This documents RDAL, Rdf Database Annotations Language, an implemented XML grammar language for making RDF database API calls. This language as been used in a production RDF parser and toolkit for two years. This paper covers the XML grammar language and the RDF database API made available to that language. Alternate approaches and implementation costs are also discussed.
The document is a description of an implementation of an XML parsing language. It represents only the thoughts of the author and not any sort of recommendation or note by the W3C. The author hopes that the experience gathered in developing this language will be useful to groups working on schema annotation. There is currently no commitment to maintain any particular version of this document. Future revisions are likely to replace this version, $Revision: 1.12 $. The author will maintain anchor tags withing this document. Obsolete anchor tags will be listed in the obsolete anchors section.
The language is expressed in terms of an datastructure. The only implementation is currently expressed as a perl datastrcture but it is trivial to express the same structure in C, Python, or whatever. Future work would involve developing a practical serialization for this language so that implementations in different languages could make use of the same language serializations.
The language is consists of two layers. The events define a set of XML events tied to an agent encountering XML infoset elements. The event dispatcher is currently impelemented as a SAX document handler but could easily be implemented by a depth-first DOM walker. The actions are associated with a particular XML event and provide access to variables stored in a simple virtual machine and access to an RDF database via a fixed API.
Each production in the state machine is named with a URI. (It has been convenient to implement a namespace preprocessor to abbreviate and simplify the expression of the productions.) Productions reference each other by these URIs. Within each production is a set of events and the associated bindings and actions.
Events are associated with one of two catagories:
The events are defined as follows:
The parser provides only string matches on URIs produced by concatonating namespaces and local names. It does not provide and operations for matching tuples produced by the namespace and local name separately. The practical implication of this is that
<a:ex1 xmlns:a="http://www.w3.org/2002/12/26-XMLgrammer2RDFdb/Overview.html#"/>
and
<a:x1 xmlns:ap="http://www.w3.org/2002/12/26-XMLgrammer2RDFdb/Overview.html#e"/>
are considered identical in their mapping to http://www.w3.org/2002/12/26-XMLgrammer2RDFdb/Overview.html#ex1. The exact algorithm for concatonating is determined by the form of the binding.
The state of the parser is stored in a stack of associations between variable names and values. As the parser encounters a nest element, it pushes a new variable stack frame onto the bottom of the variable stack. As it reaches a close element, it removes a stack frame from the stack.
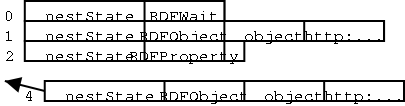
The parser maintains all of its state in variables that are available to the actions and bindings. It uses the following predefined variabels for this purpose.
In addition to reading pre-defined variables, RDAL allows the creation and assignment of variables withing the current variable stack frame.
An alternate way to implement the variable stackb was to have each new stack entry inherit all the variable binding from the one above it. This eases the burden of isolating the exact depth for locating a variable but didn't eliminate the need to look up the stack as the values of certain variables (for instance, the object variable in RDFObject) were simultaneously needed in both their shadowed and unshadowed values. Since depths were needed, it seemed that the flexibility offored by value inheritance would only make grammars harder to predict and debug, as well as increase the run-time burden.
Bindings control the interpretations of attribute values as URIs. The URI may be interpreted relative to namespaces and may have other string manipulations performed on it. The resulting URI is assigned to a variable for later reference in actions and other bindings.
The currently implemented BNF grammar for bindings is as follows:
binding: namespace? prefixStr? (target || lvalue) postfixStr? {described}namespace: variableRef '.' {described}variableRef: variableName stackPosition? {described}variableName: [a-zA-Z1-0_]+ {described}stackPosition: '[' integer ']' {described}prefixStr: '"' variableName '"' {described}target: '#' variableName {described}lvalue: variableName {described}postfixStr: '"' variableName '"' {described}Let's examine the following exerpt from the strawman WSDL mapping.
'defTNS[-2]."message_"messageName'
binding: interpretation of an attribute value as a URI.
namespace: a URI for relative evaluation of the attribute value.
variableRef: a reference to a variable someplace on the stack. In the absence of a stackPosition, the reference is to the bottom-most element, also address as [-1].
variableName: a valid name for a variable in the variable stackb.
stackPosition: an depth in the variable stackb where a veriable resides.
prefixStr: A piece of text inserted before the localname.
target: a localname interpreted as a URI reference (with a '#' between the namespace and the localname).
lvalue: a localname interpreted as a URI.
postfixStr: A piece of text inserted after the localname.
Actions are written in a simple language providing access to variabels on the variable stack, simple conditionals, and access to the RDF database API. The following operators are used to construct actions:
predicate[-2] selects the variable called "predicate" in the stack frame one up from the bottom.nestState="RDFProperty" assigns the literal "RDFPRoperty" to the predifined variable nestState.parseType=="Literal" true if the variable parseType is assigned to the literal "Literal".name!=\'rdf:Description\' true if the variable name is notassigned to the URI "http://www.w3.org/1999/02/22-rdf-syntax-ns#Description".!reifyChild[-2] true if the value of reifiyChild in the second bottom-most stack frame is unassigned or is assigned to NULL.reifyChild[-2]?reificationBag=reifyChild[-2]assigns reificationBag to the value of reifyChild[-2] if reifyChile[-2] has been assigned a non-NULL value.predicate[-2]&&!reifyChild[-2]?true if predicate[-2] is assigned and reifiyChile[-2] is not assigned.[] ! == != && = ?
