RDF and SOA
Views expressed herein are those of the
author and do not necessarily reflect those of HP.
Abstract
The purpose of this paper is not to propose a particular standardization
effort for refining the existing XML-based, WS* approach to Web services, but
to suggest another way of thinking about SOA in terms of RDF message
exchange, even when custom XML formats are used for message serialization.
As XML-based Web services proliferate through and between organizations, the
need to integrate data across services, and the problems of inconsistent
vocabularies across services ("babelization"), will become increasingly
acute. In other contexts, RDF has clearly demonstrated its value in
addressing data integration problems and providing a uniform, Web-friendly
way of expressing semantics. Might these benefits also be applicable in
an SOA context? Thus far, the Web services community has shown little
interest in RDF. Web services are firmly wedded to XML, and RDF/XML
serialization is viewed as being overly verbose, hard to parse and
ugly. This paper suggests that the worlds of XML and RDF can be bridged
by viewing XML message formats as specialized serializations of RDF
(analogous to microformats or micromodels). This would allow an
organization to incrementally make use of RDF in some services or
applications, while others continue to use XML. GRDDL, XSLT and SPARQL
provide some starting points but more work is needed.
Introduction
Although in one sense Web services appear to be a huge success -- and they
are for point-to-point application interaction -- their success is exposing
new problems. Large organizations have thousands of
applications they must support. Legacy applications are being wrapped
and exposed as Web services, and new applications are being developed as Web
services, using other services as components. These services
increasingly need to interconnect with other services across an
organization.
Use cases
For example, consider the following use cases:
- An organization wishes to automate some of its security administration
procedures by connecting and orchestrating several existing applications,
each of which currently uses its own message formats, domain model and
semantics. Applications originally intended for one purpose need to
be interconnected and data needs to be integrated and reused.
- Each of these applications needs to be versioned independently, without
breaking the orchestrated system.
- After achieving the above, the organization then wishes to automate the
process of periodically auditing the security authorizations that have
been automatically granted by this orchestrated system. Thus, it
must relate the terms and semantics used by one application at one end of
the orchestration to the terms and semantics used by another application
at the other end of the orchestration.
These use cases are intentionally general. Here are some of the
problems they expose.
XML brittleness and versioning
Perhaps the most obvious problem with XML-based message formats is the
brittleness of XML in the face of versioning. Both parties to an
interaction (client and service) need to be versionable independently.
This problem is a well recognized, but still a challenge.
Inconsistent vocabularies across services: "babelization"
In the current XML-based, WS* approach to Web services, each WSDL document
defines the schemas for the XML messages in and out, i.e., the vocabulary for
that service. In essence, it describes a little language for
interacting with that service. As Web services proliferate, these
languages multiply, leading to what I have been calling "babelization".
This makes it more difficult to connect services in new ways to form new
applications or solutions, integrate data from multiple services, and relate
the semantics of the data used by one service to the semantics of the data
used by another service.
Schema hell
If we look at the history of model design in XML, it can be characterized
roughly like this.
- Version 1: "This is the model."
- Version 2: "Oops! No, this
is the model."
- Version 3: "This is the model today, but here is an extensibility
point for tomorrow."
- Version 4: "This is the super
model (with extensibility for tomorrow, of course)." [Explanation]
- Version 5: "This is the super-duper-ultra model (with extensibility, of
course)."
There are two basic problems with
this progression. The first of course is the versioning challenge it
poses to clients and services that use the model. The second is that
over time the model gets very complex, though each service or component often
only cares about one small part of the model.
Like a search for the holy grail, this eternal quest to define the model is forever doomed to fail.
There is no such thing as the model! There are many models, and there always will
be. Different services -- or even different components within a service
-- need different models (or at least different model subsets). Even
the same service will need different models at different times, as the
service evolves.
Why do we keep following this doomed path? The reason, I believe, is
deeply rooted in the XML-based approach to Web services: each service is
supposed to specify the model that
its client should use to interact with that service, and XML models are
expressed in terms of their syntax, as XML schemas. Thus, although in
one sense the XML-based approach to Web services has brought us a long way
forward from previous application integration techniques, and has reduced
platform and language-dependent coupling between applications, in another
sense it is inhibiting even greater service and data integration, and
inhibiting even looser coupling between services.
