Project acronym: QUESTION-HOW
Project Full Title:Quality Engineering
Solutions via Tools, Information and Outreach for the New Highly-enriched
Offerings from W3C: Evolving the Web in Europe
Project/Contract No.
IST-2000-28767
Workpackage 2, Deliverable D2.5
Project Manager: Daniel Dardailler
<danield@w3.org>
Author of this document: Thomas Spinner, Klaus Birkenbihl
Created: 29 August 2002. Last updated: 31 march 2003.
This work describes the development of a multimodal demonstrator, which simulates a mobile Internet device of the next generation. W3C technology was used to implement 3 degrees of multimodality:
First a so called isolated model was implemented. This model communicates either by voice or by visual in/output. Secondly a handover model was derrived from this. In this model the mode of communication is changed explicitly by switching from one mode to another. Finally the multimodal model is introduced as advancement of the two previous models. It allows dynamically to switch from one mode to another and is a model for the new direction of multimodal mobile web communication.
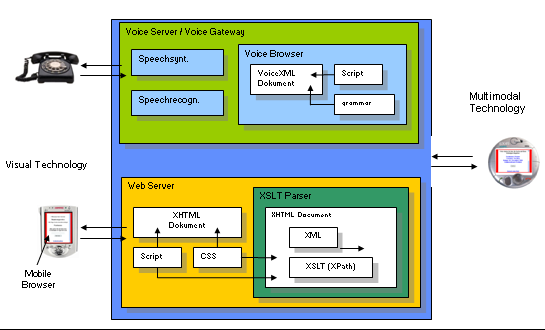
In order to compensate the limited functionality of small mobile devices as for example PDAs or mobile phones several communication channels between users and Internet are used. These different channels formed by a visual and a speech interface form a multimodale application. The demonstrator uses a separate Browser for each of the two modes. For the visual representation a mobile Browser is used and for communication via language a Voice Browser. So that the multi-modality provides an advantage for the user, the two modes are synchronized with each other, so that mixed communication is possible.
For output of information speech synthesis, audio files and visual text are used. For User input speech recognition and the keyboard input is supported.
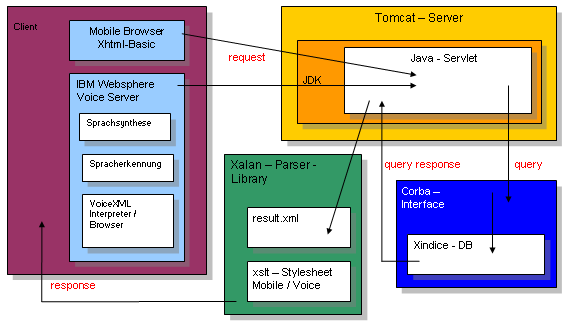
The information contents of this application are multimedia data, which is available in XML format. In order to integrate these data in existing web infrastructures and test available W3C standards on their applicability in this context, the following open standards are used on the client and server side: XML, VoiceXML, XHTML and XHTML basic, XSLT and XPath. Additionally to these languages Java Script is used on the clientsite and Java Servlets on the server side. Further the complete system landscape is presented consisting of a data base, web and voiceserver, parsers and browsers.
In order to have a reallistic environment the demontrator was integrated in a existing multimedia database on parliament speeches in the "Deutscher Bundestag" which was developped at FhG-IMK. So we have the following setup:
The development of multimodal capabilities, devices as well as applications has just begun. It will be enriched by further communication modes in the future. For example the gesturing of the user is to be regarded as another independent mode for example apart from the language. There are scenarios conceivable, in which one points to a selection of the screen with the finger and at the same time expresses a language instruction, which must be synchronized with the gestic instruction.
With this project a server-based scenario was carried out. This means that complete application except the mobile browser runs on a server - partially on the application server and patially on the voice server. Nowadays this is necessary since resources of the mobile devices are not sufficient to run the complete voice browser with speech recognition and synthesis. In the future both voice and the mobiles browser will be integrated on the mobile device.See the complete report and demo page at: http://greece.imk.fhg.de/Sivacow/html/index.html
None