









http://www.w3.org/2006/Talks/0525-ka-voice/
Kazuyuki Ashimura
<ashimura@w3.org>
25 May, 2006

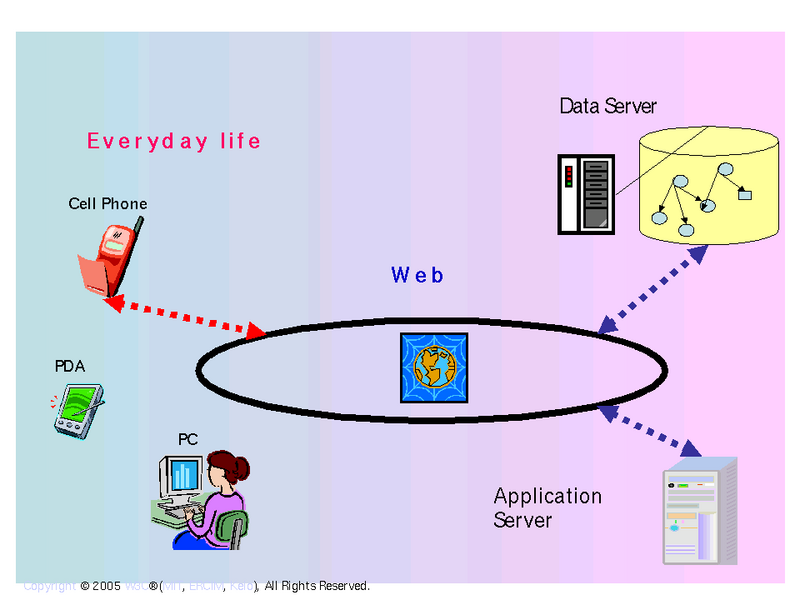
Applying Web technology to enable users to access services from their telephone.
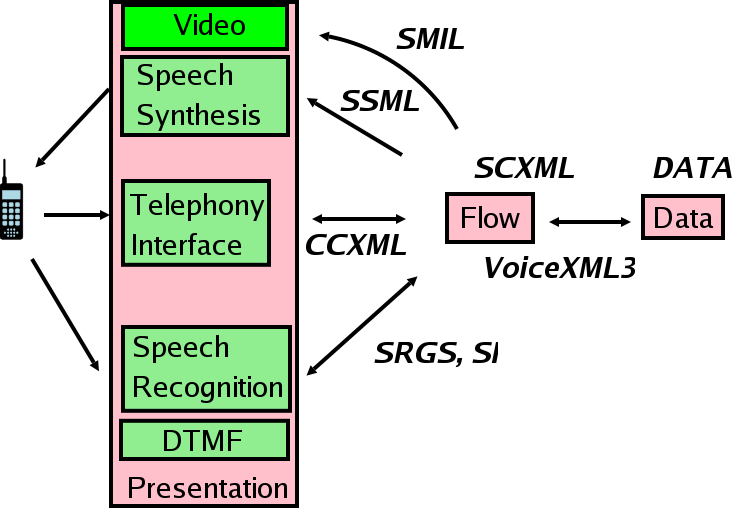
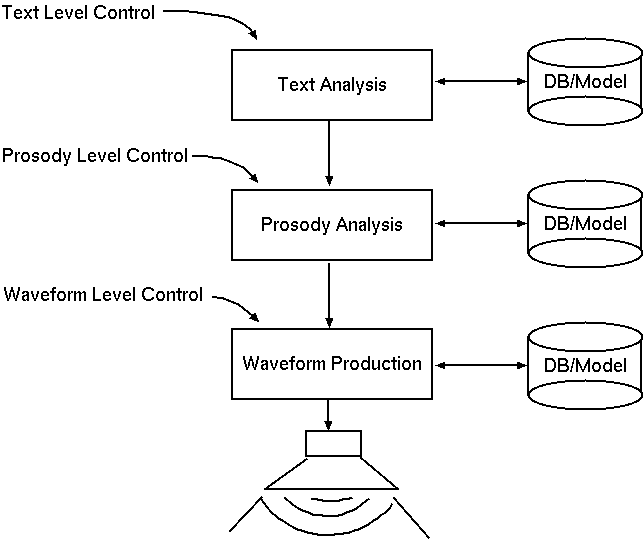
Modular approach faciliates application development, maintainance, debugging and reuse.
