Anselm Lingnau
Oswald Drobnik
Peter Dömel
Recent times have seen exciting new developments in computer networking. Applications like the World Wide Web have made computer networks such as the Internet available (and palatable) to users outside of computer science departments all over the world. Information servers offering all sorts of interesting data are cropping up, and, as researchers are trying to find ways of reliable electronic payment, the net will soon be important as a `virtual marketplace'.
Yet the sheer amount of data available to users in such a network will be difficult to handle. How will they be able to locate the information they need? How are they going to find the best offer for some service they require? One possible solution brought forward to help in this situation consists of `mobile agents' - autonomous programs that move about the network on behalf of their owners while searching for information, negotiating with other agents, or even concluding business deals.
In this paper we propose an infrastructure for such agents. This infrastructure allows agents to move between hosts and communicate with other agents; it supports agents written using diverse languages and lets agent programmers implement a variety of interaction schemes based on a general mechanism for agent communication. Our agent infrastructure uses the Hypertext Transfer Protocol (HTTP) [2] for agent transfer and communication, taking advantage of this widely accepted, platform-independent mechanism to make it as easy for providers to offer agent-based services as for users to access them. We also expect future advances in, e.g., HTTP security and electronic payment resulting from the World Wide Web research community to save considerable effort which would otherwise be necessary to implement such in some separate framework for mobile agents.
The term agent means many things to many people. This section defines a (mobile) agent for our purposes and gives a general overview of agent technology.
According to our dictionary [22], an agent is `anyone who acts on behalf or in the interest of somebody else'. Agent-based systems have recently gained considerable attention in computer science, although nobody has come up yet with a reasonably succinct definition of what an `agent' is actually supposed to be in this context. For the purposes of this paper, we assume that an agent is a computer program whose purpose is to help a user perform some task (or set of tasks). To do this, it contains persistent state and can communicate with its owner, other agents and the environment in general. Agents can do routine work for users or assist them with complicated tasks; they can also mediate between incompatible programs and thus generate new, modular and problem-oriented solutions, saving work.
Tasks that seem to be amenable to agents include electronic mail handling (an agent helps with prioritizing, forwarding, deleting, archiving, ...of mail messages [10]), scheduling of meetings (the people involved run agents that will negotiate a date and time, reserve a conference room etc.) or filtering an information source such as Usenet news for interesting bits according to various rules or heuristics.
Since agents consist of program code and the associated internal state, we can envision mobile agents which can move between computers in a network. An obvious application of this idea is in information retrieval, where it is easy to picture a mobile agent that gathers interesting data on some computer. If it has gone through all the available data, it moves somewhere else in order to find out even more tidbits before returning to its `owner' loaded with pertinent information. Of course the same information could be retrieved by the owner's computer itself using some suitable mechanism for remote access. The advantage of the agent-based approach is that complex queries can be performed by the agent at the remote side without having to transfer the raw data to the owner's computer first, which would likely waste considerable bandwidth. Other applications of mobile agents include active documents, electronic commerce (a hot topic in itself as far as the World Wide Web is concerned), network management, control of remote devices and mobile computing.
It is important to emphasize that, even if an environment supports mobile agents, agents are not required to move about. There may be agents for which there is no point in mobility, or others which are just too big. However, if the environment allows agents to communicate, mobile and stationary agents can fruitfully work together on behalf of their owners.
The interest in agents is fueled by the AI community as well as by researchers in the fields of distributed computing and communications. AI researchers tend to think of agents as entities that can observe and reason about the goings-on in their environment, while distributed computing scholars consider agents a new way of structuring distributed computer systems.
An overview of agents and, in particular, agent communication from the point of view of AI research is given by Genesereth and Ketchpel [12]. Kirn and Klöfer [21] discuss the applicability of organization theory to agent systems and examine their potential for `compound intelligence', while Kautz, Milewski and Selman [20] take a look at how agents can assist and simplify person-to-person communication. As an example of concrete experiments with AI-based agents, Etzioni and Weld [10] present a stationary agent (softbot) which helps its owner access Internet resources. It is of course legitimate to ask whether mobile agents are worth the trouble at all; this question is discussed by Harrison, Chess and Kershenbaum [16]. Eichmann [9] examines the issue of ethics for agents (including stationary `Web crawlers' or `spiders') on the Web.
