RDF enables information providers to attach general metadata to
published web resources. This metadata intends to be
machine-interpretable so that web developers can access it by
programming languages in order to create applications for i.e.,
crawling, aggregating, summarizing, or highlighting contained
information. While publishing RDF data on the web is vital to the growth
of Linked Data,
using the information to improve the collective utility of the Web for
humankind is the true goal. To accomplish this goal, the RDF Application
Programming Interface (RDF API) defines a set of standardized interfaces
for working with RDF data in a web-based programming environment.
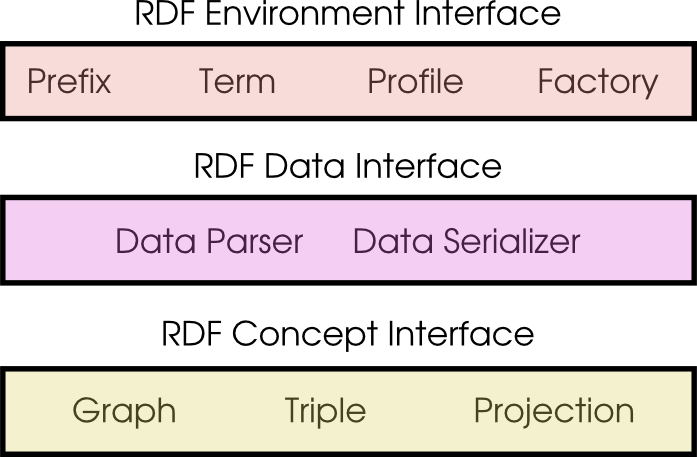
The RDF API Specification
The following section contains all of the interfaces that RDFa API
implementers are expected to provide as well as guidance to ensure that
implementations are conformant.
Term Maps
- omittable getter DOMString get(in DOMString term)
-
- DOMString term
- The term MUST not contain any whitespace or the
: (single-colon) character
- omittable setter void set(in DOMString term, in DOMString iri)
-
- DOMString term
- The term MUST not contain any whitespace or the
: (single-colon) character
- DOMString iri
- An IRI, as defined by [[!IRI]]
- omittable deleter void remove(in DOMString term)
-
- DOMString term
- The term MUST not contain any whitespace or the
: (single-colon) character
- DOMString resolve(in DOMString term)
-
Given a valid term for which an IRI is known (for example "label"),
this method will return the resulting IRI (for example "http://www.w3.org/2000/01/rdf-schema#label").
If no term is known and a default has been set, the
IRI is obtained by concatenating the term and the default
iri.
If no term is known and no default is set, then
this method returns null.
- DOMString term
- The term to resolve.
- DOMString shrink(in DOMString iri)
- Given an IRI for which an term is known (for example
"http://www.w3.org/2000/01/rdf-schema#label")
this method returns a term (for example "label"), if no
term is known the original IRI is returned.
- DOMString iri
- The IRI to shrink to an term
- void setDefault(in DOMString iri)
-
- DOMString iri
- The default iri to be used when an term cannot be resolved, the
resulting IRI is obtained by concatenating this
iri with
the term being resolved.
- TermmMap import(in TermMap terms, in optional boolean override)
-
This method returns the instance on which it was called.
- TermMap terms
- The TermMap to import.
- optional boolean override
- If
true then conflicting terms will be
overridden by those specified on the TermMap being
imported, by default imported terms augment the existing set.
Example
This example illustrates how TermMap can be used to
resolve known terms to IRIs, shrink IRIs for known terms in to terms,
and how to specify and use a default vocabulary for unknown terms.
Profiles
Profiles provide an easy to use context for negotiating between
CURIEs, Terms and IRIs.
- readonly attribute PrefixMap prefixes
- An instance of PrefixMap
- readonly attribute TermMap terms
- An instance of TermMap
- DOMString resolve(in DOMString toresolve)
-
Given an Term or CURIE this method will return an IRI, or null if it cannot be resolved.
If toresolve contains a : (colon) then this method returns the result of calling prefixes.resolve(toresolve)
otherwise this method returns the result of calling terms.resolve(toresolve)
- DOMString toresolve
- A string Term or CURIE.
- void setDefaultVocabulary(in DOMString iri)
- This method sets the default vocabulary for use when resolving
unknown terms, it is identical to calling the
setDefault
method on terms.
- DOMString iri
- The IRI to use as the default vocabulary.
- void setDefaultPrefix(in DOMString iri)
- This method sets the default prefix for use when resolving
CURIEs without a prefix, for example
":me", it is
identical to calling the setDefault method on prefixes.
- DOMString iri
- The IRI to use as the default prefix.
- void setTerm(in DOMString term, in DOMString iri)
- This method associates an IRI with a term, it is identical to
calling the
set method on term.
- DOMString term
- The term to set, MUST not contain any whitespace or the
: (single-colon) character
- DOMString iri
- The IRI to associate with the term.
