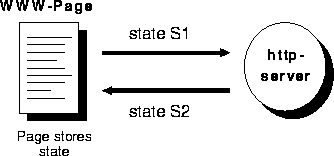
Figure 1: State information stored in pages
Werner J. Schoenfeldinger
Department for Applied Computer Science
Vienna University of Economics and Businness Administration
Email: schoenf@aia.wu-wien.ac.at
Keywords: World Wide Web (W3), User Interfaces, Linda, CGI-programming, Perl
Using WWW (W3) as a front-end for applications has recently become quite popular. Starting with simple interfaces for retrieval tools such as WAIS or Archie, programmers have decided to teach their programs HTML. The reason for this trend is that a W3-based application has a wide range of advantages for programmers and users alike:
These advantages make W3 particularily attractive as a front-end for multi-user, transaction processing applications and mass information systems. However, two severe problems limit the applicability of W3 for this kind of systems:
First, the problem of secure data transmission on the network and second, the problem of integrating transaction processing with the W3-based front-end. In this paper, we suggest a uniform and general solution to the second problem: We integrate the coordination language Linda[9] with the W3 front-end and give two simple applications to illustrate the power of the approach.
In this section we give a brief overview about W3-based front-ends for user-applications. Starting with a short definition of the Common Gateway Interface (CGI), we describe the main parts of CGI-scripts and try to point out problems with the use of W3 as front-end via ordinary CGI-scripts.
The clear and uncomplicated structure of the gateway allows great flexibility and makes it easy to implement applications with a W3-based front-end. But due to the flexible structure of the gateway we have to deal with two major problems, namely the security problem and the consistency of transaction problems which we will discuss at the end of this section.
`The Common Gateway Interface, or CGI, is a standard for external gateway programs to interface with information servers such as HTTP servers''[5]
It provides the functionality for passing data between World Wide Web-Pages and programs. CGI uses for the actual data transfer both standard input and environment variables of the called process. The processing of passed data is left to the called program. The standard output of the program is returned to the HTTP-server and is immediately sent to the browser for beeing displayed. When we use CGI-scripts to process the output of HTML-forms, we can distinguish two major methods in passing data to the CGI-script[11]:
If the form has METHOD=`GET'' in its FORM tag, the CGI-script will receive the encoded form input in the environment variable QUERY_STRING.
If the form has METHOD=`POST'' in its FORM tag, the CGI-script will receive the encoded form input on STDIN. The server will not send an EOF at the end of the data. The number of characters which should be read from STDIN is stored in the environment variable CONTENT_LENGTH.
The data is passed in a CGI-specific format which is defined in [15, p.146,]. In several programming languages we can already find routines to handle and translate passed data in a suitable format for further computation.
CGI-scripts are written to perform a certain user-defined task. The task can reach from simple 'output only'-scripts to sophisticated programs. Generally, we can identify three major parts in CGI-scripts:
In most languages en-/decoding from HTML is implemented in specific library routines such as `cgi-lib.pl''[6] for Perl or `ReadParse''[18] for C++. CGI-scripts can receive data from a W3-page in several ways[19]:
<A HREF="/CGI/myscript/this_var=15"> testlink</A>
In this case, data is passed in the PATH_INFO variable. Considering
the example, it contains "/this_var=15".
<A HREF="/CGI/myscript?this_var=15"> testlink</A>
This method works in the same way as the GET-method with an HTML-form. The data is passed in the variable QUERY_STRING. Note, that the transfer requires a specific format.
It is up to the programmer to decide how data is passed. If you use another method than POST, the disadvantage is that the data string is displayed in the 'Location'-line of most browsers.
Output is given to the server via writing to STDOUT. The first output line determines the type of the output. The second line should be left blank. From the third line on, additional output can follow.
The first line must be either:
Location: /path/to/some_doc.html
The reference will be interpreted by the server and the stated document will be browsed. This mechanism is used with ISMAP-structures.
Content-type: text/html
In this case the whole document is an output of the CGI-script. The script has to give some hints to the server about the document's type. This is performed in stating type and subtype of the document. In our case, it is a HTML-document.
