Figure 3: A tree of versions with a branch of nodes selected out
Fabio Vitali
David G. Durand
This paper describes VTML (Versioned Text Markup Language), a markup language for storing document version information. VTML can easily be implemented within a text editor, and provides a notation and semantics for tracking successive revisions to a document. The main purpose of VTML is to allow asynchronous collaboration in the creation and editing of text documents. This is based on our previous work [Maioli] [Durand] in systems and models for version control for hypertext.
Version control allows different instances of the same document to coexist, enabling individual and comparative display as well as automated or assisted merging and differencing. Version control systems are routinely used in many fields of computer science such as distributed DBMS [Coulouris], Software Engineering [Tichy], hypertext [ECHT] and CSCW. VTML is a general versioning language allowing for a large number of different applications in all these fields, and particularly in the joint editing of hypertext documents such as those available on WWW.
Naturally, most authors are not going to give away disk space so that others can revise their work, but with VTML it is possible, in principle, to enable universal write access on the web. With VTML's ability to store changes externally to a document, it is possible for someone with access to the web to publish correction or update documents that create a new version of another author's work stored separately. Access control for derived works becomes a matter of who has access to the relatively small server resources needed to make changes available. The author and the author's server do retain an imprimatur to mark revisions as "official." Such free access raises two fundamental requirements: consistency and accountability.
Consistency is a problem since the meaning of a link depends on the state of the document that it refers to. When documents are edited or revised, locations change, potentially destroying a record of what text was linked. Even if the link is translated to the corresponding part of the new document, the meaning may have changed significantly enough to make the original link and comment meaningless or incorrect. The use of symbolic identifiers avoids the problem of shifting text locations, but is, practically, only available to an author, since the original document must be changed to create the link destinations.
Accountability is the question of who is responsible for a document, and while always important, it is even more critical in the case of documents with multiple authors, or successive versions. A reader needs to know who has authored a document, whether the document was modified, and, if so, by whom.
In a versioned context, both consistency and accountability can be managed much more easily. The most important characteristic of versions is that they are immutable: rather than overwriting old data as simple file systems do, new versions are simply added to the repository, superseding, but not replacing their previous versions. This guarantees that links to old versions are always accessible, and that they are always in context (temporally as well as spatially). Since links frequently remain relevant in later versions of a document, it is also desirable that data locations are tracked through successive versions of a document, so that current location of externally-stored links can be determined.
Accountability is enhanced because each server is responsible for the versions or updates it stores, and can retain any author or group identification information desired. VTML provides specific ways to record this information, so that, every change made to a document can be tracked to the person who made it.
Versioning also provides a solution to the problem of addressability, identified by Engelbart Since once needs to be able to refer to any point in a document from outside that document, there must be a way to deal with change, or at least mitigate its effects. Because versions are immutable, they are addressable across time, even as the document they relate to evolves. This also means that any convenient structural addressing scheme can be used to reference within a versioned document, whether character offset in a file, or path specification through a structured tree. All are safe to use, as the navigational procedure for that version is fixed forever. This is the key that allows document information to be stored outside the document itself and makes it possible to externally create and manage resources such as external modifications, annotations, external links (like HyTime's ilink[DeRose], chunk inclusions, private links, and documents of links (e.g., paths and guided tours). These facilities incur no update cost: no explicit update of external references is required when changing the referenced document, since the external references are all grounded by the persistent addressing schema provided by the versioning system.
It is important to bear in mind that this solution handles the problem of references to document-internal objects. Fully persistent references depend on a location-independent naming scheme. VTML does not address this latter problem, though it is compatible with, and indeed, depends on, such a scheme. For the World Wide Web, the URN (Universal Resource Name) protocols under development within the IETF will provide such an infrastructure.
VTML associates every editing operation on the document with a specific version and each version with its author and the date on which it was created. The division of labor between client and server is simple. Document creation and editing happens locally (users work on their own computers), asynchronously (there is no requirement for immediate notification of the users' actions), and in parallel (all users can work on the same document independently, creating their own separate revised versions). These features make both simultaneous (as in GINA [Berlage]) and non-simultaneous collaborations possible. The delta-based nature of VTML also helps keep storage size reasonable, as constant data is generally not duplicated between versions. The deltas recorded are, however, expected to reflect the actual editing operations performed by users, rather than solving the expensive problem of the minimum space to store differences between versions. We believe the changes stored should reflect what actions were actually performed on the document, in order to be truly meaningful to users of the system.
