Warning:
This wiki has been archived and is now read-only.
RDF AND JSON-LD UseCases
Author : Sumit Purohit, Mark Harrison
Date : See History
Introduction
The collection of interrelated datasets on the Web is referred to as Linked Data and it can be used by various Semantic Web technologies (RDF, OWL, SKOS, SPARQL, etc.) that provide an environment where applications can query that data, draw inferences using vocabularies, etc [1] . All these technologies should provide data in a common format in order to facilitate on-the-fly data access or conversion. There have been many discussions among data generator, data publisher and data consumer communities about selecting a specific technology based on its validity, ease of use, learning curve, availability of tools in the commonly used programming environments etc.
This wiki page strive to address one of many question about use of RDF vs JSON-LD to store linked data. This page attempts to provide a general introduction of both the technologies and provide suitability analysis of various kind of applications to use either technology.
Assuming basic understanding of the user about LinkedData, the first and foremost point to note is that RDF and JSON-LD are NOT two mutually exclusive approaches. Following sections attempt to put more light on the topic.
RDF
The Resource Description Framework (RDF) is a language for representing information about resources in the World Wide Web. RDF is a graph based data model which provides a grammar for its syntax. Using this grammar, RDF syntax can be written in various concrete formats which are called RDF serialization formats. Most used serialization formats are Turtle, TriG, N-Triples, N-Quads and JSON-LD. RDFa is also a concrete syntax for RDF, but it was not defined by the RDF Working Group.
JSON-LD
From JSON-LD specification page [2]:
JSON-LD is a concrete RDF syntax as described in [RDF11-CONCEPTS]. Hence, a JSON-LD document is both an RDF document and a JSON document and correspondingly represents an instance of an RDF data model. However, JSON-LD also extends the RDF data model to optionally allow JSON-LD to serialize Generalized RDF Datasets. A Generalized RDF triple is a triple having a subject, a predicate, and object, where each can be an IRI, a blank node or a literal. A generalized RDF graph is a set of generalized RDF triples. A generalized RDF dataset comprises a distinguished generalized RDF graph, and zero or more pairs each associating an IRI, a blank node or a literal to a generalized RDF graph
The JSON-LD extensions to the RDF data model are listed in following subsection.
Differences with RDF
- In JSON-LD properties can be IRIs or blank nodes whereas in RDF properties (predicates) have to be IRIs. This means that JSON-LD serializes generalized RDF Datasets.
- In JSON-LD lists are part of the data model whereas in RDF they are part of a vocabulary, namely [RDF11-SCHEMA].
- RDF values are either typed literals (typed values) or language-tagged strings whereas JSON-LD also supports JSON's native data types, i.e., number, strings, and the boolean values true and false. The JSON-LD Processing Algorithms and API specification [JSON-LD-API] defines the conversion rules between JSON's native data types and RDF's counterparts to allow round-tripping.
JSON-LD was created for Web Developers who are working with data that is important to other people and must interoperate across the Web. As per one of lead editor of the draft The desire for better Web APIs is what motivated the creation of JSON-LD, not the Semantic Web. It starts at basics, assuming that the audience is a web developer with modest training. It strives to help developers get to the “adjacent possible” using commonly used web tools. It showcases the power of Linked Data without having to go through the somewhat steep learning curve that the Semantic Web usually has because of grand view of RDF, SPARQL, OWL etc.
Most of tool developer community perceives RDF data as a RDF/XML document which is only ONE OF the serialization format and probably not the easiest, cleanest serialization format of RDF data model. On the contrary JSON like syntax is well received because of ease of use. Most of highly used format such as RDF/XML, TURTLE etc serialized graph based RDF data model into a tree like structure of triples. On the contrary JSON-LD represent it as a graph. Although various recent formats such as TriG and N-Quads can represent multiple graphs. Also the allowed use of non-URI predicates presents a challenge for the overall semantic alignment of LinkedData.
