Problems With Expressiveness Of The Schema Language
We have encounter several problems because of limitations in the expressiveness of the schema language and these are described below, ranked most severe to least.
1. Extend Only At End
For each UML class in a given model we generate a complex type. The content model of the type is a sequence of the attributes (UML class attributes and obviously not XML attribute) and associations of the given class, where the child elements for the class attributes come before the child elements for the associations.
When one UML class specializes another class (by adding attributes and/or associations) we would like to be able to define the complex type for the specialization as an extension of the first class. However, the only way we can could currently do that it is if we break the rule that all child elements representing class attributes come before child elements for associations. This is because of the "extend only at the end" rule.
For example, consider the following simple UML model, with a general Entity class, with LivingSubject and Person specializations that each add additional attributes.
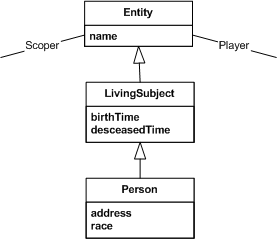
Note: the player and scoper associations go to another class called a Role; e.g. a certain Person plays the Role of patient, scoped by a certain Hospital (Entity).
We need our instances to looked like:
<entity>
<name/>
<player>
…
</player>
<scoper>
…
</scoper>
</entity>
<livingSubject>
<name/> <-- from Entity -->
<birthTime/>
<desceasedTime/>
<player> <-- from Entity -->
…
</player>
<scoper> <-- from Entity -->
…
</scoper>
</livingSubject>
<person>
<name/> <-- from Entity -->
<birthTime/> <-- from Living Subject -->
<desceasedTime/> <-- from Living Subject -->
<address/>
<race/>
<player> <-- from Entity -->
…
</player>
<scoper> <-- from Entity -->
…
</scoper>
</person>
However, because of the "extend only at end" rule there is no way to derive the type for LivingSubject from Entity or Person from LivingSubject and maintain this child element order. We would have to have the following:
<person>
<name/>
<player>
…
</player>
<scoper>
…
</scoper>
<birthTime/>
<desceasedTime/>
<address/>
<race/>
</person>
which we actually tried for a while but that element ordering was confusing to our users. As a result, we have had to give up on using extension at all! [Actually, we use extension in several other places but not to model the class hierarchy in our UML model.] An important part of our processing model is that if a receiver does not understand what a Person is they should still be able to process the information as an instance of a LivingSubject or Entity. Naturally, if we could define the types as extensions of each other then handling this processing model would be very simple…just walk up the base type chain in the PSVI until you got to a type that you understand.
To accomdate this processing model we have had to add fixed attributes in each type whose value is the name of the UML class it represents and receiving applications must maintain their own table of the class hierarchy This is very unfortunate!
2. Lack Of Co-Occurance Constraints
As with many other users, we have a need to express co-occurance contraints. During the WG's discussions on this issue I introduced the distinction between occurance-based and value-based co-occuance contraints. In the first case, the attributes and content model of a given type are conditional on the occurance of some other element/attribute; in the later, the attributes and content model are conditioned on the value of some other element/attribute.
While HL7 has at least one need for value-based constraints we really need occurance-based constraints and would gladly settle for that.
It is often the case with clinical information that the values of certain UML class attributes or an entire UML class at the distal end of an association are unknown or null. XML Schema provides the xsi:nil feature to indicate that required child elements that are missing should not cause the parent element to be treated as invalid.
However, there are two reasons we can't use use xsi:nil (in isolation) to signal these unknown values. First, there are often clinical and/or legal reasons that make it necessary to say why some value is unknown.
Imagine a person is in an auto accident and is rushed to the emergency room unconscious. Their spouse, who was not injured in the accident, is asked for vital clinical information by the admitting nurse: e.g., is the patient allergic to any medications. If the spouse is unsure whether the patient is allergic it is necessary to indicate in the admission message that this question was asked but the answer was unknown, as this is a very different state of affairs from simply not including any information about allergies…if the patient has a reaction to some medication given them in the emergency room, the hospital and doctors have a certain amount of legal protection against malpractice since it is documented that they at least asked! HL7 has developed a very rich vocabulary of "null flavors" to cover all of the various cases of why required information might be unknown. xsi:nil does not give us any way to convey these "null flavors" (we tried to get that capability in while XML Schema was still in development but the rest of the WG felt it didn't make the 80/20 cut…and they may have been right). Instead, we have a separte nullFlavor attribute whose value is drawn from the controlled vocabulary we have developed.
As might be expected, there has been a large amount of confusion among those implementing the HL7 standard about the relationship between our nullFlavor attribute xsi:nil.
