Roberto García
Universitat de Lleida, Spain
rgarcia@diei.udl.cat
http://rhizomik.net/~roberto
This position paper is related with the Rhizomik initiative carried out by the GRIHO Human-Computer Interaction and Data Integration research group of the Universitat de Lleida. From the data integration perspective, the Rhizomik initiative proposes generic tools that facilitate mapping XML instance data and schemas to Semantic Web technologies. These tools can be applied in the XBRL scenario and can contribute a quick and direct way to make XBRL data and schemas available for processing using Semantic Web technologies and methodologies.
XBRL is constrained by its XML document-oriented nature. This makes more difficult to perform queries that mix information from filings from different dates, companies, or accounting principles than with a formalism based on a graph model instead of a tree model. Semantic Web technologies provide a graph model that facilitates mashing-up different XBRL sources.
We have put into practice this approach mapping the XBRL filings available from the SEC’s EDGAR program to Resource Description Framework (RDF) and the XML Schema taxonomies these filings are based on to Web Ontology Language (OWL). The resulting semantic metadata, though highly tied to the XML structure it is mapped from, benefits from Semantic Web technologies and tools in order to facilitate integration and cross-querying, even together with other parts of the Web of Linked Data.
In order to move existing XBRL instances and taxonomies to the Semantic Web, and due to the fact that XBRL is based on XML and XML Schema, we have applied the XML Semantics Reuse methodology [1]. This methodology is implemented as two mappings by the ReDeFer project , the first one from XML Schema to OWL and the second one from XML to RDF.
This approach has already shown its usefulness with other quite big XML Schemas, especially in the multimedia metadata domain [2], where it has produced the more complete MPEG-7 ontology to date [3].
The XML Schema to OWL mapping is responsible for capturing the schema semantics. This semantics are determined by the combination of XML Schema constructs. The mapping is based on translating these constructs to the OWL ones that best capture their intended meaning. These translations are detailed in Table 1.
Table 1. XSD2OWL translations for the XML Schema constructs and shared semantics with OWL constructs
|
XML Schema |
OWL Mapping | Motivation |
| element | attribute |
rdf:Property owl:DatatypeProperty owl:ObjectProperty |
Named relation between nodes or nodes and values |
| element@substitutionGroup | rdfs:subPropertyOf | Relation can appear in place of a more general one |
| element@type | rdfs:range | The relation range kind |
|
complexType | group | attributeGroup |
owl:Class | Relations and contextual restrictions package |
| complexType//element | owl:Restriction | Contextualised restriction of a relation |
|
extension@base | restriction@base |
rdfs:subClassOf | Package concretises the base package |
|
@maxOccurs @minOccurs |
owl:maxCardinality owl:minCardinality |
Restrict the number of occurrences of a relation |
Once all the metadata XML Schemas are available as mapped OWL ontologies, it is time to map the XML metadata that instantiates them. The mapping is based on modeling the XML structure, i.e. a tree, using RDF.
The fundamental translation is between relations, from xsd:elements and xsd:attributes to rdf:Properties. Concretely, owl:ObjectProperties for node to node relations and owl:DatatypeProperties for node to value ones.
Values are kept during the translation as simple types and RDF blank nodes are introduced in the RDF model in order to serve as the source and destination for properties. They will remain blank for the moment until they are enriched with semantic information.
The resulting RDF graph model contains all that we can obtain from the XML tree. It is already semantically enriched thanks to the rdf:type relation that connects each RDF property to the owl:ObjectProperty or owl:DatatypeProperty it instantiates. It can be enriched further if the blank nodes are related to the owl:Class that defines the package of properties and associated restrictions they contain, i.e. the corresponding xsd:complexType. This semantic decoration of the graph is formalised using rdf:type relations from blank nodes to the corresponding OWL classes.
First of all, we have generated an ontological infrastructure for the XBRL core, currently XBRL 2.1. It is composed by the ontologies resulting from mapping the XBRL core XML Schemas using the XSD2OWL mapping: XBRL Instance, XBRL Linkbase, XBRL XL and XBRL XLink. Apart from the previous schemas, the EDGAR Standard Taxonomies schemas have been also mapped in order to be able to map the XBRL data submitted to the XBRL voluntary program EDGAR.
Each filing for the companies participating in the EDGAR program contains an XBRL XML file representing the actual financial data and also a specific XML Schema extending the XBRL core. This schema provides specific guides for the corresponding financial data. Both files are mapped using XML2RDF and XSD2OWL respectively.
For instance, for Adobe Systems Inc filing on 2008-07-03, there are the adbe-20080616.xml file containing the instance data and the adbe-20080530.xsd schema for data structures specific for this filing. They are mapped, respectively, to the RDF file for instance data adbe-20080616.rdf and the OWL ontology adbe-20080530.owl for the schema.
All the previous ontologies are available from the BizOntos Business Ontologies web page and the semantic data for all the processed filings can be queried and browsed from the Semantic XBRL site . Currently, 612 filings have been processed from EDGAR. The combination of all these filings once mapped to RDF amounts slightly more than 1.3 million triples.
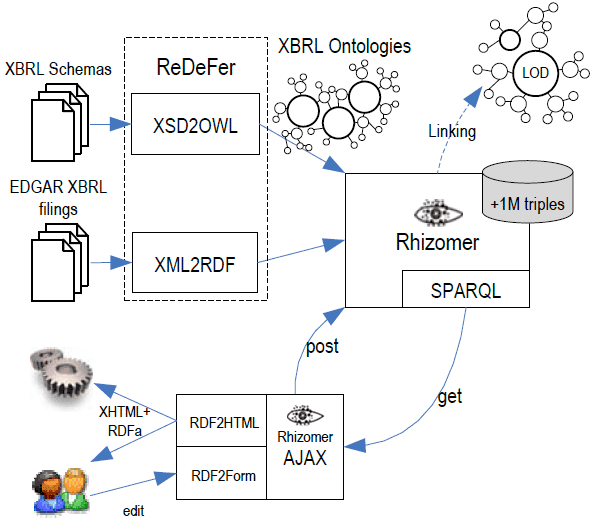
Finally, the generated data is published as Linked Open Data in the World Wide Web. The approach is based on generating XHTML plus RDFa. In order to do that, we have used the Rhizomer platform that, apart from encapsulating the metadata store, also provides an RDF to XHTML+RDFa transformation and a RDF to HTML Form transformation that makes it possible for users to interactively edit the published data. The whole architecture is shown in Figure 1.
Fig. 1. Rhizomer SemanticXBRL architecture
By applying the proposed approach, it is possible to map the XML data for XBRL filings in order to generate RDF semantic data that keeps all the original information and structure. This mapping also includes the involved XML Schemas that structure the XML data. These schemas are mapped to Web ontologies, which make all the semantics implicit in the original XML Schemas explicit and available when semantically querying RDF data.
Moreover, it is also possible to take profit from Web ontology primitives in order to semantically integrate different filings following different XML Schemas, i.e. XBRL taxonomies. Once mapped to ontology concepts and relations, the XBRL contexts, facts and other resources defined for different filings can be related as more specific, more general or equivalent.
This approach has been put into practice in the context of the SEC’s EDGAR program that promotes XBRL filings for USA companies. It has been possible to apply the previous XML to RDF and XML Schema to Web ontology mappings to a test set of more than 600 EDGAR filings and more than 1.3 million triples have been obtained.
We have also have made all this semantic information generated from the EDGAR program available online, so it can be queried and browsed using a Web user interface. The proposed semantic queries illustrate the benefits of the semantic integration available once XBRL data is translated to semantic data.
However, it is important to note that we do not see our proposal as an alternative to XBRL. Semantic Web technologies have some limitations that currently do not make them a clear alternative to XBRL. For instance, OWL does not provide the primitives to easily model features available in XBRL like the calculation facilities provided by calculation linkbases.
Moreover, the characteristics of the logic formalisms underlying OWL might not be the more intuitive choice in some XBRL use scenarios. For instance, a great part of OWL relies on the Open World Assumption and it is based on restrictions instead of on constraints [4].
On the contrary, we see XBRL and the Semantic Web as clearly complementary. XBRL can be used for business and financial data representation and validation, while its translation to Semantic Web technologies can be the way to make all this data publicly available enabling cross analysis of this data thanks to semantic integration and a graph based model.