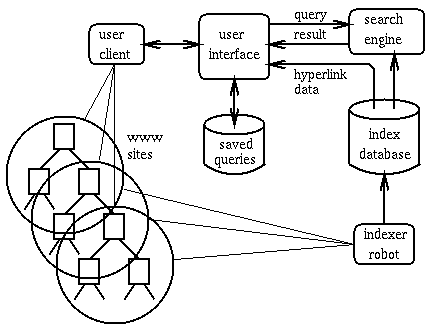
Figure 1. The WWW Resource Discovery System's architecture.
As with other applications on the Internet that are distributed in nature, the WWW is highly diversified and is ever changing in a non-coordinated way. An ideal search tool should be able to keep track of such changes, detect any inconsistencies caused by independent local modifications, and organize information into a structured index which enables efficient search. Such an index can substantially reduce network load since users need to access only the index data in order to locate resources. In this paper we present a WWW resource discovery system which employs a so called Web robot to build and maintain an index database for keyword searching. This approach, as opposed to manual indexing, is suitable for the size and the dynamical nature of the WWW environment.
The issue in the design of a keyword-based search tool is how effective the tool can meet the user's information needs. This involves the choice of the search algorithm and the user-system interaction component. In our previous work, we have studied a number of document search and ranking algorithms for the WWW environment. From our empirical evaluation, we concluded that TFxIDF algorithm which is based on word distribution outperforms other algorithms which rely on WWW hyperlink information [15].
No matter how good the search and ranking algorithm is, however, it does not guarantee that the documents or WWW pages with high relevance scores are actually relevant to the user's information need. Such discrepancies may be due to ill-defined queries, such as too few/many keywords resulting in too specific/general queries, problems related with synonyms and homonyms, or the user's unfamiliarity with the subject he/she is interested in. One of the approaches to alleviating this problem is by means of a relevance feedback mechanism, i.e., an interaction between the user and the system to iteratively refine a query until a desired set of retrieved documents is obtained. In this paper, we present a relevance feedback mechanism which is supported by the user interface component of our system. The mechanism expands the previous version of a query by adding certain keywords extracted from WWW pages marked as relevant by the user.
There is, however, a problem with the above scheme, namely judging which WWW pages retrieved by the search engine are relevant requires the user to access and read through the actual pages, which can be time consuming. Even if the user has the time and patience to do so, it may not be easy to fully make sense of the contents of the individual pages without examining the context at the neighboring pages. The reason is that in hypertext environments such as WWW's, a document or page is often only a small chunk of a larger discourse formed by a network of interlinked pages. Our system's user interface component alleviates this problem by presenting the search result in a hierarchical page map which shows the links among the hit pages and the links with the neighboring pages.
While different users may have different information needs, it is often desirable to share one user's discovery with other users who may find it interesting. To facilitate such information sharing, our index server allows any user to save his/her query statement on the server's side so that other user or the user him/herself can reuse it later. This mechanism can also save other users time to perform query refinement themselves.
The remaining of the paper is organized as follows. In section 2, we provide a detailed description of the components of our WWW resource discovery system, namely the indexer robot, the search engine and the user interface. Section 3 discusses lessons learned from the trial run of the system, particularly regarding its retrieval effectiveness, hypertext mapping capability and usability, and the issue of system scalability. Section 4 closes this paper with brief comparisons with other work and conclusions.
Figure 1. The WWW Resource Discovery System's architecture.
The index consists of a page-ID table, a keyword-ID table, a page-title table, a page modification-date table, a hyperlink table, and two index tables, namely, an inverted index and a forward index. The page-ID table maps each URL to a unique page-ID. The keyword-ID table maps each keyword to a unique keyword-ID. The page-title table maps every page-ID to the page's title. The page modification-date table maps every page-ID to the date when the page was last visited by the indexer robot. The hyperlink table maps each page-ID with two arrays of page-ID's, one array representing a list of pages referencing the page (incoming hyperlinks) and the other array representing a list of pages referenced by the page (outgoing hyperlinks). The inverted index table maps each keyword-ID to an array of <page-ID, word-position> pairs, each of which represents a page containing the keyword and the position of the word (order number) in the page. This word-position information is used in query by phrase, or keyword-order specific search, and the relevance feedback mechanism. The forward-index table maps a page-ID to an array of keyword-ID's representing keywords contained in the page. This forward index is used in the search algorithm, i.e., for computing the occurrence frequency of a word in a document, in the relevance feedback mechanism, and in various index maintenance functions. To obtain a fast access speed, hashing method is used to index each of these tables on the page-ID or keyword-ID attribute.