Second, in our instances, the values of UML class attributes are (largely) represented as XML attributes on the element that represents the UML class attribute itself. For example,
<livingSubject>
…
<birthTime value='1962-06-17T06:31:00-800'/>
…
</livingSubject>
xsi:nil has no effect on how the presence or absence of attributes effects local validity…it applies only to child elements. Because of this, we have had to make all XML attributes optional…which has the very unfortunately consequence that an instance may be "structurally" valid but contain no actual information. For instance, the instance fragment above is actually valid even though it contains none of the values of UML class attributes. Note: we represent the values of UML class attributes as XML attributes because it drastically reduces the size of our messages…at one time we had developed an element-only language but our community found the bloat to be excessive (on the order of doubling or tripling message size in some cases).
Thus, what we really need is a way to say "if the nullFlavor attribute is present then no child elements and, more importantly in most cases, other attributes are allowed." Without this capability the efficacy of using our schemas for validation is drastically reduced.
3. Wildcards deficiencies
XML Schema provides for the appearance of wildcards in a content model. While there is a great deal of capability embedded in wildcards (controling the namespace in question, and strict/lax/skip processing, etc.) there are two limitations that HL7 has bumped into.
The first is the lack of a "typed" wildcard. We have certain cases where the distal class of a UML association is not known at "design time", all that is known is that it will be a specialization of some given class. That is, instead of saying "any element from namespace foo goes here", we have cases where we need to say "any element of type bar (or any time dervived from bar) goes here".
We have gotten around this limitation by using substitution groups, which have a certain degree of "typed wildcard"-ness. However, using substitution groups is not ideal for us, as it forces us to make certain elements global that we would otherwise rather have be locally scoped. Granted, because of the problems identified with extend only at the end, even having "typed wildcards" would be of limited value since our schema type hierarchy is not as rich as we would really like.
The second is the oft cited problem about harmful interactions between wildcards and UPA. This problem surfaces for us in that we have a construct, called encapulated data (or ED) that is modeled after MIME media types. That is, values of type ED have a mediaType (e.g., img/jpg or text/xml), may be base64 or "text" encoded, an optional "thumbnail" or "abstract/summary" representation, etc. If the mediaType has an appropriate value then the content may be XML markup. The "thumbnail" property is recursively defined as an ED where "thumbnail" is restricted out, and comes in the content model prior other child elements (all optional), including a wildcard to allow for the arbitrary XML content. That is, we would like to have a type such as:
<xs:complexType name='ED' mixed='true'>
<xs:sequence>
<xs:element name='thumbnail' minOccurs='0'/>
<xs:any/>
</xs:sequence>
…
</xs:complexType>
Because of the wildcard--UPA interaction, we have had to limit the extent to which elements from the HL7 namespace are allowed in the abitrary XML markup. In particular, we've had to say that only 'root' elements from our namespace are allowed, as follows:
<xs:complexType name='ED' mixed='true'>
<xs:sequence>
<xs:element name='thumbnail' minOccurs='0'/>
<xs:choice minOccurs='0'>
<xs:any namespace='##other'/>
<xs:any namespace='##local'/>
<xs:element ref='HL7RootElement'/>
</xs:choice>
</xs:sequence>
…
</xs:complexType>
<xs:element name='HL7RootElement' abstract='true'/>
<xs:element name='Message123' substitutionGroup='HL7RootElement'>
…
</xs:element>
<xs:element name='Message567' substitutionGroup='HL7RootElement'>
…
</xs:element>
We believe that the "weak wildcard" direction that the WG is exploring for XML Schema 1.1 will be a definate improvement in this area. The
4. Component Identity Vagueness
Because XML Schema never completely came to grips with the notion of component identity, it is not possible to derive one complex type from another when the "base" type is defined in terms of anonymous types. Of course, the workaround is to name all types, just in case one might want to derive something in the future…but that just needlessly polutes the type symbol-space.
Without good reason, global variables should be avoided in programming. We believe that global types and elements should equally be avoided with good reason.
5. Limitations On All Groups
In Extend Only At End we discussed how we generate one complex type per UML class in our models, with the content model being a sequence of elements, one for each of the UML class attributes, followed by one for each of the UML associations coming from that UML class. In fact, what we'd like to have is something like the following:
<xs:complexType name='Class'>
<xs:sequence>
<xs:all>
<xs:element name='attr1'/>
<xs:element name='attr2'/>
<xs:element name='attr3'/>
</all>
<xs:all>
<xs:element name='assoc1'/>
<xs:element name='assoc2'/>
</all>
</xs:sequence>
…
</xs:complexType>
However, because of the limitations that XML Schema imposes on the all compositor (both the limitation on cardinalities of the particles within the group as well as the fact that an all group can only appear at the "root" of a content model) this is not possible. Thus, we have had to define an arbitrary ordering for UML class attributes and associations and ensure that all of our tools enforce this ordering. That's just one more thing that can go wrong and we would like to see the limitations on the all compositor lifted.