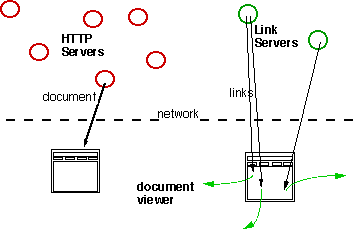
The provision of an independent link service is designed to allow any information environment to be augmented with hypermedia functionality, whether or not it provides link following facilities itself. The WWW, of course, has a well-established method for expressing links as attributes of its native document format, and so the link service will provide a complementary set of links on top of those standard facilities. By contrast, a simple text editor (such as Window's Notepad) has no built-in hypertext links, and so the link service provides an otherwise non-existent service to such users. Without a link service, Web users can follow links from HTML documents or `imagemapped' pictures into dead-end media such as spreadsheets, CAD documents or text; with the link service they can also follow links out of these media again [6].
But how can a link service deal with disembodied links? A link is often considered to be similar to a GOTO instruction in a programming language, and since it is useless to examine a jump instruction extracted from its program context it would seem that a link extracted from its document would equally be an oddity. However, a link can instead be seen as a specification of a relationship between two data items (i.e. it is declarative); it expresses a relationship between its source and destination, and may even be expressed in a way to allow its source or destination to be parameterised. In this way the source may expand to one of several offsets in a particular set of documents, or the destination may resolve to any of a number of alternative documents. These flexible relationships can be expressed in a simple way, and stored together in database; the link service is effectively a database lookup service where the data items are interpreted as links between other data items.
The HyTime [8] standard for hypermedia links provides a comprehensive set of mechanisms for coding the relationship between objects using an SGML representation. It allows for both HTML-style links, where the link is coded in situ at one of its end points, and also for independent links, where the link is coded in a section or document separate from the data which it links together. Although the DLS does not yet use the HyTime standard coding, it uses the HyTime concepts of links as independent entities. The links themselves are distributed across a number of databases and the databases can be distributed across a number of servers. Further, the document server may provide only a basic set of link databases, whereas the end user may have a private set of link databases and a third party server may provide some sets of specialist links on a commercial basis.
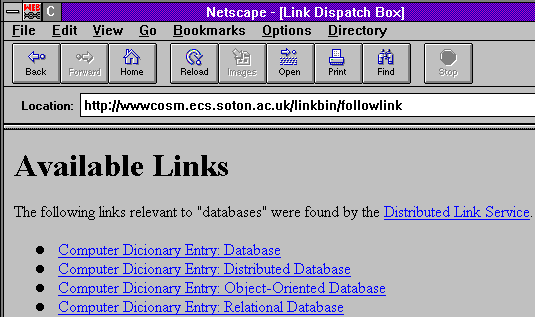
When the user wishes to investigate links from some information, they select the data of interest and choose the Follow Link menu item from the interface agent (Figure 2a). The agent grabs the current selection, tries to determine the current document context (which document was that selection made in? what was its URL? where in the document was the selection located?), parcels this information into a message which is sent to the link server. This process consists of creating an HTTP message with POST data and sending it to a Web server, since the link service is actually hosted by the Web.
The link server then responds with a set of links which are available from the specified selection in the specified document. These links are presented to the user in the form of a 'clickable' list of destinations, displayed as a page of HTML by the Web viewer (Figure 2b).
The user can select the Show Links menu item instead. This will send a similar message to the server which causes the selection to be analysed word-by-word or phrase-by-phrase. All links which apply to any of the constituent words or phrases will be returned as if the user had selected Follow Link on each of them.
Figure 2a: A user requests a link from the link service
Figure 2b: The server responds with a page of available destinations
In some respects this process is similar to making an enquiry of a Virtual Library--certainly the same kind of database lookup is going on, and a similar-looking page of HTML is returned. On the other hand, this activity is both document centered, occurring while the user's focus is on the information content instead of the navigation superstructure, and context specific, parameterised by the location of the query data.
If this action is not totally like a database query, it is also not completely like a normal link following operation. It is reader-driven rather than author driven as it is the user who decides what is of interest for link following rather than the author's sole perogative to determine what material can be followed up [7]. This has some positive benefits for some application environments (such as education) where an exploratory style is encouraged, but may be less useful for other areas where a more prescriptive style is appropriate.