In extracting the keywords, we exclude high-frequency function words (stop-words), numbers, computer specific identifiers such as file-names, directory paths, email addresses, network host names, and HTML (Hypertext Markup Language [3]) tags. To reduce storage overhead, the indexer robot only indexes words enclosed by HTML tags indicating tokens such as page titles, headings, hyperlink anchor names, words in bold-face, words in italic, and words in the first sentence of every list item. We assume that a WWW author will use these tags only on important sentences or words in his/her WWW pages. Thus, these words make good page identifiers. This is one of the advantages of adopting SGML (Standard General Markup Language), of which HTML is a subset. Words chosen as keywords are then stemmed by removing their suffices.
Resources using protocols other than HTTP (FTP, Gopher, Telnet, etc.) or in formats other than HTML text file (non-inline image, sound, video, binary, and other text files), click-able image maps, and CGI scripts are indexed by the anchor texts referencing them.
Periodic maintenance of the index files is performed bi-weekly by the indexer robot. First, the indexer robot checks the validity of every URL entry in the database by sending a special request to the WWW server containing the page to check whether the page has been modified since the time it was last accessed by the indexer robot. This special request, known as HEAD request, is a feature supported by HTTP. Non-routine index maintenance is also supported. This is performed at night in response to user requests received during the day to index new pages (URL's) or re-index updated pages. Such user requests are facilitated by an HTML form provided by the user interface component (to be discussed later).
The indexer robot has the capability of detecting looping paths, e.g., those caused by Unix symbolic links, and does not visit the same page more than once unless the page has been modified since the time it was last visited by the robot. The latter is made possible by supplying the last access date and time into the HTTP request (using the If-Modified-Since request header field). As specified in the HTTP specification [2], the remote WWW server will not send the page content in response to the request if the page has not been modified since the specified time. Furthermore, the indexer robot will not even send an HTTP request if the page was last accessed by the robot within the last 24 hours. This is to prevent the robot from sending more than one HTTP requests for the same page during a maintenance batch. To prevent itself from roaming around uncontrollably from one server to the next, the indexer robot accesses one site at a time and only references within the same site domain as that of the referencing page are traversed. Finally, the indexer robot supports the proposed standard for robot exclusion(1) which prevents robots from accessing places where, for various reasons, they are not welcome.
The indexer robot is written in the C language. All index files are implemented using the GNU GDBM Database Manager library package [9].
Footnote 1: <http://web.nexor.co.uk/users/mak/doc/robots/norobots.html>
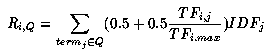
where TF(i,j) is the term frequency of term(j) in document(i), TF(i,max) is the maximum term frequency of a keyword in document(i), and IDF(j) is the inverse document frequency of term(j), which is defined as in Equation 2 below:
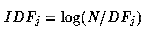
where N is the number of documents in the collection, and DF(j) is the number of documents containing term(j).
This term weighting function gives higher weights to terms which occur frequently in a small set of the documents. As shown in Equation 1, the term weight is normalized for document length, so that short documents have equal chances to be retrieved as longer documents. In our earlier work [15], it was shown that vector length normalization [13] does not work well for the WWW environment.
Given a query, the search engine computes the scores of WWW pages in the index, and returns at most the top H pages, where H is the maximum number of hits. By default H is set to 40, although the user can set it to a different value if so desired. Since the index database contains all of the information needed for ranking, the ranking process does not have to access any WWW pages physically.
The search engine supports Boolean constructs which make use of & (logical AND), | (logical OR), and brackets (scope marker) notations. To accommodate user who are not familiar with Boolean constructs, it allows the keywords to be separated by white spaces, which are treated as logical AND operators. Hyphens may also be used as keyword separators to specify phrases for keyword-order specific searching.
