Mark Nottingham and David Orchard (BEA Systems)
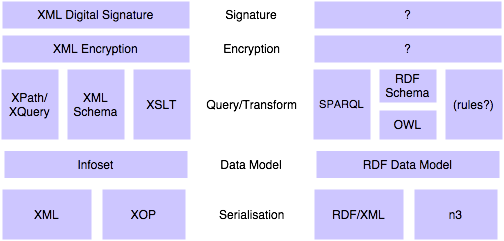
The W3C seems to be standardising two stacks for serialising, modeling and working with data; one based on the Infoset (and its derivatives) as a data model, and one based upon the RDF data model. Although the RDF stack isn't done yet, it's clear that it's going in a similar direction; based upon statements by the Director, facilities like digital signatures for estabilishing trust will eventually standardised (and indeed are already used in demos).
Current Web services specifications focused on the Infoset stack; the Infoset is the basis of communication in SOAP and the default metamodel for describing the message's payload in WDSL. Although other solutions can be used in both cases, there is a clear preference in both the specifications and current implementations for the Infoset.
BEA believes that having two stacks is neither a bad thing, nor an "either/or" choice. The Infoset has the property of being easy to serialise in a human-readable and canonical fashion, and is especially well-suited for markup applications. The RDF Data Model, on the other hand, is simple, scalable, and more capable of representing graph-structured data.
Thus, we encourage the accommodation of more than one data model, particularly in Web services specifications. In the past, we have worked to assure that the specifications actually do this.
There is, however, a difference between accommodating alternate data models and specifying their use. For a variety of reasons -- not least among them, the fact that the set of Web services specifications is considerably complex, and that even the largest Member has limited resources to contribute -- Web services vendors have chosen to concentrate on the Infoset.
Put another way, Web services is a considerable, multi-year undertaking by a large set of companies that only get along some of the time. Introducing a parallel stack that's unfinished and frankly controversial would endanger the entire enterprise, and the damage may not be limited to that effort alone.
This is an important point; in the past, there have been several attempts to force RDF and Semantic Web tecnologies on reluctant Working Groups (e.g., P3P, WSDL). We feel that doing so is not only bound to fail, but it also engenders hostility to the Semantic Web from individuals as well as companies that otherwise might be more neutral.
Thus, while we do not anticipate tying Semantic Web development to Web services development in the immediate future, we do have a few modest suggestions for those who wish to explore and further the use of the Semantic Web in Web services.