It is important to underline that there is a need to educate/inform user community about the difference between data model(i.e. RDF) and a serialization format (i.e. RDF/XML, JSON-LD, TriG etc). Recommending a graph based, clean, easy to use RDF serialization format would be a good step that can help users to select/no-select JSON-LD based on their requirements. Following table lists few application categories with suitable data model approach.
| Application Category | RDF OR JSON-LD | Comments |
|---|---|---|
| Web API Application | JSON-LD | The syntax is designed to easily integrate into deployed systems that already use JSON, and provides a smooth upgrade path from JSON to JSON-LD |
| Browser based UI Application | JSON-LD | Huge amount of JSON based parsers, DOM manipulators, general purpose tools. Javascript is THE language for browser |
| Inference, Reasoning Based Application | RDF | Great support of reasoners and scalable triple stores |
| Expressive Query tools | RDF | Matured state of SPARQL 1.1 supporting property paths allows to write powerful and expressive query |
| Archive/Retrieval with RDBMS | JSON-LD | Great support of JSON base libraries |
| List Based Data Applications | RDF1.1 , JSON-LD | JSON-LD has built-in support for list as in JSON which was not available in RDF1.0. But with RDF1.1 rdf:List is an instance of rdfs:class |
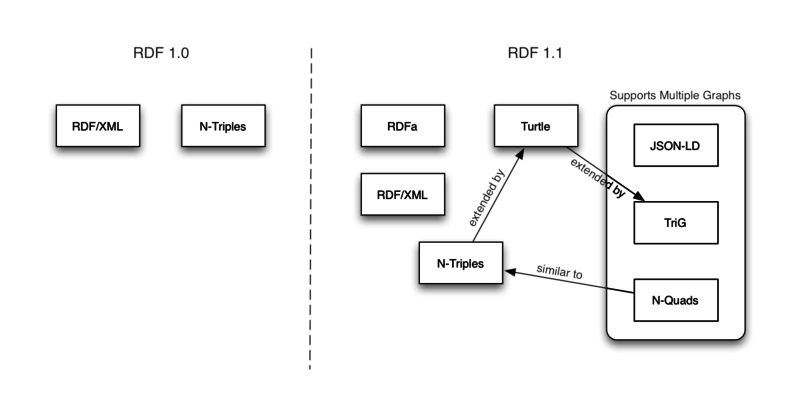 Image Source : http://www.w3.org/TR/rdf11-new/
Image Source : http://www.w3.org/TR/rdf11-new/
Support for internationalisation and multi-lingual strings
Just as RDF and RDFa support multilingual strings (e.g. for labels, descriptions etc.), this is also supported in JSON-LD - see Chapter 6.9 of the JSON-LD v1.0 W3C Recommendation: http://www.w3.org/TR/json-ld/#string-internationalization and examples 31-36 therein. In JSON-LD, the special key @language is used to indicate the specific natural human language of any non-typed plain string.
RDFa 1.1 uses the @lang property as well as the xml:lang declaration in an XHTML web page or the lang attribute in HTML. RDF Turtle uses language tags such as @de, @fr, e.g. "Allemagne"@fr or "Deutschland"@de - see http://www.w3.org/TR/turtle/#literals. In all situations, the alphabetic codes for the human language are those defined in ISO 639-1, typically using the 2-character lower-case codes. See also http://www.rfc-editor.org/rfc/bcp/bcp47.txt A list of ISO 639-1 language codes can be found at http://www.iana.org/assignments/language-subtag-registry/language-subtag-registry
The patterns to be used are explained at http://www.w3.org/TR/json-ld/#string-internationalization See in particular example 34: a language map expressing a property in three languages:
{
"@context":
{
...
"occupation": { "@id": "ex:occupation", "@container": "@language" }
},
"name": "Yagyū Muneyoshi",
"occupation":
{
"ja": "忍者",
"en": "Ninja",
"cs": "Nindža"
}
...