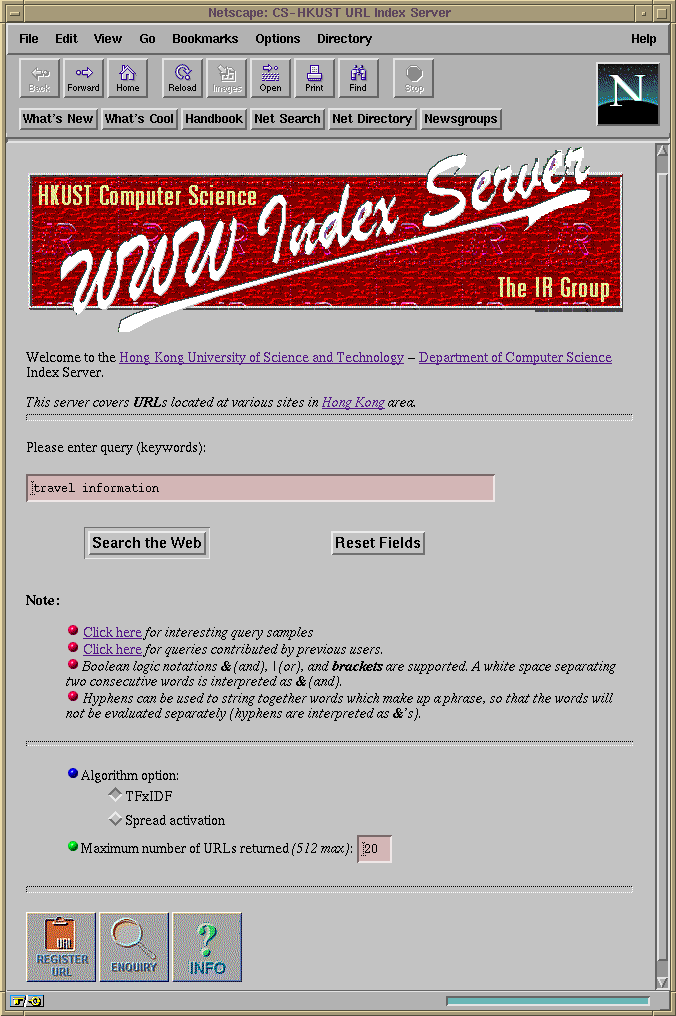
Figure 2. The home page of the WWW Resource Discovery System's
user interface.
After the user types in the keywords, the query can be sent to the search engine by clicking on the Search the Web submit button. Upon receiving the result from the search engine, the user interface displays a list of URL's and their respective titles ordered in descending relevance scores. The user can physically access these URL's by clicking on the titles. In addition to the above ordered list, the result page also shows other information and buttons for various functionalities, which are described in the following paragraphs.
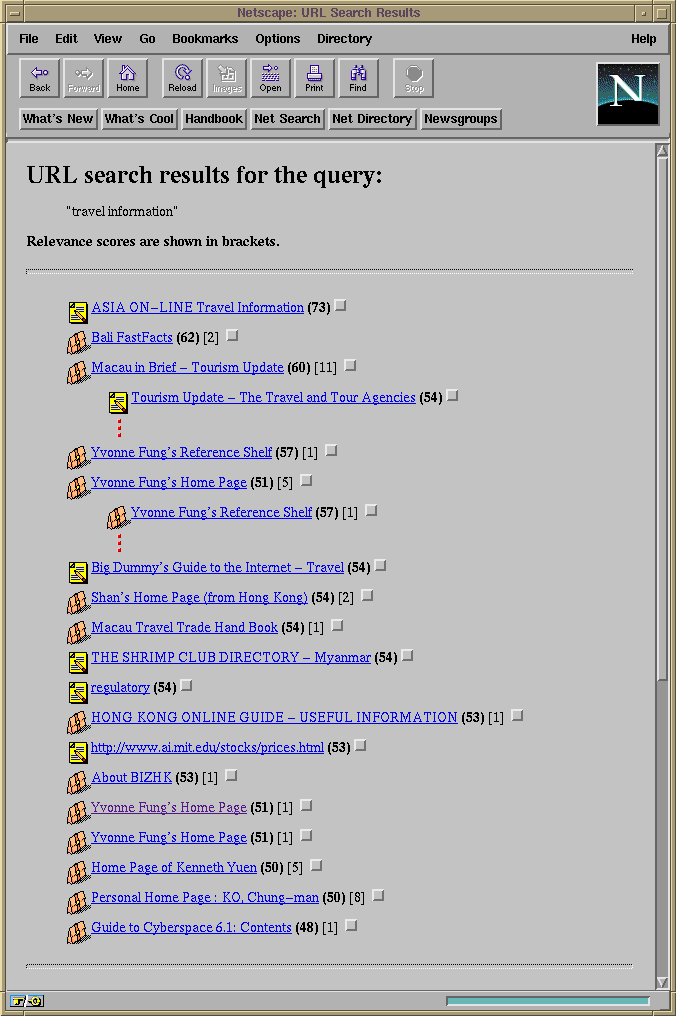
Figure 3. The result page displaying a list of hit pages
(represented by their titles) ordered in descending relevance scores.