Benefits of RDF
RDF has some notable
characteristics that could help address these problems.
- Easier data integration.
RDF excels at data integration: joining data from multiple data models.
[Why]
- Easier versioning. RDF
makes it easier to independently version clients and services. [Why]
- Consistent semantics across
services. [Why]
- Emphasis on domain
modeling. [Why]
XML experts may claim that an RDF approach would merely be trading XML schema
hell for RDF ontology hell, which of course is true, because as always there
is no silver bullet. But RDF ontology hell seems to scale better than
XML schema hell, again because it provides a uniform semantic base grounded
in URIs, and it is syntax independent. Furthermore, these benefits will
become increasingly important over time. [More
on weighing benefits] [Differences
in data validation]
RDF in an XML world: Bridging RDF and XML
It's all fine and dandy to tout the merits of RDF, but Web services use
XML! XML is well entrenched and loved. How can these two worlds
be bridged? How can we incrementally gain the benefits of RDF while
still accommodating XML?
Treating XML as a specialized serialization of RDF
Recall that RDF is syntax independent: it specifies the data model, not the
syntax. It can be serialized in existing standard formats, such as
RDF/XML or N3, but it could also be serialized using
application-specific formats. For example, a new XML or other format
can be defined for a particular application domain that would be treated as a
specialized serialization of RDF in RDF-aware services, while being processed
as plain XML in other applications. A mapping can be defined (using
XSLT or something else) to transform the XML to RDF. Gloze
may also be helpful in "lifting" the XML into RDF space based on the XML
schema, though additional domain-specific conversion is likely to be needed
after this initial lift. GRDDL provides a standard
mechanism for selecting an appropriate transformation.
In fact, this approach need not be limited to new XML or other formats: any
existing format could also be viewed as a specialized serialization of RDF if
a suitable transformation is available to map it to RDF. This approach
is analogous to the use of microformats or micromodels, except that it is not
restricted to HTML/xhtml, and it would typically use application-specific
ontologies instead of standards-based ontologies.
Generating XML views of RDF
On output, a service using RDF internally may need to produce custom XML or
other formats for communication with other XML-based services. Although
we do not currently have very convenient ways to do this, SPARQL may be a
good starting point. TreeHugger
and RDF Twig could also be
helpful starting points.
Defining interface contracts in terms of RDF messages
Although the RDF-enabled service may need to accept and send messages in
custom XML or other serializations, to gain the versioning benefits of RDF it
is important to note that the interface contract should be expressed, first
and foremost, in terms of the underlying RDF messages that need to be
exchanged -- not the serialization. Specific clients that are not
RDF-enabled may require particular serializations that the service must
support, but this should be secondary to (or layered on top of) the
RDF-centric interface contract, such that the primary interface contract is
unchanged even if serializations change.
An RDF-enabled service in an XML world
The diagram below illustrates how an RDF-enabled service might work.
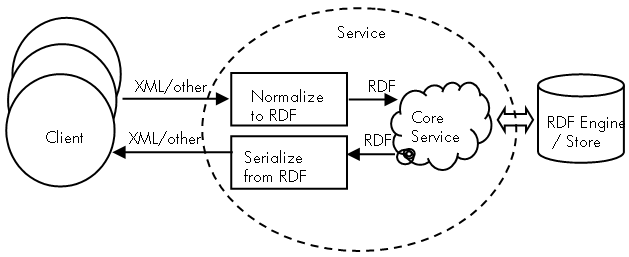
[Explanation]
[Comments
on granularity] [Comments
on efficiency] [Summary
of principles]
Conclusion and suggestions
Although we have some experience that suggests this approach may be useful,
there are still some technology gaps, and we need practical experience with
it. I would like to see:
- More exploration of paths for the graceful adoption of RDF in an XML
world. Techniques to facilitate the coexistence of XML and RDF in
the context of SOA.
- More work on techniques for transforming XML to RDF. GRDDL is a
good step, and XSLT is one potential transformation language. Are
there better ways?
- More work on ways to transform RDF to XML. SPARQL seems like a
good start.
- More work on practical techniques for validating RDF models in an SOA
context. SPARQL may be one good approach. Are there
others?
- Best practices for all of the above.
*Thanks to Stuart Williams for helpful comments and suggestions on this
document.
Last updated: Thu Jan 11 06:08:09 UTC 2007