- void setPrefix(in DOMString prefix, in DOMString iri)
- This method associates an IRI with a prefix, it is identical
to calling the
set method on prefixes.
- DOMString prefix
- The prefix to set, MUST not contain any whitespace.
- DOMString iri
- The IRI to associate with the prefix.
- Profile importProfile(in Profile profile, in optional boolean
override)
-
This method functions the same as calling prefixes.import(profile.prefixes,
override) and terms.import(profile.terms, override), and
allows easy updating and merging of different profiles, such as those
exposed by parsers.
This method returns the instance on which it was called.
- Profile profile
- The Profile to import.
- optional boolean override
- If
true then conflicting terms and prefixes will
be overridden by those specified on the Profile being
imported, by default imported terms and prefixes augment the existing
set.
Projections
A Projection is an object-oriented view of a particular subject
that is expressed in the document. For example, to get all projections that
express people in a document, a developer can do the following:
var people = document.data.getProjections("http://www.w3.org/1999/02/22-rdf-syntax-ns#type", "http://xmlns.com/foaf/0.1/Person");
A developer can also specify short-cuts to use when specifying the URI:
document.data.setMapping("rdf", "http://www.w3.org/1999/02/22-rdf-syntax-ns#type");
document.data.setMapping("foaf", "http://xmlns.com/foaf/0.1/");
var people = document.data.getProjections("rdf:type", "foaf:Person");
The Projection interface is used to build language-native
objects that can be accessed in a way that is natural for the
implementation language.
- DOMString[] getProperties()
- Retrieves the list of properties that are available on the
Projection. Each property MUST be an absolute URI.
- DOMString getSubject()
- Retrieves the subject URI of this Projection as a string, the
value MUST be an absolute URI.
- any getter get()
- Retrieves the first property with the given name as a language-native
datatype.
- DOMString uriOrCurie
- The name of the property to retrieve. The argument can be
either an absolute URI or a CURIE that will be resolved using the default
document mapping.
- any[] getAll(in uriOrCurie)
- Retrieves the list of values for a property as an array of
language-native datatypes.
- DOMString uriOrCurie
- The name of the property to retrieve. The argument can be
either a full URI or a CURIE that will be resolved using the default
document mapping.
RDF Environment
The RDF Environment is an interface which exposes a high level
API for working with RDF in a programming environment, an instance of
this interface MUST be exposed by an rdf attribute by
libraries implementing the RDF API. For example:
The RDF Environment interface extends Profile and
provides the default context for working with CURIEs, Terms and IRIs,
implementations are encouraged to offer rich prefix maps by default, and
MUST instantiate the environment with the following prefixes defined:
| Prefix |
IRI |
| owl |
http://www.w3.org/2002/07/owl# |
| rdf |
http://www.w3.org/1999/02/22-rdf-syntax-ns# |
| rdfs |
http://www.w3.org/2000/01/rdf-schema# |
| rdfa |
http://www.w3.org/ns/rdfa# |
| xhv |
http://www.w3.org/1999/xhtml/vocab# |
| xml |
http://www.w3.org/XML/1998/namespace |
| xsd |
http://www.w3.org/2001/XMLSchema# |
This interface also exposes all methods required to create
instances of TermMaps, PrefixMaps, Profiles and all the Concept
Interfaces.
Implementations MUST expose all the methods defined on this
interface, as defined by this specification.
Future RDF API extensions and modules SHOULD supplement this
interface with methods and attributes which expose the functionality
they define, in a manner consistent with this API.
- Profile createProfile(in optional boolean empty)
-
- optional boolean empty
- If
true is specified then a profile with an
empty TermMap and PrefixMap will be returned, by default the Profile
returned will contain populated term and prefix maps replicating those
of the current RDF environment.
- TermMap createTermMap(in optional boolean empty)
-
- optional boolean empty
- If
true is specified then an empty TermMap
will be returned, by default the TermMap returned will be
populated with terms replicating those of the current RDF environment.
- PrefixMap createPrefixMap(in optional boolean empty)
-
- optional boolean empty
- If
true is specified then an empty PrefixMap
will be returned, by default the PrefixMap returned will
be populated with prefixes replicating those of the current RDF
environment.
Document Data
The DocumentData interface is used to access the structured data
in the document.
- attribute optional RDFEnvironment rdf
- The interface to the RDF convenience methods and functionality.
Implementations MAY omit access to the underlying RDF implementation.
If implementations include this attribute, they MUST conform to the
[[!RDF-INTERFACE]] specification.
- attribute RDFaEnvironment rdfa
- The RDFa Environment interface provides RDFa-specific capabilities.
- Projection getProjection (in DOMString subject, in optional object template)
- Retrieves a Projection given a subject and an optional
Projection template if the subject exists in the document. If the subject
does not exist in the document,
null is returned.