Requirements for an agent infrastructure (or agent meeting point) are considered by Chess et al. [7]. Goldszmidt and Yemini [13] extend the notion of an agent infrastructure to encompass real-time control and system management. A proprietary agent infrastructure is described by White [26,27]. Proposals abound for agent implementation languages: (Safe-)Tcl [6,23], Java [14,18] and Telescript [27,28] seem to be some of the more important contenders.
In this section we consider the requirements that mobile agents place on the systems they're running on, and vice-versa.
To be useful, an agent needs to interact with its host system and other agents - it must access information that the host offers or negotiate with other agents about the exchange of services. Agents must also be able to move within heterogeneous networks of computers. This is only possible if there is a common framework for agent operations across the whole network: a standardized agent infrastructure. This infrastructure must offer basic support for agent mobility and communications. It must also protect the host from unauthorized access by agents and safeguard the agents' integrity as well as possible.
The basis of our architecture model for an agent infrastructure is the notion of an agent server. This is a program (like a mail server, FTP server, ...) which runs on every computer that will be accessible to agents and is in charge of the agents running on that computer. Its tasks include accepting agents, creating the appropriate runtime environments, supervising the agents' execution (in the meantime answering queries about their status) and terminating them if so directed. The agent server must also organize agent transfer to other hosts, manage communications among agents as well as between agents and their owners and do authentication and access control for all agent operations. In a network of agent servers, each individual server may be expected to participate in management operations such as the gathering of usage statistics.
We assume that each agent server knows about other agent servers in its `neighbourhood' and makes this information available to agents, who use it to pick a new destination when they decide to leave the host. Such `neighbours' do not have to be physically close to one another - for example, an agent server on a host which specializes in bibliographic databases could tell an agent about other servers that offer similar information. Thus no server (or agent) needs to know the topology of the whole network; if each server knows about its own vicinity, an agent will still be able to traverse an `interesting' subset of all servers. As a refinement, the list of neighbours presented to an agent can be customized according to the origin or purpose of the agent. That way, `firewall' schemes or domain boundaries can be realized.
For each agent running on a server, there is a dedicated runtime environment. The runtime environment interfaces between the agent and its host by making resources available to the agent in a controlled way.
The user interacts with the agent infrastructure through a client. The client will let the user submit an agent for execution, find out about its status, stop or recall it and perform other operations as necessary. It is important to note that the client does not need a permanent connection to the rest of the agent infrastructure; it can, for example, reside on a mobile computer that communicates with the fixed infrastructure via a slow radio link.
The main design guideline for our agent infrastructure is to allow maximum flexibility concerning the implementation of agents, their access to the host system(s) and their communication. We do not want to prejudice our research by constraining, e.g., the language to be used for agent implementation. Furthermore, we are convinced that a general infrastructure for mobile agents must provide `mechanism, not policy' in order to gain wide acceptance.
Figure 1 shows an overview of the various components of our agent infrastructure.
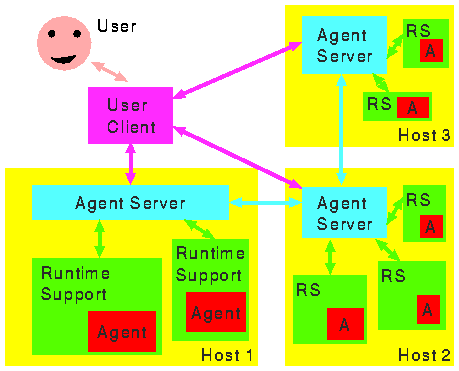
Before delving deeper into the details of agent support, we will examine the structure of a mobile agent more closely. A mobile agent contains
The model for agent communications in our infrastructure is based on an abstract information space which is maintained by each agent server on behalf of the agents in its charge. The information space contains triples consisting of an item's key (or name), an access control list and the item's value (Figure 2).
