Project acronym: QUESTION-HOW
Project Full Title:Quality Engineering
Solutions via Tools, Information and Outreach for the New Highly-enriched
Offerings from W3C: Evolving the Web in Europe
Project/Contract No.
IST-2000-28767
Workpackage 1, Deliverable D1.2
Project Manager: Daniel Dardailler
<danield@w3.org>
Author of this document: Nayim Yerlikaya, Klaus
Birkenbihl
Created: 29 August 2002. Last updated: 26 march 2003.
The work is about a semi-automatic Test Suite for XSLT/XPATH Processors.
For the time being there is a test suite for XSLT/XPATH provided by OASIS and NIST. These environment give only limited help to the user in identifying errors cause every output must be checked manually and there is no validator for XSLT/XPATH.
This project has implemented a test environment that
Within this work a test Framework is developped with whose assistance the quality of the XSLT/XPath processors are determined.
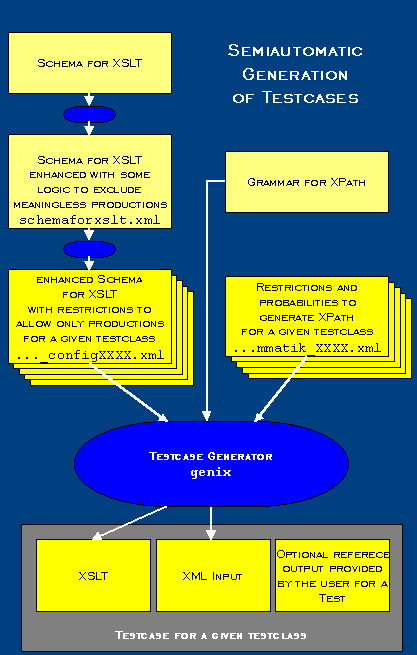
The test environment consists of two parts.
The generation XSLT Stylesheets takes place by means of an XML Schema, which represents a grammar for XSLT. Based on a Schema valid XSLT code is generated randomly. Since also XPath expressions in XSLT can occur and the pattern specified above is only for XSLT, a further grammar is needed, which describes XPath expressions. An EBNF grammar is used in the XPath Recommendation.
The above pattern has however also some disadvantages. For the test environment it is not sufficient that a valid code is produced, but also a logically correct code.
Therefore the XSLT Schema was extended with information from a new namespace. This namespace adds new attributes and new attribute values. These are used to generate only meaningful XSLT.
A further problem of the XSLT Schema is rather a general XML Schema problem. In the XML Schema the "use" attribute determines whether an attribute is necessarily, optional or forbidden. Now it can occur however that in a language a context dependency between attributes exist. Particularly for XSLT "template" either the attribute "match" or the attribute "name" may occur - but not both. This logic cannot be expressed in XML Schema (really not? At least it is not in the existing XML Schema for XSLT). There are similar problems in XSLT 2.0, where the "for-each-group" element for some attributes has an XOR usage. These problems were solved, by adding a new attributes "ud:use" with a name as attribute value to every of the attribute elements specified above. A new element "ud:useType" with the same names as one added above was added. "ud:useType" defines the logic (in KNF logic) of these attributes with each other.
There are also still further problems in XMLSchema. A "variable" may only have a text element if it does not have a "select" attribute. Also such a condition cannot be expressed in XML Schema. For this no elegant solution was developped. Instead the logic was (preliminarily) implemented into the application.
From the such modified XSLT Schema, which is called from now on schemaforxslt.xml, random XSLT codes can be generated. This is done by starting with the root node "transform" or "stylesheet" parsing the grammar and whenever a decision is to be made, how often a node is to be implemented or which node to select next, a random but valid choice is made. However since this might end up in a never ending loop. To avoid this a global maximum depth of the nesting was defined. If this max depth is reached, then a backtracking takes place up to a node, where a new decision is to be made.
Now we are able to generate XSLT but we don't have means to controll the generation. The goal is to generate for each test class different XSLTs. Therefore schemaforxslt.xml is changed for each class of tests. The files developed from it are called Pre_schemaforxslt.test_configXXXX.xml, whereby XXXX is used to identify the class. In these files each element keeps additionally the attribute more ud:maxNumber, which defines the maximum number of occurrences in XSLT. Furthermore an attribute is added for all elements, which replace a substitutionGroup. It is nameds "ud:prob", and defines the probabilityof the replacement.
Within a choice, the same attribute determines the probability by wich an element is to be selected. By use of these attributes we can controll the generation in such a way that some subtrees will be processed rarely or never while others are used more often. Another configuration option is offered by XMLSchema by means of "minOccurs" and "maxOccurrs". Last not least this permits to determine the size the generated file.
As already above mentioned XSLT contains also of XPath patterns. Therefore there should be also a configuration option of the XPath grammar. These configuration options are defined in XML files: the Counter_Grammatik_XXXX.xml. They also define how often a node may be maximally implemented and with which which probability a node is selected. By means of the Pre_schemaforxslt.test_configXXXX.xml, the XPath grammar and the Counter_Grammar_XXXX.xml "genix" the main application generates XSLT with associated XML input files.
In order to stay short we omit the description of the internals of "genix".