The DLS is a particular kind of information service, and so bears some similarity to a WAIS server. In fact one kind of hypertext can be implemented using just such a text retrieval service, where the links are all derived by a statistical analysis of the lexical data contained in the documents. This style of hypertext, known as a hyperbase, is characterised by the lack of internal structure as opposed to a hyperdocument in which the links are created by human authorship [10]. Services like WAIS and the Virtual Libraries provide some similar features to the DLS, but lack the capability to express human-authored links. The DLS on the other hand can implement a range of links, from the (expensive but highly relevant) human authored variety through to the (cheaper and less specific) automatic keyword matching variety.
Another feature of the DLS is that it allows link following to be affected not just by the static document context of the link source, but also the reader's dynamic context: task-specific information that affects the kind of resources that they would like to follow up. A reader may choose to subscribe to a subset of many different linkbases, depending for example, on whether they are to write an essay for an undergraduate or postgraduate course on Cell Motility, or whether they are interested in Computer Science in general or Parallel Computer Architectures in particular. This is achieved by the interface agent querying its link server about the link databases it supports; the list of named databases is offered to the user as a Context menu.
By selecting a different set of links using the Context menu, the user will see different responses to the Follow Link request: in effect they have the ability to reconfigure their hyperdocument, controlling their own view on the web (a facility previously explored by users of the Intermedia system [11]). This can also be further achieved by choosing which link servers to connect to: a user may improve their Web connectivity by subscribing to a new commercial host which offers an enhanced sets of links across a greater set of Web sites.
To create a link, the author highlights the link source, chooses Start Link from the interface agent, finds the link destination, highlights it and chooses End Link. At this stage the interface agent packs the selections, static document context and dynamic user context information into a Create Link message and sends it to the link server via the Web. The newly-created link may be added to the user's personal link database or to the current Context database; either of these may be subsequently edited by a forms-based interface in the Web browser.
This kind of functionality is fairly straight-forward, but the real advantage for the author comes in the kinds of link definition that are allowed. Following the Microcosm model [1, 2], upon which much of this work is based, links may be declared to be more or less generic, i.e. having the location of the selected text constrained to appear more or less specifically within the static document context. A standard (or specific) link applies only at the exact place that the link source was selected, whereas a completely generic link will match the link source's selection at any place in any document. This facility allows the author to treat a link as a declaration which states "any place in such-and-such a document context that phrase `X' is mentioned links to this data", and allows the author to create a set of documents along with a set of links that can be used to `come to' the documents from other places as well as a set of links which `go to' other documents from the current documents.
The `come-to' link type leads to a resource-based authoring style in which an author can publish a largely standalone suite of documents, together with some link databases which define the `routes' into, through and out of the documents. Making use of the link service allows the author to `mix together' a number of these resources as the `into' links for each of them will act on the text of the others and bind them all together. In fact, the `into' links can act to bind the resources not just to each other, but to the larger Web of documents outside the author's control--the readers' environment. One of the major benefits of this authoring style is the scope for information reuse: not only can the author vary the internal paths through the documents by changing the link databases, but also the documents themselves can be used and reused in many different situations by providing different sets of `into' and `out of' links.
Link databases use an SGML-based format, and so can be processed using standard tools like Perl, sed or awk. In particular it is possible for an author to automatically create a simple link database from scratch by extracting sets of keywords from documents and turning them into generic links. Such a database would need a certain amount of author-editing to become properly useful, but seeding a set of links in this way can provide a basic amount of hypertext functionality with minimal effort.
As a variation to the standard use of the link service, a user can choose to send to the server not just a selection from a document but an entire document. The link service will then undertake to return that document with all the applicable links (from whichever context was chosen) hard wired into the document in whichever native format the document was created. This option, available from the Compile Links menu item on the interface agent, currently handles HTML, RTF, PDF and text document.
The effect of this facility is to place the links belonging to a document back into the document so that the new document can be used independently of the link service, especially if the document is to be distributed as part of a non-networked environment (on CDROM for example). This facility also allows publishers to work with a resource-based paradigm, creating a Web of information nodes for a specific niche market, and recreating a different Web over some of the same information for a different market.