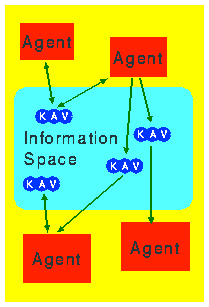
While the information space mainly serves as a means of communication among agents, it can also be used for communication between agents and the host system. For example, in a security-conscious environment, a trusted stationary agent could be endowed with the higher privileges necessary to gather some data and hand out summaries to visiting agents via the information space.
An obvious generalization of this approach to communications would be to allow access to a server's information space from agents running on other servers. However, such a `global' information space cannot be arbitrarily scaled up without serious loss of efficiency. Furthermore, it is unclear whether a global information space would lead to a worthwhile increase in functionality when it is easy for agents to move between hosts.
Finally, there should be a way for agents to communicate with their owners. A simple approach is to let the agent send electronic mail back to its owner; this asynchronous method ties in nicely with the fact that the owner is probably not on-line all the time, e.g., in a mobile computing environment. Synchronous communication is not much more difficult in principle: An agent might want to check back with its owner about some aspect of its operation, so after attracting its owner's attention by sending a mail message it could - in an HTTP-based framework - provide a Web form to be filled out by the owner and suspend itself until a reply arrives.
An agent server needs to provide runtime support to agents for various reasons: Firstly, agents must be able to take advantage of the agent server for communications and mobility services - therefore suitable primitives must be accessible from the agent implementation language. Secondly, agents are not supposed to misuse their access to the host system by, e.g., collecting its password file for off-site cracking or by formatting the main hard disk. Potentially dangerous operations such as executing arbitrary operating system commands or opening files or network connections must be tightly controlled. A runtime environment can do this by either completely outlawing them or else by vetting their arguments and endorsing an operation only if it is `harmless'. The most promising approach in this area is Safe-Tcl [5,6], which distinguishes between a trusted and an untrusted environment. The agent runs in the untrusted environment and may perform safe calls into the trusted environment. The trusted environment checks their validity and forwards them to the underlying system if they are acceptable.
It is important to note that the level of trust extended to an agent may vary considerably between agents. For instance, a locally developed agent is likely to be rather more trustworthy than some random piece of code coming in from the network. These different levels of trust can be accommodated by suitable selection of runtime environments, with a more highly trusted agent being allowed more freedom of access to the underlying system.
An agent infrastructure needs protocols for agent mobility and communication. Here we explain why the Hypertext Transfer Protocol (HTTP) seems to be a sensible choice.
Using HTTP as the basis of an agent infrastructure offers several advantages:
We have implemented a prototypical HTTP-based agent infrastructure which offers most of the features proposed in section "An Infrastructure for Mobile Agents". It consists of a custom HTTP server written in Perl [25] and a set of language-dependent modules providing runtime services to agents. We will include some details of our implementation at appropriate places during the following paragraphs; lack of space prevents us from a full discussion within the scope of this paper.
In HTTP, data (request/reply bodies) are transferred in a format based on MIME (Multipurpose Internet Mail Extensions, [4]). For the purposes of agent transport, we define an application-specific MIME-like content type, application/agent. This content type carries attributes describing, e.g., the programming language used and the agent type (say, library search agent). The agent server uses this information for choosing the right kind of runtime support or rejecting the agent if its requirements cannot be met.
The body of an application/agent part contains subparts corresponding to the agent's attributes, code and state (using content types application/agent-attributes, .../agent-code and .../agent-state, respectively). The agent-attributes subpart gives agent attributes (see section "A Mobile Agent Dissected") in a form similar to MIME headers (Figure 3). The format of the latter subparts is not specified further; it is assumed that their contents will be defined in a manner appropriate to the programming language used for the agent. If necessary, a suitable content transfer encoding can be applied to any of the subparts, supporting, e.g., agents compiled to some form of byte code.
From: lingnau@tm.informatik.uni-frankfurt.de
Date: Thu 13 Jul 1995 12:37:00 +0200
Content-Type: application/agent; boundary="AbCdEfG"; language="tcl";
type="silly"; context="default"
--AbCdEfG
Content-Type: application/agent-attributes
Owner: lingnau@tm.informatik.uni-frankfurt.de
Agent-ID: <a123.950713123700@deneb.tm.informatik.uni-frankfurt.de>
Home-URL: http://deneb.tm.informatik.uni-frankfurt.de:5055/home/a123/
Start-Date: Thu 13 Jul 1995 12:34:56 +0200
Expires: Thu 20 Jul 1995 12:34:56 +0200
Log: deneb.tm.informatik.uni-frankfurt.de Thu 13 Jul 1995 12:34:56 +0200
rigel.tm.informatik.uni-frankfurt.de Thu 13 Jul 1995 12:36:13 +0200
Authentication-Cookie: * fa389df25671e4a515ca87efda149852
--AbCdEfG
Content-Type: application/agent-code
puts "This is a useless agent"
sleep $sleep if [llength $visit_list} {
set nextHost [lindex $visit_list 0]
set visit_list [lreplace $visit_list 0 1]
agent moveto $nextHost
} else {
agent quit
}
--AbCdEfG
Content-Type: application/agent-state
set sleep 60
set visit_list {arktur algol}
--AbCdEfG--
We have to distinguish two cases: a new agent being submitted to a server for the first time, and an agent moving from server to server of its own accord. In the first case, the server must be established as the home server for this agent, which will be keeping track of the agent's progress through the network. In the second case, the home server must be notified by the new server that the agent has moved to a new location.
Generally, an agent is moved by POSTing it to a special URL [3] managed by the agent server (server/create or server/move, respectively, in our implementation, where server is short for http://host:port). The agent server parses the agent, checks whether it is acceptable according to the server's policies and the agent's requirements as expressed by its attributes, and launches it in an appropriate runtime environment. In the case of a new agent, the client (owner) is returned a new URL identifying the agent for the purpose of status queries (the home URL - in our implementation it is of the form server/home/id, where id uniquely identifies the agent on this server); in the case of an agent moving between servers, the target server assigns a temporary visitor URL (server/visit/id) to the agent and POSTs this to the agent's home URL to notify the home server of the agent's new location.
Our agent server spawns a new process for each agent and its runtime environment. This separates the agent from its peers and the server, increasing security and the flexibility of the runtime support - this approach is instrumental in allowing agents implemented in arbitrary languages. It also makes it possible to take advantage of `resource limits' that the operating system can impose on processes to enforce limitations on the CPU time or memory used by agents.
Once an agent has been submitted to the infrastructure, its owner can query its status by accessing its home URL. Since the home server is kept up-to-date as to the whereabouts of the agent, it can issue an appropriate HTTP code 302 `moved temporarily' response specifying the current visitor URL of the agent. These will be handled transparently by most Web clients, giving the agent owner apparently instantaneous access to the agent. Such a status query returns a HTML document which not only advises the owner of the status of the agent, but also allows more detailed examination of attributes or part of the state (for example, a partial result) via links to special URLs. In our implementation, URLs like visitorURL/attributes or visitorURL/state are used for this purpose; again, these can be accessed via the home URL by redirection. More URLs are available for stopping or recalling the agent, e.g., visitorURL/recall.
HTTP lends itself not only to agent transport, but also to agent communications. The `information space' discussed in section "Agent Communications" can be implemented as part of the agent server, accessible via a mechanism similar to other database queries. Information items can be added to the information space by POSTing them to a URL (server/info?key), with the access list information given in an Access: entity header. Suitable content transfer encoding allows values of arbitrary content and size (subject to space limitations on the server) to be entered as the message contents. The GET method is used to read information items, and a DGET method can be introduced into the HTTP protocol to enable atomic `destructive GET' for retrieving and removing an item in a single operation.
Another feature that would be nice to have is the ability of agents to be notified asynchronously of changes in the information space that are interesting to them. For example, an agent may want to be informed when a new agent turns up at the server or whenever a new piece of information has been put into the information space by its `opposite number' during negotiation. While an agent could find out about this by periodically polling the information space, asynchronous notification will be much more efficient. This is not currently implemented by our infrastructure, but work is underway to support this in the near future.
