Privacy Enhancing Browser Extensions
| Editor: |
Dave Raggett (W3C) |
| Reviewers: |
Julio Angulo (KAU),
Leif-Erik Holtz & Ulrich König (ULD) |
| Identifier: |
D1.2.3 |
| Type: |
Deliverable |
| Class: |
External |
| Date: |
28 February 2011 |
Abstract
This document is a deliverable for the PrimeLife project and
describes three privacy enhancing Web browser extensions. The
first instruments the practices used by websites and third parties
to collect personal data and track users, as well as offering
users the means to set per site preferences. This extension was
further extended to automatically collect data on the top thousand
websites as listed by Google, and some preliminary results are
presented in this report.
The second browser extension provides a fresh take on P3P
(W3C's Platform for Privacy Preferences), using the vocabulary
defined by P3P for machine readable privacy policies covering
information collected from HTTP requests that web browser make to
web sites as part of the process of loading a web page. The
policies are constrained to make it easier to provide a user
interface for setting preferences, and for generating human
readable descriptions of the conflicts between the user's
preferences and the site's policy. The browser extension looks for
a link to the site's privacy policy which is represented in JSON
(JavaScript Object Notation) for ease of processing.
The third browser extension explores the potential for privacy
enhancing Web authentication using zero knowledge proofs, and is
based upon the Java-based Identity Mixer library developed by IBM
research.
Members of the PrimeLife Consortium
| 1. |
IBM Research GmbH |
IBM |
Switzerland |
| 2. |
Unabhängiges Landeszentrum für
Datenschutz |
ULD |
Germany |
| 3. |
Technische Universität Dresden |
TUD |
Germany |
| 4. |
Karlstads Universitet |
KAU |
Sweden |
| 5. |
Università degli Studi di
Milano |
UNIMI |
Italy |
| 6. |
Johann Wolfgang Goethe - Universität
Frankfurt am Main |
GUF |
Germany |
| 7. |
Stichting Katholieke Universiteit
Brabant |
TILT |
Netherlands |
| 8. |
GEIE ERCIM |
W3C |
France |
| 9. |
Katholieke Universiteit Leuven |
K.U.Leuven |
Belgium |
| 10. |
Università degli Studi di
Bergamo |
UNIBG |
Italy |
| 11. |
Giesecke & Devrient GmbH |
GD |
Germany |
| 12. |
Center for Usability Research &
Engineering |
CURE |
Austria |
| 13. |
Europäisches Microsoft Innovations
Center GmbH |
EMIC |
Germany |
| 14. |
SAP AG |
SAP |
Germany |
| 15. |
Brown University |
UBR |
USA |
Disclaimer: The information in this
document is provided "as is", and no guarantee or warranty is
given that the information is fit for any particular purpose. The
below referenced consortium members shall have no liability for
damages of any kind including without limitation direct, special,
indirect, or consequential damages that may result from the use of
these materials subject to any liability which is mandatory due to
applicable law. Copyright 2011 by IBM Research GmbH, Unabhängiges
Landeszentrum für Datenschutz, GEIE ERCIM, Katholieke
Universiteit Leuven, Università degli Studi di Bergamo, Center
for Usability Research & Engineering.
List of Contributors
The work described in this report includes contributions from
several PrimeLife partners. Peter Wolkerstorfer (CURE) and Rigo
Wenning (W3C) helped with the user interface design described in
Chapter 2. Patrik Bichsel (IBM) helped with the work on anonymous
credentials described in Chapter 5.
Thanks are offered to Julio Angulo (Karlstads Universitet), and
to Leif-Erik Holtz and Ulrich König (Unabhängiges Landeszentrum
für Datenschutz Schleswig-Holstein) for their detailed and
thoughtful reviews of the draft report.
This deliverable was rendered from HTML pages using PrinceXML from
YesLogic Pty
Ltd. YesLogic has donated a license of PrinceXML to W3C.
Introduction
The World Wide Web has given us easy access to a wide range of
online services, often free of charge. Businesses have looked to
advertising as a way of recouping their costs, and this has led in
turn to an increasing focus on tracking users as a basis for
crafting measurably more effective advertising. Starting from
analysis of basic logs of HTTP traffic, websites have looked for
ever richer ways to track users as they move across a site, across
repeated visits to sites, and across different sites. This has
been accompanied by an evolving ecosytem of companies, for
example, web site owners, content distributors such as akamai,
companies providing support for analytics, such as Google
analytics and Quantcast, advertising networks such as DoubleClick
(Google) and RightMedia (Yahoo!). What does this mean for users'
privacy and what steps can they take to safeguard it?
Privacy means different things to different people, and it is
perhaps easier to define in terms of the consequences of a lack of
privacy. In order of decreasing importance, here are three levels
of consequences:
- harm that you can suffer, e.g., loss of life or livelihood,
persecution on account of your beliefs or other factors
- loss of face, e.g., in front of your family, friends,
colleagues or in public
- loss of control, where you are unable to control information
that you may prefer to remain strictly private
This report will describe work on a suite of browser extensions
that focus on different aspects of privacy. The first Chapter
briefly reviews previous work on privacy related browser
extensions. The second Chapter looks at what techniques websites
are using to track users, before introducing the Privacy
Dashboard, which provides a means for users to examine website
practies and to set per site preferences as a way of reclaiming a
degree of control over their privacy.
Chapter 3 describes work on applying the Privacy Dashboard to
automatically collect data from the top thousand websites as
listed by Google, and looks at the dense web of relationships
between the public facing sites and the ecosystem of supporting
sites on the dark side of the Web. An account is given of the
complementary roles of automated and manual data collection.
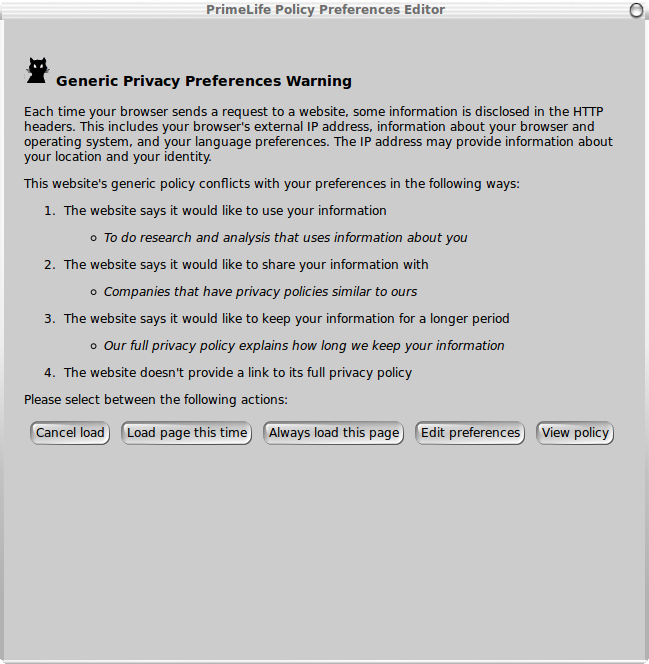
W3C's Platform for Privacy Preferences (P3P) has had limited
success in its original aims to allow users to express their
preferences and have these matched against the privacy policies
published by websites. One significant factor behind this, is the
high degree of flexibility that sites have in how they express
policies with P3P. This has made it difficult to create effective
user interfaces for setting preferences. Chapter 4 describes work
on an experimental browser extension that addresses this by
constraining policies and expressing them in the JavaScript Object
Notation (JSON). The approach is then compared with the topical
proposal for a "do not track header".
The last Chapter describes work on minimizing the disclosure of
personal information through the use of anonymous credentials, in
which zero knowledge proofs are used to show that the user is in
possession of credentials from a trusted issuer. For example, you
could demonstrate that you have a government issued credential
giving your date of birth, and prove to the website that you are
at least 18 years old, but without disclosing your name or actual
age.
The report ends with a collection of references for further
reading.
Previous Work
The Firefox web browser provides a mechanism for downloading
and installing browser extensions written as a cross-platform
package of markup, scripts, style sheets and other resources.
These browser extensions (sometimes referred to as "add-ons") run
in an elevated security mode compared to web page scripts, and
have access to a rich suite of application programming interfaces
(APIs). These include the ability to eavesdrop on HTTP requests
and responses, and to provide a user interface separate from that
of web pages.
This flexibility has been exploited in a range of browser
extensions relating to privacy. Mozilla provide a list of
privacy and security related extensions for the Firefox browser:
Here are a selection of them:
BetterPrivacy
This extension attempts to protect against lasting cookies that
are hard to delete. Cookies are pieces of information that the web
browser stores on behalf of the website, and can be used to a
variety of purposes, e.g., authentication, site preferences,
shopping cart contents and tracking the user across a repeated
visits to the site. Some sites use scripts to automatically
recreate HTTP cookies whenever users instruct the browser to
delete them. This is possible by redundantly storing information
in other ways, e.g., as Flash cookies (aka Flash shared objects, a
means for Flash applications to store data in the user's
computer), or in DOM storage (a means for web page scripts to
store data in the browser for retrieval in subsequent visits to
that website).
Adblock Plus
This provides a means for removing online advertising and
blocking well known malware domains. It does so using filters
provided as part of a subscription. These are maintained and shared
amongst AdBlock Plus users. Filters can either block the download
of content that is external to a web page, or they can hide parts
of web pages so that advertisments are no longer visible.
NoScript
This extension blocks JavaScript, Java, Flash and other plugins
except for those sites you trust. You can authorize a temporary
override when you need to, and allow scripts from a site to
execute whilst disabling scripts from third parties. NoScript also
includes some measures to combat cross-site scripting attack, e.g.,
when a given site tries to inject JavaScript code inside a white
listed site.
Taco
The Targeted Advertising Cookie Opt-Out (TACO) installs
permanent opt-out cookies that instruct advertising networks to
avoid applying behavioral advertising techniques. Adverts may
still be chosen on the basis of web page content, but not upon
your browsing behaviour. This depends on the advertising network
honoring the cookie, and not all such networks support opt-out
cookies. If users clear their cookies, the extension detects this
and reinstalls the opt-out cookies. Taco was developed by
Christopher Soghoian and later taken over by Albine, Inc.
TrackerBlock
This blocks specific sites from reading or writing cookies on
your browser. To select which advertising sites are blocked, users
visit a web page operated by PrivacyChoice. This page is
essentially a web page form with radio boxes for each network. The
page sets a cookie with your opt-out preferences.
PrivacySuite
This is an extension of Taco with support for managing and
deleting HTTP, Flash and Silverlight cookies as well as DOM
storage.
Garlik
This isn't a browser extension, but rather a service that
carries out frequent scans of a wide range of sources for evidence
of misuse, for instance, informing you as a subscriber when your
personal details are being traded online, when a website has
published your sensitive or personal information, or when someone
has set up a postal redirect on your name to steal your mail.
Privacy Dashboard
This Chapter describes work on a Firefox browser extension that
enables users to see how websites are tracking them online, and
allows users to set per site preferences, e.g., to block third
party content or cookies.
A Survey of Tracking Techniques
What techniques are available for websites to track users, and
how can these be detected? This Section presents a brief survey of
tracking techniques as they existed at the time of writing this
report.
IP Addresses
Every HTTP request carries the Internet Protocol (IP) address
of the client. Analysis of HTTP logs can thus provide information
about which clients accessed what resources and when, thereby
providing information about people's browsing habits. The IP
address can be used to identify the originating network and to
narrow down the geographic location. The identity of the
originating client may be masked:
- It is common practice for the Internet to be accessed through
a Network Address Translation (NAT) gateway. The HTTP logs will
then show the IP address of the gateway and not that of the
originating device.
- The request may have passed through an HTTP proxy server, in
which case the HTTP logs will show the IP address of the proxy
server and not that of the originating device. In many cases
users may not even be aware that there is an HTTP proxy, as all
external HTTP traffic may be routed though a proxy to filter
requests, and to gain benefits from caching responses. Note that
proxy servers may provide information about the originating client
in headers added to the forwarded request.
- The client may have a dynamically assigned IP address. This
is common practice for dial up connections, DSL lines and cable
modems.
Hidden Form Fields
HTML forms include support for hidden fields that the browser
hides from view, e.g.,
- <input type="hidden" name="id" value="573925654">
The value of such fields is passed back to the server when
the user submits the form. This technique breaks down when the
user leaves a web page after clicking on a hypertext link rather
than submitting a form.
Dynamic URLs and URL Parameters
An earlier technique for tracking users was for servers to
make use of dynamic URLs where some kind of identifier is embedded
as part of the URL itself, or as part of a parameter passed with
the URL, e.g.,
- http://example.com/3657473
- http://3657473.example.com/
- http://example.com?id=3657473
The server dynamically creates web pages to ensure that all
links from the page to other parts of the website use the
appropriate dynamic URL. This allows the server to track users as
they move through a website. When the user first appears at the
site, the server can use an HTTP redirect response (with a 302 or
303 status code) to redirect the browser from the generic URL to
the dynamic URL. Alternatively, the assignment of the id can be
made when generating the initial page.
Drawbacks of this approach include an increased load on the
server due to the need to dynamically generate the pages. This can
be avoided by using a static HTML page together with a web page
script that effectively rewrites all of the link addresses.
However, servers will still see more hits as proxy servers will be
unable to use the same cache entry to serve requests from
different clients. Another drawback is that users can see the
dynamic URL in the browser location field. One advantage is that
the server can track users across visits if the user has
bookmarked the dynamic URL.
HTTP Cookies
These are strings that are set by a website or a web page
script and served back to subsequent requests to that site. They
make use of HTTP headers. The server response includes the
Set-Cookie header to set a cookie, and the client request includes
the Cookie header to pass a cookie back to the server.
Cookies were originally proposed as a means to store online
shopping baskets in the browser, to mimimize the resource demands
on web servers. They were soon used to track users across a website
during a single visit, and across visits to a site. Session cookies
are automatically deleted by browsers when the browser is shut down,
but lasting cookies are kept until they expire as indicated by the
expires or max-age parameter as given with the Set-Cookie header,
e.g.,
- Set-Cookie: lovefilm_session=8a05ae1f5f88e1a2325b62c34080e7d5;
domain=.lovefilm.com; path=/; expires=Tue, 02-Aug-2011 12:03:50 GMT
The Domain and path parameters instruct the browser to only send
a cookie to a server if the URL matches the given domain and path.
If not specified, they default to the domain and path for the
request that resulted in the response with the Set-Cookie header.
This provides considerable flexibility, enabling websites to share
cookies with all servers with the same base domain. Larger websites
often make use of a number of servers with the same base domain,
as a means to optimize performance. To avoid cookies being shared
with unrelated sites, browsers block cookies with domains like
".com" or ".co.uk". This involves checking against a public suffix
list, which is both very long and regularly changes, thereby
necessitating the browser having to frequently check for updates.
Third-Party HTTP Cookies
Web pages may use third party sites for images, scripts and other
resources that are loaded by the browser as part of the page. These
sites can set their own cookies. This allows third parties to track
users across all of the websites using that third party. Such third
parties can play a variety of roles such as helping a website with
analysing the behaviour of their visitors (e.g., Facebook Beacon),
helping with content distribution (e.g., Akamai), or for advertising
(e.g., Google Adsense, AdBrite, Yahoo, and Blue Lithium).
Browsers may provide a means to block third party cookies, e.g.,
if the corresponding sites don't support P3P. The inclusion of
this feature in Microsoft's Internet Explorer web browser has
encouraged the adoption of P3P by third party sites, see e.g., the
September 2010 CMU report by Leon, Cranor, McDonald and McGuire [1],
and the associated New York Times article [2]
Browser Settings
Browsers generally provide support for users to enable or
disable cookies completely, but blocking cookies will have a
significant impact on the user experience, and some sites require
cookies to be enabled in order to use their services. Most
browsers allow users to clear out all cookies, and some browsers
allow this to be done on a per site basis. To block cookies on a
per site basis typically requires the use of a browser extension.
A further problem discussed later in this report is the emergence
of super cookies which are automatically re-installed whenever the
user deletes them.
Opt-Out Cookies
The US National Advertising Initiative (NAI) publishes a list of
opt-out cookies on behalf of its members for the purpose of
enabling consumers to opt out of behavioral advertising
delivered by these members. Consumers can selectively set these
cookies by checking boxes on the web page provided by the NAI for
this purpose [3].
As noted in the earlier description of previous work, such cookies
will need to be re-installed if the user clears all cookies, or
switches to a new browser, or to a browser on another device. This
is a significant problem since it is now common for people to own
multiple devices with web browsers.
See Section 2.2.3.1 for a discussion on
alternative approaches based upon HTTP headers, and the amended
E-privacy directive that requires user consent for
tracking.
Adobe Flash Player
The Adobe Flash Player plugin is very widely installed in web
browsers, and as of December 2010, Adobe cites over 99% penetration
for mature markets and 97% in emerging markets [4]
Flash is used extensively for advertising thanks to its support
for animation, multimedia, and its flexible scripting language.
Flash provides a rich suite of APIs for developers, including
support for making network requests, accessing device capabilities,
and storing limited amounts of information locally on the device.
This can be used to track users in an analogous fashion to using
HTTP cookies, and Flash Shared Objects are often referred to as
Flash Cookies. The inability for browser extensions to hook into
network traffic from the Flash Player is an issue that will be
picked up later in this Chapter.
Note: Adobe provides a website that can be used to view what
Flash cookies are currently set, and to clear them on a per website
basis [5]
DOM Storage
With the introduction of HTML5, modern browsers provide
additional means for web page scripts to save data locally on the
device. Similar to cookies, data can be stored for the duration of
the browser session or permanently. The size limits are much
larger than for cookies, e.g., several megabytes per domain. Web
page scripts can read and write this data, and exchange it with
the website via HTTP.
HTML5 Ping Attribute
Another feature introduced in HTML5 is support for a "ping"
attribute that can be used with links to give a list of URLs
for resources that are interested in being notified if the user
follows the link. The browser then makes an HTTP POST request to
all of the listed URLs. This allows websites to see which offsite
link the user followed when leaving the website.
Note: this feature is disabled by default in Firefox 4.
Web Bugs
This is a generic name for one of a number of techniques used
specifically for surreptitiously tracking users when loading a web
page or opening an HTML email. One such approach is to include an
image that will be loaded from a third party. This image may be
invisible, either by it being transparent, setting its extent to a
single pixel, or by hiding it in some other way, e.g., by a style
sheet rule. The approach isn't limited to images and any kind of
resource that the browser will load in order to render the page
will do.
Google Analytics is a very popular service provided by Google to
websites for collecting and analysing data on their users' visits.
The website includes a small piece of JavaScript in every page.
This programmatically sets a first party cookie, and reports the
user data to Google's servers via a hidden image functioning as a
web bug. Google periodically analyses the data it collects and
makes this available to the website owners.
Device Finger Prints
This refers to techniques which combine different sources of
information available to a web page script in an attempt to
uniquely identify a device. The Electronic Frontier Foundation's
Panopticlick project found in a study [6] of nearly half a million
browsers that 83.6% have a "instantaneously unique fingerprint."
The number jumped to 94% for browsers using Adobe Flash and
Oracle’s Java plug-ins. In addition, only 1% of plug-in users'
browsers had fingerprints that were seen more than twice.
Some of the characteristics collected are:
- Browser user agent string
- HTTP Accept headers
- Browser plugin details
- Time Zone
- Screen size, and colour depth
- System Fonts
- Are cookies enabled?
- Is DOM storage supported?
One motivation for using device finger prints is to enable
advertising networks to determine the number of unique visitors
to a site.
The "evercookie"
In 2010, Security researcher Samy Kamkar published a JavaScript
library [7] for extremely persistent cookies that survive casual
attempts to delete them. This was featured on the front page of
the New York Times [8], and in an article by John Turner for
arstechnica [9].
According to Kamkar, The evercookie library draws upon
techniques that he discovered when investigating how advertisers
tracked him on the Web. Evercookie redundantly stores the cookie
data in multiple places:
- Standard HTTP cookies
- Flash cookies
- Silverlight Isolated storage
- Encoded pixel values in auto-generated, force-cached
PNG images, and using the HTML5 canvas API to read back pixel
values
- The browser's web history
- HTTP ETags
- The browser's web cache
- window.name caching
- Internet Explorer's userData storage
- HTML5 DOM storage (session, local and global)
- HTML5 database storage via SQLite
Not all of these techniques work on all browsers, nonetheless,
the evercookie library is able to provide extreme resilience in
the face of a user's effort to purge an evercookie. The arstecnica
article linked above describes subsequent efforts to help users.
The evercookie library has pinpointed the conflicting pressures on
the Web, as on the one hand, browser vendors seek to enable
developers to create ever more powerful applications, and on the
other hand, advertisers and malware authors find ways to exploit
this for their own benefit. The amended EU E-privacy Directive due
to come into force in May 2011 is expected to have an effect on
techniques such as the evercookie that override the user's intent
to opt out of tracking. See Section 2.2.3.2
for more details.
The Privacy Dashboard Browser Extension
This Section will describe the kinds of data collected by the
Dashboard extension, the queries that can be made on it, and
the user preferences available. The implementation details are
given in Section 2.4.
Data Collected
The browser extension measures the following properties
on a per site basis:
- website session cookies
- website lasting cookies
- website Flash cookies
- internal 3rd parties
- external 3rd parties
- internal 3rd party session cookies
- internal 3rd party lasting cookies
- internal 3rd party Flash cookies
- external 3rd party session cookies
- external 3rd party lasting cookies
- external 3rd party Flash cookies
- DOM storage
- Geolocation permission
- HTML5 pings
- Invisible images
A distinction is drawn between internal and external third
parties, based upon whether the third party has the same
base domain as the website. This is the first part of the DNS
domain before the non-assignable public suffix. Thus the following
are from the same domain:
- www.example.com
- images.example.com
whilst the following are not:
- www.example.com
- images-example.com
- www.example.co.uk
Note: support for detecting suspicious URLs is only partly
implemented and therefore excluded from the above list. Whilst
it is possible for the Dashboard to observe HTTP requests and
responses initiated by the browser or web page scripts, this isn't
the case for requests initiated by Flash or Java.
The Dashboard also collects information on what name/value
pairs were submitted in forms, the URL if any the page
was redirected from, and whether the site supports W3C's
Platform for Privacy Preferences (P3P).
Dashboard Database Schema
Firefox integrates the SQLite relational database, which
provides support for SQL queries on memory resident files. A new
database was designed to persistently hold the data collected on
each site visited.
This essentially covers:
- the relationship between a website and its third parties,
whether direct or indirect
- the data submitted as form name/value pairs
- numeric counts for miscellenous properties, such
as the number of lasting cookies set by the site
Where Firefox already records information, it wasn't
necessary to record this separately. This applies to the
list of lasting (but not session) cookies, and to details
on which sites the user has told the browser to remember
a decision on access to the device's gelocation.
Here follows the database schema. This gives the instructions
for creating the database tables and associated indexes, as well
as rules to automatically update the date fields when data records
are updated:
Database Schema
CREATE TABLE IF NOT EXISTS relations (
parent TEXT,
child TEXT,
offsite INTEGER,
time DATE,
PRIMARY KEY (parent, child)
)
CREATE INDEX IF NOT EXISTS relations_parent_index ON relations (parent);
CREATE TRIGGER IF NOT EXISTS insert_relations_time AFTER
INSERT ON relations
BEGIN
UPDATE relations SET time = DATETIME('NOW')
WHERE rowid = new.rowid;
END
CREATE TRIGGER IF NOT EXISTS update_relations_time AFTER
UPDATE ON relations
BEGIN
UPDATE relations SET time = DATETIME('NOW')
WHERE rowid = new.rowid;
END
CREATE TABLE IF NOT EXISTS parties (
page_host TEXT,
third_party TEXT,
offsite INTEGER,
time DATE,
PRIMARY KEY (page_host, third_party)
)
CREATE INDEX IF NOT EXISTS parties_page_host_index ON parties (page_host)
CREATE INDEX IF NOT EXISTS parties_third_party_index ON parties (third_party)
CREATE TRIGGER IF NOT EXISTS insert_parties_time AFTER
INSERT ON parties
BEGIN
UPDATE parties SET time = DATETIME('NOW')
WHERE rowid = new.rowid;
END
CREATE TRIGGER IF NOT EXISTS update_parties_time AFTER
UPDATE ON parties
BEGIN
UPDATE parties SET time = DATETIME('NOW')
WHERE rowid = new.rowid;
END
CREATE TABLE IF NOT EXISTS http_data (
name TEXT,
value TEXT,
host TEXT,
posted INTEGER,
form INTEGER,
time TEXT
)
CREATE INDEX IF NOT EXISTS http_data_host_index ON http_data (host)
CREATE TRIGGER IF NOT EXISTS insert_http_data_time AFTER
INSERT ON http_data
BEGIN
UPDATE http_data SET time = DATETIME('NOW')
WHERE rowid = new.rowid;
END
CREATE TRIGGER IF NOT EXISTS update_http_data_time AFTER
UPDATE ON http_data
BEGIN
UPDATE http_data SET time = DATETIME('NOW')
WHERE rowid = new.rowid;
END
CREATE TABLE IF NOT EXISTS site_info (
host TEXT PRIMARY KEY,
visited INTEGER,
prefs INTEGER,
session_cookies INTEGER,
lasting_cookies INTEGER,
flash_cookies INTEGER,
int_3rd_parties INTEGER,
ext_3rd_parties INTEGER,
int_3rd_party_session_cookies INTEGER,
int_3rd_party_lasting_cookies INTEGER,
int_3rd_party_flash_cookies INTEGER,
ext_3rd_party_session_cookies INTEGER,
ext_3rd_party_lasting_cookies INTEGER,
ext_3rd_party_flash_cookies INTEGER,
dom_storage INTEGER,
html5_pings INTEGER,
invisible_images INTEGER,
suspicious_urls INTEGER,
geo_permission INTEGER,
p3p INTEGER,
time DATE
)
CREATE TRIGGER IF NOT EXISTS insert_site_info_time AFTER
INSERT ON site_info
BEGIN
UPDATE parties SET time = DATETIME('NOW')
WHERE rowid = new.rowid;
END
CREATE TRIGGER IF NOT EXISTS update_site_info_time AFTER
UPDATE OF visited ON site_info
BEGIN
UPDATE site_info SET time = DATETIME('NOW')
WHERE rowid = new.rowid;
END
This schema was chosen to offer reasonable performance on data
track queries, as well as being able to record the time a record
was last updated. This is used to avoid resending previously shared
data for users that have opted into sharing the data they have
collected on the websites they have visited. For more details, see
Section 2.3.7.
Data Queries
What do to with all the data that is collected? A full blown
query language seemed likely to be too difficult to use for most
people. The solution was to define a fixed set of queries along
with a text field for a parameter where needed. The following
queries are supported:
- Which websites use long lasting cookies?
- Which websites use session cookies?
- Which websites use flash cookies?
- Which websites use DOM storage?
- Which websites use invisible images?
- Which websites use HTML5 ping attributes?
- Which websites provide P3P privacy policies?
- Which websites are 3rd parties?
- Which websites use a given 3rd party?
- Which internal 3rd parties are used by a given website?
- Which external 3rd parties are used by a given website?
- What http cookies are used by a given website?
- Which websites have permission to access my location?
- What data has been sent to a given website?
- Which websites a given datum value has been sent to?
- Which websites a given datum name has been sent to?
- Which datum names are used for a given value?
User Preferences
The Dashboard extension records user preferences for each site,
and allows you to set default preferences for previously unvisited
sites. The following preferences are supported:
- Block third party content
- This can be used to block requests for external third party
content such as advertisements, or 3rd party sites being used to
track you.
- Never block
- When third party content is blocked for a given site, this
preference can be selected to unblock a specific third party,
but needs to be set when visiting that third party directly.
- Block third party cookies
- Used to suppress sending cookies to external third
party sites.
- Block lasting cookies
- Used to suppress sending lasting cookies to a web site.
Lasting cookies can be used for a variety of purposes, e.g.,
in conjunction with session cookies for session timeout, for
recording user preferences for interaction with the site on
a lasting basis, or for tracking users across sessions.
- Clear Flash cookies set by this website
- Used to delete Flash cookies from the user's computer.
These are stored in the local file system separately from the
browser. The Dashboard clears Flash cookies when opening a new
browser window, thus ensuring that they are cleared even in the
event that the browser crashed. Flash cookies may be used to
record where you left off when pausing a movie, and more generally
for Flash-based application preferences. Unlike HTTP cookies,
Flash cookies are held indefinitely (there is no expiry property).
- Block Scripting
- Disabling web page scripts on a per site basis is implemented
by cancelling HTTP requests when the http-on-examine-response
handler detects the JavaScript content type, and temporarily
disabling scripting by setting a browser wide preference until
shortly after the page has finished loading. This is needed to
disable scripts embedded directly within HTML content. This
isn't ideal as problems can occur if the user attempts to load
multiple documents at the same time, for instance, in separate
browser windows or tabs. Some browsers, e.g., Opera allow you
to disable scripting on a per site basis through site
preferences. Disabling scripting may cause web pages to "break"
and the site may even instruct you to re-enable scripting in
order to use the site. Note: this preference only applies
to JavaScript executed by the browser as part of a web page.
Separate preferences are available to block Flash (which includes
its own scripting environment) and Java.
- Block Flash
- This blocks the loading of Adobe Flash or Shockwave media
for a given website. This is done by examining the content type
of the HTTP response and cancelling the request as necessary.
- Block Java
- This blocks the loading of Java code for a given website. This
is done by examining the content type of the HTTP response and
cancelling the request as necessary.
- Block Geolocation Requests
- This sets a browser wide property to inhibit sending
geolocation information to websites.
- Block HTML5 Pings
- This sets a browser wide property to inhibit sending
pings to the URLs listed in a link's ping attribute when
the user activates the link.
- Block HTTP Referrer header
- This sets a browser wide property to inhibit setting the HTTP
Referrer header in HTTP requests. The Referrer header tells the
server the URL of the referring document, i.e., the one containing
the hypertext link that the user activated. Blocking this header
may break some sites, which may refuse to serve images or scripts
in an attempt to block inclusion of these resources by web pages
on other sites. The absence of the header may cause some sites to
redirect the browser to the site's main entrance page in an attempt
to block deep linking to web pages within the site.
- Block DOM storage
- This sets a browser wide property to disable the use
of DOM storage.
- Do not track
- This sets experimental do not track headers. More details
are given in Section 2.2.3.1.
Using browser wide preferences on a temporary basis is
prone to causing problems when more than one page is being
loaded at the same time. This is where more fine grained
control would be valuable, but would involve direct changes
to the Firefox browser code base. One possibility would
be a means to disable a given property on a per tab basis.
Do Not Track
This sets a pair of experimental HTTP headers in all HTTP
requests to a site or its third parties:
- X-Behavioral-Ad-Opt-Out: 1
- X-Do-Not-Track: 1
which indicate that servers should avoid sending advertisements
tailored according to the user's behaviour, and separately, that
servers should avoid tracking the user. This is based on
Christopher Soghoian's January 2010 article: "The History of the
Do Not Track Header" [10].
The Do Not Track technique avoids the drawbacks with the use
of opt-out cookies that have to be set on a per site basis, and which
need to be re-installed after clearing out the browser's cookies.
More recently, there has been renewed interest in the idea of
using an HTTP header for opting out of tracking and behavioural
targeting of advertisements. The US Federal Trade Commission (FTC)
issued a report in December 2010 that recommends that companies
should adopt a privacy by design approach by building privacy
protections into their everyday business practices. The report
further recommends that consumers should be presented with a choice
about collection and sharing of their data at the time and in the
context in which they are making decisions – not after having to
read long, complicated disclosures that they often cannot find.
The FTC staff recommends a Do Not Track mechanism governing the
collection of information about consumer’s Internet activity to
deliver targeted advertisements and for other purposes [11].
The FTC is now collecting comments on the report, and early
feedback indicates that whilst all parties seem to agree on the
need for stronger protection of privacy online, inhibiting
behavioural targetting of advertising isn't necessarily in the
user's interest, as it makes the advertisements less effective,
and hurts the business of ad-provided services. Moreover the
Do Not Track header wouldn't cover information provided by
the user, e.g., by entering data in web page forms. Nor would
it cover contextual advertising where ads are selected based
on the content of the page into which they will be inserted.
Mozilla.org is proposing to support the Do Not Track header
as part of its next release of the Firefox browser [12]. Users would
have to enable the header, e.g., through checking a box on the
Firefox privacy pane. See also Mozilla's Mike Hanson's article
"Thoughts on Do-Not-Track" [13].
The format of the do not track headers generated by Firefox [14]
are different from that shown above, and now take the form:
An Internet Draft covering a Do Not Track proposal was submitted
to the IETF on 7 March 2011 [15].
Third party Web page scripts are often used for tracking
purposes, e.g., to make use of Google analytics, a web site embeds
code to download and run Google's "ga.js" script as part of a web
page. It has been suggested that the Do Not Track user preference
should be directly exposed to web page scripts via a boolean
property on the document.navigator object. This would in some
cases be more convenient than modifying the server to handle the
Do Not Track HTTP header. For more information on the Google
Analytics script, see [16].
Other browser vendors are considering how to proceed. Microsoft
has introduced a feature named "Tracking Protection" in new builds
of Internet Explorer (IE) 9. Tracking Protection will be an opt-in
mechanism, and based upon lists of URI patterns, together with
allow and deny rules, that indicate which sites can be loaded as
third parties. Microsoft has worked with a number of partners to
provide Tracking Protection Lists for users to install, e.g.,
Abine, EasyList, PrivacyChoice and TRUSTe, see [17] and [18].
Opt-in and Loyalty Schemes
An alternative approach would be to consider an opt-in approach
where users sign up to loyalty schemes, where certain well defined
benefits are offered in exchange for being tracked across
participating sites. This would build upon existing loyalty
schemes such as the UK's nectar card. When combined with support
for micropayments, we could see sites offering a real choice
between limited free services, ad supported services where you opt
into being tracked, and for pay services where you can make spur
of the moment decisions on spending a few Euro cents without being
put off by having to sign up for so many Euro's a month for a
service you aren't yet sure about. Note that this would be
complementary to P3P like schemes that cover what data is
collected, how long it is retained, what purposes it can be used
for, and with whom it can be shared. See Chapter 4 for more
details.
The 2009 amendment to the European e-Privacy directive
2009/136/EC requires websites to have the explicit consent of
users for being tracked with cookies [19]. This will come into
force in May 2011 and is expected to have an big impact as European
websites are required to switch to an opt-in approach to
tracking. This may well prove the tipping point for the introduction
of opt-in loyalty schemes as described above.
It is likely that the Do Not Track header mechanism in browsers
won't be sufficient to comply with the amended Directive, and this
should stimulate further discussions.
Dashboard User Interface
This Section will present the user interface of the Privacy
Dashboard with screen shots and an account of the design rationale.
A brief description is given of the user studies conducted by
CURE and the resulting changes in the user interface.
Initial Dashboard UI
At the outset, the aim was to provide a way for users to
view information about the current website, to be able to set
per site preferences, and a means to query the data gathered
during visits to websites. An early idea was to place a graphical
button in the browser navigation button as a means to:
- Allow users to show data on the current site by clicking
the button
- Provide a rough indication of the site from a privacy
perspective by changing the graphic
This led to the adoption of a smiley face which could be changed
to a happy "cool" face, a thoughtful face and an indignant face.
This is automatically installed in the navigation bar when the
Dashboard extension is first run. An entry is also added to the
browser's Tools menu as alternative to clicking the face.
The indignant face is selected if a website has lasting
external third party HTTP or Flash cookies. The thoughtful face is
selected if the site has lasting cookies, Flash cookies or
external third party content and lacks a P3P policy. Otherwise,
the happy/cool face is shown. The use of three levels and the
criteria behind them is to some extent arbitrary, but was chosen
as a rough indicator of potential privacy issues with websites.
For a detailed view, users are recommended to read the website's
privacy policy.
Initially the idea was for the dashboard to be a pane on the
side of the browser window, that would slide in from the left when
needed. This idea was dropped as it became clear that significant
horizontal space would be needed to present the results of querying
the data collected on websites. The solution was to instead use
a pop-up window along with tabbed panes.
Notification Bar
When the user loads a new page, the Dashboard is notified
of the request, and observes the HTTP requests and responses
involved in loading the page. When the page load event
is seen, the Privacy Dashboard makes an assessment of the website
and updates the face on the browser navigation toolbar to
match. If this is the first time this site has been visited,
and it is classified with the thoughtful or indignant face, then
a notification bar is displayed as follows:
Notification Bar
The user can then decide that the privacy risk is low and
to always load this page without further warning (Accept always),
to switch to a paranoid mode for this website where the extension
does its best to protect the user's privacy (Protect me), or
to display the Dashboard pop-up window to learn more (Tell me
more). A further choice is to click on the notification bar's
close button. In this case the user will get a fresh warning
for this website in future browser sessions.
About Pane
The About pane gives the version number for the extension,
copyright details, information on PrimeLife and an acknowledgement
of funding from the European Union's 7th Framework Programme
The pane introduces the PrimeLife Privacy Dashboard, along with
the function of the various panes, the face button, and a pointer
to the Dashboard website.
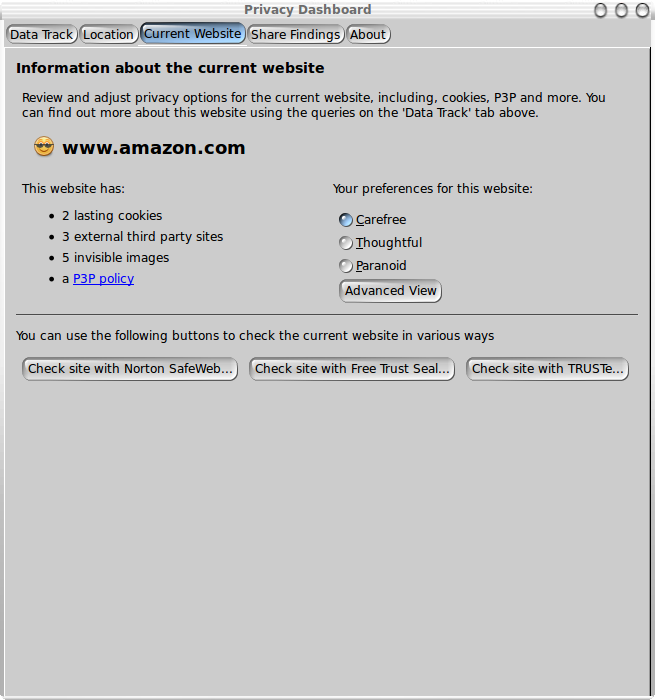
Current Website Pane
The Current Website pane provides an assessment of the current
website, a user interface to set preferences, and buttons for
accessing external services for further assessments of the site.
The Dashboard's assessment of the current site is shown as a
bullet list on the left. This list varies in length according to
the assessment. To reinforce the icon on the navigation toolbar,
the face is shown next to the website's domain name, e.g.,
"www.amazon.com" as shown in Figure 4.
The preferences are shown on the right. The following
screenshot (Figure 4) shows the simple view aimed at novice
users. It offers three levels of increasingly strong privacy
protections, plus a button to switch to the advanced view.
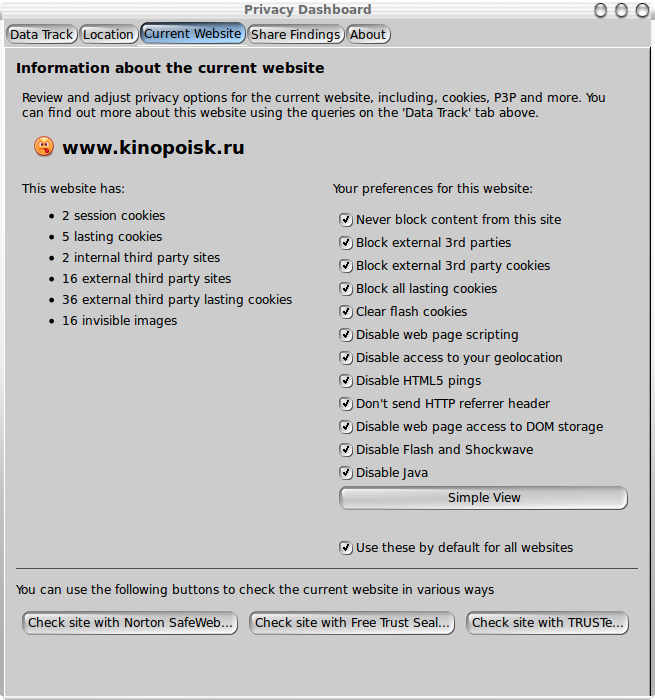
The three levels in the simple view map to settings in the
advanced view:
- Carefree
- Nothing is blocked
- Thoughtful
- This blocks external third party cookies as well as disabling HTML5 pings
- Paranoid
- This blocks external third party cookies, all lasting cookies,
clears Flash cookies, inhibits web page scripts, blocks access to
the device's location, disables HTML5 pings, blocks the sending
of the HTTP Referrer header, disables DOM storage, disables Flash
and Java.
There was some discussion during the PrimeLife General Meeting
about the naming of the levels. Should they be given neutral
names, or are emotive names easier to understand? The user studies
conducted by CURE (see Section 2.3.8) suggest that participants
found the existing names easy to understand, and none of the
participants suggested changing them.
The detailed definition of the levels is to some extent
arbitrary, but users are free to pick the details for themselves
with the advanced view, as is shown below:
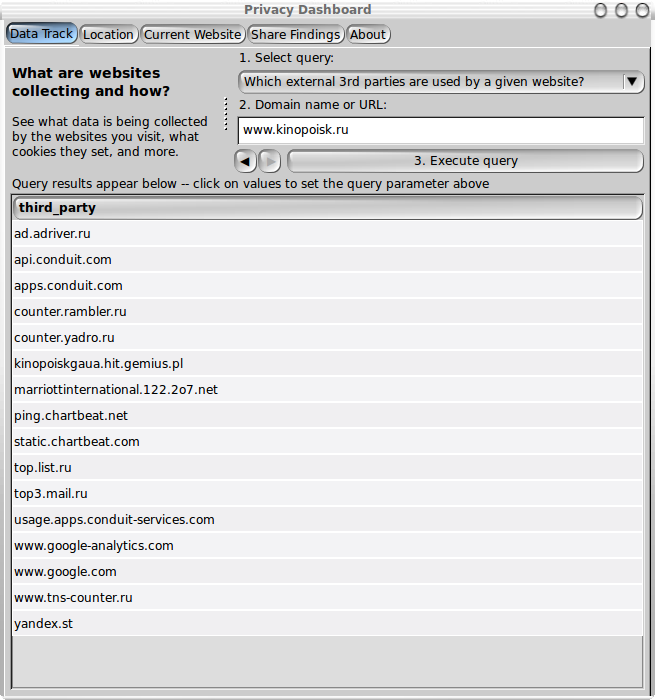
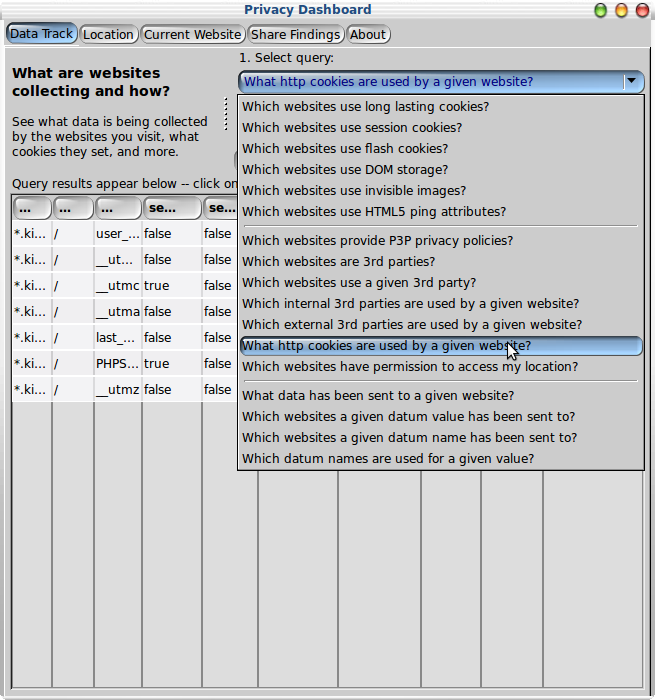
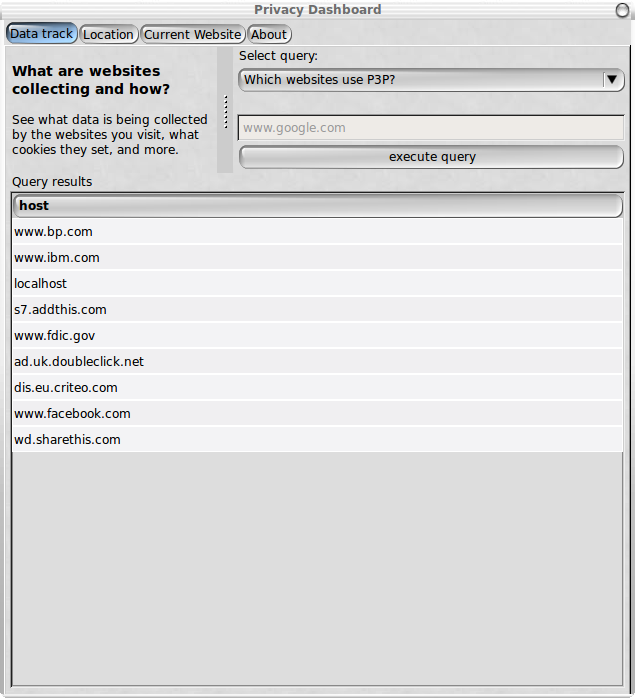
Data Track Pane
The Data Track pane provides users with the means to browse
through the data collected during visits to websites. Users have
to first pick a query from a drop down menu, then enter a query
parameter such as a website domain, and finally click on the
execute query button to display the results in the table below.
The following screenshot (Figure 7) shows how queries are
grouped in the drop down menu. The grouping was added fairly late
on in the development of the Dashboard. The screenshot shows
cookies and illustrate the challenge raised by the number of
fields for each column. The user interface allows users to change
the widths of individual columns by dragging the separators
between the column labels. You can also expand the width of the
Dashboard pop-up window, e.g., on Linux, by double clicking the
window title bar.
The choice of the queries and their grouping presents quite a
challenge to novice users, as there is quite a lot of terms to
learn, e.g., what are cookies and what is the difference between
regular cookies and Flash cookies? This requires introductory
materials on the terms and their relevance to privacy. Some
consideration was given to including a glossary of terms in a
new pane, but it became clear that this would be better handled
by linking to a website devoted to the Dashboard and maintained
with a community process.
Location Pane
Location based services are very topical. Most Web browsers have
recently added support for the W3C geolocation API, see:
Web page scripts can request access to the device's location.
The Firefox browser, then prompts the user for a decision and
whether or not to remember this decision for future requests.
However, to rescind this recorded decision, users have to navigate
the browser back to the website, and there is no support built into
the Firefox for viewing a list of all sites for which you have
recorded a decision. It seemed appropriate to add this capability
to the PrimeLife Privacy Dashboard, and a separate pane was
allocated for this purpose. It shows the list of website domains
together with check boxes that can be unchecked if you want to
rescind the recorded decision.
The device location can be sensed either via accessing a GPS
interface, or by examining the WiFi neighbourhood and using a
third party service to map this to the location. The Firefox
browser at the time of writing only supports this latter method,
and makes use of a Google webservice for determining the location.
Google and its partners have driven vehicles along many roads to
take photos for Google Street View, and to record data on WiFi
access points and tie that to the location from an on board GPS
sensor.
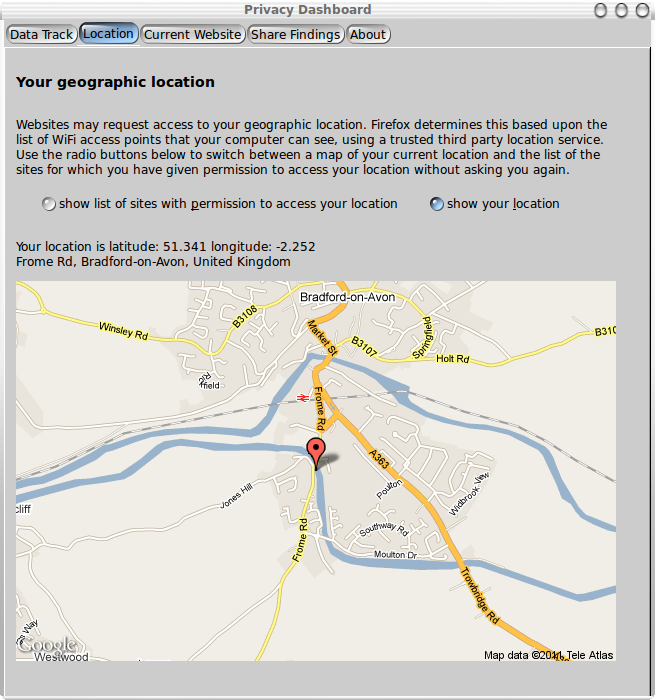
The Dashboard Location pane allows users to optionally check
if Firefox knows their location. If found, a map is displayed
centered on the location, as is shown in the screenshot below:
Note that the default is to show the list of sites with
permission to access the user's location. This default was
chosen to avoid the Dashboard contacting the third party location
service each time it is displayed, as in principle, the location
service could log all such requests, with implications for the
user's privacy. It has been suggested that the Dashboard obtain
the map from OpenStreetMap, but this wouldn't contribute to the
user's privacy as Google is the geolocation provider for Firefox.
Google has been criticised for collecting too much information
in its drive bys. One lesser known instance is the collection of
the MAC addresses of the computer network interfaces. For a while
at least, it was possible to query Google for the last reported
location of any MAC address. This privacy breach has now been
closed.
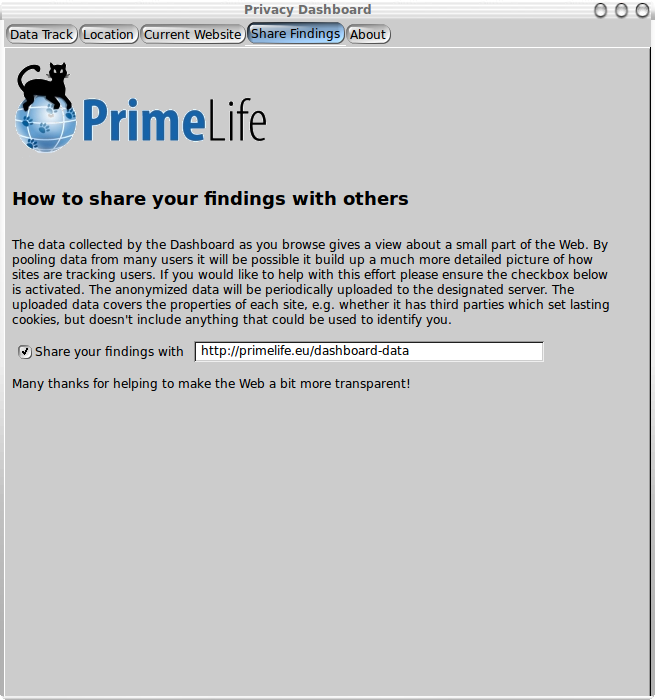
Share Findings Pane
The Privacy Dashboard collects data on the sites you visit,
lighting up a small part of the Web. To get a wider view it will
be necessary to combine data from many users. This is essentially
about how to datamine the very sites that are datamining us! To
support this an opt-in sharing facility was added to the
Dashboard. This allows users to opt into sharing their data with a
server of their choosing. No personal data will be shared. The
data is anonymized before uploading, which takes place at
intervals controlled by a preference setting, currently accessible
through the browser's about:config page. The default is 14 days.
This facility stimulated lengthy discussion during the last
PrimeLife General Meeting. There was a concensus that this should
be an opt-in feature, and when the extension is first installed,
the Dashboard website should be shown to introduce people to what
is involved, the way the data is anonymized and the rationale for
sharing it. A button to visit the site should be added to the
sharing pane.
The main issue in discussion was the nature of the anonymization
and what possible mechanisms could be used to strengthen it. Before
going into that, here is the data schema used for the transfer
expressed as an SQLite schema:
Sharing Schema
CREATE TABLE IF NOT EXISTS relations (
parent TEXT,
child TEXT,
offsite INTEGER,
PRIMARY KEY (parent, child)
)
CREATE TABLE IF NOT EXISTS parties (
page_host TEXT,
third_party TEXT,
offsite INTEGER,
PRIMARY KEY (page_host, third_party)
)
CREATE TABLE IF NOT EXISTS site_info (
host TEXT PRIMARY KEY,
visited INTEGER,
session_cookies INTEGER,
lasting_cookies INTEGER,
flash_cookies INTEGER,
int_3rd_parties INTEGER,
ext_3rd_parties INTEGER,
int_3rd_party_session_cookies INTEGER,
int_3rd_party_lasting_cookies INTEGER,
int_3rd_party_flash_cookies INTEGER,
ext_3rd_party_session_cookies INTEGER,
ext_3rd_party_lasting_cookies INTEGER,
ext_3rd_party_flash_cookies INTEGER,
dom_storage INTEGER,
html5_pings INTEGER,
invisible_images INTEGER,
suspicious_urls INTEGER,
geo_permission INTEGER,
p3p INTEGER,
)
This is essentially a subset of the Dashboard's schema for
the dashboard.sqlite database, without times, preferences or
form data.
The Dashboard serializes each table to records with comma
separated values, and sends each table separately. The process
only sends records that have been added since the last sharing
operation. A checksum (adler32) is added for use as a basic check
on data integrity. A PHP script and MySQL database schema were
developed to test the data transfer and insertion into the server
side database. A basic UI has been developed for using your browser
to query the data held by the server, and it is hoped that this can
be developed further as part of a community process.
Data Sharing and Anonymity
It is envisaged that a community process would be used to maintain
a website dedicated to the Privacy Dashboard and discussions about
privacy and tracking practices. The site's PHP scripts would be
open source and available for anyone to view. The site would have
a privacy policy which clearly states that there is no tracking of
users, including no logging of client IP addresses, nor of the time
of each access. By running this site within the European Union, it
would be subject to European data protection laws, giving further
assurances to users.
Assuming that you are paranoid about your privacy but want to
contribute your data to the community, then you may not find the
above fully satisfying. What steps could you take? One idea is to
configure your browser to access the sharing site via a trusted
anonymising proxy server such as those operated by the Tor Project:
This would mask your IP address. What issues remain and how
could they be addressed? The current Dashboard implementation
batches up all new records since the last sharing operation. This
makes efficient use of the network connection. However, the set of
sites covered in the batched data leaks some information that might
in principle help to pin you down despite not knowing the IP address.
One way to deal with that is to send each record separately. The
Dashboard should also ensure that only the minimal set of HTTP
headers are set in the request, e.g., excluding the user agent,
accept, referrer and cookie headers. A remaining problem is that
some sites may include tracking codes as part of the website's
domain name, e.g., 534662.tracker.com. A paranoid version of
the Dashboard extension should apply a rule of thumb to avoid
sending records with such domain names.
User Studies of the Initial Dashboard UI
The Center for Usability Research and Engineering (CURE), Vienna,
Austria, provided help by assessing the usability of the PrimeLife
Privacy Dashboard, and making suggestions for improving the user
interface. This took place in two phases:
- Guerrilla Testing - first half of 2010
- Formal Laboratory Testing - October 2010
The first phase involved informal assessments of the user
interface by "passers by". This led to a number of valuable
suggestions which are described below. The formal user testing
is documented in D4.1.5 Final HCI Research Report.
[[ *** add proper reference *** ]]
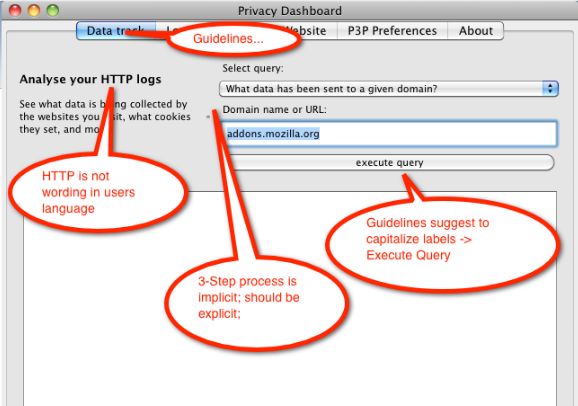
- Capitalization of labels
- Consistent capitalization of the labels for panes
and headings, making them easier to read.
- Using easier to understand terms
- This particularly applied to the early use of the terms
"host" and "domain". These were switched to the uniform use
of "website".
- Tool Tips
- The uniform provision of tool tips that appear when the
mouse pointer lingers over text that is part of the user
interface. This was especially important for the Current
Website pane, where longer tool tips were added to explain
each of the bullet points in the assessment, and each of
the options in the preferences.
- Localization
- The Dashboard was developed by a native English speaker, but
when tested in Vienna, the ability to provide a version localized
to German would have been valuable. Accordingly, the Dashboard
XUL markup and scripts were changed to support the use of
localization files.
- Tailoring to the operating system
- Side by side comparison revealed significant differences
in how UI controls were rendered on the Apple Macintosh and Ubuntu
Linux operating systems. This led to a restructuring of the
Dashboard to support operating system specific styling.
- Clarifying the steps for making queries
- User feedback suggested the need for making the sequence of
steps needed for querying the data more obvious. Initially, this
was done within the tool tips for the labels for the query
selection drop-down list, the text box for the query parameter,
and the execute query button. However, it became clear that it
would be better to number the steps explicitly in the labels.
The old version of the Data Track pane is shown below and
should be constrasted with the final version above.
- Making the data "browsable"
- Having to manually type the text parameter for some queries
proved to be tedious. The first step was to automatically set the
field to the current website domain. The next step was to support
clicks on the query results as a means to set the text field from
the clicked value. The final step was to introduce a query history
mechanism with backward and forward buttons. In Figure 6, these are the two small buttons
with left and right arrows to the left of the execute query
button. The buttons gray out when they are inapplicable, drawing
upon the user's familiarity with the Firefox browser's backward
and forward buttons on the browser's navigation toolbar.
- Use of a graphical texture to enliven the general appearence
- Some users felt that the Dashboard's uniform gray color to be
a bit dull. This led to experiments with graphical textures for
the background.
- Design Grid
- Some of the best user interfaces make use of a regular grid
for visually aligning different components. The lines in the grid
are only used in the design process and invisible to end users.
This is hard to implement for Firefox extensions, especially when
layout involves a mix of HTML and XUL markup, as these involve
different layout policies. Layout proved quite tricky, especially
when it comes to vertically extending the Dashboard pop-up
window.
Figure 12 shows an earlier version of the Data Track pane,
which can be contrasted with the final design as shown in Section 2.3.4.
Implementation Details
The PrimeLife Privacy Dashboard is implemented as a Firefox
extension, and comprises a mix of scripts written in JavaScript,
stylesheets written in CSS, image resources, dialog definitions
written in the XUL markup language, and a few other files.
The main challenge in working on the Dashboard was in
discovering which of the many APIs exposed by Firefox to use, and
finding work arounds for problems. This necessitated an agile
methodology in which technical risks were identified and
prioritized, and then studied in working code. The traditional
water fall model of sequentially working on requirements, design,
implementation and testing, would never have been practical.
Instead it was more a matter of a progressive learning curve in a
loop of studying the Mozilla documentation, implementing some
code, then testing and identifying problems requiring further
study.
Packaging
The Dashboard extension is spread across several nested folders
as depicted below:
Dashboard Files
dashboard
├ chrome
│ ├ content
│ │ ├ overlay.xul
│ │ ├ overlay.js
│ │ ├ observer.js
│ │ ├ misc.js
│ │ ├ p3p.js
│ │ ├ database.js
│ │ ├ dashboard.xul
│ │ ├ dashboard.js
│ │ ├ assess.js
│ │ └ share.js
│ ├ locale
│ │ └ en-US
│ │ ├ dashboard.dtd
│ │ └ dashboard.properties
│ └ skin
│ ├ common
│ │ ├ dashboard.css
│ │ ├ cat-globe.png
│ │ ├ logo.png
│ │ ├ glasses-cool.png
│ │ ├ disappointed.png
│ │ ├ mad-tongue.png
│ │ └ texture.jpg
│ ├ mac
│ │ └ dashboard.css
│ └ win
│ └ dashboard.css
│
├ defaults
│ └ preferences
│ └ dashboard.js
│
├ build.sh
├ chrome.manifest
├ install.rdf
└ readme.txt
The build script (build.sh) generates the "dashboard.xpi" file
which is what you need to install the Dashboard extension into
the Firefox browser. The build script is specific to Linux, but
the XPI file is platform independent. The "skin" folder contains
the images and CSS style sheets. The chrome manifest file determines
which platform specific style sheet is loaded at run time for a
given operating system. It turns out that the same icons and
style sheets can be used for both Windows and Linux. The Apple
Macintosh generally needs differently sized icons and the layout
applied to XUL dialogs is also somewhat different from Windows and
Linux. The observant reader may have noticed that the same face
icons are currently used for all platforms. This is something that
could be changed in future.
The locale files bind named symbols to strings in a given locale.
So far, only one locale has been defined (en-US), but it would be
straightforward to add others to cover the variety of languages
used in Europe and elsewhere. The bindings are split into ones
for XUL dialogs and ones for use from JavaScript. The chrome
content folder contains the XUL dialog definitions and their
associated scripts. The chrome manifest acts as the glue that
Firefox uses to make sense of the various components. It looks
like:
Dashboard Manifest
# scripts and xul markup
content dashboard chrome/content/
# language specific text resources for localization
locale dashboard en-US chrome/locale/en-US/
# register a global skin and OS dependent skins
skin dashboard-common classic/1.0 chrome/skin/common/
skin dashboard classic/1.0 chrome/skin/win/ os=WINCE
skin dashboard classic/1.0 chrome/skin/win/ os=WINNT
skin dashboard classic/1.0 chrome/skin/mac/ os=Darwin
skin dashboard classic/1.0 chrome/skin/win/ os=Linux
skin dashboard classic/1.0 chrome/skin/win/ os=SunOS
skin dashboard classic/1.0 chrome/skin/win/ os=FreeBSD
# Firefox only
overlay chrome://browser/content/browser.xul chrome://dashboard/content/overlay.xul
The "install.rdf" file defines metadata and includes its own
localization, in this case a token stab at French which needs
attention from a native speaker:
Dashboard Metadata
<?xml version="1.0" encoding="UTF-8"?>
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:em="http://www.mozilla.org/2004/em-rdf#">
<Description about="urn:mozilla:install-manifest">
<em:id>dashboard@dave.raggett</em:id>
<em:version>0.9.1</em:version>
<em:localized>
<Description> <!-- example localization via google translate -->
<em:locale>fr-FR</em:locale>
<em:name>Confidentialité Dashboard</em:name>
<em:creator>Dave Raggett</em:creator>
<em:description>Un assistant de la vie privée mis
au point par le consortium PrimeLife</em:description>
</Description>
</em:localized>
<em:name>Privacy Dashboard</em:name>
<em:creator>Dave Raggett</em:creator>
<em:description>A privacy assistant developed by
the PrimeLife consortium</em:description>
<em:iconURL>chrome://dashboard-common/skin/cat-globe.png</em:iconURL>
<em:homepageURL>http://www.primelife.eu/</em:homepageURL>
<em:optionsURL>chrome://dashboard/content/dashboard.xul</em:optionsURL>
<em:targetApplication>
<Description>
<em:id>{ec8030f7-c20a-464f-9b0e-13a3a9e97384}</em:id> <!-- firefox -->
<em:minVersion>3.0.3</em:minVersion>
<em:maxVersion>4.4.*</em:maxVersion>
</Description>
</em:targetApplication>
</Description>
</RDF>
The Internal Design of the Dashboard
A Firefox extension generally starts by binding a script to
each browser window as an overlay. This is done with the
"overlay.xul" file, see above. The top level script is
"overlay.js" which defines a JavaScript (dashboard overlay) object
with a suite of methods. The object is initialized by the window
load event and de-initialized by the window unload event.
The dashboard overlay object in turn initializes the Dashboard
database, and the network observers. A complication is that the
user can open multiple Firefox windows, resulting in multiple
dashboard overlay objects which may be closed in any order. Care
is taken to ensure that the database and network observers are
opened only once, and not once per browser window. This is possible
as Firefox maintains a hidden singleton DOM window on which it is
possible to set and access properties.
The network observers are managed by the observer object, see
"observer.js". The Mozilla Category Manager is used to register
observers for content policy notifications for handling the
ShouldLoad method call. This is called very early on in
the handling of a page load request. Additional observers are
registered for the http-on-modify-request and http-on-examine-response
notifications which are made when an HTTP request is made, and
when an HTTP response has been received. The handlers for these
notifications are used to track the requests for all of the
resources that are loaded as part of a web page, e.g., scripts,
style sheets, images and so forth. The data is collected and
stored in the Dashboard database. The user preferences are
used to determine whether or not to block the loading of
a given resource (including the clearing of HTTP Cookie headers),
and whether it is appropriate to temporarily reset browser
preferences, e.g., for disabling scripting or the use of DOM
storage.
A further task is to assess the current website and determine
what face to show on the browser's navigation toolbar. If this is
the first time the current website has been visited and it isn't
classified as "cool", a notification bar is displayed inviting
the user to accept always, protect me or tell me more. Selecting
the latter displays the Dashboard pop-up window. See Section 2.3.2
for a screenshot of the notification bar.
There were plenty of complications in implementing the
Dashboard, and plenty of perusing of the Mozilla developer
documentation and associated example code. One major challenge was
tying HTTP requests to the browser tab that originated them. A
rough solution was eventually developed, and it would be helpful
if future versions of the observer APIs were to make the
originating tab browser explicit. As a measure of complexity, the
Dashboard implementation involves sixty thousand lines of JavaScript
code.
Suggestions for Further Work
Here is a list of suggestions for further work:
- Devising rules of thumb to detect suspicious URLs as potential
web bugs. This would involve looking for substrings that could be
intended for use as identifiers for tracking purposes.
- Look for evidence of information leakage to third parties
via URLs and URL query parameters.
- Providing localizations for a variety of human languages so
that the Privacy Dashboard is usable by people in many countries.
- Refining the styling, particularly on the Apple Macintosh,
through the use of Mac specific icons and style sheets.
- Developing mechanisms for searching JavaScript, CSS and Flash
SWF files for indications of privacy unfriendly practices, e.g.,
browser history probes and device finger printing. To avoid
slowing down the browser user interface, this could be done using
web workers (scripts that work in the background), or via
delegation to server based agents.
- Extending the Dashboard user interface to make it easier for
users to selectively disable particular third parties.
- Extending the data track query user interface to be
able to query information shared by other users or dashbots.
- Developing a community of people interested in discussing
website practices in tracking users, and in further work on the
Dashboard software.
- Code review and subsequent submission of the Privacy Dashboard
to the Mozilla add-on site.
- Developing a means for people to share site preferences
analogous to Microsoft's Internet Explorer 9 Tracking Protection
Lists
- Further rounds of usability testing and adjustments to the UI.
An open source site is planned to support the dissemination
of the Privacy Dashboard. This will include a wiki for community
led documentation and a mailing list for discussion purposes.
A related (and possibly the same) site for collecting shared
data and enabling it to be queried via the Web. At the time of
writing this report, a PHP script and MySQL schema has been
developed, for storing shared data, but further work is needed
to provide the UI and back-end for querying this data and
presenting it in various ways.
Finally, acknowledgement is due to the graphics designers for the
smiley icons used in the open source Gnome Pidgin instant messenger
project, from which the three face icons used by the Dashboard
were borrowed.
Privacy Dashbot
This Chapter reports on an extension to the PrimeLife Privacy
Dashboard to automatically collect data on the most popular websites.
It grew out of discussions about how users of the Dashboard could
share data via a community website devoted to exposing how websites
collect data, and their interelationships with third party sites.
Such a community site would be immediately a lot more interesting
if it already had data on the most popular sites. The sharing
facility would still be valuable for collecting data on the less
common sites (the long tail) and for tracking the popular sites in
more detail. In particular, the Privacy Dashbot only looked at the
home page for each site, and will have overlooked the privacy
practices used on other pages as users navigate around the site.
The starting point was Google's list of the top thousand
websites world wide [20]. This ranks sites by the number of unique
visitors per month as measured by Google's DoubleClick Ad Planner.
For each site, Google provides the following information:
- The site category
- The number of unique visitors per month (based upon
cookies)
- The number of page views
- Whether the site has advertisements
The list was copied to a local file and used to extract a
JavaScript version for the Dashboard, and a C-language version
for use in subsequent analysis. The Dashboard extension was
modified to allow it to automatically visit each site, with one
site per minute. The study was performed in a fresh Firefox
profile created for the purpose, and using a version of the top
thousand list downloaded in January 2011.
One complication is that the host name given by Google excludes
the customary "www." prefix. This was inserted by the Dashboard
extension, and dropped when the site in question couldn't be
reached with the prefix present.
Analysis of the Results
To analyse the data a C-language program was developed that
could read the SQLite database files copied from the browser
profile folder together with the list meta-data as described
above.
Visualizing the Web of Relationships
The data collected includes the relationships between a website
and its third parties, both direct and indirect. To get a better
feeling for the data, an anlysis was performed to divide the
set of host names for sites and third parties into isolated
clusters based upon the relationships between servers.
- The host field in the site_info table defined in Figure 10 was used to initialize
the set of sites, where each site is represented as a node and
indexed by its host name using a hash table. The nodes are also
formed into a linked list.
- The "relations" table was then used to expand the set of nodes
to include all third parties, and to add arcs for the
relationships. The node objects use a pair of red-black binary
trees to represent the arcs into and out of each node as a map
from host names to objects.
- The linked list of nodes was then iterated through to create
the clusters. Each previously unvisited node is used to create a
fresh cluster with the node as its root. A depth first search was
then performed on the node's arcs (both in and out) to visit all
of the nodes in the cluster.
- A red-black tree was used to sort clusters by the number of
domain names they contained.
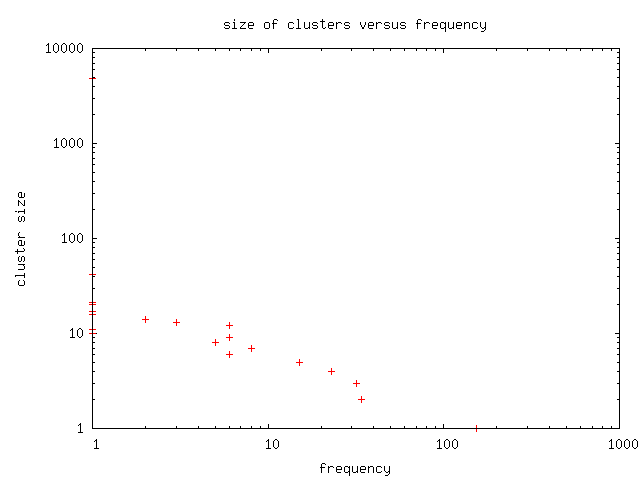
The above processing found 302 clusters in 20 sizes from 5807
nodes. This shows that for each site in Google's top thousand list,
there are on average roughly 5 hidden third party sites. The
distribution of cluster size versus the number of host names
involved is very strongly skewed by a very large cluster of
interlinked sites with 4860 hosts in the largest cluster, and 154
hosts in isolation (cluster size 1). This may reflect a bias in
the procedure Google used to select the top thousand sites.