- DOMString subject
- The subject to use when matching against triples. The subject can
be either an absolute URI or a CURIE. The subject is used
to match against the URI in the first part of a triple. An implementation
MUST coerce the DOMString to the same type as the triple's subject being
compared. If the type coercion will result in a URI, the CURIE mappings
MUST be queried first for a mapping and the given property expanded as a
CURIE if a mapping is found. If the subject does not exist in the
document, the return value MUST be
null.
- optional object template
- The Projection template is used to build the return
value. The template consists of a key-value associative array
where the key is the name of the property to create in the
Projection and the value is the URI to use when matching against
predicates in each triple.
- Sequence <Projection> getProjections(in optional object? template)
- Retrieves a list of all Projections in the document using
the optional Projection template to build the
Projections.
- optional object template
- The Projection template is used to build the return
value. The template consists of a key-value associative array
where the key is the name of the property to create in the
Projection and the value is the URI to use when matching against
predicates in each triple.
- Sequence <Projection> getProjections (in optional DOMString property, in optional DOMString? value, in optional object template)
- Retrieves a list of Projections that match the given optional
property and value, constructed using the given Projection
template.
- optional DOMString property
- The property to use when matching against triples. The property can
be either an absolute URI or a CURIE. The property is used
to match against the URI in the second part of a triple, also known as the
predicate. An implementation MUST coerce the DOMString to the same type as
the predicate being compared. If the type coercion will result in
a URI, the CURIE mappings MUST be queried first for a mapping and the given
property expanded as a CURIE if a mapping is found. If the value is
null, the match is always positive.
- optional DOMString? value
- The value to use when matching against triples. The value can
be either an absolute URI or a CURIE. The value is used to
match against the final part of a triple, also known as the object. An
implementation MUST coerce the DOMString to the same type as the
object being compared. If the type coercion will result in a URI, the
CURIE mappings MUST be queried first for a mapping and the given value
expanded as a CURIE if a mapping is found. If the value is
null, the match is always positive.
- optional object template
- The Projection template is used to build the return
value. The template consists of a key-value associative array
where the key is the name of the property to create in the
Projection and the value is the URI to use when matching against
predicates in each triple.
- Sequence<DOMString> getProperties (in optional DOMString? subject)
- Retrieves a list of DOMStrings which are IRI identifiers for properties
given an optional subject to match against.
- optional DOMString? subject
- The subject to use when matching against triples. The subject is used
to match against the URI in the first part of a triple. The subject can
be either an absolute URI or a CURIE. The subject is used to
match against the first part of a triple. An implementation MUST coerce the
DOMString to the same type as the triple's subject that is being compared.
If the type coercion will result in a URI, the CURIE mappings MUST be
queried first for a mapping and the given property expanded as a CURIE if a
mapping is found. If the given subject is
null, the match is
always positive.
- Sequence<DOMString> getSubjects (in optional DOMString? property, in optional DOMString? value)
- Retrieves a list of DOMStrings which are IRI identifiers for subjects
given an optional property and value to match against.
- optional DOMString? property
- The property to use when matching against triples. The property can
be either an absolute URI or a CURIE. The property is used
to match against the URI in the second part of a triple, also known as the
predicate. An implementation MUST coerce the DOMString to the same type as
the predicate being compared. If the type coercion will result in
a URI, the CURIE mappings MUST be queried first for a mapping and the given
property expanded as a CURIE if a mapping is found. If the value is
null, the match is always positive.
- optional DOMString? value
- The value to use when matching against triples. The value can
be a number, a boolean, a DOMString, an absolute URI or a CURIE. The value is
used to match against the final part of a triple, also known as the object.
An implementation MUST coerce the DOMString to the same type as the triple
object being compared. If the type coercion will result in a URI, the
CURIE mappings MUST be queried first for a mapping and the given property
expanded as a CURIE if a mapping is found. If the value is
null, the match is always positive.
- Sequence<any> getValues (in optional DOMString? subject, in optional DOMString? property)
- Retrieves a list of mixed types given an optional subject and property to
match against.
- optional DOMString? subject
- The subject to use when matching against triples. The subject can
be either an absolute URI or a CURIE. The subject is used
to match against the URI in the first part of a triple. An implementation
MUST coerce the DOMString to the same type as the subject being
compared. If the type coercion will result in a URI, the CURIE mappings MUST
be queried first for a mapping and the given property expanded as a CURIE if
a mapping is found. If the value is
null, the match is always
positive.
- optional DOMString? property
- The property to use when matching against triples. The property can
be either an absolute URI or a CURIE. The property is used
to match against the URI in the second part of a triple, also known as the
predicate. An implementation MUST coerce the DOMString to the same type as
the predicate being compared. If the type coercion will result in
a URI, the CURIE mappings MUST be queried first for a mapping and the given
property expanded as a CURIE if a mapping is found. If the value is
null, the match is always positive.
- DOMString setMapping ()
- Sets a mapping given a mapping and a URI to map.
- in DOMString mapping
- The shortened form of the URI to map.
- in DOMString uri
- An absolute URI that the mapping should expand to when used with any
of the structured data APIs.