VTML data is stored in markup tags alongside the affected data, or externally in separate documents. The simplest VTML implementation is as a preprocessor that interprets VTML tags, producing a stream of characters for some other processor or protocol. For instance, to display a requested version, the document and its external resources can be read and parsed, and the content of the requested version created on the fly. VTML can store versioning information on anything represented as a linear document, but is particularly suited for distributed hypertext documents such as those created by collaboration on the WWW. VTML makes it possible to display selected versions (both subsequent and alternative ones), compare them and merge them.
The purpose of this paper is to describe the uses of a versioning system in a cooperative environment for joint editing of written texts--particularly HTML and SGML documents. In Section 2 a number of issues regarding collaboration in a versioned environment are described, and in section 3 the versioning language VTML is introduced, with a brief description of its syntax and features and a discussion of version numbers and VTML applications.Version management has a number of effects on collaborative editing and linking of documents. We are concentrating on asynchronous collaboration, that occurs over a long enough time (days to years) that collaborators will need to work in isolation as well as cooperatively. In particular we assume that the machines being used by collaborators cannot count on constant availability of a link to other collaborator's machines. This parallel asynchronous collaboration, leaves the greatest freedom of interaction to the collaborating team.
We also consider and define our view of the fundamental nature of a versioning system. Versioning systems, besides providing useful tools for the management of the complex and dynamic evolution of documents, also gracefully allow asynchronous parallel collaboration, thus becoming a fundamental tool for joint editing.
But, even more importantly, versioning creates a persistent addressing scheme on versioned documents, which is fundamental for sophisticated uses of references. We will examine the ways in which these immutable addresses can be fully exploited in the context of a hypertext system like the WWW.
A number of collaboration models are possible, for group and distributed editing:
A versioning system is a software module that maintains an identity relationships between different instances of a single data object. Each instance is a version of the object, and is connected to the other versions in a possibly complex structure of ancestors, descendants and siblings. Documents are thus shaped as a sequence, or a tree, or a directed acyclic graph of versions, so that the content of any desired version is determined by the operations performed on the sequence of nodes connecting it to the root of the derivation.
A versioning system allows parallel asynchronous collaboration, since it facilitates the display of differences between several subsequent versions of a document (time-based versioning), or the tracking of modifications between several different variants of the same version (author-based versioning). Furthermore, by allowing automatic merging, it makes it possible to build a single final state of the document as the result of several parallel contributions, making the collaboration converge to a single state as it would with the other kinds of collaboration.
Since version editing never impacts other users' activities, the check-in operation of a private version can happen at any time after several versions have been produced. Thus, it is possible for a user to download a working draft locally, work on it several times, produce several successive versions, and then send the final one or the whole set of them back to a server where the official copy of the document is stored. Furthermore, emergent collaborations become possible. Any user having read access to a document can create a modified version of it and submit it to the original authors, who may decide to put it in the set of official versions. Becoming part of the group of authors of a document is thus possible at any time, even for someone not known to the author previously.
A versioning system allows distribution of a team over a large-scale network without inherent scale problems in the number of authors, available documents or involved servers. It can avoid many standard techniques such as locking and replication of objects or synchronization and serialization of operations. It would pose minimal constraints on the distributed system in terms of network load, maximum allowable number of collaborating partners, client-server interaction patterns, among other factors.
Another important advantage for hypertext versioning systems is the management of the persistent relationships of a versioned object. This is particularly important for hypertext: links are the explicit mark of an existing relationship between two given data objects. When either of the two objects is modified, the relationship needs to change as well. HTML has both ends of the link stored along with the data they refer to (the <A HREF> and <A NAME> tags), so that the update of the links is automatically performed when the documents are changed.
However, requiring internal storage of this kind of relationship has several drawbacks: basically, it is necessary to have write permission on a document to insert new relationships. Thus, it is impossible for us to add an internal HTML link, a comment, or new content to a document, unless we own it.