Under UNIX the CGI-program is invoked by the http-server under a specific userid and groupid. Both ids are set in the http-server configuration file. This gives the script the same access-permissions and possiblities on the system as the invoking user.
As pointed out in [17], the http-server is a stateless server and therefore it cannot keep any state information for running scripts. If applications require state information, the state has to be maintainted by the script. There are two methods to deal with this problem which are implemented frequently:
Both methods, however, have serious disadvantages. In using hidden attributes to store the state information, everyone can read the state information in the html-source. For some applications disclosure of the internal system state is a severe security problem.
In multi-user environments we have the problem of state-consistency. This problem arises, when the state of one client depends on the state of other clients. In this situation we have to take in consideration, that a client might crash and the state information is lost. This can lead to a deadlock in the whole application. We can find these problems in many types of applications, for example, computer games, credit card validation and credit approval, computer based exams ...
Figure 1: State information stored in pages
Using the file-system of the http-server's host as storage medium
requires two things: First, the userid, under which the http-server
runs must have access to an area in the file-system. On UNIX-systems,
this could e.g. be /usr/tmp. Second, this implies that all necessary
processes for the application have to run on the same host.

Figure 2: State information stored at the host
With NFS we can overcome this limitation in sharing the relevant data among hosts on which it is needed. In such a solution the data has to be placed in a directory, accessible by all participating hosts.
Especially for building large multi-user transaction systems W3 is an attractive front-end. Unfortunately, however, transaction processing is a major problem for W3-based applications. Today, transaction processing, process communication and synchronization, data locking,... are not supported by the existing CGI-toolbox which is available for most http-servers. It is the responsibility of the application programmer to ensure, that no conflicts and deadlocks can occur, when several users invoke CGI-scripts at the same time. Since the filesystem is the only shared media between the different CGI-processes stability for multi-user transactions can only be achieved through the lock-files and access-delays.
In this section we describe Linda, a coordination language which coordinates the cooperation of several processes. After a short introduction and a historical review, we focus on the Perl Linda Server and the Perl Linda Client[20], which we will use later for building applications.
Linda was originally developed by D. Gelernter [9] and has already prooved its usefulness for writing parallel programs [1][3][7][21]. There are several programming languages, which have been extended by Linda, such as APL[12], C[3], C++[2], Lisp, ML[21], Prolog and Perl[20].
The core of Linda is a small set of functions that can be added to a base language to yield a parallel dialect of that language. It consists mainly of a shared data collection called Tuplespace and a set of functions to access and modify the data stored in the Tuplespace. The unit of communication is a tuple, a list of typed fields which can be either actual or formal. Actual fields have a specific value whereas formal fields are placeholders for values. Tuples stored in the Tuplespace can only have actual values. Apart from the limitations of the programming language, there are no limitations for both, the number of fields in a tuple and the fieldlength. There must not be any empty fields in tuples. How tuples are represented in the Tuplespace is highly dependend on the implementation. In the Perl-Linda implementation, they are stored in encoded ASCII-text. Let us give here some examples for tuples:
(this,is,an,example,for,a,tuple)
(x,y,135,436)
In addition to storing and retrieving tuples, the Linda functions provide process synchronization. The basic functions for accessing and modifying the contents of the Tuplespace as described by [3, p.399f,] are:
The function out() puts a tuple into the Tuplespace. The tuple can be retrieved by all other processes with the help of other Linda-functions. With out() you can only put data-tuples into the Tuplespace. Out never blocks.
For retrieving tuples from the Tuplespace we use the function in(). It removes all tuples which match a given template from the Tuplespace and returns them. A template is a tuple with formal fields, to which actual values can be assigned during the matching process. However, no match exists in the Tuplespace, in() blocks until at least one matching tuple appears in the tuple-space.
Read is quite similar to in(). The difference is that rd() does not remove the matching tuples from the Tuplespace.
Eval creates an active tuple, in fact a task-descriptor for which, in Perl Linda, the Linda-server is responsible for computation. The active tuple may consist of ordinary elements and functions which need evaluation. The results are stored as a passive tuple in the Tuplespace. Because the command is highly language-dependend, it is not yet implemented in the Perl-Linda implementation. We will not need eval() for our examples.
