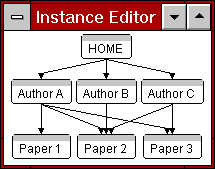
Figure 3:The Authors & Papers class and instance schemas
Consider the very simple class schema in Figure 3: A set of
authors and papers written by them are to be presented as a
hypertext. In the instance schema we have three authors (A, B & C)
and three papers (1, 2 & 3).
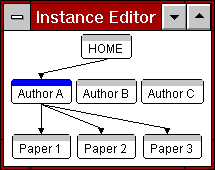
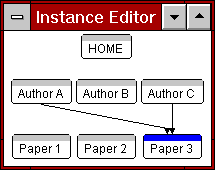
Figure 4: A target and a source collection
The left screen dump of Figure 4 shows the target collection of
Author A, i.e., A is author (or co-author) of papers 1, 2 & 3 (HSDL
has a display mode in which only the links into or from a selected
instance are visible). The right screen dump of Figure 4, shows the
source collection of Paper 3, which was written by A & C. Therefore,
the link instances of a single link class from Author to
Paper naturally induce a collection of papers in the target
direction ("Papers by this author") and a collection of authors
in the source direction ("Authors of this paper").
Anchors from an owner to a collection usually form an
index. By default, HSDL translates indices into the unordered
list (<UL>) HTML environment. By manipulating the anchor
expanders (see below) it is possible
to create a wide variety of layouts for such indices.
Changes to the order of a collection (i.e. sorting) is done by
drag-and-drop in the HSDL GUI. Since collections are defined by link
instances, reordering always occurs relative to a selected link
instance and therefore affects only one of the many collections the
instance may be part of.
Since authors may not want to include every possible hierarchy
as an explicit index into an HTML node, their generation can easily
be toggled in a link-class-properties pop-up menu. The same
applies to the generation of previous/next links.
The anchors that aid navigation within the members of a target
collection are organized into previous/up/next-triplets (or
previous/down/next-triplets for source collections). Consider
Figure 5, which shows the compiled HTML result for
the Dora Maar instance of Figure 2 in the NCSA
Mosaic browser. Dora Maar is a member of three collections:
It's a panting by Picasso and has been classified as a
Portrait and a Cubistic painting. Such crossing
collections are best visualized by color-coding the respective
triplets according to their owners. In Figure 5 the
up anchor of the first triplet, to Picasso, has been
compiled into an up-arrow icon, while in the other two triplets, both
to instances of Thematic Collection, have been compiled into
the owner's name. For simple changes to triplets styles HSDL offers
pop-up menus (e.g. Void, Arrow, Name, Name+Arrow, Color). For users
wishing to go further, expander programming offers the necessary
degrees of freedom.
It should be emphasized, that Figure 5 has no edited
contents whatsoever. All visible elements are HSDL
defaults. The "Painted by" label is entered by the
user during link class definition and therefore produces this layout
in all instances of Painting.
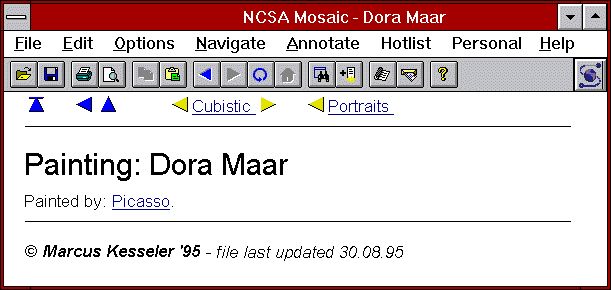
Figure 5: The Dora Maar instance in the NCSA Mosaic browser
Non-Hierarchical Links
Obviously, not all links in an hypertext will be hierarchical. One of
the main characteristics of hypertext is the ability to explicitly
represent associations between any two nodes in a network, completely
disregarding any overall structure the nodes may be embedded into.
With the slight restriction that every link is an instance of
some link class, it is possible to create such links without
introducing new concepts into HSDL.
Suppose that Cezanne's biography mentions that he was influenced
by van Gogh. Clearly, one would like to make the words "van Gogh"
into a link to the node representing van Gogh. In Figure 2 the class
Painter has a link class called Influenced by (link
class names are not visible in the screen dump) from
Biography to Painter. What at first looks like a
puzzling link class from a class to itself, works exactly how one
would expect on the instance level: As shown in the instance schema of
Figure 2, it is possible to link Cezanne's biography to van Gogh.