}
More Use Cases
JSON-LD can be used as a way to embed structured data within web pages as a single block that appears within the <head> element of an HTML page. Note that this is quite a different approach from inline approaches to markup such as the use of RDFa or Microdata. There are of course advantages and disadvantages of each approach, as described below:
Inline markup (e.g. using RDFa or Microdata):
Advantages
- the semantic annotations can be accessed more easily from faceted browsers because the annotations appear very close to the human-readable information, typically using attributes such as
property(RDFa) oritemprop(Microdata). - it may be easier for search engines to trust that inline semantic markup is not providing misleading information, because the values (
Objectof RDF triples) are often associated directly with human-readable text on the web page.
Disadvantages
- adding inline semantic markup to existing web pages can be tricky and time-consuming when it is necessary to understand the existing page structure and the hierarchical nesting of various
<div>and<span>elements - and care must be taken to check that the RDF triples that can be extracted from the page are as intended, without mis-connected nodes or dangling nodes. Sometimes it is necessary to re-assert theSubjectof a set of RDF triples using the about attribute. - inline semantic markup can break very easily if further HTML edits are made to a semantically annotated page, without involving the semantic annotator in the discussion. A simple example of this is that the person adding the inline semantic annotations might use an attribute such as
property="schema:image"oritemprop="schema:image"to indicate that a specific image on the page is a depiction of theSubject. Now if someone else wraps an<a href>hyperlink around the annotated image, then the image is then considered to be aschema:imageproperty of the thing identified by the URL of the new hyperlink, rather than theschema:imageof the originalSubject. The original triple can be restored by inserting anaboutattribute within the<img>image tag - but it seems undesirable that this kind of defensive coding must be used merely to ensure that another web editor cannot easily break the RDF triples that were originally intended to be present.
Single block markup (e.g. using JSON-LD):
Advantages
- for users who are less familiar with the details of Linked Data technology or the use of inline markup (via RDFa or Microdata), they can be provided with JSON-LD templates that can be inserted as a single block of structured data within the
<head>element of a web page. They only need to populate the template with the correct data values. Since many data-driven websites are already using templates for the human-readable content of the<body>section of the web page, it should be fairly straightforward for them to include an additional template within the<head>section and use the same data to populate both the existing template for human-readable information and the new JSON-LD template for the machine-interpretable information. - the single block of JSON-LD markup is decoupled from the human-readable HTML markup appearing in the
<body>of the page, which means that if changes are made to the structure of the<body>section, there is much less risk of breaking or misconnecting the collection of RDF triples that can be extracted from the page. - many companies already use JSON within their websites, particularly for AJAX calls in which small pieces of information are exchanged between the browser and web-server after the page has loaded and without requiring reloading of the page. Via the
@contextheader of JSON-LD, any locally named properties / keys / predicates can be mapped to specific predicates in defined web vocabularies or ontologies, making the meanings of local names for properties globally unambiguous and also enabling the local structured data to be converted into RDF triples that can be exchanged with others, without ambiguity. This means that a block of JSON-LD data can continue to work with JavaScript local to the website or web application that only makes use of locally-defined names for properties, while also serving as a serialisation format for RDF triples that can be consumed and used by other external applications that might not otherwise know the precise meaning of locally defined names of properties.
Disadvantages
- because the it is more difficult for search engines to verify that the JSON-LD structured data is consistent with the visible human-readable information and that the JSON-LD block does not contain misleading information.
- because the single block of JSON-LD does not appear alongside the human-readable information, faceted browsers can not easily display contextual hyperlinks in close proximity to the annotated content, although overall, the same set of RDF triples is available in the page.
- tool support for ingesting and verifying JSON-LD is sometimes not as complete as for inline serialisations such as RDFa and Microdata, although JSON-LD is well supported by tools at http://json-ld.org/playground/ and http://linter.structured-data.org - but less well supported by http://www.google.com/webmasters/tools/richsnippets - and whereas a very useful tree graph visualisation of RDFa data is available via http://rdfa.info/play , there is not yet a corresponding visualisation tool available at http://json-ld.org/playground/
TODO: