
Sandro Hawke (sandro@hawke.org)
20 March 2012
MIT Decentralized Information Group
https://www.w3.org/2012/Talks/0320-crosscloud-sandro
This is an idea I've been incubating for a few years
• May 2009 posting to semantic-web@w3.org
Not my day job at W3C, but folks there are supportive
I've had a little support from a private foundation
• I did a partial implementation last year (weekend/holiday project)
I'd like to work on this more - TimBL and I are looking for funding
To work right, social apps need to reach everybody
• If I share my photos with you on Flickr ... you have to use Flickr
• This applies to every app that involves other people: scrabble, chess, chat, MMORPGs, FPSs, collaborative filtering, open source development, find friends nearby, shared calendars, ...
When an app reaches everyone:
• We all get to work together online
• But we are constrained by that one provider's limits
• It has monopoly power
When it only reaches some people:
• Other people are excluded
• We can't do things that require everybody
• We can't always do the things we want with the people we want
• Folks advocate for the monopoly, out of self interest.
The "standard" solution is standard protocols...
• email (RFC 821, 822)
• http (RFC 2616)
• xmpp (RFC 6120)
• ical (RFC 5546)
• vcard (RFC 2426)
But they
• are very expensive to create
• are even more expensive to change
• don't happen much (weak business case?)
• often don't work well (hard to iterate)
Is there a better way?
Social apps are "shared-state apps"
• Alice and Bob are looking at different screens.
• But they see the same world-state represented
• Alice makes a change
• They both see it.
Let's figure out shared-state apps
Usually implemented as Client-Server
• Client is the UI (a Viewer and Controller)
• Data lives on a central server

Formalize/Abstract that Client-Server interaction
Post
• Create/Update/Delete - change the world
Query
• Express what you want to know about the world
Results
• get the detailed results of your queries
post each move each player makes
[ a chess:Move;
chess:inGame <http://example.org/games/2454544>;
chess:player <http://www.w3.org/People/Sandro/data#SandroHawke>;
chess:move chess:c4c5;
chess:seq 7 ]
query for the moves the other player makes
• Could do this with polling
• Or Pub/Sub. Query=Subscription / Results=Notify
results will be the set of all moves the other player has made
... or query for the games out there
... or query for the moves from both sides of a particular game
Map designer posts all the details of the map
Players
• post each action done in the world
• query for walls, items, players, etc, nearby
• results will include all data the client UI needs
Fits nicely with RDF
c = PQR.connect(user_identity, user_authentication) c.post(rdf_graph) r = c.query(rdf_graph_pattern, filters) for binding in r: ...
By itself, this is nothing new.
SQL (Oracle, DB2, MySQL, ...)
NoSQL (MongoDB, CouchDB, Cassandra, ...)
SPARQL 1.1 Server
(Most are not engineered for streaming new answers, though)

A decentralized system where each node provides PQR
1. Each of the systems needs a good reason to participate
• people only adopt standards when they see the benefit
2. The system has to be fast enough, at scale
• acceptable latency: 1s turn-based; 0.1s "real time"
3. Information must only be shown to permitted parties
• read access control, secrecy, privacy
4. Query results must be correctly attributed
• write access control, data integrity, provenance
5. Posted information must remain available (until deleted)
• reliability, durability, high-availability
(What Else?)
Linked Data provides PQR platform, in some situations
Post = make new RDF pages appear somewhere on the Web
Query = dereference all the URLs used in the graph pattern
Results = parse, merge, graph match, filter what came back
Consider a typical FOAF scenario
This works for { eg1:sandro foaf:knows ?x }
• deref of eg1:sandro will find the foaf:knows triples I put there
It MIGHT work for { ?x foaf:knows eg1:sandro }
• If I happened to put in back links.
• Does anyone do that? (no)
It won't work for {?x foaf:knows ?y}
alice.org has the meeting info and times available
bob wants to tell the system his selections....
• alice.org provides a URL where he can post it
This works, but:
• Alice has to install meeting scheduling software
• Bob needs to trust Alice's to correctly count and remember his vote
Who hosts all the real-time game data?
Who controls who can see what?
How do I find what games Alice is playing, chess or otherwise?
How long will they keep the game data?
What if I want to play an unsupported chess variation?
Maybe Bob can post his actions to http://bob.example.com
• He can post his choices on Alice's Event1 poll
• He can post the moves he's making in various chess games
• He can post where's he's shooting in his FPS
(Of course it's really apps that are making these posts)
... and somehow everyone finds these posts
This is the core of my proposal.
1. Some people run RDF trackers, eg track.example.com
2. If you mint a URI for something, in its "home" document, put a triple saying which trackers you want used
{ <http://track.example.com> reg:tracks "http://alice.example.com/*"; }
3. When you use a URI, ping its trackers with your data's source URL
4. To find data using a URI, query its trackers for source URLs.
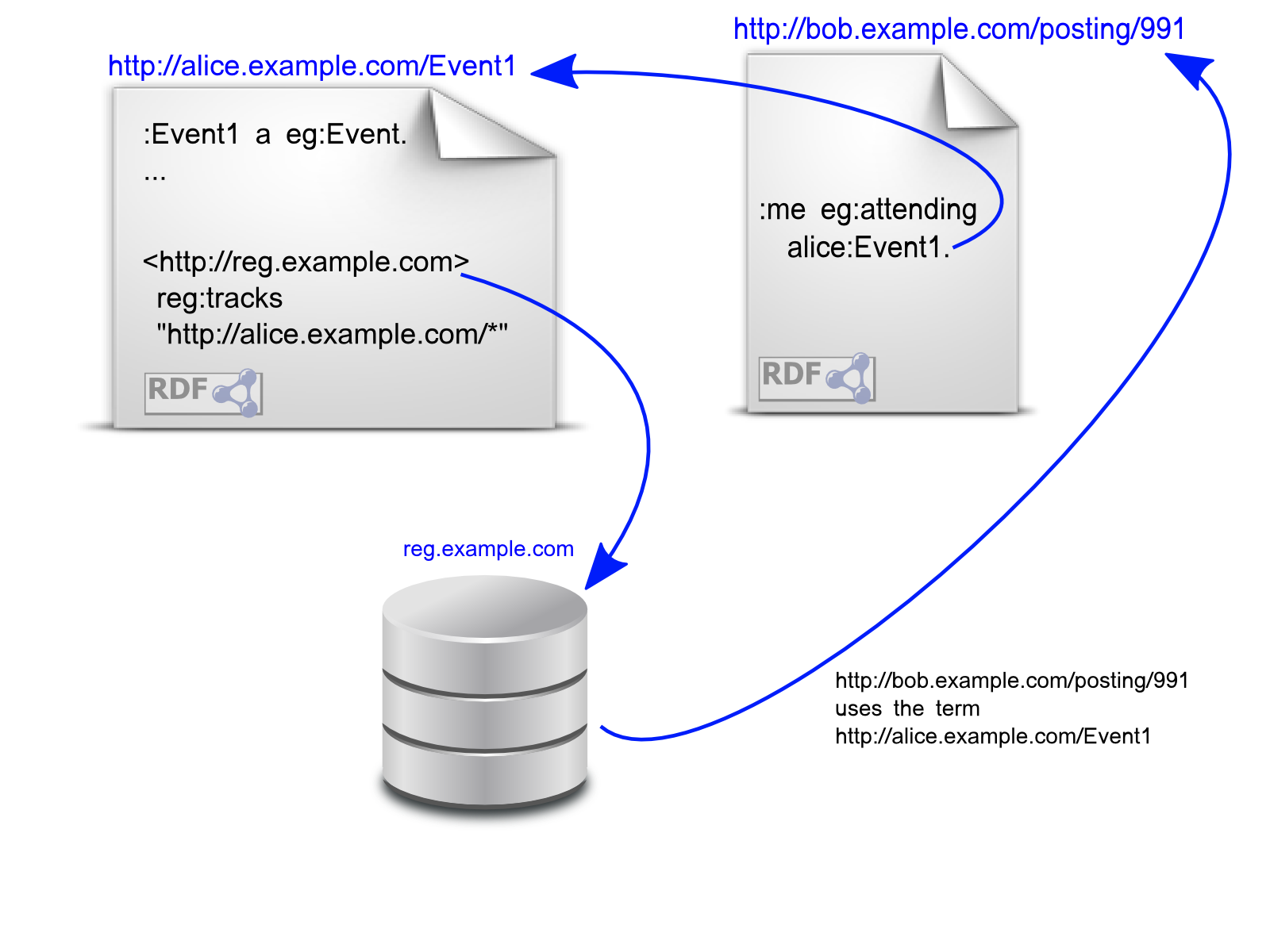
alice.org has the meeting info and times available
bob published on bob.org
bob 'registers' his data
• he looks up alice's trackers
• he notifies them
• (they may verify he is publishing data about event1)
• they may notify others that are currently querying
• they will answer future queries, giving bob's data URL
Now Alice and Bob and everyone justs hosts RDF data, and PQR works.