Even if a browser allows us to add new data to a document by storing it locally (i.e. externally to the document), there still would be a key consistency problem: if the original copy of the document is changed, the references stored locally are no longer valid, because the position they refer to has moved.
VTML offers a solution based on a simple consideration on versions: the addresses of the chunks of every version of a document are unique, global, stable, and independent of the addresses of chunks inserted in alternative versions. Furthermore, they may be derived from the addresses of previous versions, by recording successive edits performed in the meantime (such as insertions, deletions and modifications), or, when this is not possible, through a sufficiently effective diff mechanism on the two versions [Neuwirth].
This means that, by storing the successive operations that were done on the document, we are able to build persistent addresses of chunks in any version we are interested in. Furthermore, operations that do not belong to the chain of versions we are interested in may be stored as well: as long as it is possible to determine that they are irrelevant to the desired versions, they and their associated data can be completely ignored.
Being able to compute the position of any chunk in any version of a document means that references need not be modified when the document is changed and a new version is created. Instead, the current values can be computed when they are needed. References can be stored externally and independently of the document: it is possible to make local references to remote documents or to readable documents on which we have no write permission.
In hypertext, external references allow point-to-point (or span-to-span) links to be stored separately from the document they refer to. Point-to-point links are extremely useful in several situations where the length of the document cannot be decided arbitrarily (for instance, when using electronic instances of long linear texts such as traditional books).
External links are also ideal for implementing private links: users will be able to create personal point-to-point links on public documents, and store them on their computers. Links are always consistent, do not use public disk space, and do not clog public documents. We believe that all other solutions for private links have greater drawbacks than external links on versioned documents.
Finally, external references provide the basis for a truly useful inclusion facility: users are not limited to including whole documents, but can specify parts of them, being confident that the correct part will be retrieved again no matter what has happened to the document since the inclusion was specified. This form of inclusion is more like Copy and Paste, where the source of the data is still available, the source can be displayed, the data is not actually duplicated, and the data can be requested to modify and update according to what has happened in the source document in the meantime. The form of inclusion provided by versioning and subsumes the functions of intelligent Copy&Paste and Hot and Warm links.
VTML is a markup language designed to attach version information to the chunks of a document. Since every chunk is the result of a modification operation performed to one version, VTML tags identify the modifications themselves.
VTML information is supposed to be read by a parser before the visualization of the document. The parser will filter the content of the tags depending on the version. VTML data is printable, human-readable, and easily recognizable. In particular, VTML tags are put into SGML comments, so that they can be ignored by unaware tools.
VTML stores information on two editing operations: INSertions and DELetions. Support for other operations (particularly MOVe and SUBstitute) is possible and could be easily added to the grammar and the current implementation when needed.
VTML encloses all tags with the strings <!--{ and }-->. <!-- and --> enclose SGML comments, and are ignored by HTML browsers and SGML tools. This makes it possible to store versioning information, and yet have it ignored by unaware tools.
A VTML document is contained within a VTML tag. Many different
documents can be contained in a single file, each enclosed in a VTML tag.
The attributes of this tag define general characteristics of the document.
They are:
INS and DEL tags are stored within the document to which they refer, and attach version information to the text contained within the tag.
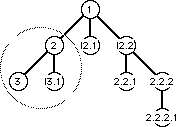
Inserting data means adding new data at a given position of the document. The new data is added at the point of insertion and is a successor of the version that inserted its immediate context. Deleted data is simply located and labeled. No modifications are possible to deleted data in any version that is a descendent of that version. Any alternate versions whose deletions overlap with each other are required to break up the deleted ranges to create a properly nested tree of insertions and deletions. A picture of such a tree is shown in Figure 1. Each consistent selection of tags creates a complete document when displayed.
Figure 1: A depiction of the tree of modification tags
Deleted chunks are not removed from the document, but are flagged as deleted and ignored during display. Thus, the internal tags of a VTML document typically contain all the data necessary to compute the content of any version of the document, and not merely the ones making up the most recent one.
Since persistent addresses of independent variants are independent, it is possible to store side by side information about incompatible versions regardless of their order. It is thus possible to maintain a complete set of tags of all existing versions of a document, even when they belong to separate branches of the version tree.