To prevent deadlocks, Perl Linda has two additional commands. They are
non-blocking versions of the rd() and in() commands which
have been implemented in the many versions of Linda
[3][1]. They are called nbin()
(non-blocking in) and nbrd() (non-blocking read) and return an
empty list, if no matching tuple is found. The formal fields in
templates, supplied with in(), nbin(), rd() and
nbrd()-functions can have wild cards, which are symbolized in Linda
by the character '?'. A wild card can be matched to any other
field in a tuple of the Tuplespace.
Let us illustrate, how a typical Linda-transaction between two
processes takes place. Consider an example of two communicating
processes shown in Table 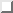 .
.

Figure 3: Two communicating processes under linda
In step 1 the clients put the tuples (x,b,2) and (a,c,4) to the Tuplespace. Client2 tries to retrieve all 3-element tuples with `b` as the second element using in(). Because there are matching tuples, they are retrieved from the Tuplespace and handed to client2. In step 4 we have an example for the blocking mechanism of in(). Tuples matching the pattern of the in()-statement given by client1 are not found in the Tuplespace, therefore client1 blocks. The tuple sent by client2 in step 5 matches the pending request from client1 and it is transfered to client1 in step 6. The following out()-statement of client2 is not sent to client1 thus it was matching the pattern. This comes because a blocking in() or rd() is satisfied with just 1 matching tuple.
The steps shown in the example are logical processing steps of the Tuplespace. There is no need for further coordination between the two Clients since in() blocks automatically until a matching tuple arrives in the Tuplespace.
Perl Linda is an extension of the language Perl[22]. We have chosen Perl for the implementation of Linda because of its flexible structure and extensibility. Further, Perl has the advantage to be available on many systems, because the source code is public domain. The implementation of Linda in Perl was done in the following way:
This two-layered implementation of Linda allows clients of different programming languages running on different hosts to access the Linda-server and exchange information. The coordination is achieved by using the Linda-functions in the specific language. All Linda-clients access the data from the server in the same encoded format[20], therefore no compatibility problems between the clients of different programming languages arise.
We have already used Perl Linda for the implementation of distributed ray-tracing, distributed processing and multi user computer games. In these applications, we have learned that the Linda coordination language is a very powerful tool to coordinate several clients and the resulting client programs are considerably smaller than programs using a classical approach described in [8, p.183ff,]. Distributed Tuplespaces among several servers on different hosts have been already been developed[1][7][21][23], but have not been implemented in Perl-Linda by now.
The requirements for using the Perl Linda server is a UNIX platform, Perl 4.036 and a TCP/IP-based network. We have already tested the Linda server on several platforms such as AIX, HP-UX, LINUX, OSF1 and ULTRIX.
Since the Linda-server only handles the incoming requests from clients and stores or retrieves tuples from the Tuplespace, the processing of the tuples and transactions are left to the clients. We have developed clients for different programming languages each of which has a certain specialization:
These clients can use the interface to the Linda-server to cooperate and solve a given task. There is no need for further coordination. This is done by the intrinsic blocking mechanism of the in()- and the rd()-command which is implemented by the Linda-server. The clients do not need to run on the same host as the server, because they can connect to the Linda-server via the network.
Since data is represented in an encoded form in the Tuplespace, the application programmer generally does not need to care about data-compatibility between Linda-clients in different programming languages. Compatibility should have been achieved by the programmer of the Linda-functions in the specific language. He is the one to ensure that all data is converted from the language-specific representation to a suitable format for the Linda-server and vice versa.
The basic structure of a Linda-client looks more or less the same:
To illustrate the usage of a sample Perl Linda, we show
the example of a Linda-client for distributed counting in Figure 4
. Several Linda-clients count together a variable from 1
to 10000. Only one client is able to increase the variable at a
time. The coordination is fully left to the clients. Although
this task is not useful in itself, it represents a very good example
for parallel programming and coordination.