Here is a log-log graph produced with gnuplot showing the number
of host names in each cluster versus the number of clusters found
with that size:
This is roughly consistent with a power law distribution (i.e.,
a straight line in the log-log scale), except for the largest
cluster. Here is the actual data as a table:
Table of Cluster Size vs Frequency
| Number of clusters |
Hosts per cluster |
| 1 | 4860 |
| 1 | 42 |
| 1 | 21 |
| 1 | 20 |
| 1 | 17 |
| 1 | 16 |
| 2 | 14 |
| 3 | 13 |
| 6 | 12 |
| 1 | 11 |
| 1 | 10 |
| 6 | 9 |
| 5 | 8 |
| 8 | 7 |
| 6 | 6 |
| 15 | 5 |
| 23 | 4 |
| 32 | 3 |
| 34 | 2 |
| 154 | 1 |
A further analysis was performed to rank hosts by the number of
hosts citing them as direct third parties. First, here is a log-log
graph produced with gnuplot, and omitting the point for hosts with
no references:
This provides a better fit to a power law, taking into account
noise for low frequencies. Such a power law is in keeping with the
idea of the Web as a scale free network as first noticed by
Albert-László Barabási et al. in 1999, who coined the term
scale free network to describe networks exhibiting power-law
degree distributions. According to Wikipedia, examples include the
World Wide Web, citation networks, biological networks, airline
networks and some social networks.
- Barabási, Albert-László; Albert, Réka. (October 15, 1999). "Emergence of scaling in random networks". Science 286 (5439): 509–512. doi:10.1126/science.286.5439.509. arXiv:cond-mat/9910332 MR2091634.
Next here is the actual data as a table. In the interest of
conserving space, the entries are truncated for hosts with 3 or
fewer citations as third parties.
Number of citations as third parties
| Number of citations |
Number of Hosts |
Host Names |
| 465 | 1 | www.google-analytics.com |
| 152 | 1 | b.scorecardresearch.com |
| 105 | 1 | pixel.quantserve.com |
| 95 | 1 | edge.quantserve.com |
| 89 | 1 | googleads.g.doubleclick.net |
| 82 | 1 | s0.2mdn.net |
| 79 | 1 | ad.doubleclick.net |
| 78 | 1 | connect.facebook.net |
| 74 | 1 | ajax.googleapis.com |
| 60 | 1 | pagead2.googlesyndication.com |
| 54 | 1 | ad.yieldmanager.com |
| 47 | 2 | pix04.revsci.net
js.revsci.net |
| 40 | 1 | view.atdmt.com |
| 39 | 1 | www.googleadservices.com |
| 35 | 1 | partner.googleadservices.com |
| 31 | 1 | counter.yadro.ru |
| 26 | 2 | pubads.g.doubleclick.net
www.google.com |
| 25 | 1 | ads.revsci.net |
| 24 | 1 | hm.baidu.com |
| 22 | 1 | www.tns-counter.ru |
| 21 | 3 | s7.addthis.com
ad-emea.doubleclick.net
tags.bluekai.com |
| 20 | 2 | bs.serving-sys.com
secure-us.imrworldwide.com |
| 19 | 1 | counter.rambler.ru |
| 18 | 2 | leadback.advertising.com
w.cnzz.com |
| 17 | 1 | ds.serving-sys.com |
| 16 | 1 | ak1.abmr.net |
| 15 | 2 | static.ak.connect.facebook.com
spe.atdmt.com |
| 14 | 4 | a.tribalfusion.com
statse.webtrendslive.com
platform.twitter.com
static.chartbeat.com |
| 13 | 2 | top100-images.rambler.ru
cb.baidu.com |
| 12 | 1 | cm.g.doubleclick.net |
| 11 | 4 | ping.chartbeat.net
a2.twimg.com
tap-cdn.rubiconproject.com
s3.amazonaws.com |
| 10 | 9 | segment-pixel.invitemedia.com
ad.adriver.ru
altfarm.mediaplex.com
a0.twimg.com
o.aolcdn.com
images.scanalert.com
uac.advertising.com
content.yieldmanager.com
ib.adnxs.com |
| 9 | 5 | media.fastclick.net
widgets.twimg.com
a3.twimg.com
cbjs.baidu.com
tap.rubiconproject.com |
| 8 | 11 | akamai.smartadserver.com
www.adobe.com
ad.uk.doubleclick.net
g-ecx.images-amazon.com
ecx.images-amazon.com
ad.br.doubleclick.net
mc.yandex.ru
tcr.tynt.com
p.ic.tynt.com
ac.tynt.com
pixel.rubiconproject.com |
| 7 | 17 | js.adsonar.com
ads1.msn.com
a1.twimg.com
z-ecx.images-amazon.com
o.sa.aol.com
qs1.cnzz.com
secure-uk.imrworldwide.com
img-cdn.mediaplex.com
dnn506yrbagrg.cloudfront.net
js.tongji.linezing.com
dt.tongji.linezing.com
sr-r3.ace.advertising.com
tags.expo9.exponential.com
i.kissmetrics.com
doug1izaerwt3.cloudfront.net
wpa.qq.com
s.clicktale.net |
| 6 | 16 | ad.de.doubleclick.net
ads.bluelithium.com
w88.go.com
bannerfarm.ace.advertising.com
eiv.baidu.com
cg-global.maxymiser.com
content.dl-rms.com
admin.brightcove.com
a248.e.akamai.net
web-jp.ad-v.jp
secure-it.imrworldwide.com
an.tacoda.net
tacoda.at.atwola.com
ads.adjust-net.jp
cou.adjust-net.jp
cstatic.weborama.fr |
| 5 | 34 | qs.ivwbox.de
twitter.com
img.alimama.cn
drmcmm.baidu.com
p.ebaystatic.com
q.ebaystatic.com
www.bkrtx.com
dw.com.com
yandex.st
ad.nttnavi.co.jp
www.statcounter.com
gscounters.gigya.com
cdn.gigya.com
recs.richrelevance.com
pics.ebaystatic.com
maxymiser.hs.llnwd.net
d3.zedo.com
a.analytics.yahoo.com
tu.connect.wunderloop.net
ak.imgfarm.com
data.coremetrics.com
c.brightcove.com
img.ak.impact-ad.jp
content.yieldmanager.edgesuite.net
static.adlantis.jp
ad.adlantis.jp
imagesrv.adition.com
icon.cnzz.com
loadus.exelator.com
core.videoegg.com
amconf.videoegg.com
beacon.videoegg.com
api.twitter.com
aka-cdn-ns.adtech.de |
| 4 | 73 | r.openx.net
www.bing.com
msnportal.112.2o7.net
rover.ebay.com
profile.ak.fbcdn.net
csi.gstatic.com
l.yimg.com
upload.wikimedia.org
ajax.microsoft.com
img01.taobaocdn.com
img04.taobaocdn.com
img02.taobaocdn.com
ai.yimg.jp
rtm.ebaystatic.com
include.ebaystatic.com
offers-service.cbsinteractive.com
i.i.com.com
log.go.com
img.yandex.net
c.statcounter.com
twitter-badges.s3.amazonaws.com
socialize.gigya.com
media.richrelevance.com
cts.channelintelligence.com
ads.adbrite.com
api-read.facebook.com
yads.zedo.com
p.iivt.com
img.mediaplex.com
imgad1.3conline.com
ivy.pconline.com.cn
www1.pconline.com.cn
c7.zedo.com
survey.112.2o7.net
map.media6degrees.com
c.wrating.com
b.st-hatena.com
top3.mail.ru
aimfar.solution.weborama.fr
img.ll.impact-ad.jp
yeas.yahoo.co.jp
yui.yahooapis.com
c.bigmir.net
union.rising.com.cn
maps.google.com
secure.quantserve.com
maps.gstatic.com
switch.atdmt.com
cpro.baidu.com
b3.mookie1.com
t.mookie1.com
optimized-by.rubiconproject.com
trgca.opt.fimserve.com
adserver.adtech.de
l.addthiscdn.com
static.csbew.com
track.send.microad.jp
cre.adjust-net.jp
img.mlstatic.com
dejavu.mlapps.com
www.res-x.com
sales.liveperson.net
b.aol.com
qs5.cnzz.com
gatr.hit.gemius.pl
widgets.digg.com
content.adriver.ru
217.170.78.111
217.170.78.112
ssl.google-analytics.com
garu.hit.gemius.pl
es.optimost.com
ad.targetingmarketplace.com |
| 3 | 117 | trgc.opt.fimserve.com
www.pconline.com.cn
www.mercadolibre.com
udc.msn.com
c.atdmt.com
row.bc.yahoo.com
d.yimg.com
ads1.msads.net
m.webtrends.com
secure-cn.imrworldwide.com
img03.taobaocdn.com
s.gravatar.com
stats.wordpress.com
i.ebayimg.com
track.ra.icast.cn
adlog.com.com
cdn.eyewonder.com
jxmn.nttnavi.co.jp
servedby.advertising.com
g-ec2.images-amazon.com
nht-2.extreme-dm.com
i.cdn.turner.com
qs3.cnzz.com
adadvisor.net
js.3conline.com
img.pconline.com.cn
whois.pconline.com.cn
use.typekit.com
s.xnimg.cn
data.cmcore.com
b.collective-media.net
ec.atdmt.com
s.mcstatic.com
js.users.51.la
www.qiyipic.com
i.dell.com
secure.leadback.advertising.com
click.wrating.com
cf.ad-v.jp
b.hatena.ne.jp
image.www.rakuten.co.jp
image.infoseek.rakuten.co.jp
vsc.send.microad.jp
l3static.weborama.fr
ad-apac.doubleclick.net
as.dc.impact-ad.jp
t.japanmetrix.jp
c.japanmetrix.jp
ad.it.doubleclick.net
. . . . . . |
| 2 | 408 | img.xywy.com
www.facebook.com
www.yandex.ru
vkontakte.ru
secure.wlxrs.com
analytics.live.com
c.msn.com
amer.rel.msn.com
api.bing.com
b5.yahoo.co.jp
adcdn.goo.ne.jp
pre.ra.icast.cn
pv.ra.icast.cn
b6.yahoo.co.jp
pv.cm.sandai.net
s2.56img.com
l1.yimg.com
trace.qq.com
img1.gtimg.com
a.tbcdn.cn
acookie.taobao.com
www.atpanel.com
marketing.taobao.com
t.alimama.com
s.stats.wordpress.com
s1.wp.com
s2.wp.com
g2.ykimg.com
g4.ykimg.com
static.youku.com
lstat.youku.com
i.yimg.jp
thumbs.ebaystatic.com
i3.itc.cn
images.17173.com
i1.itc.cn
i2.itc.cn
js.sohu.com
alpha.brand.sogou.com
kw.ra.icast.cn
pv.sohu.com
post.ra.icast.cn
biz5.sandai.net
api.cnet.com
aglobal.go.com
passport.yandex.ru
yabs.yandex.ru
img-fotki.yandex.net
geo.yahoo.com
top5.mail.ru
static01.linkedin.com
stat.ameba.jp
stat100.ameba.jp
spstatic.ameba.jp
st.deviantart.com
. . . . . . |
| 1 | 3994 | home.xywy.com
www.youtube.com
www.msn.com
www.baidu.com
www.taobao.com
wordpress.com
www.mozilla.com
www.paypal.com
www.rakuten.co.jp
login.facebook.com
www.blogger.com
www.craigslist.org
www.cntv.cn
www.xinhuanet.com
www.infoseek.co.jp
www.cncmax.cn
www.wo.com.cn
. . . . . . |
| 0 | 1077 | www.766.com
start.ubuntu.com
www.bbc.co.uk
uk.yahoo.com
www.yahoo.com
login.live.com
www.live.com
sn129w.snt129.mail.live.com
www.wikipedia.org
uk.msn.com
www.microsoft.com
www.wordpress.com
www.twitter.com
www.soso.com
www.youku.com
uk.ask.com
www.ask.com
. . . . . |
To visualize the relationships the data was exported in the DOT
format for use by the Graphviz utility [21]. The initial attempt
included labels and allowed the nodes to overlap as Graphviz
failed to finish in a reasonable time when asked to prevent
overlaps. Graphviz provides several different layout policies, the
following shows clusters of size 2 and above, and is suggestive of
a privacy black hole at the centre of the Web, analogous to the
super massive black hole at the centre of our galaxy!
After a search for better tools for visualizing larger networks,
Gephi [22] was found to do a reasonable job. Here is the complete
set of hosts without labels.
Gephi allows you to zoom in and see the labels for all hosts
in a given cluster. At this scale you can start to appreciate
the rich interconnections between websites and the hidden
third parties, or what might be thought of as the "dark side
of the Web".
Suggestions for Further Work
A lot remains to be done with the data that was collected. For
each host, there is the per site information, for instance, the
use of HTTP and Flash cookies, support for P3P, and indicators of
web bugs. In principle, this could be shown in a console at the
bottom of an interactive view of the web of sites. It would be
interesting to work on a 3D view where you can navigate through a
galaxy of sites with distant sites shrouded in the mists of
interstellar space. Pointing at a site would highlight the
connections to other sites as curving paths that arc between the
sites. The popularity of a site could be indicated on a log scale
basis by the size of the node. Where favicons are available these
could be attached to each node. The console would form a natural
part of the spaceship bridge looking out into the void.
This isn't as fanciful as it sounds, as modern web browsers are
beginning to support WebGL on a 3D canvas element which
essentially exposes OpenGL to web page scripts. The amount of data
would be a challenge, but this could be allievated using a
clipping plane together with a distance fog, so that nodes fade
out as they get closer to the clipping plane. There are a variety
of layout algorithms that could be adapted for use, e.g., map each
cluster into a hierarchy and layout nodes breadth-first using a
space filling algorithm. Repeat this for all of the clusters in
decreasing size order and use the smaller ones to fill in the
spaces between the larger ones. Once, an initial layout is done,
the next step is to iteratively apply some kind of cost function
that try to keep arcs short whilst keeping nodes apart. This can
be made to scale with techniques developed for n-body simulations
such as collisions between galaxies. The basic idea is to
approximate the aggregate influence of the large number of distant
nodes and combine this with direct calculations for nearby
nodes.
Work by Craig Wills and Balachander Krishnamurthy on privacy
leakage looks at 1200 popular Web sites using a Firefox extension
to download the pages and collect data on cookies, scripts and
identifying URLs for offline analysis, see [23] and [24]. This
work is strikingly similar to the Dashbot and came to my attention
as a result of the February 2011 DagStuhl Workshop: Online
Privacy: Towards Informational Self-Determination on the Internet.
The shared goals and techniques would make it advantageous to pool
ideas for future work on techniques for monitoring practices on
the Web, perhaps as part of a community open source effort as
discussed in the next section.
Open Source Privacy Dashbot
The immediate plan is to make the Dashbot source code and the
data collected available on an open source basis. The aim is to
stimulate the growth of a community of people interested in
creating online tools for interacting with the data, and in building
new agents to collect data on an even larger scale, and on a regular
basis, as a means to track shifts in privacy practices over time.
A further suggestion would be to emulate the Seti@home project,
where clouds of Dashbots download their mission plans from a
central server.