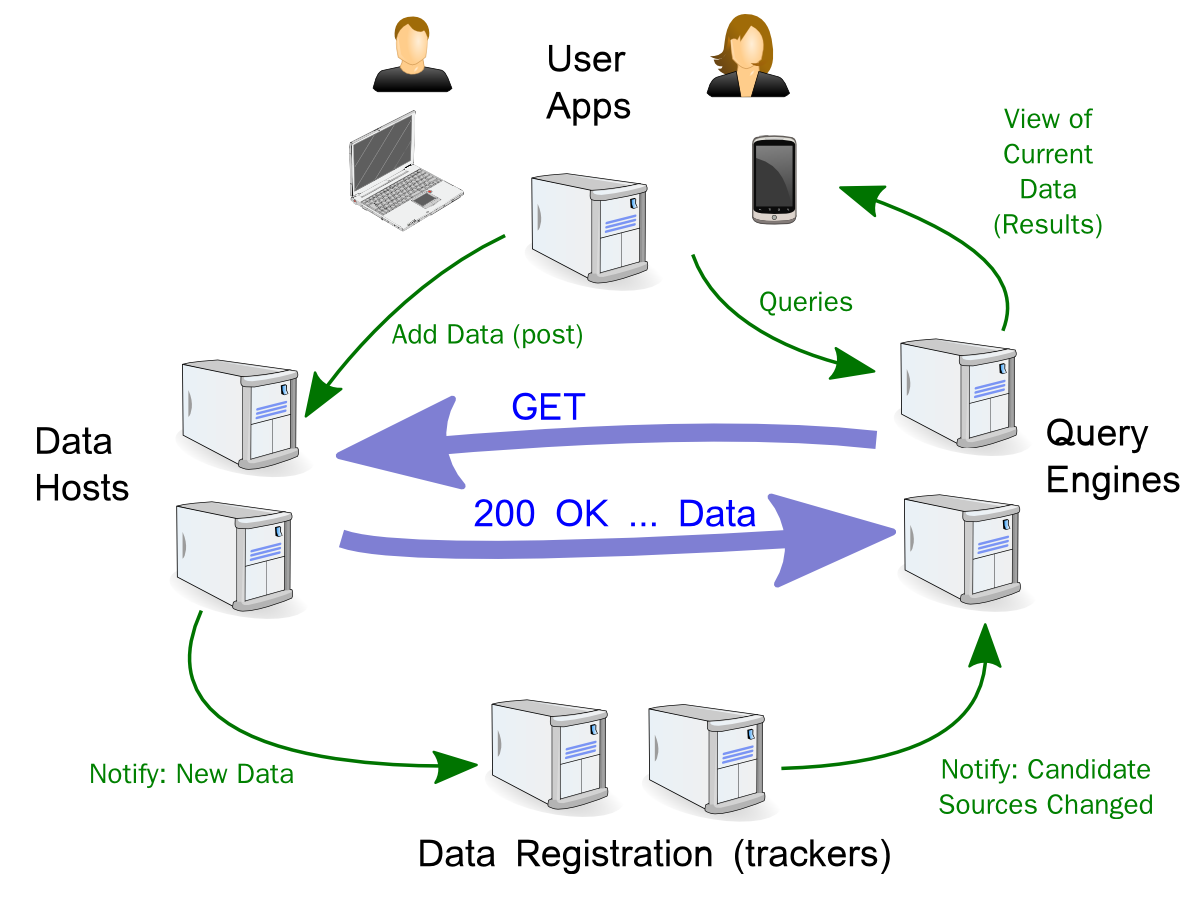
1. Each of the players needs a selfish reason to play
• publishers - yes, want their data out OR get paid
• trackers - get paid
• consumers - yes, want to find data; may pay
2. The system has to be fast enough, at scale
• Millions of small vocabs - works smoothly
• A few vocabs with millions of sources - that'll fund server farms
3. Information must only be shown to permitted parties (cf read access)
• it's just web identification/authorization
• (well, plus whatever trackers leak)
4. Query results must be correctly attributed (cf write access)
• Querier has all the URLs they came from
• Could use SSL and webfinger to tie them to email addresses
5. Post information must always be available (unless delete was authorized)
• Folks who did the post get to pick the server(s) where it goes
• They also get to pick the vocabs, and hense the trackers
• They MIGHT be unreachable if excluded by vocabs (eg licensing)
Merging Data (Social Merge)
• What if Bob and Alice say conflicting things?
Vocabulary Migration (Shims)
• How do we avoid being locked into Vocabularies, instead of apps?
RDF Sync
• Pub/Sub for changes in RDF data sources
Web Identity and Authorization
• WebID, OAuth2, etc, etc
Wire protocol / formats
Footprints
• Do we need to characterize large data sources?
SPARQL
• How do you refer to a Graph in a SPARQL Endpoint, etc?
High Availability
• Replication for hosts being down
• Replication for trackers being down
Business Models
• Can I query { ?s ?p ?o } if I'm willing to pay for it?
Prototype last year
• No logins
• No inference
• Sketchy protocol
• Demo: up/down votes of URLs; real time browser-to-browser
Looking for funding
• Applying for Deshpande Innovation grant (reviewers needed)