HTML anchors representing link instances are placed at default
positions before or after the HTML contents of an i-node, depending on
the current set of expanders. The built-in HSDL HTML-Editor provides
the means to override such default placements and insert anchors
anywhere into the HTML contents of an i-node. Link anchors can be
copied or grabbed: A copied anchor will still have a
duplicate at the default position. A grabbed anchor will be removed
from it. Whole indices can also be copied or grabbed.
Note that some authors (e.g. Conklin [5] and Garzotto et al. [7]) make a clear distinction between
organizational links, which span hierarchies, and
referential links, which allow random linking of nodes.
In HSDL this distinction becomes somewhat blurred. At first sight,
there really seems to be a great difference between the links from a
chapter to its sections and a link expressing that van Gogh influenced
Cezanne. On closer inspection, we find that the Painted by
links from a painter to his or her paintings, which though seeming to
carry much more meaning than an index of sections in a chapter, span a
completely analogous structure. Now, if our gallery had, say, six
painters that were influenced by van Gogh, even the instances of this
link class, which seemed to carry a lot of semantics, would start
looking like a collection (and hence hierarchy) of
painters. Therefore, as seen from the HSDL formalism, there is no
difference between referential and organizational links. Their
seemingly different semantic weight is in the eye of the beholder.
Referential Integrity and Fast Prototyping
The HSDL implementation enforces strict referential integrity on the
class and on the instance schemas. Therefore, it is impossible
to create a dangling link or to make parts of the schema inaccessible
(no orphans). Referential integrity is enforced by following three
simple rules:
- When a new class is created, a link class linking it into an
existing class has to be created along with it.
- When deleting a class, also delete all link classes leading into
or out of it.
- Class or link class deletions are not allowed if they make parts
of the schema inaccessible.
The same rules apply to the instance schema. Deletions in
the class schema are cascaded to the instance schema, that is,
when a class schema object is deleted, all its instances are also
deleted. If cascading a legal class schema deletion leads to an
inconsistent instance schema, the class schema deletion is declared
illegal and undone.
To efficiently enforce rules 2 and 3, the HSDL software
architecture includes a Change Manager. Aided by an
undo-stack, which records all schema changes that occur during
an editing session, the Change Manager implements the transaction
concept for schema update operations. Therefore, destructive
operations that lead to a referentially inconsistent schema are simply
rolled back.
The pop operation on the undo-stack is also available to the
user, thereby providing full undo capabilities within an
editing session.
Given that referential integrity is ensured, it is possible to
compile the schema into a working hypertext at any stage during
development. This has great advantages for fast prototyping, since an
author can generate hypertext skeletons very fast. Such
skeletons of HTML nodes, though devoid of edited content, contain
default anchors generated by HSDL and are therefore fully navigatable.
They are of great help to check if the design and structuring
decisions represented in a schema really mirror the author's intention
on the hypertext level.
Experienced HSDL users can create fully functional HTML skeletons
consisting of hundreds of nodes and links in a couple of minutes.
Heterogeneous Collections, Guided Tours and Multi-Link-Classes
As yet, there is one important feature missing in the expressiveness
of HSDL: The ability to create heterogeneous collections, that is,
collections composed of instances of different classes, which are
needed in two main modelling situations:
- Fine grained modelling:
- Suppose we want to model the
canonical "Article" hierarchy of sections and
subsections. As such, it presents no problem. But suppose we want to
go further and say that a subsection is composed of a random sequence
of paragraphs, figures or tables. With the HSDL indices presented so
far, it is not possible to insert a link to a figure between two
paragraphs. We would have an index of all paragraphs, followed by an
index of all figures and an index of all tables. Although we could
explicitely copy or grab the respective link instances into the
i-node contents, thereby "welding" them to fixed locations, this
unfortunately renders the link instances inaccessible to the
reordering operators provided by the HSDL GUI.
- Guided tours:
- Which are sequencial paths through random
subsets of i-nodes of an instance schema.
To tackle this problem, we extend the definition of link classes as
connecting a set of source classes to a set of target
classes. A link class where the source or the target class set has
a cardinality larger than one is called a multi-link-class. A
multi-link-class defined from {A, B} to {C, D, E} allows
for link instances from any instance of A or B to any
instance of C, D or E.
Figure 6 shows the "Article" schema with a multi-link-class from {Subsection} to
{Paragraph, Figure, Table}.

Figure 6: The article schema with a multi-link-class
Linearizing Hypertexts along Link Classes
The fine-grained model of the "Article" hierarchy down to single
paragraphs, as outlined above (Figure 5), raises a new
problem: A single paragraph is usually too small an information unit
to be presented as a hypertext node of its own. Ideally, one would
like to lump many paragraphs together into a larger unit. Taking this
idea one step further, it would be nice to linearize the whole
hypertext into a single, large document, mainly to make it
accessible in printed form.
To cater for this need, HSDL link classes and link instances have an
embedding mode. When activated, the location of the anchor in the
source i-node is replaced with the whole content of the target
i-node. Setting the link classes of some "main" hierarchy of a
schema into embedding mode, will linerize the whole hypertext. Note
that other, non-embedding, links remain fully functional within the
single "super" node (at least in HTML). HSDL checks for and
prevents attempts to create circular embeddings.
Schema Evolution
As mentioned above, authoring is an opportunistic process. Therefore,
to be acceptable, a schema-based approach has to provide a wide range
of operators that allow authors to revise schema design decisions. In
the database field this problem is known as schema evolution
[3].
In HSDL the following schema evolution operations are supported:
- Add a component to a class:
- All existing instances of
the augmented class are extended by a corresponding node.
- Reposition a component in a class:
- All existing
instances are restructured accordingly.
- Delete a component:
- The corresponding nodes are also
removed from all instances. Links defined on the deleted component
are moved up to the deleted component's parent.
- Re-class an instance:
- An instance can be made to change
class. If the instance is source or target to link instances for
which no equivalent link classes exist in the new class, corresponding
new link classes will be inserted automatically.
- Re-anchor a link instance:
- The source and/or target
i-nodes of a link instance can be moved to new i-nodes. If no link
class exists between the components corresponding to the changed
i-node, a new link class will be inserted automatically.
- Transitive derivation of link classes:
- A pair of
transitive link classes can be used to derive a new link class
(e.g. A->B and B->C ==> A->C). On the instance schema new
link instances corresponding to the inner product between the existing
link instances are inserted.
- Triangular derivation of link classes:
- From
A->B and A->C derive B->C or C->B, depending on the
user's choice. Again, on the instance schema new link instances
corresponding to the inner product between the existing link instances
are inserted.
- Split a class into two new classes:
- Any component of a
class, except the root, may be selected to become a class of its own.
Any subcomponents of the selected component as well as any link
classes into or from these components are also carried over to the new
class. A link class between the new class and the source class is
created automatically. All instances are also split accordingly.
- Merge two classes into a new class:
- If, first, two
classes have exactly the same number of instances and, second, there
is a link class between the two classes, the link instances of which
form a bijective (one-to-one) mapping between the instances, then it
is possible to merge the two classes along this link class (target
moves into source). If the target component is not a root component,
the target class will continue existing but the target component will
migrate over to the source class.
Compilation into HTML
The translation of a schema into HTML is controlled by a series of
programs in the programming language Scheme [1]. These programs, called
expanders, can be attached to any object in an HSDL schema. As
an example, consider the default expander that generates the visible
title of an HTML node:
(define (title node)
(emit "<H1 ALIGN=CENTER><B>"
(name (class node)) ": " (name (instance node))
"</B></H1>"))
The n-ary function emit writes all its arguments into
the HTML file corresponding to the node that is currently being
compiled. The function name generally returns the name of an
HSDL object as a string. The functions instance and
class respectively return the instance the node belongs
to and the class that the node is an instance of.
Applying the expander above to the root node of the instance
Picasso of class Painter would generate the HTML
title:
<H1 ALIGN=CENTER><B>Painter: Picasso</B></H1>
Expander Shadowing
Since expanders can be attached to any HSDL object, it is easily
possible to customize the appearance of certain classes or even
instances. If, for example, we attach the following (re)definition of
the title expander to the class Painting
(define (title node)
(emit "<H3>" (name (instance node)) "</H3>"))
then this new expander will shadow the global one defined
above, and the title of the painting The Sunflowers will be
expanded into:
<H3>The Sunflowers</H3>
Instead of shadowing, we could also say that unless an expander is
locally defined, it will be inherited from the higher schema
levels.
To start translation into HTML the following function is called in
turn for each node of the current schema:
(define (generate node)
(header node)
(body node)
(footer node)
(for-each generate (included-children node))
(if (not included?) (signature)))
Compilation is incremental, that is, after an initial full
compilation only changed instances are translated into HTML files.
Note that expander programming is not necessary as long as the
default expanders built into the system produce acceptable HTML
structures (and hence layout). Only users wishing to adapt the
structure to their own needs will have to deal with expander
programming.
Mapping I-Node Trees to Files
Some hypertext systems support composite nodes, that is, nodes that
have internal addresses which can be directly jumped to. Since HTML
is also in this category, we are offered the possibility of mapping
composite HSDL instances to a smaller number of HTML files than the
instance has i-nodes. Consider the class Painter of Figure 1:
in a hypertext system without composites, each component would be
mapped into its own node (or file). In systems which do support
composite nodes, we might insert all five components into a single node,
separating them by appropriate visual cues (rulers, titles, etc).
To support this feature, HSDL components and i-nodes have an
inclusion status, which may be set to included or
excluded. If all i-nodes of a painter are included, HSDL will
linearize the tree depth-first and generate a single composite HTML
file. If they are all excluded, HSDL would generate five HTML
files. Since inclusion is a property of each individual node, any
mapping from a composite node to one or more HTML files is possible.
In every case appropriate navigation is ensured by the insertion of
the necessary link anchors.
By default, the i-nodes of an instance inherit the inclusion
status from the respective components. Therefore, it is possible to
change the mapping of all instances of a class by modifying the
inclusion status on the class schema. On the other hand, the user can
override the inherited status for individual i-nodes.
HTML nodes are saved in a directory tree. The names of the
directories and HTML files try to reflect the schema as much as
possible. For example, the root i-node of the instance van
Gogh of class Painter in the schema Gallery is
written into the HTML file gallery/painter/vangogh.htm.
HTML Anchor Generation
During compilation links have to be translated into HTML anchors. To
this end, the HTML string ultimately building the anchor is divided
into seven parts:
- The anchor prefix html-prefix, which, to generate the
index of a collection, would be typically set to the string
"<LI>" so that it will appear as a list item in a
corresponding HTML environment.
To create such an HTML environment we distinghish between the
first html-prefix in an index and all the following ones. For
example, to start an HTML enumeration with a header displaying the
name of the link's target class in "<H4>" size, the
first prefix is set to the string returned by the evaluation of
(string-append "<H4>"
(name (class (target link)))
"</H4><OL><LI>"))
The HTML anchor start tag and attribute ("<A
HREF=\"").
The URL (generated by HSDL).
The SGML close tag (">").
The anchor label html-label, which in indices is set
to the string returned by the evaluation of (name (target
link))) so that the name of the corresponding node will be
inserted. Of course, any legal HTML anchor label is permissible. The
ubiquitous previous/next links between members of collections or
hierarchies will usually have iconic labels, often images of arrows.
To do this in HSDL, the link label expander is simply set to something
like "<IMG SRC=\"images/arrow-lt.gif\">".
The HTML anchor end tag ("</A>").
The anchor trailer html-trailer, which will usually
be used to set punctuation marks after labels. For example, setting
the prefix to the empty string "" and the trailer to
", " will produce a comma separated list of anchors in an
index.
In analogy to the special first prefix in a collection, the
last trailer in a collection is different from all preceeding ones. It
is therefore easily possible to close HTML environments. The last
trailer in an enumerated list will then consist of the string
"</OL>".
To compile a link into an HTML anchor the function
expand-anchor is called with the link as parameter:
(define (expand-anchor link)
(emit (html-prefix link) ;; 1 Anchor prefix
"<A HREF=\"" ;; 2 HTML start tag
(html-href link) ;; 3 Link target address
"\">" ;; 4 SGML close tag
(html-label link) ;; 5 Anchor label
"</A>" ;; 6 HTML end tag
(html-trailer link) ;; 7 Anchor trailer
))
Related Work
HDM
Garzotto et al. have shown the importance and the feasibility of
using a schema-based approach to AIL in several applications of their
Hypertext Document Model (HDM)
[7].
The HDM schema, though, includes a much larger number of concepts
than the HSDL schema. In HDM there often are many ways to
model identical access structures. The lack of orthogonality can
significantly raise the complexity of the implementation, especially
with regard to schema evolution problems.
It is unclear, if HDM has been implemented up to the GUI level
and if users can adapt hypertext generation to their own needs. HDM
is used to generate ToolBook (Asymetrix Corp.) applications
[2]. To our
knowledge HDM has not yet been ported to generate HTML.
MacWeb
MacWeb, by Nanard & Nanard
[9]
[10]
, also uses a class schema (called a Web
of Types) and an instance schema (the MainWeb). It has a
GUI (for MacOS) and a scripting language (WebTalk). MacWeb
generates an internal hypertext format browsable with the MacWeb
viewer.
MacWeb aims to provide the means to capture knowledge about the
target domain that will be used at runtime to generate documents
dynamically. Dynamic documents are adapted or even created at runtime
under the control of the author's WebTalk scripts.
Such an approach could also be applied to HTML. Instead of WebTalk
scripts one would have to generate programs for whatever is the
scripting language of the respective WWW server. Portability would be
strongly restricted, since it is not (yet) possible to intertwine HTML
with code (although HotJava's Java language surely is an interesting
possibility in this context).
Notice that in such approaches the problems of hypertext authoring
are augmented by the problems of programming (debugging, runtime
errors, etc). Programming expanders in HSDL is on a completely
different level, since they are used solely to generate HTML. After
compilation, an HSDL-generated hypertext is a standard HTML application.
Schema updates are much more complex if they are to transform the
hypertext structure and the semantics of the attached scripts
consistently.
To our knowledge MacWeb has not yet been ported to generate HTML.
Text to HTML Translators
As yet, the only tools supporting AIL in the HTML world were text
to HTML translators. Such systems exist for a variety of text
formats. Two of the most popular are WebMaker [13] (originally from CERN, now
available from Harlequin Inc.) and LaTeX2HTML [6] by Nikos Drakos.
Text to HTML translators start from a linear document and
translate the ubiquitous part/chapter/section hierarchy into a
corresponding HTML hierarchy. Only anchors supporting navigation
within this hierarchy are generated automatically (e.g. previous,
next, up, contents). References within the text (e.g. citations) are
also translated over to functional HTML anchors, but such links
cannot be counted as automatically generated, they are merely
translated. It is possible to embed HTML anchors into the text, but
such links are created individually and the author has no global view
onto the current net topology. Therefore, it is probably an arduous
task to embed nodes into multiple hierarchies.
One of the advantages of the text to HTML approach, is that a high
quality paper version of the same hypertext will by definition always
be available. In HSDL we follow the reverse route to achieve the same
effect: We start from a network of nodes and produce a linear paper
version by specifying the linearization hierarchy afterwards.
Complex schemas will often have a whole range of possible
linearization hierarchies. The text to hypertext approach does offer
this level of flexibility.
Conclusion and Future Work
We believe that the HSDL schema-based approach to HTML authoring of
large hypertexts offers the following advantages:
- Easy creation and maintenance of complex access structures:
- True networks (not just hierarchies)
- Operations on whole sets of links
- Inherent referential integrity
- Fast prototyping
- Two level representation: Class schema (intentional representation)
and instance schema (extensional representation)
- Advanced schema evolution operators
- Classes work like coarse-grained templates, enforcing coherence
over sets of nodes representing objects of the same kind
- Large parts of the layout and, more importantly, of the access
pathways are generated automatically from structural information
- The embedded extension language Scheme allows for full
customization of the generated HTML structure and hence layout
- Layout changes applicable to whole sets of nodes at a time
- Easy linearization of hypertexts
- Powerful Graphical User Interface
- Built-in schema-aware HTML editor
Several medium-scale projects employing HSDL are currently under way.
Most of them are commercial applications revolving around technical
documentation and business-to-business WWW marketing. We are looking
forward to report on our and our users' experiences in the coming
months.
Future Work
The interfaces between the internal HSDL modules (formalism, GUI,
persistent storage, compiler, etc) have been carefully crafted to
provide a maximum of orthogonality. The multiple inheritance
capability of the implementation language CLOS (see below) has been essential to achieve this goal.
We see the current HSDL implementation as the kernel of a
system extensible in various directions:
- Support for CSCW (Computer Supported Cooperative Work):
-
Obviously, the edition of large hypertexts will often be the task of a
whole group of authors. Hence, we have to deal with the
synchronization problems typical of CSCW. We believe that the easiest
way to achieve this is to use a database as the persistent storage and
the database locking mechanisms to enforce consistency.
- Versioning:
- The need for effective version management
for large bodies of information is de rigueur for any system
claiming AIL capabilities. Like for CSCW, using a database as
persistent storage should provide a firm foundation for the extension
of HSDL with version management.
- Improved Instance Schema Editor:
- The current instance
schema editor (see Figure 2) is not really well suited for AIL. A
screen containing hundreds of interconnected items will always look
clogged, no matter how cleverly they are arranged.
In the short run we will be implementing an instance browser
inspired on the class browsers usually found in object oriented
programming environments (e.g. Smalltalk, CLOS).
As a medium term goal, we think that the article on fisheye
views by Sarkar and Brown [11] offers some intriguing
perspectives well worth exploring.
Appendix: Miscellaneous Implementation Details
- Persistent Schema Storage:
- The schema is stored in an SGML
file, tagged with a custom HSDL DTD.
- Implementation Language/Platform:
- HSDL was implemented
in CLOS, the Common Lisp Object System, in Allegro Common Lisp for
Windows (ACL/W 2.0) by Franz Inc. HSDL has been tested under Windows
3.1, Windows95 and Windows NT.
- Performance:
- In a typical application, the compiler
will generate approximately 10 HTML files per second when running on a
90MHz Pentium processor (8MB RAM).
This paper has been produced with HSDL. A meta-hypertext
describing the corresponding schema and some further HSDL features can be found at
http://faui80.informatik.uni-erlangen.de/IMMD8/staff/Kesseler/www4meta/home/ahyperte.htm
.
References
1. Harold Abelson and G. J. Sussman.
Structure and Interpretation of Computer Programs. MIT Press,
Cambridge, 1985.
2. Andrea Caloini. Matching Hypertext Models to
Hypertext Systems: a Compilative Approach. In Lucarella et al.
[8],
pages 91--101.
3. Jay Banerjee, Won Kim, Hyoung-Joo Kim, and Henry
F. Korth. Semantics and implementation of schema evolution in
object-oriented databases. In Proceedings of the ACM SIGMOD
Conference, 1987.
4. Emily Berk and Joseph Devlin, editors.
Hypertext/Hypermedia Handbook. Software Engineering Series.
MGraw-Hill Publishing Company, 1991.
5. J. Conklin. Hypertext: An introduction and
survey. IEEE Computer, 20(9):17-41, 1987.
6. Nikos Drakos. From text to hypertext: A post-hoc
rationalisation of LaTeX2HTML. 1994. (Available via WWW UCSTRI
Computer Science Index: http://www.cs.indiana.edu/ctr/search).
7. Franca Garzotto, Paolo Paolini, Daniel Schwabe,
and Mark Bernstein. Tools for Designing Hyperdocuments,
pages 179--207. In Berk and Devlin
[4], 1991.
8. D. Lucarella, J. Nanard, M. Nanard, and P.
Paolini, editors. ACM Echt 92: Proceedings of the ACM
Conference on Hypertext. ACM Press, 1992.
9. Jocelyne Nanard and Marc Nanard. Using Structured
Types to incorporate Knowledge in Hypertext. In Proceedings of
the Hypertext '91 Conference, pages 329-342, 1991.
10. Jocelyne Nanard and Marc Nanard.
Should anchors be typed too? an experiment with MacWeb.
In Proceedings of the Hypertext '93 Conference, pages 51--62,
1993.
11. Manojit Sarkar and Marc H. Brown.
Graphical fisheye views.
Communications of the ACM, 37(12):73--84, December 1994.
12. Norbert Streitz, Jörg Haake, Jörg Hannemann, Andreas Lemke, Wolfgang
Schuler, Helge Schütt, and Manfred Thüring.
SEPIA: A Cooperative Hypermedia Authoring Environment.
In Lucarella et al.
[8], pages 11-22.
13. The Harlequin Group Limited. WebMaker
Users's Manual, 1995.
About the Author
Marcus Kesseler
http://faui80.informatik.uni-erlangen.de/IMMD8/staff/Kesseler/kesseler.html.
University of Erlangen-Nürnberg
IMMD VIII - Artificial Intelligence
Am Weichselgarten 9 / D-91058 Erlangen / Germany
email: kesseler@immd8.informatik.uni-erlangen.de