What Part of "Resource" Don't I Understand?
David Booth <dbooth@w3.org>, W3C Fellow / Hewlett-Packard
$Revision: 1.7 $ of $Date: 2003/01/28 03:47:26 $ by $Author: dbooth $
This document: http://www.w3.org/2002/11/dbooth-names/dbooth-rfc2396-analysis_clean.htm
Table of Contents
Abstract
This document analyzes the definition of "resource" in RFC2396 [1] in an attempt to understand it. It notes ten questions or points of confusion (labeled QUESTION1 - QUESTION10) that I encountered.
WARNING: This analysis is painfully detailed, and somewhat rambling (sorry!), reflecting my thought process as I (honestly) attempted to understand the definition. It is only recommended to those who believe that the definition is clear, and want to see evidence to the contrary.
Status of This Document
This document represents my own views. It has no official status. Comments are invited.
Prerequisites
Throughout this analysis I try to relate statements in RFC2396[1] to my own pre-existing understanding of the ways that I have seen URIs used in reality, which I have described in "Four Uses of a URL: Name, Concept, Web Location and Document Instance"[2]. That document describes a classification scheme of four kinds of things -- names, concepts, Web locations and document instances -- which you should understand before reading this document. You should also understand what I mean by the "different names" versus "different context" approaches described therein.
Admittedly, notions in RFC2396 might not correspond to notions in my classification scheme. It's quite possible that I need to adopt some entirely new concepts in order to understand the definition of "resource". So although I do try to relate notions in RFC2396 to my own classification scheme, I also try to keep my mind open.
Analysis
For ease in discussing particular lines in RFC2396, I created a line numbered version. Each excerpt below was copied from that document, and is followed by my thoughts.
39. Abstract 40. 41. A Uniform Resource Identifier (URI) is a compact string of characters
42. for identifying an abstract or physical resource. [...]
Thought 0: Since this appears in the abstract of RFC2396, I probably shouldn't consider the statement to be normative. Nonetheless, it provides evidence that a URI identifies a resource, and a resource can be abstract or physical.
"Resource" seems to be defined mostly in lines 103-123, though further evidence of its meaning, and its relationship to a URI, appears in lines 124-143.
103. Resource
104. A resource can be anything that has identity. [...]
Thought 1: Okay, so a resource can be anything, since anything can have identity.
Thought 2: What does it mean to "have identity"? Presumably, it means you can refer to it. Which of the four things in my classification scheme can be referenced? Potentially any of them. On the other hand, maybe "having identity" means that you can refer to the thing *directly*, meaning that the thing has a name. In my classification scheme, any of the four things could potentially have a name, though I think the "concept" and the "Web location" are the most likely to have names.
104. [...] Familiar
105. examples include an electronic document, an image, a service 106. (e.g., "today's weather report for Los Angeles"), and a107. collection of other resources. Not all resources are network
108. "retrievable"; e.g., human beings, corporations, and bound 109. books in a library can also be considered resources.
Thought 3: Okay, so (translating into my classification scheme) the set of resources is the union of all things that are on the Web and all things that are not on the Web. Fine.
107. [..] Not all resources are network
108. "retrievable"; [...]
Thought 4: If 'Not all resources are network "retrievable"', then presumably some resources ARE network retrievable. In my classification scheme, the only things that are network retrievable are document instances. Hmm, not sure what I can conclude from this.
Thought 5: QUESTION1: But what is meant by "retrievable"? Does it mean that the *resource* can be retrieved via the network? Or does it mean that I can retrieve something *from* the resource via the network? If it means the former, then that would imply that some resources are document instances. If it means the latter, then that would imply that some resources are Web locations. I don't know which interpretation is intended.
Thought 6.1: [Previously labeled "Thought 6"] I notice there are quotes around the word "retrievable", so maybe they don't really mean that some resources are "network retrievable" at all. Maybe they are using the term "retrievable" figuratively in some other way that I haven't considered.
108. [...] e.g., human beings, corporations, and bound
109. books in a library can also be considered resources.[...]
118. The resource is the conceptual mapping to an entity or set of119. entities, [...]
Thought 6.2: [Previously labeled "Thought 7"] Uh-oh. QUESTION2: Lines 108-109 imply that a human being can be a resource, but lines 118-119 say that the resource is a *mapping*. I assume that a human being is NOT a mapping, so I'm confused by this apparent contradiction.
Thought 6.3: [Previously labeled "Thought 6"] Hmm, maybe lines 108-109 were imprecise, and didn't really mean that a human being can be a resource. Maybe they meant that the resource is the "conceptual mapping" to a human being.