Line indentation is used to depict hierarchical dependence relationships
among the pages.
Accompanying each of the page titles an icon is shown indicating the page's data format (image file, sound file, video file, etc.) or one of two special icons representing an expandable item (closed suitcase) and a shrinkable item (open suitcase) respectively. Figure 4 shows the page icons and their meanings.
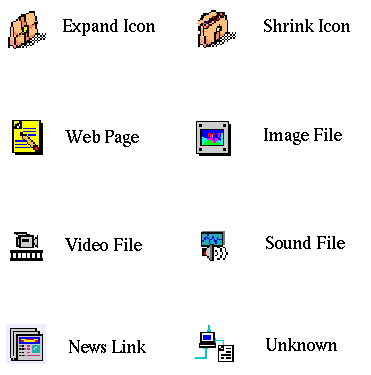
Figure 4. The page icons and their meanings.
When the user clicks on a closed suitcase icon, a new result page is then displayed with the WWW pages referenced by the page whose icon was clicked on, shown as a list of titles with line indentations under the title of the referencing page. At this point the referencing page is shown with an open suitcase icon. Clicking on this open suitcase icon will revert the result page to its original state, i.e., shrinking the result by removing child pages under the referencing page whose icon was clicked on. This expand/shrink operation is performed by the user interface using the hyperlink data available from the index database. Figure 5 shows an example of the result page after a page expansion operation.
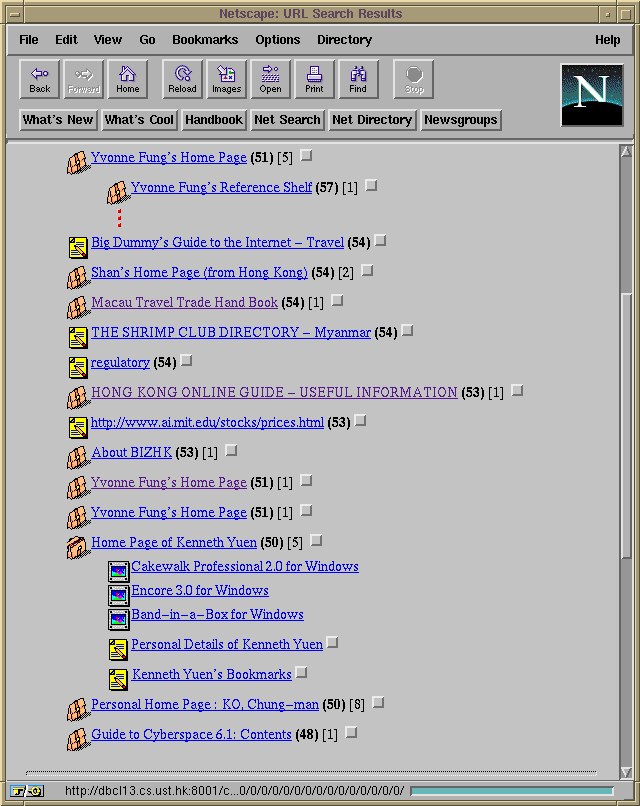
Figure 5.
The result page after a page expansion operation by the user's clicking
on the icon of the page entitled "Home Page of Kenneth Yuen".
In this example, the page entitled ``Home Page of Kenneth Yuen'' is expanded into a group with five child pages. In addition to the page icons, the number of pages referenced by each hit page, referred to here as child pages, is shown in square brackets. Because the use of the hierarchical organization, where hit pages are shown in groups with their child pages, the ordering of the hit pages on the list is based on the maximum relevance score within each group (see Figure 3).
The user can physically access any of the pages displayed on the result page by clicking on its title. Finally, the system keeps track of the user's session state by assigning a unique page-ID to every result page it generates. Every request issued by the user's clicking on a click-able item on a result page is tagged with the page's ID. The system maintains the information associated with every page-ID for a period of time.