Fresh Take on P3P
Introduction
The W3C Platform for Privacy Preferences (P3P) 1.0 was published
as a W3C Recommendation in July 2002 [25]. It defines a machine
interpretable format for websites to express their privacy
practices. A revised format (P3P 1.1) was published as a W3C
Note in November 2006, but failed to reach Recommendation status [26].
In summary, P3P describes the business name and address
responsible for the website, the dispute resolution procedures,
the means (if any) for users to access personal data collected by
the website, the kinds of data collected, the purposes it will be
used for, the data retention policy, and the recipients of the
data.
P3P supports a notice and consent model of privacy, where websites
describe their privacy policies and users can review the policy
and decide whether to walk away or to proceed to interact with the
site, and by so doing indicate their consent to that policy.
Rather than expecting users to review the privacy policy for each
website that they visit, a P3P enabled web browser performs an
automatic comparison of the user's recorded preferences with the
website's policy, and only alerts the user if there is a mismatch.
P3P provides plenty of flexibility in the representation of
privacy policies. This flexibility poses huge challenges for
expressing user preferences in a practical way for the purposes of
automatic comparison of preferences with policies. This problem
was recognized early on in the development of P3P, and partially
addressed through the introduction of compact policies. These were
intended to enable an efficient comparison process, but only cover
policy information related to cookies. The full P3P policy remains
the authoritative statement of policy.
Browser support for P3P has been largely limited to Microsoft's
Internet Explorer (IE), which has included support for P3P compact
policies since IE6. Microsoft's dominant market share has encouraged
websites to implement P3P despite the lack of support from other
browser vendors.
P3P-based Browser Extension
With increasing public awareness of the amount of information
being collected by websites, it seems timely to consider new
approaches covering more than just cookies, whilst enabling a
practical treatment of the user interface for expressing privacy
preferences.
To investigate this, a Firefox extension was developed to look
at the issues involved. This had to support:
- auto-generation of a human readable version of the policy
- automatic comparison of the user preferences with the policy
- automatic generation of a human readable report on any mismatches
- user interface for viewing and changing user preferences
The scope was taken as the data that websites can collect from
HTTP request headers during a session. This includes the IP
address, cookies, the user agent header, information on user
preferences for language and data formats, the requested URL, the
date and time of day, and more.
To simplify the user interface for preferences, a subset of P3P
was chosen. This has the following object model:
- The URI for the site's full (human readable) policy
- The URI for instructions that users can follow to request or
decline to have their data used for a particular purpose
(optional)
- The name of the business responsible for the website
- The set of categories of collected data as defined by P3P 1.1
- The set of purposes collected data can be used for as defined by P3P 1.1
- The set of recipient types as defined by P3P 1.1
- The data retention policy type as defined by P3P 1.1
Note this uses P3P's data categories rather than the taxonomy of
data items. This was found to be a much better fit to the needs for
describing the kinds of data collected from HTTP requests.
The simple object model allows the preferences user interface
to be provided as a set of grouped checkboxes, as shown below:
Preferences Dialog
Accessing the policy
To reach a website, the user can type in a URL, follow a bookmark,
or follow a link from another site, e.g., on the results page from
query on a search engine like Google. The browser extension intercepts
the Firefox location change event and cancels the HTTP request before
it is sent. The extension then sends an HTTP HEAD request to the
website's root. The response is examined to find a refererence to
the site's generic privacy policy. This is represented as an HTTP
Link header (analogous to the HTML link element), e.g.,
Link: <http://localhost/w3c/policy.json>;
rel="http://primelife.eu/generic-privacy-policy"
This header is easy to add to pages generated via PHP. The URI
for the policy is then dereferenced to obtain the policy itself.
Note P3P 1.0 defined a P3P HTTP header rather than using the
generic Link header. This is something that could be considered
if and when this work is brought into the standards track.
The object model for policies is decoupled from the on-the-wire
transfer format, but from a practical point of view it was easiest
to implement the transfer format with JSON [27]. Here is an
example policy in JSON:
{
"fullURI": null,
"optURI": null,
"name": "ACME widgets online inc.",
"purposes": ["current", "admin", "tailoring", "individual-analysis" ],
"recipients": [ "ours", "delivery", "same" ],
"retention": "business-practices",
"categories": [ "computer", "navigation", "interactive" ]
}
Generating a human readable version
The P3P 1.1 specification includes suggested text for each
element in the taxonomy. This was copied into JavaScript and used
to generate a human readable version of the policy. Here is an
example:
Site Policy
The same text was also used for constructing a dialog
summarising the mismatch between the user's preferences and
the website's policy, for example:
Mismatch Dialog
If the site's policy matched the user's preferences, or the
user decided to override the mismatch, the browser extension
then proceeds to relaunch the HTTP request for the original
URL.
The Firefox notification bar is shown when a site is found to
lack a privacy policy.
No Policy Notification
You can cancel loading the page, or continue to load the page.
You then have a choice of whether to show the warning on future
visits (Load this time) or not (Always load).
The Firefox notification bar is shown when a mismatch
is found.
Mismatch Notification
Clicking "View details" brings up the warning dialog shown
earlier. You can alternatively click the close icon to dismiss
the notification.
A local SQLite database was used to capture the user's
preferences, and to cache the policy for sites as a performance
optimization.
Anonymising Proxies
The act of making an HTTP HEAD request on a website's root
discloses the browser's external IP address. This can be avoided
by routing the request through an HTTP proxy. This could be
configured via a user preference, but is not implement as part
of the current demonstrator.
This section looks at related work, first describing
suggestions for describing privacy policies with a small set of
icons, then an earlier approach to integrating P3P with web
browsers, and finally, work on combining access control and data
handling obligations into a single policy language.
Privacy Policy Icons
Aza Raskin (Mozilla) proposes a family of icons for describing
privacy policies in the same spirit as icons used for giving
washing instructions for clothes [28]. The idea is that each policy
could be described in its essentials by a handful of icons, making
it easy for users to decide whether or not to proceed to interact
with that web site. Such an approach could form a layered approach
where users can peel back the layers for progressively more details.
The icons could be followed by the bullet list of practices covered
by the P3P vocabulary, and in turn by the full human readable
policy.
The AT&T Privacy Bird
The AT&T Privacy Bird is an extension to Microsoft's
Internet Explorer web browser that can compare P3P policies
against the user's privacy preferences and assist the user in
deciding whether to exchange data with a website, see [29] and
[30]. It focuses on a subset of the P3P vocabulary in order to
present users with a set of configuration options designed to
address most of their needs without overwhelming them. Its name
comes from the bird icon presented on the browser's navigation
toolbar. This changes in appearance according to the degree of
mismatch between a website and the user's preferences, and makes a
tweeting sound to draw the user's attention.
The current work differs from the Privacy Bird in a number of
respects:
- The current work targets Firefox rather than Internet Explorer.
- It supports all of the P3P 1.1 vocabulary with the exception
of the taxonomy of data items.
- It shares with the Privacy Bird the need to constrain the
flexibility of privacy policies in order to support a practical
user interface for setting preferences, presenting mismatches,
and for generating a human readable representation of policies.
- The use of JSON instead of the XML representation defined in
the P3P specifications. This simplifies the implementation and
would also make it easier to combine with JSON based authentication
policies as proposed by Mozilla for the Firefox Account Manager.
Another consideration is the ability to set privacy preferences
on a per site basis rather than as global preferences that apply
to all sites. The Privacy Dashboard described in Chapter 2 supports
the per site approach, and allow users to make the minds up as they
encounter sites, and to change their minds later as appropriate.
This reflects the varying levels of trust users have for different
websites. The Privacy Dashboard further offers users fine grained
control, e.g., over cookies, compared with the take it or leave it
approach provided by the Privacy Bird. Further work is needed to
combine the ideas presented in Chapter 2 with those in this Chapter.
The PPL Policy Language
P3P and the approach described in this Chapter are couched in
legal terms relevant to the obligations extended by websites to
their users. Websites also have the challenge of operationalizing
privacy policies when it comes to controlling access and use of
personal data in the website's backend. This suggests the need for
transforming privacy policies into data handling policies. One
possible solution for this is the PrimeLife PPL Policy Language which
combines the XACML access control language with extensions for
expressing data handling obligations [31]. Policies expressed in
PPL are acted upon by the website in order to determine what kinds
of credentials are needed to grant access to a named resource.
A sanitized version of the policy is made available to the user
agent (the browser) for comparison with the user's preferences.
This is similar to P3P but uses a vocabulary that is oriented to
server-side use to fulful the obligations made to end users in
respect to the personal data they disclose to the site.
Suggestions for further work
This Chapter has described a fresh take on P3P that goes beyond
the limitations of compact policies, whilst still enabling a
simple user interface for setting preferences. The object model
lends itself to the use of JSON as a policy transfer format.
The restricted semantics for a machine readable policy covering
data collected in HTTP requests, is supplemented by a link to
the site's full human readable policy. This is needed for the
cases where the site's policy cannot be fully expressed with
the semantics of the machine interpretable policy representation.
Furthermore, the human readable version may be necessary for use
in legal distributes.
A further consideration is the privacy policy for other kinds
of personal information collected by websites, for example,
credentials coupled to a user's public or partial identity. Can
the P3P taxonomies be extended to support these?
Widespread support for machine readable privacy policies is
likely to involve a legislative mandate with measures in place to
ensure that sites conform to the policies they disclose. However,
this would only apply to the countries with the corresponding
laws. A way is needed to allow the browser to verify the
jurisdiction a given website is subject to. This could take the
form of digital certificates issued by national agencies.
A separate issue is that many people aren't sufficiently
motivated to set privacy preferences. One reason is the desire to
just get to the website in question without having to bother with
reviewing the policy. Another is a lack of knowledge sufficient
for an informed decision. This points the way to the use of
independent third parties for help with setting privacy
preferences, and for monitoring and analysing the data handling
practices of websites. The Dashboard extension described in
Chapter 2 provides a further means for interested users to
manage their privacy on per site basis.
Finally, the vocabulary of terms defined by P3P for machine
interpretable privacy policies should become a living thing that
is extended as consensus is reached over the meaning of new
terms. The browser extension could automatically update itself
to support such additions, either in advance, or upon demand when
a previously unknown term is encountered. This would address
what some have called the supermarket effect, where an ever
increasing range of privacy policy terms are offered by websites.
A concensus process for new terms would help to avoid a weakening
of the value of being able to set user preferences that could
otherwise occur in an unconstrained expansion of terms.
Anonymous Credentials
This Chapter presents work on a third browser extension that
focuses on applying zero knowledge proofs as a privacy friendly
approach to authenticating users to web applications. The work was
done as a collaboration between Dave Raggett (W3C/ERCIM) and
Patrik Bichsel (IBM Research - Zurich).
Zero Knowledge Proofs
Zero knowledge proofs are a form of mathematical proof that the
recipient can use to verify claims by the originator, without
gaining further details. As an example, the recipient could verify
that the originator has a currently valid credential issued by a
trusted entity attesting that a user has a date of birth in some
given range, or that the user is a member of a given group,
without learning the user's name or birthdate.
Credentials will have a defined period of validity. Revocation
of credentials during this period will be needed when the issuer
withdraws the rights for an owner to use a credential, or when an
attacker is able to gain access to the credential after the
integrity of the system used to protect it has been compromised.
Revocation of anonymity is needed in case of abuse, e.g., under a
court order as part of court proceedings.
The identity mixer library provides support for zero knowledge
proofs based upon discrete logarithms and large integer
arithmetic, see [32] and [33]. Solving discrete logarithms is
believed to be NP-complete and as such is computationally
infeasible for suitably large numbers. NP-complete problems are
essentially those for which the difficulty of finding a solution
increases extremely quickly as the size of the problem grows, but
once you have a solution, it can be verified quickly. It has been
shown than all NP problems have a zero-knowledge proof associated
with them. The details are beyond the scope of this report.
Implementation Details
The starting point is a Java based utility used to issue a
credential for a given person. This is manually copied to that
person's computer and protected with a personal identification
number known only to that person. The credential is used to
authenticate the person to a website via a zero knowledge proof
over designated properties of the issued credential.
The web server can be configured to redirect unauthenticated
requests for the website to the log-in page. This can be done by
checking for a secure session cookie that was set when first
logged in. The use of transport layer security (TLS) for the site
prevents attackers from cloning the cookie to gain access.
The log-in page includes a button with a pair of attributes that
the browser extension looks for:
Markup for Log-in Button
<button primelife-idmx-policy="proofspec.xml"
primelife-idmx-nonce="471A8FC390233"
id="connect">Connect!</button>
The two attributes are as as follows:
- primelife-idmx-policy
- This provides a URL for the proof specification by which
the website indicates what kind of proof is required.
- primelife-idmx-nonce
- This is a dynamically generated hexadecimal sequence
for use as a nonce in the proof.
Here is a sample proof specification that requests a zero
knowledge proof that the user has a first and last name, together
with a date of birth, which must lie within a given interval:
Example of a Proof Specification
<?xml version="1.0" encoding="UTF-8"?>
<ProofSpecification xmlns="http://www.zurich.ibm.com/security/idemix"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xsi:schemaLocation="http://www.zurich.ibm.com/security/idemix ProofSpecification.xsd">
<Declaration>
<AttributeId name="id1" proofMode="unrevealed" type="string" />
<AttributeId name="id2" proofMode="unrevealed" type="string" />
<AttributeId name="id3" proofMode="unrevealed" type="int" />
</Declaration>
<Specification>
<Credentials>
<Credential name="dsk239fsk23er90"
credStruct="http://example.com/CredentialStructure_UtopiaHiddenValues.xml">
<Attribute name="firstName">id1</Attribute>
<Attribute name="lastName">id2</Attribute>
<Attribute name="dateOfBirth">id3</Attribute>
</Credential>
</Credentials>
<EnumAttributes />
<Inequalities>
<Inequality publicKey="http://example.com/ipk.xml" operator="geq"
secondArgument="71908">id3</Inequality>
<Inequality publicKey="http://example.com/ipk.xml" operator="leq"
secondArgument="77021">id3</Inequality>
</Inequalities>
<Commitments />
<Representations />
<Pseudonyms />
<VerifiableEncryptions />
<Messages />
</Specification>
</ProofSpecification>
The browser extension listens for the page load event and then
searches for the button element described above, and sets an event
handler for click events on the button. This avoids the need for
the log-in page itself to have a web page script.
When the user clicks the connect button, the browser extension
sees the click event and downloads the proof specification from
the website. The extension then displays the user authentication
dialog to invite the user to enter her personal identification
number (PIN).
The user types the PIN and presses Enter. The browser extension
then invokes the identity mixer library to generate a proof using
the proof specification and nonce. This is then sent to the website
via a hidden form on the log-in page that is dynamically added by
the browser extension.