#!/usr/local/bin/perl # Invoking Perl
require "linda-cli.pl"; # Adding the Linda-library
#
®ister_client("aig.wu-wien.ac.at", 7999); # Registration to the Linda-server
#
@tuple=&nbrd("COUNTBEGIN"); # Client determines if he is
&out("COUNT",1), &out("COUNTBEGIN") # the first client ?
if @tuple==(); #
#
while($var<10000) # The count routine
{ #
@tuple=&in("COUNT", "?"); # Get the actual tuple (COUNT, value)
&printtuple(@tuple); # Print the whole tuple
$var=&element("last",2,@tuple); # Extract the value of COUNT
$var++; # Increase the value by 1
&out("COUNT",$var); # Put it to the Tuplespace
} #
&close_client(); # Say good bye
The flexible structure of Linda generally allows us to easily distribute applications between different hosts and share data and work through a Linda Tuplespace[4]. Since Linda does not provide the full functionality needed for transaction management, we have to keep certain restrictions from server and clients in mind.
Bakken[1, p.289,] points out two major problems caused by a crash of the client:
Perl Linda can cope with the `lost tuple problem` in using the functions uin() and uout() which provide a recovery of the updated tuple in case of a crash of the client. A solution to the `duplicated tuple problem''has been implemented in another version of Linda[1]. This solution with atomic guarded statements which can provide atomicity for a series of out() operations. It is feasible for Perl Linda too, however, implementation is left to future work.
The second area of problems with the usage of Linda for transactions systems is the failure on the server side. To prevent data loss due to a crash on the server-side we have to solve 2 problems:
There have already been implemented a solution to both problems through replication and usage of multiple Tuplespaces[1]. In Perl Linda it is by now left to the application-programmer to equip the application with such a facility. This can be implemented via signal-handling. On the server-side is a mechanism provided to dump the contents of the Tuplespace to the local filesystem and to recover the Tuplespace from it after the restart[20].
The basic idea for supporting W3-based applications with Linda is the
separation of transaction of input/output processing and data
processing. With Linda, CGI-scripts are only responsible for
input/output-processing, whereas the responsibility for all
data-processing and transactions is shifted to background application
processes, which communicate with the CGI-scripts via a
Linda Tuplespace (Figure 6). This results in the following
advantages:
.
In this approach we see the chance to support W3-based applications with an interface to distributed computing which is both, easy to implement - and easy to use. The inclusion of Linda in such applications provides bridges between the most popular CGI-Script language Perl and other languages in which Linda-clients already exist. These languages have their strengths in different fields, and we can build heterogenuous applications using the different languages wisely. However, Linda provides W3 with an interface meeting the Transaction Processing Standards[10, p.80,]:
In a CGI-script without Linda the browser is blocking until the
CGI-script has terminated. The structure of such an application is
shown in Figure 5.
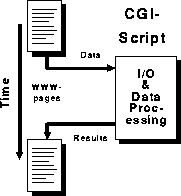
Figure 5: CGI-application without Linda
For many applications this structure is not sufficient. There are some reasons for this:
Integrating Linda in W3-based applications results in changes in the application structure. The CGI-script, in normal CGI-programs responsible for the whole functionality, is only responsible for the data-transfer to and from the Tuplespace. In addition to the transfer from the Tuplespace it has to convert the data into HTML-format.
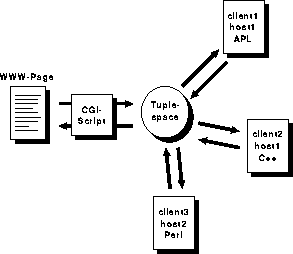
Figure 6: W3 and Linda working together
Figure 6 shows the typical structure of a W3-Linda
application. The CGI-script interacts between the front-end and the
Tuplespace. The other clients which are connected to the Tuplespace
can run on different hosts and, of course, in different languages.
Data is shared via the Tuplespace with the actual application. The
CGI-script waits with an in()-statement until the application
puts the data in the Tuplespace. Compared to the solution without
Linda, it is possible for more applications to use the data sent to
the Tuplespace. This could, for example, result in a parallel search
in several databases. The structure of such a application is shown in
Figure 7. In Figures 6 and 7
for matters of clarity the interactions are only shown for one process
but it should be clear that this application structure works for
multiple requests too. If the processing of a task is very time
consuming there can be added more worker-clients to the Tuplespace
waiting for tasks.