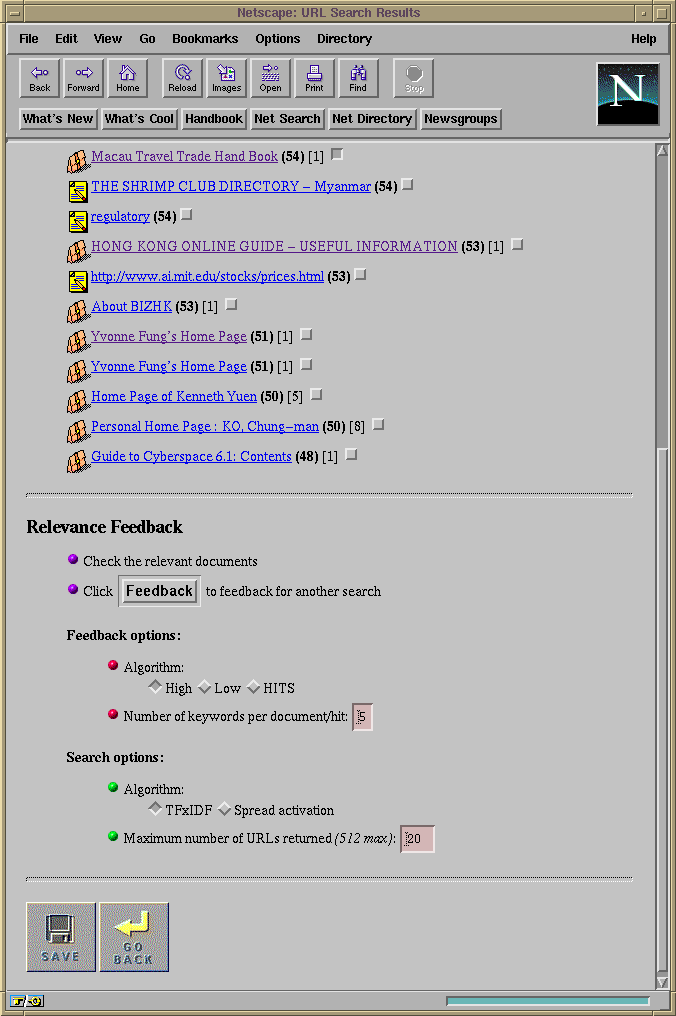
Figure 6. The relevance feedback form.
First, the user is asked to mark WWW pages judged as relevant to his/her query by clicking on a check box button next to each of the pages' titles. Next, the user can select the query expansion algorithm to use, if so desired, by clicking on one of the radio buttons under the algorithm option. The algorithms supported are as follows:
As in the home page, search options for selecting the search/ranking algorithm and specifying the maximum number of hits are also provided. Finally, the relevance feedback parameters are submitted to the system for processing when the user clicks on the Feedback button, and another result page is then shown. We are aware of the fact that providing the user with so many options can cause some confusion. In the prototype version described in this paper, all parameter setting options are made available to the user for the purpose of experimentation.
The user interface component consists of two separate modules, one for handling page expansion/shrinking operations and the other for handling the relevance feedback mechanism. These modules are written in the C language and run as CGI scripts.
We also learned from the access log that most users did not attempt to refine their queries, e.g., by adding or dropping keywords, to narrow down or broaden up the scope of their searches when we expected them to do so. However, we cannot tell what happened without any verbal protocol data. It may be that the user lost interest in the search, or the user already found what he/she was looking for, or our system was too clumsy to interact with, or the user was not familiar enough with the keyword searching process to be able to fine-tune the query. The latter pessimistic view may also be the reason why, as the log file showed, not many users try to use our relevance feedback mechanism. This observation is not something new to those who work with systems which employ advanced information retrieval techniques. Even constructing a boolean query with logical notations is not something that an average user can be expected to do.
Another possible explanation for such under utilization is that the users are overwhelmed by the number of parameter setting options presented to them. One of the solutions to this problem is to hide as many parameter setting options as possible in separate pages or pull-down/pop-up menus. Other usability techniques, such as single-line help technique which shows a single-line description of the item pointed by the cursor, can also help. However, implementing these techniques on the server's side, as opposed to on the client's side, is not practical. Ideally, functionalities such as hypertext mapping and relevance feedback mechanism should be implemented on the client's side, where the client down loads the necessary data from the server and performs the computation locally. This scheme will also make better display techniques, such as graphical hypertext maps with fish-eye view [14] or zooming capabilities, possible.
The main design objective of our hierarchical page maps is to provide efficient means for the user to identify a WWW page by showing its context, represented by links to the neighboring pages, and the data format of the page, without having to physically access the page and its neighboring pages. This approach can help preserve the network's bandwidth and save the user time to load the pages, especially on slow networks or from busy servers.
Our hierarchical page maps use page titles, for lack of better representation, to represent the contents of WWW pages. The problem with this scheme is that some page titles do not reflect the contents of the pages they represent. Also, it is not uncommon to find a group of pages, usually within the same directory path, to have the same title. Still some other pages do not have titles for various reasons. Obviously, a better page representation scheme is needed to make this approach effective. One possible alternative is to use keywords. Another related design issue is how to make the representation concise yet meaningful enough to be displayed, possibly in graphical format, as network nodes in a hypertext map.
For the above reason, we strongly advocate a system of distributed index servers with minimal overlapping coverages (e.g., by regional division). We are currently working on a mechanism which facilitates interchange of meta information among autonomous distributed index servers such that each of these servers can redirect a query to another server which can potentially gives a better result. This approach is similar to that of other server indexing methods such as GLOSS [6] and directory of servers in WAIS [7]. Upon receiving a query, an index server checks whether it should process the query or redirect it to other index servers which can potentially give better results. A simple communication protocol is used by the servers to exchange server keywords with each other.
Not many index servers use sophisticated information retrieval models beyond a simple Boolean model or pattern matching based on Unix egrep (e.g., WWWW), with exception of the RBSE, the WebCrawler, and Lycos. The RBSE uses WAIS search engine which ranks WWW pages based on the occurrence frequencies or term frequency (TF) of the query words [10]. The WebCrawler and Lycos, as with our search engine, rank the pages based on term frequency and inverse document frequency (TFxIDF).
Footnote 1: <http://lycos.cs.cmu.edu/>.
Footnote 2: <http://www.stir.ac.uk/jsbin/js>.
Footnote 3: <http://www.cs.colorado.edu/home/mcbryan/WWWW.html>.
2. Berners-Lee, T., ``Hypertext Transfer Protocol,'' Internet Working Draft, 5 November 1993.
3. Berners-Lee, T., and Connolly, D., ``Hypertext Markup Language,'' Internet Working Draft, 13 July 1993.
4. Berners-Lee, T., Cailliau, R., Groff, J., and Pollermann, B., ``World Wide Web: The Information Universe,'' Electronic Networking: Research, Applications and Policy, v.1, no.2, 1992.
5. Eichmann, D., ``The RBSE Spider - Balanching Effective Search against Web Load,'' in Proceedings of the First International Conference on the World Wide Web, Geneva, Switzerland, May 1994.
6. Gravano, L., Tomasic, A., and Garcia-Molina, H., ``The Efficacy of GLOSS for the Text Database Discovery Problem,'' Technical Report STAN-CS-TR-93-2, Stanford University, October 1993.
7. Kahle, B., and Medlar, A., ``An Information System for Corporate Users: Wide Area Information Servers,'' Technical Report TMC-199, Thinking Machines, Inc., April 1991.
8. Lee, D. L., and Chuang, A. H., ``Performance of Document Ranking and Relevance Feedback,'' (submitted for publication).
9. Nelson, P., ``GDBM - The GNU Database Manager,'' online manual pages, Version 1.7.3, 1990.
10. Pfeifer, U., Fuhr, N., and Huynh, T., ``Searching Structured Documents with the Enhanced Retrieval Functionality of freeWais-sf and SFgate,'' Computer Networks and ISDN Systems, v.27, no.7, p1027-1036, 1995.
11. Pinkerton, B., ``Finding What People Want: Experiences with the WebCrawler,'' in Proceedings of the First International Conference on the World Wide Web, Geneva, Switzerland, May 1994.
12. Salton, G., Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer, Addison-Wesley, Reading MA, 1989.
13. Salton, G., and Buckley, C., ``Term-Weighting Approaches in Automatic Text Retrieval,'' Information Processing & Management, v.24, no.5, p513-523, 1988.
14. Sarkar, M., and Brown, M., ``Graphical Fish-Eye Views of Graphs,'' in Proceeding of CHI '92: Human Factors in Computing Systems, ACM Press, New York NY, p83-92, 1992.
15. Yuwono, B., and Lee, D. L., ``Search and Ranking Algorithms for Locating Resources on the World Wide Web,'' (to appear in Proceedings of ICDE'96).