Thought 7.1: [Previously labeled "Thought 7"] What's a "mapping"? Presumably it's an association from one thing to another. QUESTION3: But from what to what? From the URI to the human being, for example? If so, then I think what I understand so far is that a URI identifies a resource, but a resource is a *mapping* from the URI to the human being. Therefore, a URI identifies a *mapping* from the URI to the human being, which seems a little odd, since a statement of the form "X identifies Y" is *itself* a mapping from X to Y. In other words, we seem to have:
a mapping: URI --> (a mapping: URI --> human being)
Or in English, we seem to have a mapping from a URI to a mapping from a URI to a human being. Although this sounds peculiar to me, maybe that's what's intended.
Thought 8: QUESTION4: On the other hand, maybe I'm interpreting lines 118-119 too literally. Maybe the resource is supposed to be the human being (for example) that is *identified* by a mapping from a URI to the resource. That sounds like a simpler interpretation. In that case, I presume the "entity or set of entities" mentioned in lines 118-119 must also be the resource.
119. [...] not necessarily the entity which corresponds to that
120. mapping at any particular instance in time. [...]
Thought 9: Okay, so an entity can correspond to the mapping at a particular instant, but a different entity might correspond to the mapping at a different instant. Fine. If "entity" is synonymous with "resource" (according to Thought 8) then lines 119-120 seem to be saying that the mapping might identify one resource at one instant, and another one at a different instant. However, I need to consider lines 119-120 in the context of the full sentence before I reach this conclusion.
118. The resource is the conceptual mapping to an entity or set of
119. entities, not necessarily the entity which corresponds to that120. mapping at any particular instance in time. [...]
Thought 10: Now I need to figure out what is meant by the word "conceptual" in line 118. Presumably a "conceptual mapping" is not an actual mapping, but merely the *concept* of a mapping. In other words, there may be many particular mappings (over time) that could fill the role of this one "conceptual mapping". I confess that I find the concept of a "conceptual mapping" very difficult to intuit, but maybe I should just go with it and see where it leads.
Thought 11: QUESTION5: Maybe line 118 didn't really mean that the *mapping* is conceptual. Maybe it meant that the *entity* is conceptual. I.e., maybe it is a mapping to a "conceptual entity", rather than to any particular entity that corresponds to that mapping at any particular instant. This sounds like a much simpler interpretation. For example, the author of this document (David Booth) will change over time, because the person that I was when I was 5 years old is different than the person that I am now, and that person is different than the person that I will be 10 years from now. Nonetheless, they can all be considered the same conceptual person.
Or another example: the White House is not exactly the same building as it was 50 years ago, but the conceptual "White House" simultaneously refers to all instances of the White House over time.
And yet another example: this document is not the same as it was 20 minutes ago. But the concept of "this document" can refer to all versions of it, past and future.
Okay, so maybe lines 118-120 mean that a resource is a conceptual entity (which could abstractly represent physical things like "this author" or the "White House" or "this document"). If this interpretation is correct, then it sounds like a URI identifies a resource, and a resource is a conceptual entity (where "conceptual entity" includes abstractions of physical entities).
120. [...] Thus, a resource
121. can remain constant even when its content---the entities to 122. which it currently corresponds---changes over time, provided 123. that the conceptual mapping is not changed in the process.
Thought 12: Okay, this makes sense according to the interpretation in Thought 11.
125. Identifier
126. An identifier is an object that can act as a reference to127. something that has identity. In the case of URI, the object is
128. a sequence of characters with a restricted syntax.
Thought 13: Good, I understand this. A URI is a particular kind of string that is used to identify a resource, which is a conceptual entity.
130. Having identified a resource, a system may perform a variety of
131. operations on the resource, as might be characterized by such words 132. as `access', `update', `replace', or `find attributes'.
Thought 14: Uh-oh. QUESTION6: How can a system perform operations on a conceptual entity? What if that resource is this author, David Booth? What if that resource is a particular concept of love? Those are things that can have identity (i.e., be referenced), can't they? I don't see how systems can be expected to perform operations on them. Perhaps line 130 meant that for *some* resources, a system can perform operations on the resource. Or perhaps lines 130-132 mean that only those things on which a system can perform operations should be considered resources. That last interpretation sounds weak to me, but *maybe* that's what's intended.
134. 1.2. URI, URL, and URN135.
136. A URI can be further classified as a locator, a name, or both. [...]
Thought 15: Great, I understand this too. "A locator" sounds very much like a "Web location" in my classification scheme. I'm not sure if "a name" in line 136 corresponds to my notion of a name though. I'll have to gather more evidence. If it does, then line 136 seems to be saying (in my classification scheme) that a URI could be both a name and a Web location. But I also know that a URI identifies a resource, which (if I've guessed right) is a conceptual entity. Therefore a name and a Web location can both identify a resource. Hmm, that's interesting.