The general format of an action is defined but the paring code:
$command =~ m/^ \s* (?:( [^\?]+ ) \s* \? \s*)? (?:( \w[\w\d\[\]\-]* ) \s* \= \s*)? ( [\'\"]?[\w\d\[\]\-:\/\.]*[\'\"]? ) ( \( ([^\)]+) \) )? \s* $/x || &throw(new W3C::Util::NotImplementedException(-function => $command)); my ($constraints, $lvalue, $funcOrVar, $isFunc, $args) = ($1, $2, $3, $4, $5);
p[-2]&&!reifyChild[-2]?foo=addStatement(p[-2], ob[-3], ob[-1], reif[-2], reifBag[-3])',
where constraint may match
Let's face it, this is not a pretty language, and I have no loyalty to it. If someone gives me a language parsable with a regular expression, I will abandon this one in a heartbeat.
The RDF database API is meant to be the minimal subset to enable a parser to assert statements consistent with the RDF statement interpretation of the text languages RDFXML, WSDL, P3P, XMLSchema and a couple of strawman RDF syntaxes.
predicate, subject, object, reificationID, reification bag, and a so-called attribtuion, a URI used to identify the source of the arc.The RDAL language elements described above must be recorded in a data structure that is parsable by agents wishing to then read the described XML documents and generated RDF triples. Any language representation for RDAL should be readable by any turing-complete programming language. For lack of counter-motivation, the current implementation uses a perl hash data structure.
'RDFWait' => {-common => {-start => 'nestState="RDFWait"',
-char => '
charAct?error("description", characters, charAct)'},
-onTag => {'rdf:RDF' => {-start => 'nestState="RDFObject"; charAct="characters_not_allowed_in_RDF_element"'},
'wsdl:definitions' => {-bind => {'wsdl:name' => 'defTNS#"definition_"defName',
'wsdl:targetNamespace' => 'defTNS'},
-start => 'nestState="WSDLdef"'}, #;defName=hashedUri(defName, defTNS)}}
'RDFObject' => {-common => {-bind => {"rdf:ID" => '#object', "rdf:about" => 'object',
"rdf:bagID" => '#reificationBag', "rdf:aboutEach" => 'aboutEach'},
-start => '
nestState="RDFProperty";
reifyChild[-2]?reificationBag=reifyChild[-2];
object?checkTrust(object);
predicate[-2]&&lastObject[-2]?error("description", object[-1], "already have", lastObject[-2],"object for property",predicate[-2]);
lastObject[-2]=object;
aboutEach?object=mappedNode(\'rdf:li\', aboutEach, NULL, reificationBag);
!aboutEach&&name!=\'rdf:Description\'?addStatement(\'rdf:type\', object[-1], name, NULL, NULL);
predicate[-2]&&!reifyChild[-2]&&object[-2]?error("description", object[-1], "inside a shortcut propertyElt", object[-2]);
predicate[-2]&&!reifyChild[-2]?addStatement(predicate[-2], object[-3], object[-1], reification[-2], reificationBag[-3])',
-attr => {
"rdf:resource" => ['reference',
'error("resource", value, "inside a shortcut typedNode", object);'],
"rdf:ID" => undef, "rdf:about" => undef, "rdf:bagID" => undef, "rdf:aboutEach" => undef},
-otherAttr => ['literal', 'addStatement(attribute, object[-1], value, GENID, reificationBag[-1])'],
-char => 'error("description", characters, "in typedNode", object)'}}
It is trivial to parse this in other languages (jave, python...) or map it to an XML DTD or schema:
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF SYSTEM "StateMachine.dtd">
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns="http://www.w3.org/2002/12/26-XMLgrammer2RDFdb/StateMachine.xml">
<StateSet rdf:about="http://dev.w3.org/cvsweb/perl/modules/W3C/Rdf/EmitterInterface.pm">
<rdf:li>
<State rdf:ID="RDFWait">
<common>
<CommonSet>
<start>nestState="RDFWait"</start>
<char>charAct?error("description", characters, charAct)</char>
</CommonSet>
</common>
<onTag>
<TagSet>
<rdf:li>
<Tag>
<name rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#RDF" />
<start>nestState="RDFObject"; charAct="characters_not_allowed_in_RDF_element"</start>
</Tag>
</rdf:li>
<rdf:li>
<Tag>
<name rdf:resource="http://schemas.xmlsoap.org/wsdl/definitions"/>
<bind>
<BindingSet>
<rdf:li>
<Binding>
<name rdf:resource="http://schemas.xmlsoap.org/wsdl/name" />
<varString>defTNS#"definition_"defName</varString>
</Binding>
</rdf:li>
<rdf:li>
<Binding>
<name rdf:resource="http://schemas.xmlsoap.org/wsdl/targetNamespace" />
<varString>defTNS</varString>
</Binding>
</rdf:li>
</BindingSet>
</bind>
<start>nestState="WSDLdef"</start>
</Tag>
</rdf:li>
</TagSet>
</onTag>
</State>
</rdf:li>
<rdf:li>
<State rdf:ID="RDFObject">
<common>
<CommonSet>
<bind>
<BindingSet>
<rdf:li>
<Binding>
<name rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#ID"/>
<varString>#object</varString>
</Binding>
</rdf:li>
<rdf:li>
<Binding>
<name rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#about"/>
<varString>object</varString>
</Binding>