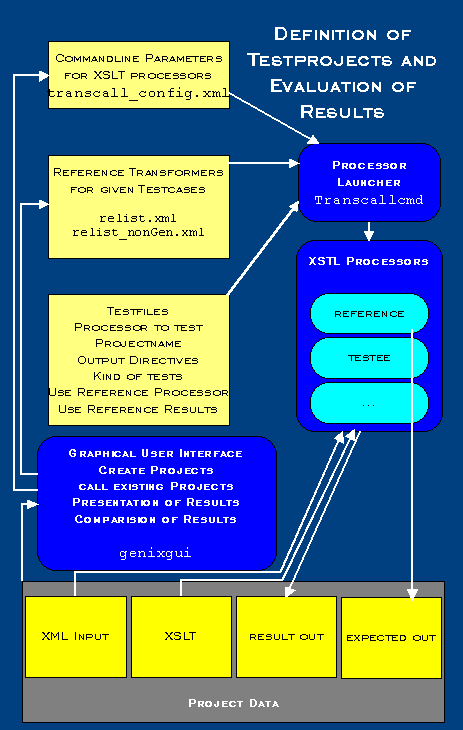
In the second part of the test environment the XML inputfiles are transformed by the processor to be tested according to the generated XSLT files. The same transformation is made by the above mentioned "reference transformer". The results are evaluated.
First a project for the transformer which is to be tested is ceated. A project is a collection of XSLTs, XML inputs and their result and reference files. This is done by a program named "transcallcmd". This program needs the test files or listings of the XSLTs and XML inputs. Moreover the program receives the name of the transformer to be tested and the project name. The last group of parameters indicate whether output is also to be normalized, whether generated test data or existing test data are used and whether reference files are to be provided by a reference transformer or by hand.
In order to have "transcallcmd" call the transformers with their options, transformers must be first of all registered. This happens in a XML file transcall_Config.xml. One can register different transformer names with different options e.g. for a transformer or in addition, define different versions of a transformer under different names, in order to be able to accomplish involution tests. If system tests are to be performed an analysis of perfomance, runtime, memory and processor usage are required. This is a further task of "transcallcmd".
If continuous loops are contained in XSLT, it can be that the transformer does not hold. If the transformer runs longer than a determined time threshhold, then the process of the transformer is terminated.
Having transformer names, XSLTDatei and XML input file tanscallcmd can call a transformer, which produces a result file.
Since result files are also needed from reference transformers, these must also somewhere be registered. This happens in relist.xml or in relist_nonGen.xml. The difference between the two files is that in relist.xml are the reference transformers for test classes. In relist_nonGen.xml reference are transformers for concrete XSLTs. The distinction is necessary, because with relist.xml not necessarily the best transformer for a test class must be always a good reference, since for a test class different cases of test can be generated.
Normalizing the result files takes place via transforming into canonical xml by assistance of the program "canonicalizer". The canonicalisation makes it easier to compare results of the tested and the reference transformers with one another.
By such a project creation is is finished. "Transcallcmd" puts on now a project folder, into which it put subfolders for
and the according files.
Having a project created, it is time to compare the results, to visualize errors and to evaluate the project by a user. This is done by means of a GUI program named "genixgui", in which the projects are opened. From this surface also all other necessary/relevant functions from the second part of the test environment can be implemented comfortably.
In the context of this work an automated test environment was presented, which allows integration and system test for XSLT/XPath processors. A flexible architecture was build based on XML technologies. The test environment consists of two parts. The first part is the generation of test datas. In the second part results are compared to expected results and evaluated results. With the help of the generation it is possible, to generate test cases more randomly or more targeted to a specific problem. By comparing results with the output of rerference transformators one can automatically run many tests and collect data to determine the quality of a transformer. A large advantage of the automatic generation is in the fact that very many test data can be produced. These are not necessarily always meaningful due to their usually coincidental generation, but often meaningless but permitted XSLTs/XMLs can supply useful cases of test. The high number of test datas makes it possible also to accomplish performance, stress or volume tests.
A large advantage of the second part of the test environment is that one can work on comfortably (by means of a GUIs) very many cases of test in a short time, since one does not have to provide expected results by hand if there are reference transformers. It offers also the possibility to the developers of transformers, to test against older versions of the own transformers. This test is reasonably, since implementation of new functionalities may hurt old functionalities.
In the presented test environment there are however also some difficulties.
The production of the configuration files (Pre_schemaforxslt.test_configXXXX.xml) for example needs some experimenting and experience to achieve usable results. First of all it is to be defined necessarily the test classes.
A new version of the recommendation means changes in its XML Schema. A change of the XML Schema requires an adoption of the "ud:" attributes. Since a few dependancies went into the application it might also require a small update there.
Possible improvements of the presented environment seems are in the area of logic, in that one extends the range of value of the attributes with logically meaningful values. A further stage of development could be an autoring tool for configuration files in order to avoid direct manipulations on XML schema level. In order to provide an increase in value, one could extend the generation of test, by the opportunity to include existing, meaningful files. This could produce logically more meaningful cases of test.
The work is finished. There is a Java program implementing the described system. Documentation is nearly finished.
Some technical changes (extensions and restrictions) were made due to the results of ongoing work.