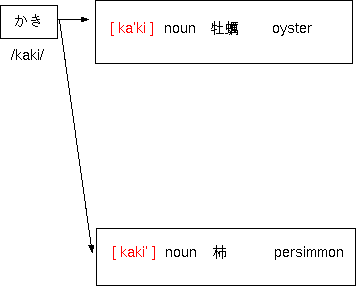
|
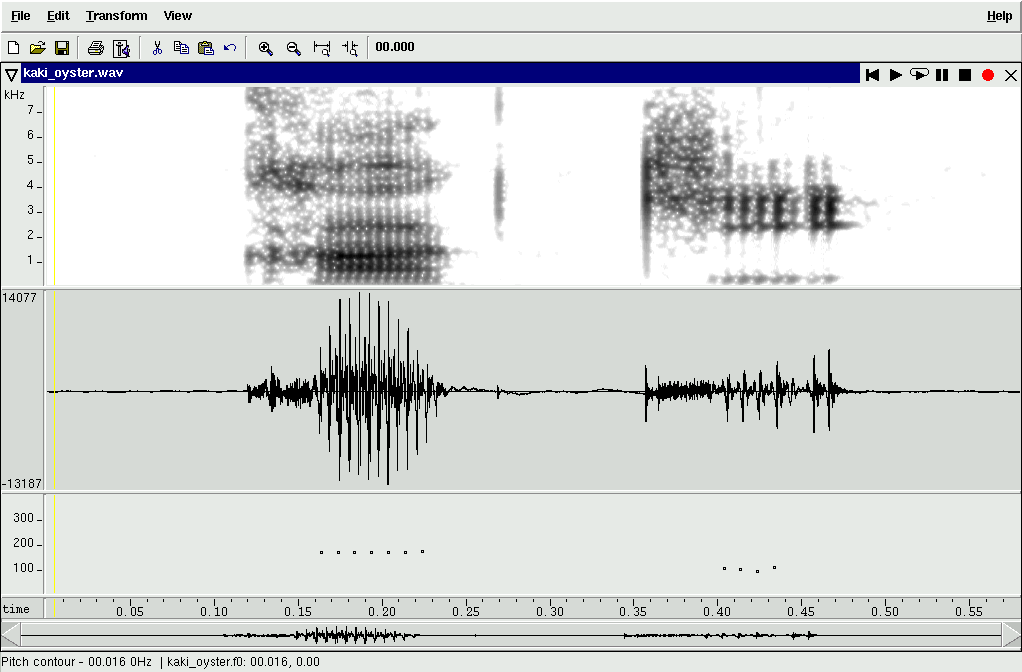
|
|
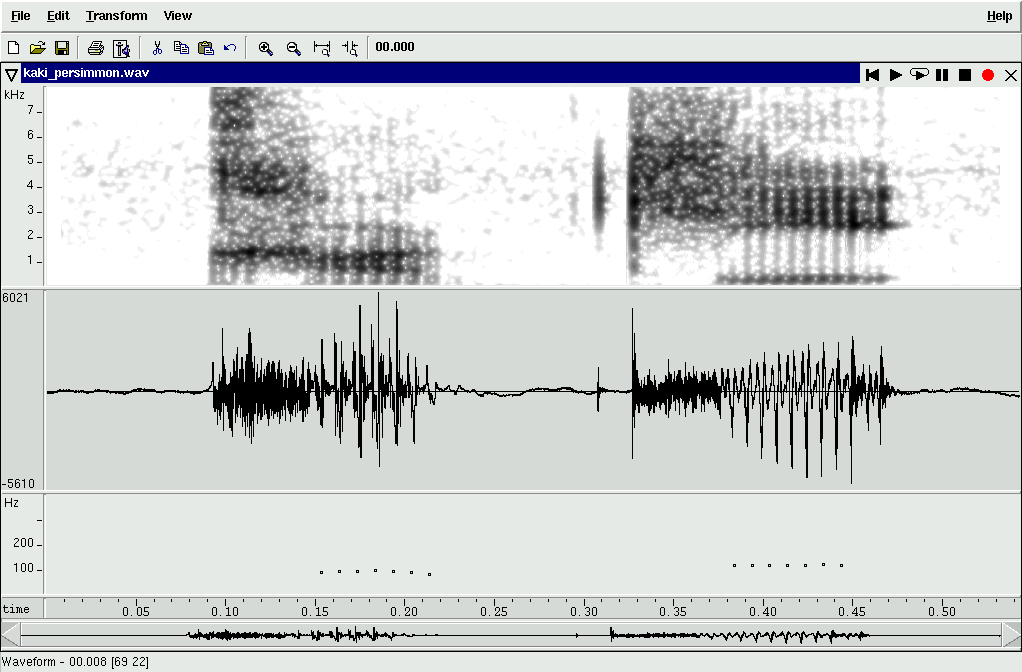
Note: "'" means that there is an accent nucleus (= perceived pitch falling).
| Person A: |
"お昼ごはんを食べましょう" (o-hiru gohan wo tabe masho) Shall we go to lunch? |
|---|---|
| Person B: |
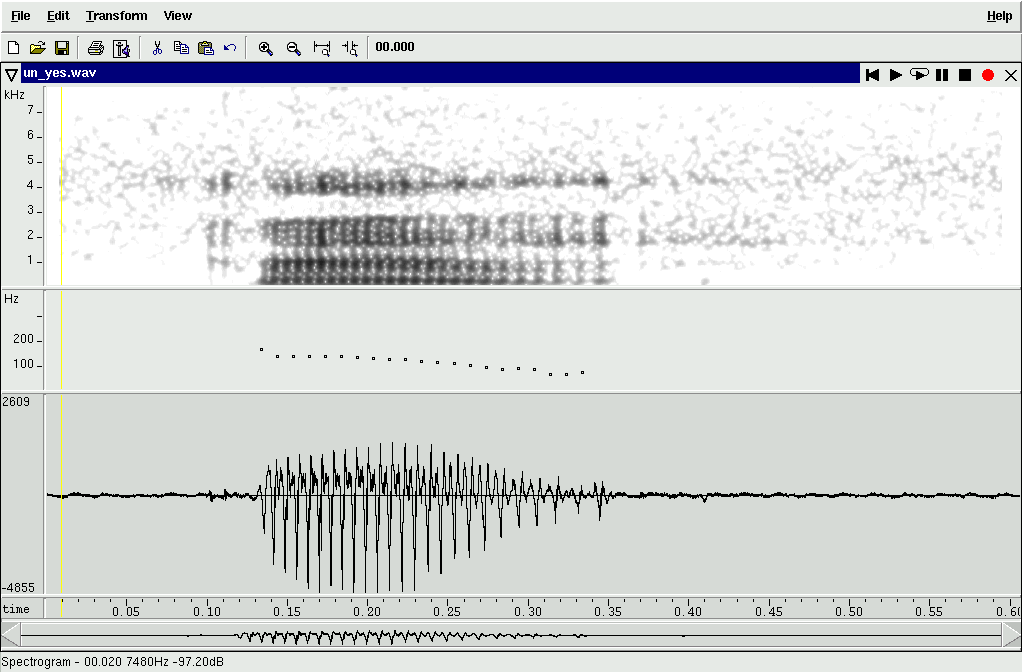
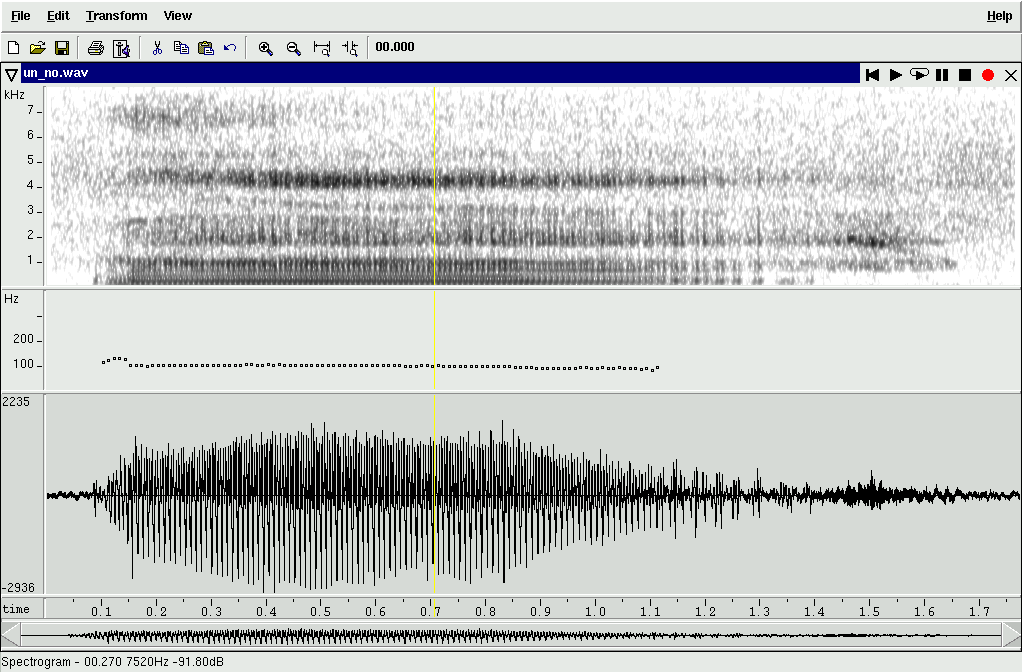
"うん" (un) Yes or No... |
|
|
|
|