</rdf:li>
<rdf:li>
<Binding>
<name rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#bagID"/>
<varString>#reificationBag</varString>
</Binding>
</rdf:li>
<rdf:li>
<Binding>
<name rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#aboutEach"/>
<varString>aboutEach</varString>
</Binding>
</rdf:li>
</BindingSet>
</bind>
<start>nestState="RDFProperty";
reifyChild[-2]?reificationBag=reifyChild[-2];
object?checkTrust(object);
predicate[-2]&&lastObject[-2]?error("description", object[-1], "already have", lastObject[-2],"object for property",predicate[-2]);
lastObject[-2]=object;
aboutEach?object=mappedNode(\'rdf:li\', aboutEach, NULL, reificationBag);
!aboutEach&&name!=\'rdf:Description\'?addStatement(\'rdf:type\', object[-1], name, NULL, NULL);
predicate[-2]&&!reifyChild[-2]&&object[-2]?error("description", object[-1], "inside a shortcut propertyElt", object[-2]);
predicate[-2]&&!reifyChild[-2]?addStatement(predicate[-2], object[-3], object[-1], reification[-2], reificationBag[-3])</start>
<attr>
<AttrSet>
<attrLi>
<Attr encoding="literal">
<name rdf:resource="rdf:resource"/>
<action>error("resource", value, "inside a shortcut typedNode", object);</action>
</Attr>
</attrLi>
<attrLi><Attr><name rdf:resource="rdf:ID"/></Attr></attrLi>
<attrLi><Attr><name rdf:resource="rdf:about"/></Attr></attrLi>
<attrLi><Attr><name rdf:resource="rdf:bagID"/></Attr></attrLi>
<attrLi><Attr><name rdf:resource="rdf:aboutEach"/></Attr></attrLi>
</AttrSet>
</attr>
<otherAttr>
<DefaultAttr encoding="literal">
<action>addStatement(attribute, object[-1], value, GENID, reificationBag[-1])</action>
</DefaultAttr>
</otherAttr>
<char>error("description", characters, "in typedNode", object)</char>
</CommonSet>
</common>
</State>
</rdf:li>
</StateSet>
</rdf:RDF>
The DTD for this document also happens to validate legal and useful RDF.
It is not difficult for most XML schemas to be annotated with an appinfo element with some langauge representation of the RDAL grammar language. Certain abstract XML grammars are not suitable for expressing productions that are selected by nesting position and not by element name. This is an issue for any regular encoding of data in XML that follows a pattern and algorithmic mapping to triples but does not have predicable element names. RDF/XML and SOAP encoding are examples of this problem. While it is possible constrain these languages to be expressable in XML Schema, or not address them with RDAL, this general problem will continue to arrise. The likely breadth of higher level data expression languages can be predicated by the number of current proposals @@(Paul Prescod's Simple XML Structure Markup Language, ...)@@.
RelaxNG is a good choice for simultaneoulsy constraining (validating) instance data and describing the mapping of that instance data to RDF triples. It has XML and non-XML syntaxes which are machine-translatable for XML-friendly and human-friendly reading and manipulation. It was relatively simpel to write an RDAL expression in RelaxNG.
A recent addition to the pool is Waterken which is aimed not at validation but instead at associating a set of data structures with elements in an XML document.
It was easy to embed the RDAL directives in a Relax NG schema for RDF.
The most common approach to using literal schema annotations for transforming a fixed XML schema to RDF is to use nested XSLT in the schema annotation elements.
The abstraction of the parser language and interpretation of another layer of code affects the efficiency of the parser. In recent, somewhat imprecise, experiments, the python RDF parser was found to be twice as fast as this parser. Additional interning costs, which are considered a small price to pay for query efficiency, may also contribute to that figure.
The choice of a perl hash as a language representation improves the efficiency of the language to some degree. Profiling has show that 16% of parsing time was spent parsing the actions associated with an event. This could be greatly reduced if the actions were pre-compiled into native or a virtual machine code like JVM.
The constraints of the language have lead to some interesting idioms, mostly for error handling. The following creates a state in your state machine which will report errors on any of its events:
'Error' => {-common => {-start => 'nestState="Error"'}}
Productions that are expecting an enumerable set of tags and attributes may default to this error state but specifically override this default if exected tags or attributes are encountered.
'WSDLdef' => {-common => {-start => 'nestState="Error"',
-char => 'error("CDATA ", characters, "in", nestState, "for tag", name)'}..