Security is important in all operations related to the agent infrastructure. We have already discussed the need for protection of host systems from interference by agents and vice-versa. In addition to this, an agent infrastructure must cater for encryption and authentication:
In the second case, we want to restrict access to a server's information space to the agents running on this server. The server and an agent's runtime environment can agree on a magic cookie; since this will never be passed across the network it should be sufficient as a first approximation to provide the needed authentication.
Mobile agents have recently generated considerable interest from researchers in distributed systems, electronic commerce, information retrieval, the World Wide Web and AI. To support experiments in this area, we have implemented a low-level infrastructure for mobile agents in an HTTP-based framework. The framework consists of a specialized HTTP server and language-specific modules that provide runtime support to agents written in various languages (we have until now concentrated on Tcl and Perl; others would be straightforward to integrate). Agents can employ various styles of interaction through a common information space as well as take advantage of customized runtime environments for specific tasks at different levels of trust. The framework also allows for stationary agents as a special case, making it possible to construct hybrid systems of agents.
Our aim is now to gain experience in the design, implementation and use of mobile agents based on our infrastructure. Ongoing projects in our group include applications in scheduling meetings and filtering Usenet news; other areas under initial investigation are system monitoring and semantic routing.
Another set of open problems concerns encryption and authentication in our agent infrastructure (section "Security Considerations"). These matters have not yet attracted due attention in our implementation, but in order to promote consistency and avoid duplicate effort we are waiting for a standard for HTTP encryption and authentication to emerge from the World Wide Web community. In the meantime we plan to provide schemes which are sufficient to foil the efforts of `casual' crackers.
Agent navigation still poses a number of questions. How will an agent decide where to go next? Besides semantic routing, the use of hyperspace mapping tools like WebMap [8] may help in locating `interesting' places. This is also a topic for future research.
1. Anderson, Scot and Rick Garvin, Sessioneer: flexible session level authentication with off the shelf servers and clients, Computer Networks and ISDN Systems, 27(6):1047-1053, April 1995.
2. Berners-Lee, T., R. T. Fielding, and H. Frystyk Nielsen, Hypertext Transfer Protocol - HTTP/1.0, Internet Draft draft-ietf-http-v10-spec-00, HTTP Working Group, March 1995, Work in progress.
3. Berners-Lee, T., L. Masinter, and M. McCahill, Uniform Resource Locators (URL), RFC 1738, Network Working Group, December 1994.
4. Borenstein, N. and N. Freed, MIME (Multipurpose Internet Mail Extensions) Part One: Mechanisms for Specifying and Describing the Format of Internet Message Bodies, RFC 1521, Network Working Group, September 1993.
5. Borenstein, Nathaniel and Marshall T. Rose, MIME Extensions for Mail-Enabled Applications: application/Safe-Tcl and multipart/enabled-mail, Distributed as part of the Safe-Tcl 1.2 distribution available over the Internet, November 1993, Working Draft.
6. Borenstein, Nathaniel S., EMail With A Mind of Its Own: The Safe-Tcl Language for Enabled Mail, Distributed as part of the Safe-Tcl 1.2 distribution available over the Internet, 1994.
7. Chess, David et al., Itinerant Agents for Mobile Computing, IBM Research Report RC 20010 (03/27/95), IBM Research Division, 1995.
8. Dömel, Peter, WebMap - A Graphical Hypertext Navigation Tool, In Proc. 2nd International WWW Conference, Chicago, IL, December 1994.
9. Eichmann, David, Ethical Web Agents, In Proc. 2nd International WWW Conference, December 1994.
10. Etzioni, Oren and Daniel Weld, A Softbot-Based Interface to the Internet, Communications of the ACM, 37(7):72-76, July 1994.
11. Genesereth, M. R., R. E. Fikes, et al., Knowledge Interchange Format Version 3 Reference Manual, Logic-92-1, Stanford University Logic Group, January 1992.
12. Genesereth, Michael R. and Steven P. Ketchpel, Software Agents, Communications of the ACM, 37(7):48-53, 147, July 1994.
13. Goldszmidt, Germán and Yechiam Yemini, Distributed Management by Delegation, In Proc. of the 15th International Conference on Distributed Computing Systems, pages 333-340, Vancouver, Canada, May 1995. IEEE Computer Society, IEEE Computer Society Press.