Figure 7: CGI-application with Linda, waiting for task completion
Through the usage of a Linda as interconnector between front-end and
application, we can develop a flexible, termination-independend
structure shown in Figure 8.
The application simply checks the tuple-space for requests. If a request is found in the Tuplespace, it is handled. Otherwise the application sleeps for a certain amount of time in order to not exhaust the system resources. The user handles the situations in the same way. After sending the request he receives a notification that his request is being processed. Meanwhile, he can do other things and check later, if the results already have arrived. This can be done either by automatical reloading the page or simply by manual query.
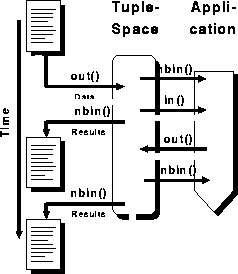
Figure 8: Linda and W3, front-end is independend from application
In this section we show how the interaction between Linda and W3 is implemented. Our code examples will be in Perl, since Perl is used frequently for programming CGI-scripts. Another reason for using Perl is, that the interaction between the front-end and the Tuplespace is not time-critical. Therefore, for this class of applications Perl represents a flexible and sufficient solution for this problem.
The only requirement for the Linda-W3-based applications is, that a Linda-server is running on the chosen host and port. The server can be started by every user if the port-number is above 1024. The default port-number is 7999. The Linda Perl-libraries have to be installed in the standard Perl include-directory. Otherwise they cannot be found by the CGI-script.
The first code example shows a very simple interaction between a form and the Tuplespace. No data processing is done, only the data-transfer is implemented.
#!/usr/local/bin/perl # Invoking Perl
require "linda-cli.pl"; # Adding the Linda-Library
require "cgi-lib.pl"; # Adding the CGI-library [cgi-lib.pl]
&ReadParse; # Reading Information passed by Form
®ister_client("aig.wu-wien.ac.at", 7999); # Registration to Linda Tuplespace
#
for( sort keys(%in)) # Transfering data to Tuplespace
{ &out($_, $in{$_}); } # in format (Name, Value)
&close_client(); #
#
print &PrintHeader; # http-server needs
print "\n<h1>Data transferred</h1>\n"; # "Content-type: text/html"
From this example we can see that very little code is needed to implement such a communication. This is to a great extend due to the functionality embedded in the 'required' libraries.
The next example deals with the data-transfer in the other direction. Let us consider as example a printer accounting system, in which the spooler stores the information about the printed pages in a Tuplespace. The format for this is:
(PACC,<userid>,<number_of_pages_today>,<number_of_pages_total>) e.g: (PACC,schoenf,23,542)
The printer accounting system consists of two components. First, the
spoolers responsible for the printers call a tiny feeder-program
which the user-data in the Tuplespace. The first item named 'PACC' is
only necessary, if the Tuplespace is used by several applications. The
second component is the printer accounting statistic shown in Figure 10
.
#!/usr/local/bin/perl # Invoking Perl
require "linda-cli.pl"; # Adding the Linda-library
require "cgi-lib.pl"; # Adding the CGI-library [cgi-lib.pl]
#
®ister_client("aig.wu-wien.ac.at", 7999); # Registration to Linda Tuplespace
@tuplelist=&nbrd(PACC,"?","?","?"); # Transfering data from the Tuplespace
&close_client(); # Closing the connection to the Tuplespace
for(@tuplelist) #
{ #
($user,$day,$total) = &detrans(split(/,/, $_)); # Extracting Data from the tuples
($usr{$total},$pday{$total})=($user,$day); # Preparing data for sorted output
} #
#
print &PrintHeader; # HTML-Output
print "\n<h1>Printer Highscore</h1>\n<hr>\n<pre>\n"; # Well <pre> will do it
printf("%-15s %6s %6s\n<br>","User","Today","Total"); #
for( reverse (sort keys(%usr))) #
{ #
printf("%-15s %6s %6s\n",$usr{$_},$pday{$_},$_); #
} #
print "</pre>\n<hr>\n"; #
The examples show, that it is quite comfortable to separate the
acquisition of information from the actual input/output
processing. Further, the update of information does not depend on
user-requests. However, an user-dependend update of information can be
implemented by the application-structure shown in Figure 7
.
In this section we present W3-based applications which work with Linda. We present Disctool, an application which allows a system administrator to view the current usage of the harddiscs in a cluster, independend on which system he currently works. The second application is "LVA-Express", a program which implements continuous opinion polls with immediate statistical analysis of the results. This system is intended to improve the course-evaluation system at our university.
In our department we have by now a cluster of 23 UNIX-workstations. Software and applications are distributed among the harddiscs of these computers. The motivation for this application is the problem, that disc-space is a scarce ressource. Due to automatic processes (ftp-mirrors, system logs, mail, backups), it frequently happens that the disc-usage approaches 100%. In this case users on the network may not be able to save their work anymore, documents cannot be printed and cannot be received. Immediate intervention of a system administrator is required.
The current solution is that the system administrator tries to forecast disc-shortages in order to take counter measures. However, to manually check 17 systems can be a very time-consuming job, therefore we decided to build a W3-based application for this task.
To check the disc-usage on a system, the UNIX-commands 'df' and 'bdf' are used, depending on the UNIX-version. These commands result in the following output:
Filesystem 1024-blocks Used Avail Capacity Mounted on /dev/rz3a 41711 32553 4986 87% / /dev/rz3g 816425 693637 41145 94% /usr /dev/rz3d 51289 15818 30342 34% /var /dev/rz1c 1025374 921267 104107 90% /disk2
Impementation based on Remote Procedure Calls (RPC)[8, p.240ff,] implies access rights for the user 'nobody', which runs the http-server. For security reasons this is an impossible situation.
So we decided to use Linda to overcome this problem. Tiny background
scripts, running on every workstation in the background should feed
the current disc-usage to a Linda-Tuplespace. The intervals of update
are variable and to be configured. A CGI-script retrieves the
information on request from the Tuplespace and convert it to HTML. The
system administrators can check the status of the whole cluster at the
first glance. The structure of 'DiscTool' is shown in Figure 11
.
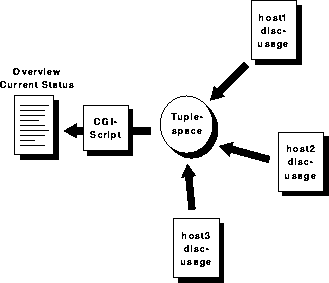
Figure 11: Structure of DiscTool
The information in the Tuplespace is updated by the clients every 5-10 minutes. In the intervals between updates, the processes sleep in order to consume no CPU-time. We have chosen a 2-level interface for the output of disc-usage. The first level shows an overview over the cluster, every partition on the harddisc is represented by an icon. Figure 12 is a screenshot of this overview. If the administrator requires details about a specific partition, he clicks on the icon and further information is retrieved from the Tuplespace.
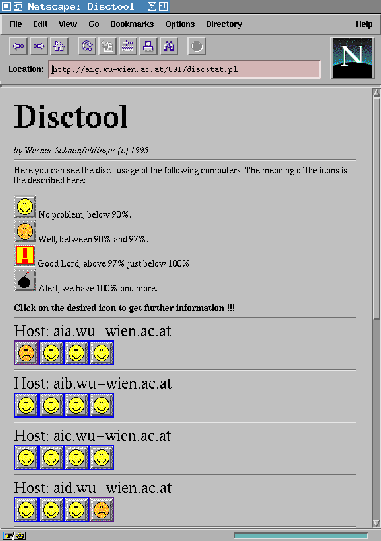
Figure 12: Screen-Shot of DiscTool-Overview
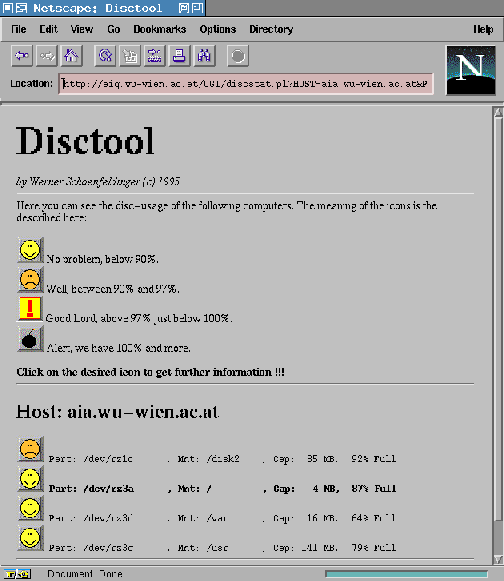
Figure 13: Screen-Shot of DiscTool - Detailed Information
The second application we present in this paper is a transaction system, which allows continuous opinion polls. Course evaluations are undertaken at the Vienna University of Economics and Business Administration (WU-Wien) every year. This is a very time consuming process. Much paperwork is involved, because the whole evaluations are based on paper-forms on which the students have to evaluate their courses. These questionaires have to be entered in a spread-sheet. On this base, the evaluation can be done. The output is a brochure, containing all lectures and their evaluation. This is a very good information for new students to get an impression of course quality.