The website's HTTP server passes the data to a backend server
for verification. For the demonstrator, we used Apache2 as the
website server and Tomcat6 for the backend server. The verification
step makes use of a Java servlet that in turn calls the identity
mixer library. If the proof is consistent with the proof specification,
the web server sets a secure cookie and returns the entrance
page for the members-only part of the website.
One complication is the communication between the browser
extension implemented in JavaScript and the identity mixer
library implemented in Java. The first step is to determine
where the library is stored on the user's computer. The second
step creates class loaders for the identity mixer (idemix) library
and a separate helper library which is used to request permission
from Java for the idemix library to access the user's credential.
The Firefox browser supports a bridge between JavaScript and
Java called "LiveConnect". This handles translation of argument
types when calling Java from JavaScript, and back again for return
values. The translation process is brittle, and we therefore chose
to pass the proof specification as a string rather than as a tree
of (DOM) objects. A further challenge was that LiveConnect failed
to work altogether with the default installation of the Java run
time on the Ubuntu Linux distribution. We found that we had
de-install the default Java run time and replace it with the
Oracle version as developed by Sun Microsystems.
Demonstrator
To demonstrate the potential, a test site was developed for the
scenario where a college student is given an electronic credential,
in addition to a conventional photo id card, attesting that he or
she is a member of the student union. The electronic credential is
contained on an inexpensive USB stick, and can be used to
authenticate the student to college services. The demonstrator
supposes that the student union operates a social website as a
private meeting place for students that is off limits to college
staff, would be employers and even former students. Students can
safely chat and post comments etc. in anonymity.
In a conventional website the user would be expected to log in
with a user id (typically an email address) and a password. This
would uniquely identify the student. To enable anonymity the
student union site makes use of anymous credentials, where the
user is asked to prove she is a current member of the union
without disclosing her identity.
The following screen shot shows the opening page for the
demonstrator:
After clicking the connect button, users are invited to
authenticate themselves to the browser by entering a four digit
personal identification number (PIN):
The browser extension then generates a zero knowledge proof
and passes it to the website for verification. If that succeeds,
the browser is directed to the entrance to the members-only part
of the site:
Credential Selection
The demonstrator involves a specific credential, but in other
scenarios, it is conceivable that the website will accept proofs
for a variety of credentials, and will need to indicate this. This
is analogous to the common practice of informing the user which
credit cards are accepted for an online payment. The user is then
expected to make a choice based upon the knowledge of which she
has in her possession. The website will learn which credential is
used, but not which set of credentials the user posesses.
A simple approach is for the proof specification to name a
specific credential, and for the website to provide multiple
proof specifications, with one per credential. The browser
can inspect the web page and assist the user in selecting between
credentials when she has more than one applicable credential for
the case in question.
What is being disclosed?
The above PIN dialog indicates which credential will be used
for authentication to the website, but it doesn't indicate what
information will be disclosed. Relying on the website to state
what information is disclosed is risky, and relies on the trust
the user places in the website. Further work is therefore needed
to create a human readable summary from the proof specification.
This implies that proof specifications should be limited in their
expressivity as otherwise it will be hard to automatically
generate an effective human comprehensible explanation.
Stronger Authentication
Anonymous credentials rely on authenticating the user to
ensure that the correct user is present. The use of a PIN for
authenticating a user to unlock her credentials is convenient as
it is relatively easy to remember a 4 digit number, especially if
you have to type it in on a regular basis. However, it is also
fairly weak. On the plus side it can only be used with the physical
presence of the USB stick with the credential, but on the minus
side, users will feel tempted to share it with a friend, when the
friend wants to log in and has forgotten his memory stick or
PIN.
A stronger solution for authentication to credentials would be
some form of biometric approach, for example, a finger print scanner,
voice authentication, face authentication, iris scanner, etc. The
approach adopted has to be convenient and reliable. Whilst some
note book computers include a finger print scanner, this is far
from ubiquitous. Some biometric techniques require special hardware,
e.g., an iris scanner. This rules them out for every day use.
A further problem is reliability, and users will quickly become
discouraged when the system fails to recognize them, something
that is familiar to users of integrated finger print scanners.
These are generally based upon capacitive sensors, where the user
swipes a finger across the sensor. The matching algorithm compares
the swipe data with previously registered data, but problems may
occur according to the condition of the finger (injured, worn,
clean or dirty, wet or dry) and from variations in the
orientiation and speed of the finger as it is swiped.
In general, biometric techniques can't be treated as 100%
reliable. It therefore makes sense to provide a fallback, and
one such approach is a long but memorable pass phrase that the
user can type in. Returning to the demonstrator scenario, most
students can be assumed to have a note book computer, and these
will typically include a built in microphone and camera. This
suggests the use of voice or face authentication.
Voice authentication typically involves asking the user to
say a short phrase or PIN, and extracting characteristics for
comparison with previous data. To prevent replay attacks with a
recording of the user's voice, the user may be asked to speak a
dynamically generated digit sequence. Voice authentication won't
work well in noisy conditions, or when the user has an infection
that makes speaking difficult, or when the context precludes
speaking (e.g., in a library or a quiet carriage on a train).
Face authentication is less intrusive, but may be sensitive to
variations in lighting. Authentication based upon taking a photo
may be defeated by someone presenting a photo to the camera, e.g.,
a printed photo, or perhaps even a photo displayed on another
computer. One way around this is to ask the user to speak a
dynamically generated digit sequence and to record both voice and
video. This enables a combination of voice and face authentication,
and at the same time preventing simple replay attacks. The user
can be asked to type her long pass phrase if neither voice nor
face authentication algorithms provide a sufficiently confident
result. Note that the above is about authenticating the user to
the credential system. None of the biometric details are passed
to the website.
Next Steps
The above discussion has focused on authenticating that the
correct user is present before generating an anonymous credential.
A separate, but important issue, is how to authenticate the
website to the user. This remains a significant challenge as
today's solutions based upon public key certificates have serious
usability problems in practice.
Today's practices for authentication on the Web are inadequate
in a number of regards:
- It is hard for most people to remember different ids and
passwords for different sites. As a result, it is common for
people to use the same id/password across many sites.
- Users tend to pick easy to remember passwords, that are
relatively easy to crack with dictionary attacks.
- The common practice of using email addresses as identifiers
facilitates linking personal data across websites.
- Asking users to enter their id/password into web page forms
facilitates phishing, where an attacker invites users to enter
their credentials into a site that the user mistakes for the
bona fide website.
- The lack of usability for public key certificates, means that
users will often overlook problems with certificates, for example,
it is common to come across expired certificates, where sites have
failed to renew them in a timely way. Phishing sites are able to
obtain certificates with relative ease, and few users will check
the certificate when the site appears sound (i.e., the browser
displays the padlock icon for a secured page). This means that
users don't have a reliable and usable means to verify the sites
authenticity
- The practice of sending user id/password in the clear, as
has been highlighted by the firesheep extension, which eavesdrops
on unencrypted WiFi traffic to collect user ids/passwords.
It is therefore timely to consider new approaches for
authentication on the Web, including the role of anonymous
credentials as a way to ensure greater privacy.
The current demonstrator relies on the LiveConnect interface
between JavaScript and Java which introduces a risk of problems,
e.g., a dependency on the version of the Java run time installed
on the user's computer. To work around this, we would like to
port the identity mixer library to C or C++ and consider how to
integrate it with the existing browser code base, as well as for
that of web servers for proof verification.
When credentials are held on smart cards, USB sticks or other
devices, including mobile phones, how does the browser discover
them? A further challenge is to look at whether anonymous
credentials should be integrated into the transport protocol
(HTTP) or should remain at the layer above. Additional work is
needed to pursue this further.
Government issued credentials such as the new German ID card
could in principle be used together with zero knowledge proofs for
privacy friendly authentication, where websites have the solid
assurance of the strength of the credential, and only the minimal
amount of personal data is transferred to the website, for example,
that the user is of age, or lives in a given city or is of a
particular gender.
Strong credentials could also be used to underwrite pseudonymous
identities, where the user generates a new such identity for each
site. Websites would then be able to verify that the person with
a given pseudonymous identity has the stated properties, but without
learning any more about who that user is. A break-the-glass
mechanism would allow the true identity to be revealed under a
court order in the eventuality of civil or criminal proceedings.
It is time to widely deploy zero knowledge proofs for strong
authentication on the Web!
Conclusions
This report has presented work on three web browser extensions:
-
The first focuses on instrumenting web site practices for
collecting personal data, and giving users the means to set per
site preferences. This has been extended to support automatic
assessment of popular websites, and to provide a means for users
to opt into sharing the information they collect on websites as
they browse the Web. This shines a light on the hitherto dark side
of the Web, revealing the network of hidden third parties used for
content distribution, advertising and analytics.
-
The second recognizes practical limitations with W3C's Platform
for Privacy Preferences (P3P), and presents a constrained version
that makes it straightforward for users to set their privacy
preferences, and to see where a website's policy differs from
their preferences. Such an approach could be made extensible to
cope with newly added policy terms, where a consensus agreement
has been reached on the meaning of these terms. If adopted, this
would allow search engines to rank results to match the user's
privacy preferences, and would complement current proposals on
do-not-track mechanisms by offering users and websites finer
grained options. Recent proposals for a icons for broad categories
of privacy policies offer the potential for a layered approach,
starting with the icons, then bullet list summaries based on
machine interpretable policies, and finally the full human
language policies.
-
The third provides an implementation of anonymous credentials
for authenticating users to websites. This makes use of a bridge
between JavaScript and Java to access IBM's identity mixer library.
A demonstrator is presented for the scenario of students wishing
to access a student only social website operated by the student
union. Anonymous credentials have an important role to play for
web authentication given the serious problems with existing
practice on the Web today. Government issued credentials could
be used as the basis for strong authentication of pseduonymous
identities and minimal disclosure of personal data.
To encourage further work by others, the source code for the
browser extensions and associated software, together with the data
collected by the Dashbot will be made available as part of an open
source site.
References
Adoption of P3P, Leon, Cranor, McDonald and McGuire, September 2010
http://www.cylab.cmu.edu/files/pdfs/tech_reports/CMUCyLab10014.pdf
New York Times on cookies, http://bits.blogs.nytimes.com/2010/09/17/a-loophole-big-enough-for-a-cookie-to-fit-through/
NAI opt-out site, http://www.networkadvertising.org/managing/opt_out.asp
Flash penetration, http://www.adobe.com/products/player_census/flashplayer/
version_penetration.html
Site for clearing Flash cookies, http://www.macromedia.com/support/documentation/en/flashplayer/help/settings_manager07.html
"How Unique Is Your Browser?", Proceedings of the Privacy Enhancing Technologies Symposium
(PETS 2010), Springer Lecture Notes in Computer Science,
http://panopticlick.eff.org/
Samy Kamkar's evercookie, http://samy.pl/evercookie/
New Web Code Draws Concern Over Privacy Risks, Tanzina Vega,
The New York Times, 10 October 2010.http://www.nytimes.com/2010/10/11/business/media/11privacy.html?_r=1&hp
It is possible to kill the evercookie, John Turner, arstechnica,
November 2010, http://arstechnica.com/security/news/2010/10/it-is-possible-to-kill-the-evercookie.ars
History of the Do Not Track Header, Christopher Soghoian, January 2010,
http://paranoia.dubfire.net/2011/01/history-of-do-not-track-header.html
Privacy by Design, US Federal Trade Commission (FTC), December 2010,
http://www.ftc.gov/os/2010/12/101201privacyreport.pdf
Firefox4's do-not-track-header, https://wiki.mozilla.org/Privacy/Jan2011_DoNotTrack_FAQ
Thoughts on Do-Not-Track, Mike Hanson, http://www.open-mike.org/entry/thoughts-on-do-not-track
Firefox do-not-track-header format, http://blog.sidstamm.com/2011/01/try-out-do-not-track-http-header.html
IETF do-not-track draft, 7 March 2011, http://tools.ietf.org/html/draft-mayer-do-not-track-00
Google Analytics script, http://code.google.com/apis/analytics/docs/tracking/gaTrackingOverview.html
Providing Windows Customers with More Choice and Control of Their Privacy Online with Internet Explorer 9, http://www.microsoft.com/Presspass/Features/2010/dec10/12-07IE9PrivacyQA.mspx
Tracking Protection Lists, http://ie.microsoft.com/testdrive/Browser/TrackingProtectionLists/Default.html
2009 amendment to the European e-Privacy directive, http://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=OJ:L:2009:337:0011:0036:En:PDF
Google's list of the top thousand websites, http://www.google.com/adplanner/static/top1000/
Graphviz graph visualization software, http://www.graphviz.org/
Gephi, an open source graph visualization and manipulation software, http://gephi.org/
Shining light on privacy leakage, Craig Wills. Dagstuhl Perspectives Workshop on Online Privacy: Towards Informational Self-Determination on the Internet, Dagstuhl, Germany, February 2011. http://www.dagstuhl.de/mat/Files/11/11061/11061.WillsCraig.Slides.pdf
Privacy diffusion on the web: A longitudinal perspective, Balachander Krishnamurthy and Craig E. Wills. In Proceedings of the World Wide Web Conference, pages 541-550, Madrid, Spain, April 2009. http://www.cs.wpi.edu/~cew/papers/www09.pdf
P3P 1.0, April 2002,
http://www.w3.org/TR/2002/REC-P3P-20020416/
P3P 1.1 November 2006,
http://www.w3.org/TR/2006/NOTE-P3P11-20061113/
http://www.json.org/
Privacy Icons, Aza Raskin. W3C API Privacy Workshop, July 2010. http://www.w3.org/2010/api-privacy-ws/slides/raskin.pdf
AT&T Privacy Bird website http://www.privacybird.org/
Use of a P3P User Agent by Early Adopters, Lorrie Faith Cranor, Manjula Arjula, and Praveen Guduru, In Proceedings of the ACM Workshop on Privacy in the Electronic Society, November 21, 2002. http://lorrie.cranor.org/pubs/wpes02/
Second Release of the Policy Engine, PrimeLife D5.3.2, March 2011, http://www.primelife.eu/images/stories/deliverables/d5.3.2-second_release_of_the_policy_engine-public.pdf
An Efficient System for Non-transferable Anonymous Credentials with Optional Anonymity Revocation, Jan Camenisch and Anna Lysyanskaya, EUROCPRYPT 2001. http://eprint.iacr.org/2001/019
Identity Mixer website, http://idemix.wordpress.com/publications/
Privacy Dashboard download:
http://www.primelife.eu/results/opensource/76-dashboard
Copyright © 2011 by the PrimeLife
Consortium