The attributes are:
Merging is the act of creating a new version containing the modifications performed in several parallel variants of the same document. Merging is intended to make different variants of the same document converge to a single new version.
Merging is performed by approving or refusing each single modification performed in the affected variants. A whole subtree can be made to converge to a single version: there is no limit to the number of different versions involved. The only requirement is that all versions involved need to be stored as internal tags, that is, that they are physically present within the VTML document (see the discussion of external tags).
Merge tags are used to bypass the effects of an operation performed in a version that has been merged.
In VTML, merging does not disrupt the shape of the tree. Rather, one of the variants is selected as the main ancestor of the merge version, and the others share with it a special merge relationship. This enables VTML to use and exploit tree numbering for versions. In Figure 2, 4 is the version number of the merge session of version 3, 3.1, 3.2 and 2.1.1. According to the schema, though, the merge session is a direct descendant of version 3, and has a different relationship with the other versions.
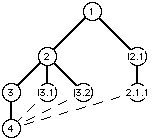
Figure 2: A tree of versions with a branch converging to one node
According to the VTML versioning model, all modifications performed in any direct ancestor of a version are automatically accepted in the current version, while all modifications belonging to versions outside of the chain of direct ancestors are ignored. The MERGE tag overrides this rule:
Thus, in the example depicted in Figure 2, all data that are present in version 3 are included, all data that are deleted in version 3 are ignored unless they have been enclosed in a MERGE tag, and all data that are present in version 3.1, 3.2 or 2.1.1 are ignored unless they have been enclosed in a MERGE tag.
EXTINS and EXTDEL tags refer to modifications that are stored outside the document to which they refer.
The purpose of EXTINS and EXTDEL, on the other hand, is to represent operations affecting another document. They are useful when parsing a base document that needs to be displayed, and several other documents containing externally-stored modifications to the base document. Our current implementation requires that the external modifications be parsed before the data they refer to.
Versions can be freely externalized or internalized as needed. It is possible at any moment to externalize some internal modifications tags, and to insert as internal tags the external modifications of one or more versions. There are only two constraints on the relationship between internal and external tags:
Figure 3: A tree of versions with a branch of nodes selected out
The attributes of external modifications are the same used for internal modifications, plus some more specific for external information:
It should be noted that insertions and deletions are particular cases of a more general operation, substitution. Substitution needs three parameters, the starting position (the POS attribute) and length of the string to be replaced (the LENGTH attribute), and the string that will replace the original string (the content of the tag). Insertion is the same as substituting the inserted text for a null string at a certain position, while deleting means replacing a string starting in position POS and LENGTH characters long with the null string.
This tag introduces a list of attributes that are shared by many different tags in the document. Usually all modifications of a version will share author, date and version number, and all external modifications also will share source version and document and target version and document.
An attribute list thus associates a list of attributes with a numeric identifier that can be referred to within the other tags. The attributes contained in the referenced attribute list are applied to the tag content as if they were put within the tag itself.
Thus, for instance, the following fragment:
<!--{INS vers=1 author="fabio" date="Jul 16, 1995"}-->
This is <!--{DEL vers=CURRENT author="david" date=NOW}-->
your<!--{/DEL}--> <!--{INS vers=CURRENT author="david"
date=NOW}--> my <!--{/DEL}--> document.
could be written more compactly as:
<!--{ATTR ID=1 vers=1 author="fabio" date="Jul 16, 1995"}-->
<!--{ATTR ID=2 vers=CURRENT author="david" date=NOW}-->
<!--{INS ATT=1}--> This is <!--{DEL ATT=2}-->
your<!--{/DEL}--> <!--{INS ATT=2}--> my <!--{/DEL}-->
document.
An attribute list can appear anywhere in the VTML document, provided that it appears before any reference to it has been made. Only one attribute list can be referenced within a VTML tag. ATTR attributes are ignored: it is not possible for an attribute list to refer recursively to another attribute list. Attribute lists can contain any of the aforementioned attributes, in any order. The only required attribute is:
In this section we will briefly examine the basic algorithm employed by the VTML parser.