Since editions of this brochure are usually released with large delays (6 to 9 months late), we decided to support course-evaluation with a W3-based application. Requirements for this application are to provide configurable front-ends for the polls which are campus-wide available. Further, a continuous evaluation, based on the data entered should be provided to give both, lecturer and students the opportunity to discuss the course quality immediately at the end of the course.
Especially with course evaluation, the implementation problem is, that many students are evaluating the same course at the same time (e.g. after the course) and that each needs an exclusive access to the data-file. Since the data has to be saved in files, the read/write-access is only possible for one client. A correct implementation of this client must use lock-files and inter process communication to ensure exclusive access to the data-files. The second problem is, that a normal CGI-script has to read, evaluate and write all the data on every request.
Linda solves both problems. A Tuplespace is placed in between the
evaluation-process and the input/output-process. The students fill out
a questionaire in a HTML-form. The results of this questionaire are
sent to the Tuplespace. Each questionaire is assigned a transaction
number for identification. The CGI-script gets the last used id-number
from the Tuplespace and increases it by one. Then it is stored into
the Tuplespace again. After sending the data, the CGI-script returns a
confirmation to the front-end. The user can now decide what to do
next. The evaluation process retrieves the stored data from the
Tuplespace and evaluates it. This is considerably faster, because the
evaluation process has the evaluation data in the memory and therefore
does not need to read the data-file. After calculating the results,
they are put into the Tuplespace with the URL of a graph of the
evaluation in gif-format, specially created for the course. If the user
decides to view the evaluation of the course, the information is
retrieved from the tuple-space and displayed. The user gets the newest
updated version of the evaluation. The evaluation- and update-time
depends on the number of simultaneous requests and the speed of the
host. The structure of the application is very similar to the
structure in Figure 8.
In this paper we presented the implementation of W3-based applications with Linda, a high level set of functions for process coordination and parallel processing which have been added to several programing languages. The inclusion of Linda provides both, a standardized interface to other systems and programming languages and the ability to overcome the limitations of conventional CGI-scripts. This is achieved by separation of input/output-processing and data-processing. Linda is responsible for the coordination and synchronization of the application, whereas the CGI-script is only responsible for input/output processing. Additionally, Linda allows interaction between distributed applications on different hosts connected with a TCP/IP-network.
Combining Linda with W3 allows new types of applications such as multi user interaction systems, cooperative games and stateful stateful server application to be used with a standard W3-front-end. All this can be established on the Input/Output-side with considerably small Perl-scripts. We showed two sample applications, in which the W3-front-end proved to be easy to implement and easy to use.
In further development of Perl Linda we intend to extend the current implementation with the feature of atomicity for multiple commands and usage of multiple workspaces with the possibility of replication. Future research in Linda-WWW applications is planned in experimental economics. We intend to implement market simulations including interaction of human competitors with adaptive agents which interact via a Tuplespace. W3 is a very good front-end for this task, because it does not limit you to text mode and provides a system-independent interface to the prospective users. Concerning Perl Linda we intend to add the feature of atomicity for multiple commands and replication and usage of multiple workspaces.