The Open Journal Framework project (funded by HEFCE's Electronic Libraries programme in the UK) is capitalising on the link service's functionality from the publisher's points of view. The aim of the OJF is to enable electronic journals in a digital library to become co-operating assets in an information delivery environment rather than isolated, one-off resources. Based on a set of several hundred PDF files, which correspond to several volumes of the Company of Biologists' journal Development, work is being done to establish link databases for those resources along with other network-accessible biology resources (gene sequence, biochemical and research databases).
The OJF can easily be extended to provide guided or free searching through a prepared database to create a powerful learning environment. Installing expert system technology into the link server allows it to become an intelligent tutor to direct students through material available on the network. The Company of Biologists is at present negotiating with other publishers to allow the use of standard texts to complement the content of their journals for teaching purposes. The benefits of the project therefore extend beyond electronic libraries for research and into customised teaching and learning environments.
The various scripts determine the appropriate context from the information passed to them by the end user's WWW browser, and the user linkbase from the details of the user and host connecting to the server. The scripts then carry out their activities using the appropriate databases.
The script which handles requests to follow links simply checks in all appropriate databases for any applicable links and returns these to the user as a list of potential links in an automatically generated HTML document. The user may then go directly to the link destinations. The show links request is a special case of the follow link process, it takes a large selection and carries out several follow link requests on the words and phrases making up the selection.
The script which creates links accepts details of start and end points for a link, and inserts a link into either the database for the specified context, or the user's personal database if no context is given.
The edit link script offers a fill in form which allows links to be entered directly into databases, deleted, or their details modified. In particular the user is able to update the description of the link, which by default is the name of the destination, or change the type of the link to make it more generally available. Links may be defined as one of two types: local, in which case it applies only in the document in which it was originally authored, or generic [5], in which case it applies whenever the source anchor selection is found, thus reducing authoring effort significantly.
Finally, a script is available to compile links held in these link databases into an HTML document, thus providing direct access to all applicable links without the need to make individual requests to the server. This can also provide a way in which material may be authored using the DLS and delivered as standard HTML.
<link type=local> <src><doc>http://diana.ecs.soton.ac.uk/~lac/cv.html <offset> <sel>Microcosm <dest><doc>http://bedrock.ecs.soton.ac.uk/ <offset> <sel>The Microcosm Home Page <owner>Les@holly <time-stamp>Fri Mar 31 13:32:34 GMT 1995 <title>Hypermedia Research at the University of SouthamptonBoth the source and destination are described as a triple (document URL, offset within document, selected object within document) and allow the system to pinpoint the link anchors either by measuring from the beginning of a document (using the offset), or by matching a selection, or both.
A link is of type specific if its source anchor is constructed from a complete triple (i.e. a specific occurrence of a selected object in the named document), local if its anchor is ignores the offset component of the triple (i.e. any occurrence of the selected object in the named document) or generic if only the selection is used (i.e. any occurrence of the selected object anywhere in any document).
In the Microcosm system (upon which this work is based) offsets are frequently used, but because of a lack of technical integration with the various viewing programs, the DLS usually ignores the offset. Hence only local and generic links can be created and manipulated by the various user interfaces, although it is possible to process specific links programmatically.
Note that the DLS provides flexibility in specifying the source anchor: this means that a single link to a destination may appear in many places at once, giving rise to a number of useful features for the hypertext author.
The main task of the client utility is to react to a request from a user to carry out a particular linking function (e.g. start link, follow link) by extracting the details of the selection the user has made, and if possible, the details of the document in which the selection is. This information is encoded in an HTTP request reflecting the chosen function, and the selection details.
This request must then be delivered to the currently specified link server. This is done by communicating with the user's WWW browser, and requesting it to load the new URL. The results of the link request are returned as HTML, and displayed by the WWW browser. For example, in response to a request to follow a link from a particular selection, the response might indicate that no links were found, or list the links that were identified.
All versions of the client interface are currently designed to support the use of Netscape 1.1 for communication with DLS servers. The nature of the client interface, and the way in which it communicates depend on the particular platform being used. In the future, some or all of the functionality of the client interface may be achieved through programmable features in browsers.
One major project, described above, is the Open Journals Framework, which uses the software to support electronic publishing. Two other major projects involve a traditional Web server for large commercial organisations, and use the DLS in conjunction with our HTML `compilation' tool to ease the significant information maintenance and authoring task. Other projects include a Web-based distance learning course, which adopts a resource-based approach [4], and, in contrast to this manually authored service, the support of an information service for university administration: different users are provided with different views of the data according to their role, and the link service is used to automatically link new documents (such as committee minutes).
In each of these applications, the link databases are held on the same server as the documents (for access or for compilation). This is the simplest use of the DLS and is adequate for many applications. Meanwhile, the fully distributed version of the DLS is under development: this supports linkbases maintained on different servers, enabling the linkbases to scale and supporting localisation of linkbases. Localisation means that an individual user, or a group of users, can work with databases held as locally as possible (as in group annotation [9]). An early prototype of the fully distributed service used SMTP to provide a standard asynchronous messaging model for inter-server communication, with MIME-encoded link resolution messages.
Experience has shown that taking a query-based approach (rather than pre-compiling into HTML) can cause a significant loss of performance where users make use of a proxy, since the results of the queries are not cached. This problem arises when there are remote users of a single DLS server, especially if those users are widely distributed (so the DLS server cannot be made local to all of them). There are various solutions: provision of a proxy with DLS extensions would allow require remote users to change their proxy, so the preferred solution is to modify the DLS server so that intermediate proxies cache appropriately.
Instructions for obtaining the Distributed Link software can be found at <URL:http://wwwcosm.ecs.soton.ac.uk/dls/dls.html>.
We will continue to develop the Distributed Link Service following our open hypermedia philosophy, adopting new browser technology (e.g we are currently using Java) and new server technology as it becomes available. We are also working with ANSA, investigating a CORBA-based approach to the distributed service [3]. Some of our existing applications will evolve to use the fully distributed implementations of the service, and we look forward to reporting on this work in due course.
[2] H. Davis, S. Knight, W. Hall, "Light Hypermedia Link Services: A Study of Third Party Application Integration", in Proceedings of the Sixth ACM Conference on Hypertext, Edinburgh, Scotland, September 1994, ACM Press, 41-50.
[3] D. DeRoure, G. Hill, W. Hall, L. Carr, "A Scalable, Distributed Multimedia Information Environment", Proceedings of the International Conference on Multimedia Communications, Society for Computer Simulation, 77-80, 1995.
[4] D. DeRoure, L. Carr, W. Hall
and G. Hill, "Enhancing Web support for Resource-based
Learning", Proceedings of Workshop H (Teaching and Training on the Web),
WWW'95: Third International World-Wide Web Conference.
[5] A. Fountain, W. Hall, I. Heath, H.
Davis, "Microcosm: an Open Model With Dynamic Linking", In Hypertext:
Concepts, Systems and Applications. Proceedings of the European
Conference on Hypertext, INRIA, France, November, 1990, 298-311.
[6] W. Hall, L. Carr, H. Davis, R. Hollom,
"The Microcosm Link Service and its Application to the World Wide Web",
in Proceedings of the First WWW Conference, Geneva.
[7] W. Hall, "Ending the Tyranny of the
Button", IEEE Multimedia 1(1), 60-68, Spring 1994.
[8] International Standards Organisation,
Hypermedia/Time-based Structuring Language (HyTime), ISO/IEC Standard
10744, 1992
[9] D. LaLiberte, A. Braverman,
"A Protocol for Scalable Group and Public Annotations", Proceedings of
the Third International World-Wide Web Conference, Computer Networks
and ISDN Systems 27(6), 911-918, 1995.
[10] P. Stotts, R. Furuta, "Hypertext 2000:
Databases or Documents?", Electronic Publishing: Origination,
Dissemination & Design, 4(2), 119-121, 1991.
[11] N. Yankelovich, N. et al, "The Concept and Construction of a Seamless Information Environment" , IEEE Computer, 81--96, January 1988
Acknowledgements
This work was partially supported by JISC grant ELP2/35 and a UK
ROPA award.
About the Authors
Leslie Carr,
David De Roure
Wendy Hall
and
Gary Hill,
Multimedia Research Group,
Department of Electronics & Computer Science,
University of Southampton.