Determining the content of a given version means examining each tag and deciding whether it still exists or it exists already in the selected version. During parsing, a stack of versions is created. Whenever a new tag is encountered, it is pushed onto the stack and the text content is examined.
The function doPrint() controls the display of a text:
doPrint(content)
char *content ;
/* SIMPLIFIED */
{
if ((type == INS) || (type == MERGE))
if (in_chain(version,verstbd))
printf("%s",content) ;
else
if ((!in_chain(version,verstbd)) &&
( in_chain(lastins,verstbd)))
printf("%s",content) ;
}
The type of the tag is examined. If it is INS or MERGE, then it is
necessary to check whether the version of the tag is an ancestor of
the version that is to be displayed ( verstbd ). If so, the
string is displayed. On the other hand, if it is a DEL tag, then we should
check that the version of the tag is not an ancestor (and thus also
deleted in this version), and that the version
in which the text was inserted is an ancestor of the version
to be displayed. If so, the text is displayed. The big simplification in
the code above is the elimination of the recursive calls required to
handle any nested tags that might be present in content.
Determining whether a version is an ancestor of the version to be displayed can be done using the version number associated with the text.
The numbering of versions is very important for VTML, since all computations on tag content depend on the version number associated with it. We have sought a schema for version numbering that is printable, easy to understand and easy to compute.
Versions of a document rigidly adhere to a tree structure. Even merging, as we implement it, does not disrupt the tree structure. Thus, version numbering will be a kind of tree nodes numbering. Easy computation implies that the chosen numbering schema must allow simple and fast algorithms to determine basic facts about nodes, such as who is the direct ancestor, who is the n-th sibling, etc.
We have distinguished three such numbering schema, which we call outline numbering, reverse outline numbering and L-shaped numbering:
When receiving a GET request from an unaware browser for the document "http://my.host/dir/file.vtml" the parser will generate a single version (the current version as determined by the CVERS attribute). To ask for a specific version, an unaware browser will specify the version number as a further path specification, such as in "http://my.host/dir/file.vtml/3.1.1". The VTML script will then create and deliver the correct requested version.
The VTML parser will also handle PUT requests for new documents, or for new versions of existing ones. It will receive either external modifications or complete vtml documents, and store them as needed. depending on the server, it can internalize external modifications, or merge two complete submissions to form a single document containing two parallel variants.
Currently, a minimal parser of the complete VTML language is available. It can be tried out at the address http://radames.cs.unibo.it:8088/fabio/vtml.html. The server accepts any valid VTML file and generates the requested version. Error messages and value checking are minimal to non-existent (for instance, any string is accepted in the DATE attribute).
This paper builds on a long, if narrow, tradition of attention to versioning issues in hypertext systems. [Delisle] created the notion of "contexts", which nest in the same way that VTML tags do, and for similar reasons. [Greif] identifies the problems with collaborating over real networks, and thus provided a part of the motivation for this work. [Prakash], in the context of synchronous editing, report interesting work on reconciliation of histories. We avoid some of the complication of their algorithms by not ordering any operations in time unless the version tree forces us to.
[Osterbye] has analyzed user-issues in versioning and hypertext. Our work is at the level of a substrate for the sorts of facilities and issues he discusses. [Haake] has explored implementation and user-interface issues in several papers. Some notion of the range of interest in the field can be found in the proceedings of the Workshop on Versioning Systems given at ECHT '94.
The prior work on Palimpsest [Durand] has formed a background to this work. Palimpsest provides a coherent semantics for an even more-flexible versioning scheme, suitable for implementing a variety of data structures. The VTML proposal is simpler, easier to understand, and tailored to the Web's existing technology, in keeping with the WWW philosophy of creating easy to implement and understand methods and protocols. It also takes advantage of the fact that all structural and linking information currently stored in the web is in the form of byte streams containing HTML tags, so it need not structurally represent documents to version them effectively.
We have presented a description of how version management can help solve some thorny collaboration issues in distributed editing environments, and presented a language, VTML for the recording and transmission of editing histories to support such versioning. The design and implementation of the language have been specified in some detail.
This kind of version description is a start at defining a new collaboration protocol that can work with the sort of distributed hypertext embodied by the WWW. Its status as an overlay on other data (particularly SGML data), means that it could fit on top of a variety of applications. One problem that is not well addressed by HTTP at the moment is the issue of transformations and encapsulated data formats. A proper solution to this problem would really be the idea solution to the problem of integrating VTML into the Web.
We intend to continue the implementation work we have started with a custom client that will create and use VTML files to track its activities. Hopefully these basic ideas will serve as a foundation for further development to advance us to the day when the WWW is as much of a writing and collaboration medium as it is a reading and publication one today.
The authors would like to thank Jerry Fowler of Rice University for a helpful reading of a draft of this paper.
Portions of this work were completed under the auspices of the open LTR project #20179 'Pagespace'"
[Berlage] Berlage, T. And Genau, A. "A framework for shared applications with replicated architecture. In Proceedings of the Conference on User Interface Systems and Technology. November 1993.
[Coulouris] Coulouris, G. F. and J. Dollimore. Distributed Systems: Concepts and Design. Addison-Wesley. 1988.
[Delisle] Delisle, N. M. and M. D. Schwartz. "Contexts -- A Partitioning Concept for Hypertext" TOIS. 5(3): 168-186, 1987.
[DeRose]Steven J. DeRose, David G. Durand. Making Hypermedia Work: A User's Guide to HyTime. Kluwer Academic. 1994.
[ECHT] Durand, D. G., A. Haake, D. Hicks and F. Vitali. Proceedings of the Workshop on Versioning in Hypertext systems. Held at the European Conference on Hypertext. 1994. Available at http://cs-www.bu.edu/students/grads/dgd/workshop/Home.html.
[Durand] David G. Durand, "Palimpsest, a Data Model for Revision Control". Proceedings of the CSCW '94 Workshop on Collaborative Hypermedia Systems, Chapel Hill, North Carolina, USA. GMD Studien Nr. 239. Gesellschaft fźr Mathematik und Datenverarbeitung MBH 1994. Available via anonymous FTP at ftp.darmstadt.gmd.de within the file /pub/wibas/CSCW94/workshop-proc.ps.Z
[Greif] Greif, I. and S. Sarin. "Data sharing in group work" ACM Transactions on Office Information Systems. 5(2): 187-211, 1987.
[Haake] "Under CoVer: The Implementation of a Contextual Version Server for Hypertext Applications" Proceedings of the ACM Conference on Hypertext, Edinburgh, 1994.
[Maioli] C. Maioli, S. Sola, F. Vitali, "Versioning for Distributed Hypertext Systems," Proceedings of the Hypermedia '94 Conference, Pretoria, South Africa, March 1994. Available via anonymous FTP at ftp.cs.unibo.it as /pub/UBLCS/Versioning.ps.gz
[Neuwirth] Neuwirth, C. M., R. Chandhok, D. S. Kaufer, P. Erion, J. Morris and D. Miller. "Flexible Diff-ing in a Collaborative Writing System" CSCW '92: Proceedings of the ACM Conference on Computer Supported Cooperative Work. 51-58, 1992.
[Osterbye] K. Osterbye. "Structural and Cognitive Problems in Providing Version Control for Hypertext" in Proceedings of the ACM Conference on Hypertext, Milano, Italy, 1992.
[Tichy] Tichy, W. F. ŇRCS -- A System for Version ControlÓ Software -- Practice and Experience. 15(7): 637-654, 1985.
[Prakash] Prakash, A. and M. J. Knister. "Undoing Actions in Collaborative Work" CSCW '92: Proceedings of the ACM Conference on Computer Supported Cooperative Work. 273-280, 1992.
Fabio Vitali
University of Bologna, Italy
Fabio Vitali holds a doctorate in Computers and Law from the University of
Bologna, and is currently doing research under a Post-Doctoral grant at the
Department of Mathematics of the same University. He was the main
architect of the RHYTHM hypertext system, and is currently working on the
PageSpace project for applying coordination languages to the WWW, and
the TextTiles project for adding versioning capabilities (and hence
collaboration and external anchoring) to the World Wide Web. Among his
interests are versioning systems, externalization of data attributes, and
distributed, collaborative hypertext systems
David G. Durand
Computer Science Department, Boston University
http://cs-www.bu.edu:80/students/grads/dgd/