14. Gosling, James and Henry McGilton, The Java Language Environment: A White Paper, Technical Report, Sun Microsystems, 1995.
15. Hallam-Baker, Phillip M., Shen: A Security Scheme for the World Wide Web.
16. Harrison, Colin G., David M. Chess, and Aaron Kershenbaum, Mobile Agents: Are they a good idea?, IBM Research Report, IBM Research Divison, March 1995.
17. Hickman, Kipp E. B., The SSL Protocol, Draft Memo, Netscape Communications, February 1995.
18. Hohl, Fritz, Konzeption eines einfachen Agentensystems und Implementation eines Prototyps, Diplomarbeit, Universität Stuttgart, August 1995.
19. Hostetler, Jeffery L. et al., A Proposed Extension to HTTP: Digest Access Authentication, Internet Draft draft-ietf-http-digest-aa-01, HTTP Working Group, March 1995, Work in progress (expires 9/1995).
20. Kautz, Henry, Al Milewski, and Bart Selman, Agent Amplified Communication, In AAAI-95 Spring Symposium on Information Gathering from Heterogeneous, Distributed Environments, Stanford, CA, March 1995.
21. Kirn, Stefan and Andi Klöfer, Verbundintelligenz kooperativer Softwaresysteme: organisationstheoretische Grundlagen, Stand der Technik und Forschungsaspekte, KI, 2:20-28, February 1995.
22. Meyers Enzyklopädisches Lexikon, Bibliographisches Institut, Mannheim, 1971.
23. Ousterhout, John K., Tcl and the Tk Toolkit, Addison-Wesley, Reading, MA, 1994.
24. Rescorla, E. and A. Schiffman, The Secure HyperText Transfer Protocol, Internet Draft, Enterprise Integration Technologies, December 1994, Work in progress.
25. Wall, Larry and Randal L. Schwartz, Programming Perl, O'Reilly Associates, Sebastopol, CA, 1990.
26. White, James E., Mobile agents make a network an open platform for third-party developers, Computer (IEEE Computer Society), 27(11):89-90, November 1994.
27. White, James E., Telescript Technology: The Foundation for the Electronic Marketplace, General Magic White Paper GM-M-TSWP1-1293-V1, General Magic, Inc., 2465 Latham Street, Mountain View, CA 94040, 1994.
28. White, James E., Telescript Technology: An Introduction to the Language, General Magic White Paper GM-M-TSWP3-0495-V1, General Magic, Inc., 420 North Mary Avenue, Sunnyvale, CA 94086, 1995.
Anselm Lingnau [http://www.tm.informatik.uni-frankfurt.de/~lingnau/]
Johann Wolfgang Goethe-Universität Frankfurt, Germany
Anselm Lingnau studied computer science
at Johann Wolfgang Goethe-Universität
and obtained his master's degree in 1993.
He is currently working as a researcher in the computer science department's
distributed systems/telematics group;
his main focus is on database issues in mobile communications,
but he is also interested in mobile agents,
programming and user environments,
and the foundations and applications of the Internet.
Oswald Drobnik
Johann Wolfgang Goethe-Universität Frankfurt, Germany
Oswald Drobnik received his doctorate degree in computer science
from the University of Karlsruhe in 1977.
After spending a year as a postdoctoral fellow at IBM Th. J. Watson Research
Center, he joined the faculty of the University of Karlsruhe in 1981
as a professor for distributed computing systems.
Since 1988 he has been Professor of Distributed Systems/Telematics
at Johann Wolfgang Goethe-Universität, Frankfurt.
Peter Dömel [http://www.tm.informatik.uni-frankfurt.de/Mitarbeiter/doemel.html]
Johann Wolfgang Goethe-Universität Frankfurt, Germany/General Magic, Inc.
Peter Dömel graduated from Johann Wolfgang Goethe-Universität
in 1993 with a master's degree in computer science.
After doing research with the University's distributed systems/telematics group
in application management, object mobility,
Web charting tools, and mobile agents
he left in 1995 to work for General Magic, Inc.