Thought 16: QUESTION7: If a URI can be "a locator, a name, or both", but a URI also maps to a resource, then what does such a URI denote? Does it denote "a locator, a name, or both", or does it denote the resource to which it maps? Well, maybe I shouldn't try to ask that question at this point.
136. [...] The
137. term "Uniform Resource Locator" (URL) refers to the subset of URI 138. that identify resources via a representation of their primary access 139. mechanism (e.g., their network "location"), rather than identifying 140. the resource by name or by some other attribute(s) of that resource.
Thought 17: Okay, this coincides with Thought 15 -- a URI can be both a name and a Web location, and both can identify a resource.
Thought 18: I'm almost certain (from other reading) that the notion of "representation" in line 138 corresponds to a "document instance" in my classification scheme. So lines 136-140 seem to be saying that a URL resource is identified by a document instance. QUESTION8: This surprises me, because I thought the resource would be identified by a "mapping" from the URL (as discussed earlier). Does this mean that the mapping itself is defined by the document instance? Or perhaps the mapping itself is defined not by one particular document instance, but by a "conceptual document instance" that represents an abstraction of all document instances that may be associated with that URL. That isn't what seems to be stated, but maybe that's what's intended.
Thought 19: Hmm, so perhaps this means that a URL identifies a conceptual document instance, and that conceptual document instance identifies the resource, which is a conceptual entity. This introduces another level of indirection than I had previously seen in the description of the "mapping", but I guess that's okay.
139. [...] rather than identifying
140. the resource by name or by some other attribute(s) of that resource.
Thought 20: This seems to imply that some URIs (though not URLs) identify their resource by name. That's interesting to know. I assume that the "name" mentioned in line 140 is the URI itself. Therefore some URIs (though not URLs) identify resources directly.
Thought 21: QUESTION9: I wonder what "some other attribute(s) of that resource" might be.
141. The term "Uniform Resource Name" (URN) refers to the subset of URI
142. that are required to remain globally unique and persistent even when 143. the resource ceases to exist or becomes unavailable.
Thought 22: Arrgh! QUESTION10: How can a resource cease to exist if, as surmised in Thought 11, a resource is a conceptual entity? I don't see how a conceptual entity can *ever* cease to exist. Hmm, well, maybe they meant "even if a particular *instance* of the resource ceases to exist".
136. [...] The
137. term "Uniform Resource Locator" (URL) refers to the subset of URI 138. that identify resources via a representation of their primary access 139. mechanism (e.g., their network "location"), rather than identifying 140. the resource by name or by some other attribute(s) of that resource.
Conclusions
I'm confused. Perhaps my best guess so far of "what is a resource" (according to the definition in RFC2396) is that a resource is a conceptual entity, where a "conceptual entity" could be an abstraction of a physical entity. And the relationship from a URI to a resource depends on what kind of URI it is. A URI that is *not* a URL directly identifies a resource. A URI that *is* a URL indirectly identifies a resource. It identifies a conceptual document instance (a/k/a a conceptual "representation"), which is an abstraction of all particular document instances that may be retrieved from a Web location determined by the URL. Finally, that conceptual document instance identifies a resource. This is illustrated below. I don't know if it's correct.
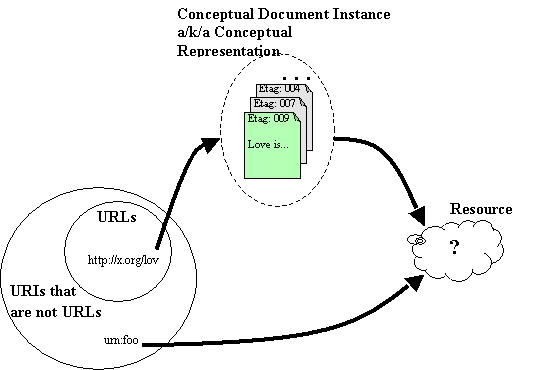
If this interpretation of RFC2396 is correct, then how can I reconcile it with my observations on the Four Uses of a URL? In particular, how should each of the four things in my classification scheme -- name, concept, Web location and document instance -- be identified?
[Unfinished. Not sure of the answer to this.]
References
1. http://www.w3.org/2002/11/dbooth-names/rfc2396-numbered_clean.htm
2. http://www.w3.org/2002/11/dbooth-names/dbooth-names_clean.htm